让AI自己调整超参数,谷歌大脑新优化器火了,自适应不同任务,83个任务训练加速比经典Adam更快
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
还在苦恼怎么给优化器调整更好的参数吗?
现在,谷歌大脑搞出了一个新的优化器VeLO,无需手动调整任何超参数,直接用就完事了。
与其他人工设计的如Adam、AdaGrad等算法不同,VeLO完全基于AI构造,能够很好地适应各种不同的任务。
当然,效果也更好。论文作者之一Lucas Beyer将VeLO与其他“重度”调参的优化器进行了对比,性能不相上下:

有网友看到了一丝优化器进步的曙光:
在Adam之后出现了不少优化器,却都表现得非常失败。这个优化器或许确实能表现更好。

所以,这个基于AI的优化器是如何打造的?
VeLO究竟是怎么打造的?
在训练神经网络的过程中,优化器(optimizer)是必不可少的一部分。
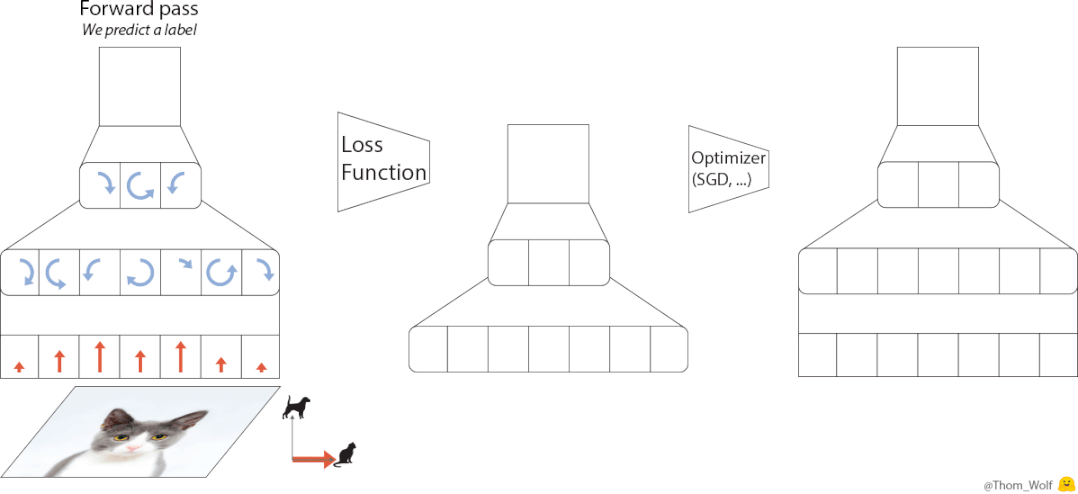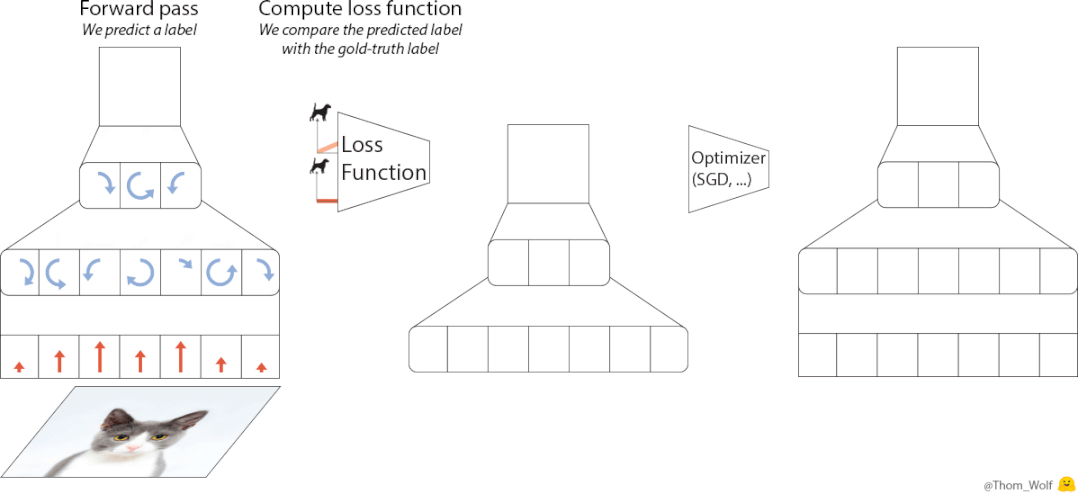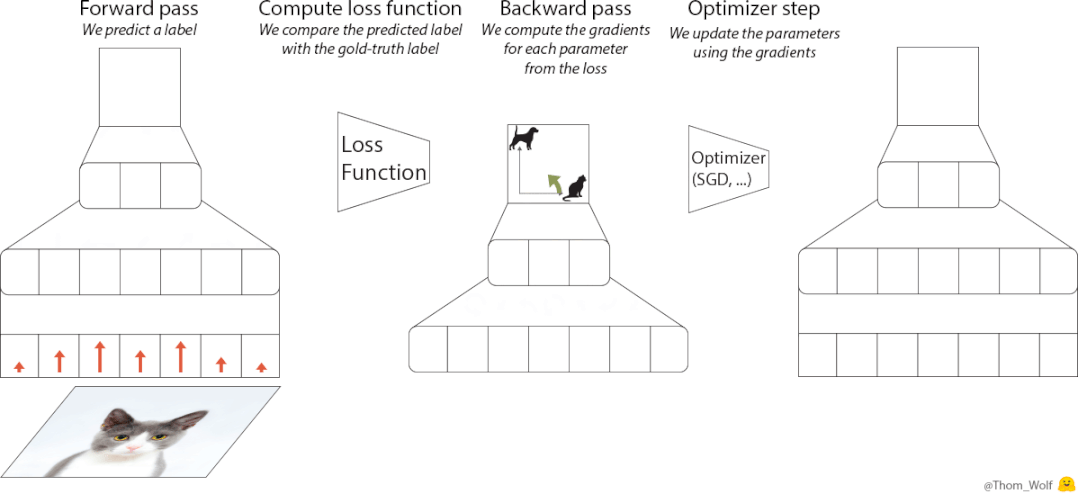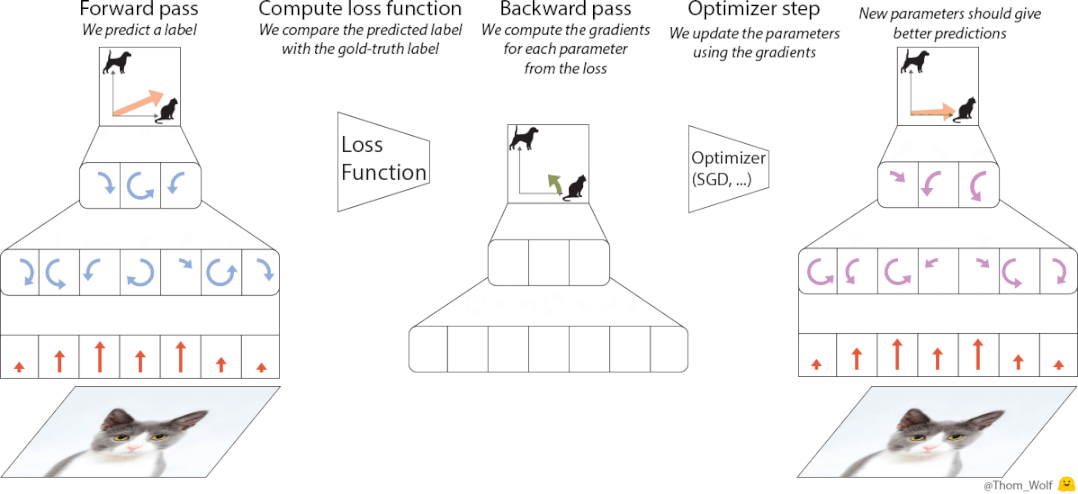
△神经网络训练过程,图源Thomas Wolf
但AI模型应用都这么广泛了,训练AI模型用的优化器却仍然是人工设计的,听起来多少有点不合理。

于是谷歌大脑的研究人员灵机一动:为何不用AI来做一个优化器呢?
