2020法研杯比赛阅读理解任务冠军参赛总结

作者 | 虹猫
学校 | 中南大学
研究方向 | 自然语言处理
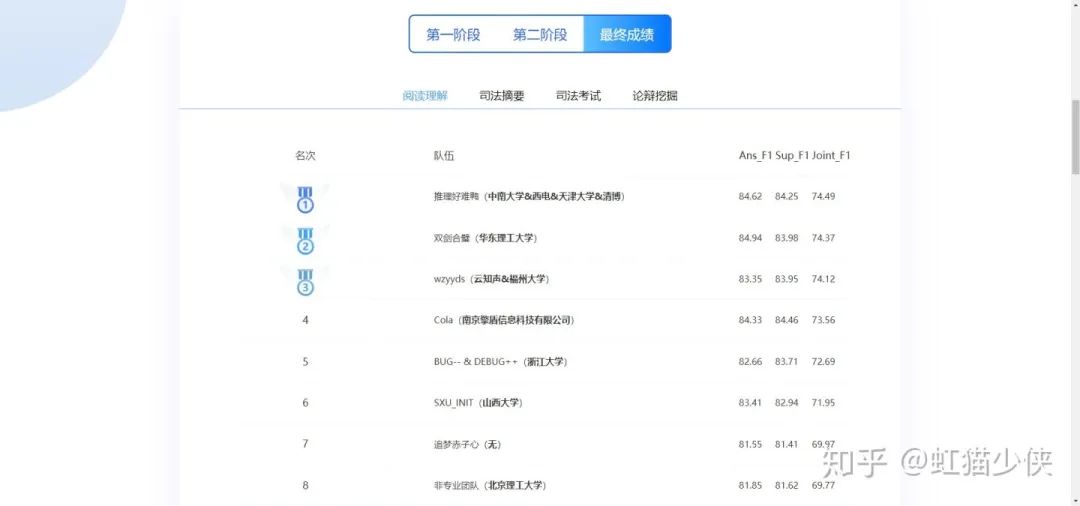
2020法研杯阅读理解竞赛上个月结束了,我们团队在最终阶段有幸获得了第一名的成绩,去年我也参加了这次比赛,过了一年,还是一只鶸,害,首先真心感谢各个队友的帮助,接下来是我对参加这次比赛的总结与分享,希望和大家相互学习,多交流。
数据介绍
今年的数据集是去年的升级版,去年格式类似SQuAD 2.0,今年格式类似于HotpotQA,不仅文书种类由民事、刑事扩展为民事、刑事、行政,问题类型也由单步预测扩展为多步推理,难度有所升级。具体而言,对于给定问题,只通过单句文本很难得出正确回答,选手需要结合多句话通过推理得出答案。
本任务技术评测训练集包括两部分,一部分为去年的CJRC训练集,一部分为重新标注的约5100个问答对,其中民事、刑事、行政各约1700个问答对,均为需要多步推理的问题类型。验证集和测试集各分别约为1900和2600个问答对,同样均为需要多步推理的问题类型。第一阶段多步推理数据仅提供民事的一部分数据,规模较小,选手可充分利用CAIL2019的数据进行训练。(来自官网介绍)
简单来看个数据就明白了,需要让模型阅读完问题question和文章context之后,不仅回答出问题的答案(答案仍然有四种类型:span、yes、no、unknown),还需要找出回答出该答案所依据的线索句子。如下例:通过线索句子1和3可以回答出正确的答案“魏7”。
{
"_id": 5048,
"context": [
[
"经审理查明,",
[
"经审理查明,",
"被告人胡x1的犯罪事实与起诉书指控的一致。",
"另查明,",
"案发后被告人胡x1与魏7达成和解协议,",
"并已履行完毕,",
"魏7对被告人胡x1的行为表示谅解。",
"上述事实,",
"被告人胡x1在庭审过程中亦无异议,",
"且有书证被告人胡x1的户籍证明、金乡县公安局刑警大队出具的到案经过、山东省金乡县人民法院移送公安机关侦查函、民事诉状及三份借据复印件、财产保全申请书、山东省金乡县人民法院(2009)金民初字第826-1号民事裁定书、EMS全球邮政特快专递回执联复印件、金乡县人民法院(2009)金8协字826-1号协助执行通知书及送达回证、(2009)金民初字第826号民事调解书及送达回证、调解笔录、协议书、谅解书、立案审批表及申请执行书、法律文书生效证明书、(2010)金执字第256号执行通知书、特快专递回执联复印件、申请书、(2010)金执字第256-2号执行裁定书、改退批条、(2010)金8协字256号协助执行通知书及送达回执、本地机动车详细查询基本信息、证明、金乡县人民法院传票及执行笔录、金乡县人民法院关于查封被执行人胡x1车辆情况说明、鲁H车辆照片复印件、机动车注册、转移、注销登记/转入申请表及委托书、二手车销售统一发票、机动车交通事故责任强制保险单、齐鲁晚报一份、办案说明、机动车单项查询信息,",
"证人魏7、付某甲、徐某、付某乙的证言,",
"被害人胡x9的陈述,",
"被告人胡x1的供述等证据,",
"足以认定。"
]
]
],
"question": "被起诉书指控的人和谁达成了和解协议?",
"answer": "魏7",
"supporting_facts": [
[
"经审理查明,",
1
],
[
"经审理查明,",
3
]
]
}
评价方式