设计上,优化器的原理基于元学习的思路,即从相关任务上学习经验,来帮助学习目标任务。
相比迁移学习,元学习更强调获取元知识,它是一类任务上的通用知识,可以被泛化到更多任务上去。
基于这一思想,VeLO也会吸收梯度并自动输出参数更新,无需任何超参数调优,并自适应需要优化的各种任务。
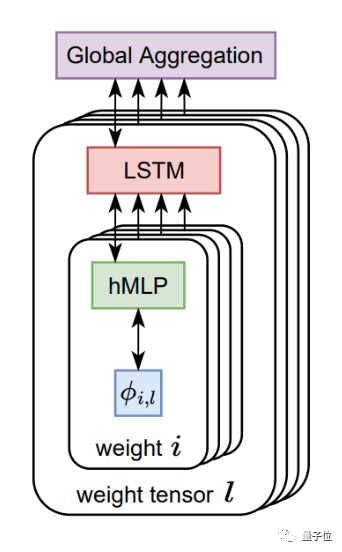
架构上,AI优化器整体由LSTM(长短期记忆网络)和超网络MLP(多层感知机)构成。
其中每个LSTM负责设置多个MLP的参数,各个LSTM之间则通过全局上下文信息进行相互协作。
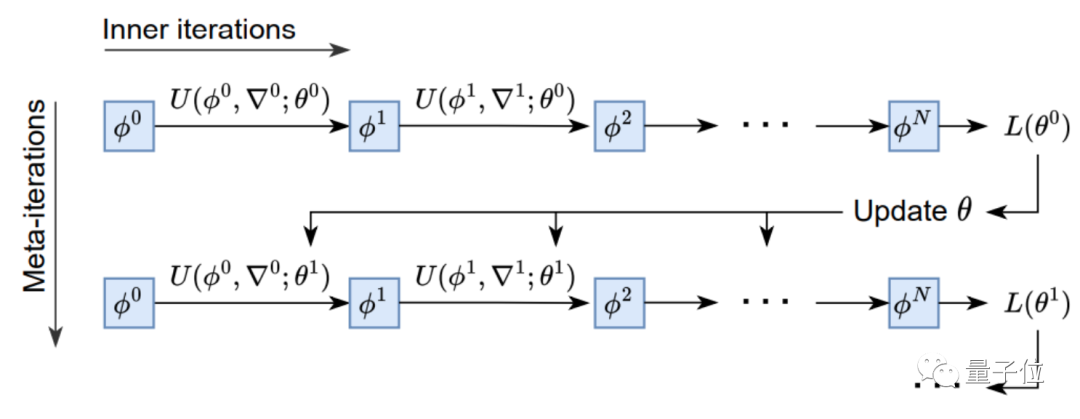
训练上,AI优化器采用元训练的方式,以参数值和梯度作为输入,输出需要更新的参数。
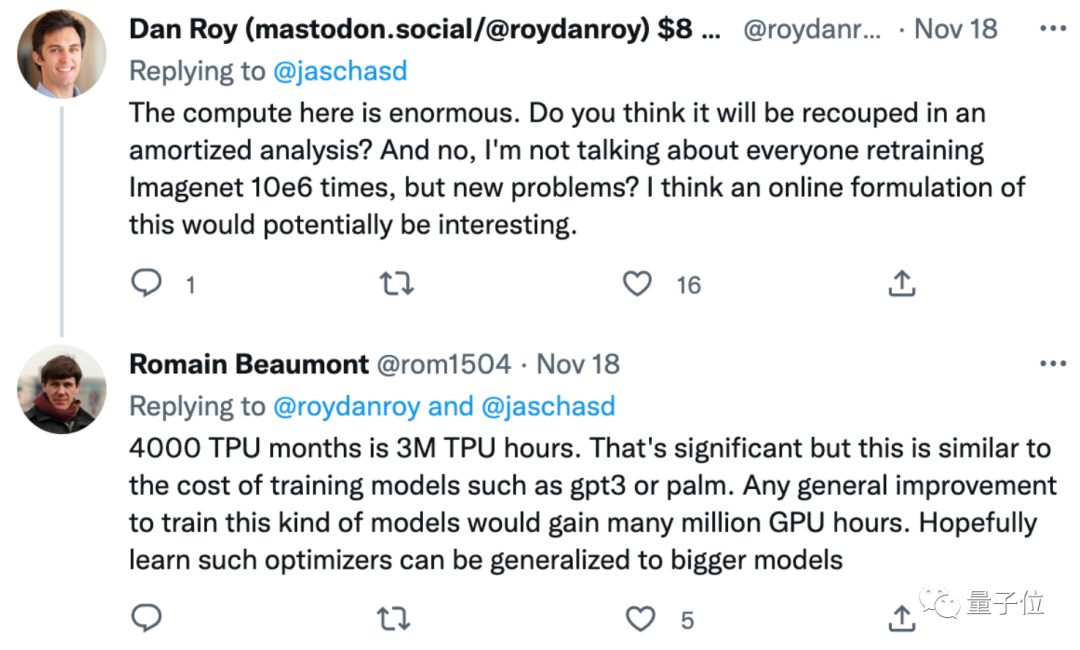
经过4000个TPU月(一块TPU运行4000个月的计算量)的训练,集各种优化任务之所长后,VeLO终于横空出世。
比人工调参优化器效果更好
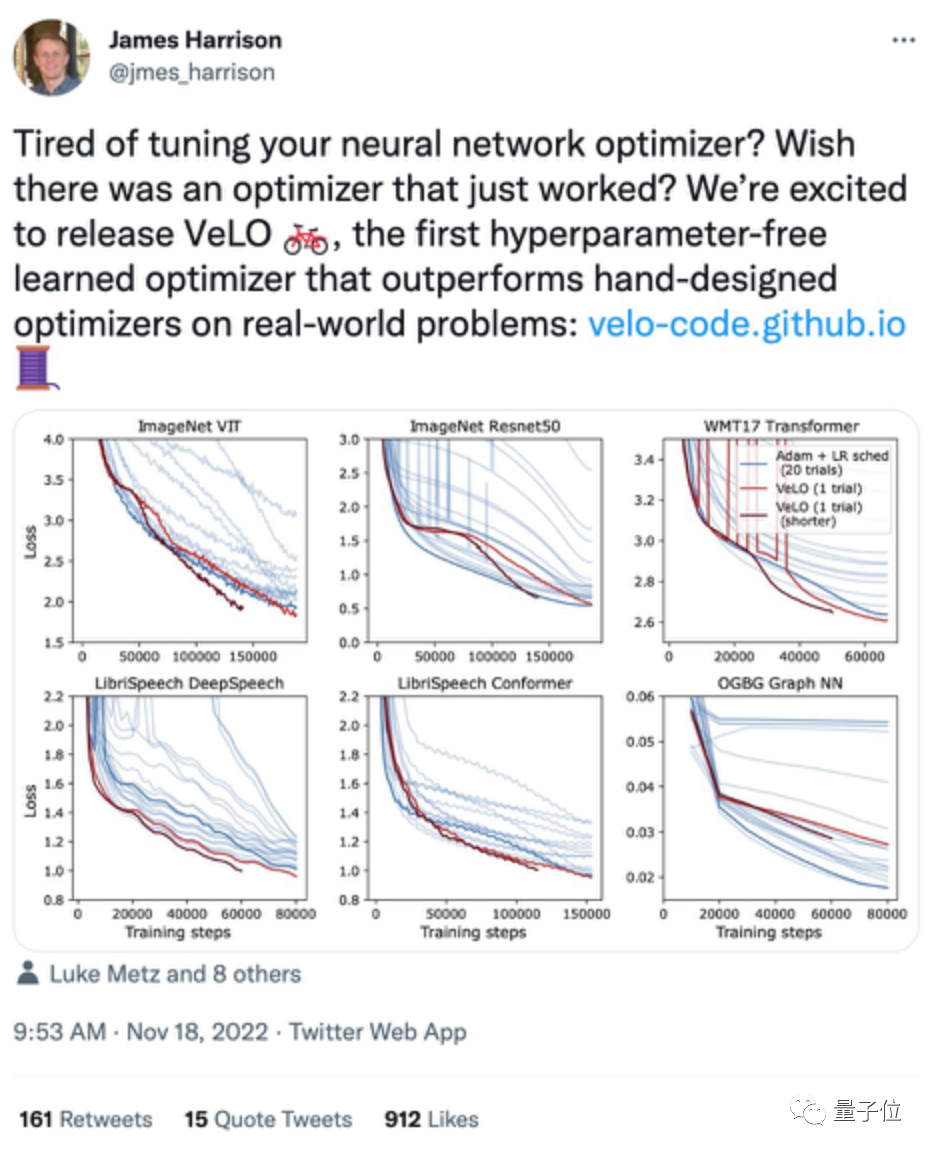
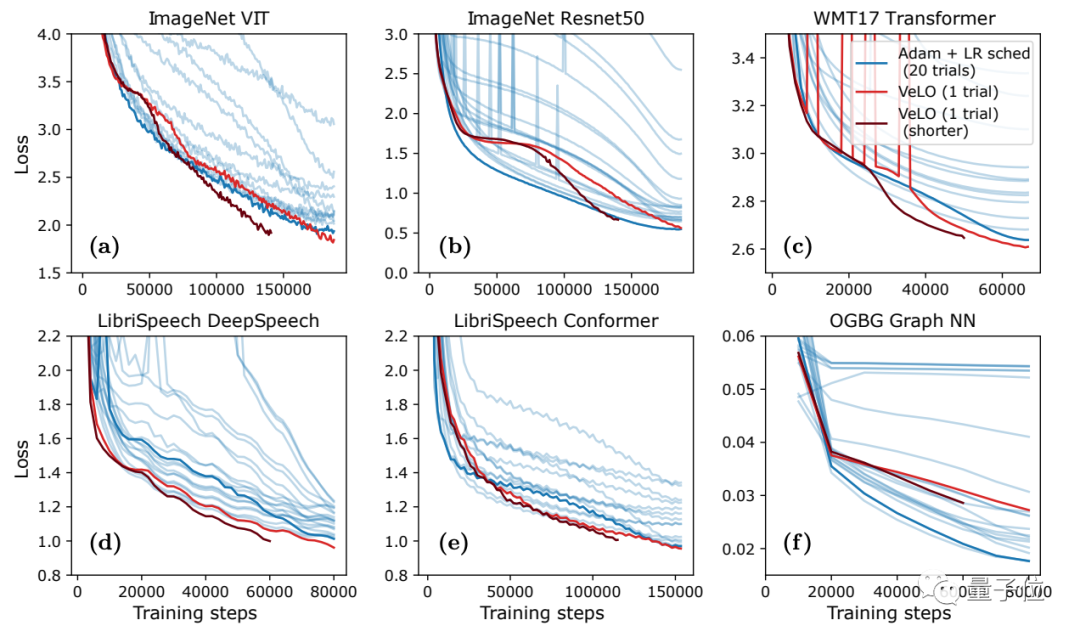
结果表明,VeLO在83个任务上的加速效果超过了一系列当前已有的优化器。