本任务采用F1进行评估。对于每个问题,需要结合案情描述内容,给出回答,回答为Span(内容的一个片段)、YES/NO、Unknown中的一种,并且给出答案依据,即所有参与推理的句子编号。评价包括两部分:1)Answer-F1,即预测答案会与标准答案作比较,计算F1;2)SupFact-F1,即预测句子编号序列会与标准句子编号序列作比较,计算F1。最终为这两部分F1的联合F1宏平均。
比赛流程
本次比赛流程仍然和去年一样,分为三个阶段,第一阶段:报名,发放samll数据集,编写、测试模型,结果不计入最终成绩;第二阶段:发放big数据集,结果将计入最终成绩;第三阶段:选手在第二阶段提交的模型中选择三个模型作为第三阶段封闭测试的模型。
比赛的最终成绩计算方式:最终成绩 = 第二阶段的成绩 * 0.3 + 第三阶段的成绩 * 0.7
评测方式仍然和之前一样,需要提供训练好的模型,主办方线上评测,选手看不到测试集。
接下来我也继续按着时间线来分享下我们团队此次比赛中使用的方案和一些经验。
第一阶段
拿到数据之后日常进行数据分析,第一阶段主办方给出了1565个样本,文章(context)长度99%分位数为592.0,问题(question)长度99%分位数为34.7,答案(answer)长度99%分位数为23.0;第二阶段公布了5054个样本,文章(context)长度99%分位数为645.0,问题(question)长度99%分位数为40.0,答案(answer)长度99%分位数为30.0。
主办方同时也发布了基于BERT的多任务联合训练的strong baseline,应该是基于Spider-Net改的,代码结构很清晰,是一个很棒的baseline。
我们也是接着baseline继续优化,其实是3个子任务的联合训练:阅读任务、答案类型四分类任务、线索句子二分类任务。
数据增强部分
主办方说明可以使用去年的数据,但是去年数据是类似SQuAD 2.0格式,仅有答案和答案类型,并没有提供线索句子,因此线索句子需要自己构造。
我们构造方式主要分为两种,第一种方式是分句之后直接在每个句子中find答案文本,如果该句子中包含答案文本,则将该句子作为支持句子。However,这样做其实是有问题的,留个彩蛋,后面说。。。
第二种方式也是基于第一种方式的,我们考虑到不仅仅是包含答案文本的句子可以是线索句子,有些句子虽然不包含答案文本,但是要回答出答案,需要这些句子的推理,其实也是线索句子的。因此,我们将问题和答案拼接[question:answer],作为句子A,依次去计算拼接后的句子与文章每个句子的TFIDF相似度,分别取相似度最高的前1、2、3条句子作为线索句子(同时也添加了答案文本所在的句子)。
之后的实验发现第一阶段采用第二种方式取TFIDF top2句子效果最好,然而,比赛第二阶段发现,第一种构造数据方式虽然简单粗暴、正负样本也不均衡,但是比第二种方式效果更好,可能是第二阶段发布了较多的训练集原因。
对于阅读任务,有了去年的经验,我们并没有在BERT后面继续添加一些基于Attention的阅读模型,而是直接取出BERT最后两层的sequence_out进行拼接去做答案的抽取,实验表明,比仅取最后一层效果会更好,BERT不同层学习到了不同的特征表示。
对于答案类型分类任务,沿用去年的方法,在BERT的最后一层sequence_out后面接CapsNet和答案四分类的Attention层进行答案的分类。
对于线索句子分类任务,基本还没做什么大的改进,沿用baseline的方式对每个句子去做2分类,尝试了下简单的添加多层网络,效果并不明显。
将三个子任务的loss加权相加在一起,作为整个任务的loss进行联合训练。第一阶段初期,我们一直使用的是RoBERTa_base预训练模型,也尝试改各种模型,数据做了一周多些,发现线下基本没啥提升,但是排行榜上前排比我们高了3-4个点,我们觉得还是预训练模型的问题,然后换了RoBERTa_large,确实分数也就提上来了。
第二阶段
第二阶段我们做的就更细致一些了。
数据部分
1.接上面说的,“我们第一种方式是分句之后直接在每个句子中find答案文本,如果该句子中包含答案文本,则将该句子作为支持句子。”由于数据中只给出了答案文本,并没给准确的答案开始位置,主办方给的baseline也是find答案文本,然后取匹配到的第一个答案文本位置作为答案开始位置,但是这样其实是有问题的,会出现错误标记的问题。举个例子:下面样例的问题是“谁垫付了后续的政府奖补资金?”,答案文本是“原告”,但是“原告”两个字在context中出现了多次,第一次出现“原告”位置句子为“被告在进贤县文港镇采砂办渡头榨下的采砂场所占的股权转让给原告所有”,明显不是真正答案的位置,真正答案线索句子为“原告先行垫付被告后续政府奖补资金”。如果按baseline的方式,会有不少样本出现这样的答案标注偏差问题,对于阅读理解这样的任务,这种影响其实挺大的。我们根据训练集给的supporting_facts中的线索句子,去重新标定答案,这样可以确保答案是和线索句子相关,提高了真正答案位置的准确率,不至于完全和问题不相关。
{
"_id": 65,
"context": [
[
"经庭审质证、认证,",
[
"经庭审质证、认证,",
"本院认定事实如下:2014年元月18日,",
"原、被告双方签订了一份采砂场股权转让协议书。",
"协议约定:原、被告自签订该协议起,",
"被告在进贤县文港镇采砂办渡头榨下的采砂场所占的股权转让给原告所有,",
"被告不再拥有采砂场的开采权益及股份权,",
"砂场平台以上存砂、石、机械设备、棚房及其他地面建筑物等全部清理出砂场;",
"被告无条件配合市、县采砂办、文港镇政府切割采砂设备和清理砂场;",
"同时,",
"原告先行垫付被告后续政府奖补资金,",
"原告支付后,",
"后续的砂场设备奖补资金归原告所有。",
"协议还就其他事项作了约定。",
"协议签订后,",
"原告按规定给付了被告全部股权、作业房、装载机、吸沙船及挖沙船的转让金175320元,",
"并垫付了后续的政府奖补资金。",
"为此原告具状法院,",
"提出如前的诉讼请求。",
"另查明,",
"原、被告签订协议后,",
"原告从进贤县文港镇采砂办领取了采砂场的部分分红。"
]
]
],
"question": "谁垫付了后续的政府奖补资金?",
"answer": "原告",
"supporting_facts": [
[
"经庭审质证、认证,",
14
],
[
"经庭审质证、认证,",
15
]
]
}
2.使用19年数据时,19年数据文章context长度普遍较长,平均约800-900,这样直接切句子时,容易超出max_len=512,因此,我们使用了下截断,将答案开始位置在480长度之后的,进行根据答案开始结束位置前后取150长度作为新的文章context,这样保证了文本长度基本在512之内,扩充了正样本量。
仅通过这两个对数据集的修正,我们ans_f1就提高了1个多点,确实证明了正确数据的重要性。
预训练模型方面的尝试:去年做法研杯的时候,当时预训练模型只有中文版的BERT_base和ERNIE 1.0,短短一年时间,NLP预训练模型五花八门,从理解到生成都发布了很多优秀的预训练模型。因此,除了RoBERTa模型之外,我们还尝试了NEZHA和ELECTRA,但是效果都没有RoBERTa好,差距约2-3个点。通过阅读ACL 2020最佳论文提名奖《Don't Stop Pretraining: Adapt Language Models to Domains and Tasks》,我们也受到启发,继续对下游任务进行预训练,使用的18年的法研杯数据,约3.5G,继续进行MLM任务的预训练,跑了20W步,然后进行测试,发现也没效果,23333....,也尝试了FGM等对抗训练方式,也没有提升。
对于阅读任务,除了第一阶段的拼接BERT最后两层句向量,还在后面接了BiAttention,类似BiDAF的query、context双向attention,然后去做答案抽取。当然也做了其他各种操作,答案验证、接BiGRU、接Highway Net等。
对于答案类型分类任务,除了在BERT的最后一层sequence_out后面接CapsNet和答案四分类的Attention层进行答案的分类,再结合CLS和sequence_out做了层attention,联合四个logit进行答案四分类,也尝试了DiceLoss这些,但并没有提升。
对于线索句子分类任务,先将BERT的sequence_out再次经过SelfAttention,然后使用了线索句子开始和结束的映射,去和输出的所有句子表示做Attention,突出线索句子的表示,最终concat线索句子开始和结束表示,与max、mean方式进行联合分类线索句子。在训练时,非线索句子数量一般远大于线索句子,由于是二分类,使用的是BCE损失,我们也设置了pos_weight,让正样本权重提高一些。
第二阶段用以上方式,我们最好的单模ansf1有83.46,support_f1有78.23,离比赛第二阶段结束还有一周多时,单模取得了线上第四的成绩。
最终的模型集成就是不同的下游模型集成了,以及不同的随机种子,然后选取加权权重这样的常规集成方式。
总结&TO DO
1.首先感谢主办方举办的第二届法研杯机器阅读理解比赛,赛题也更加有趣和挑战性,期待明年阅读任务和数据格式会是什么样子。
2.其实HotpotQA排行榜上面前排很多模型都是基于图网络的,用图网络做线索句子识别效果会更好,但也由于我们对图网络了解不够,所以没有采用这样的方法,图网络技能以后还是必须得点上。
3.这次比赛数据质量很重要,阅读理解答案位置的正确标定,真实的线索句子都会带来不小的提升,所以不论竞赛还是工程项目,在数据上做的要足够细致。
4.通过分析bad case,发现模型对答案文本靠后的答案有的识别不出来,以及如果原文中多次出现了答案文本,比如多次出现“原告”,也抽取不出来,所以可以对这些bad case再做进一步的优化。
参考文献
[1] 法研杯2020官方github
[2] RoBERTa: A Robustly Optimized BERT Pretraining Approach
[3] ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
[4] NEZHA: Neural Contextualized Representation for Chinese Language Understanding
[5] Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
本文由作者授权AINLP原创发布于公众号平台,欢迎投稿,AI、NLP均可。原文链接,点击"阅读原文"直达:
https://zhuanlan.zhihu.com/p/190266425
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
阅读至此了,分享、点赞、在看三选一吧🙏