其中y轴是相比Adam加速的倍率,x轴是任务的比例。
结果显示,VeLO不仅比无需调整超参数的优化器效果更好,甚至比仔细调整过超参数的一些优化器效果还好:
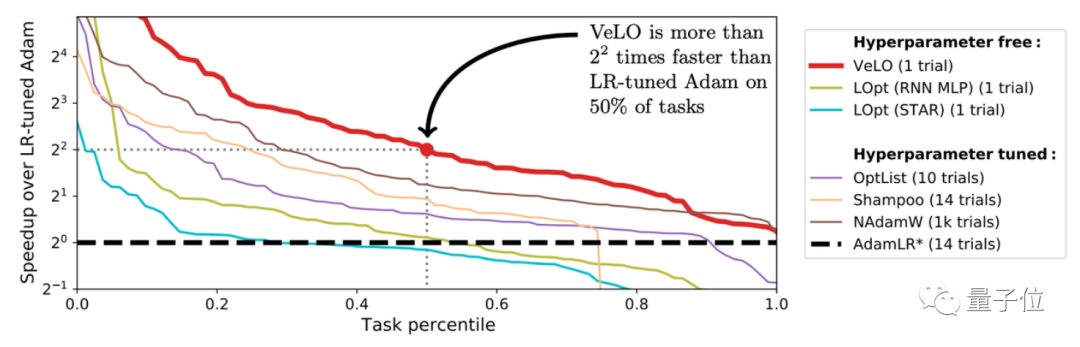
与“经典老大哥”Adam相比,VeLO在所有任务上训练加速都更快,其中50%以上的任务比调整学习率的Adam快4倍以上,14%以上的任务中,VeLO学习率甚至快上16倍。
而在6类学习任务(数据集+对应模型)的优化效果上,VeLO在其中5类任务上表现效果都与Adam相当甚至更好:
值得一提的是,这次VeLO也被部署在JAX中,看来谷歌是真的很大力推广这个新框架了。

巴特,也有网友认为耗费4000个TPU月来训练VeLO,计算量成本过大:
虽然这个进展很重要,但它甚至都快赶上GPT-3的训练量了。
目前VeLO已经开源,感兴趣的小伙伴们可以去试试这个新的AI优化器。
One More Thing
前段时间,一位哈佛博士生提了个有意思的想法,得到不少人赞同:
更多论文的作者们也应该像演职员表一样,公开自己在论文中的工作内容。

Kareem Carr是生物统计学领域的博士生,作者贡献在生物论文中比较常见,不过之前在AI论文中见得不多。
现在,这篇谷歌大脑论文的作者们也这样做了,谁写的论文、谁搭建的框架一目了然:

不知道以后会不会成为机器学习圈的新风气(手动狗头)。
GitHub地址:
https://github.com/google/learned_optimization/tree/main/learned_optimization/research/general_lopt
论文地址:
https://arxiv.org/abs/2211.09760
参考链接:
[1]https://twitter.com/jmes_harrison/status/1593422054971174912
[2]https://medium.com/huggingface/from-zero-to-research-an-introduction-to-meta-learning-8e16e677f78a#afeb
[3]https://mp.weixin.qq.com/s/QLzdW6CMkcXWQbGjtOBNwg
— 完 —
MEET 2023 大会定档!
首批嘉宾阵容公布
量子位「MEET2023智能未来大会」正式定档12月14日!
首批嘉宾包括郑纬民院士、MSRA刘铁岩、阿里贾扬清、百度段润尧、高通Ziad Asghar、小冰李笛、浪潮刘军以及中关村科金张杰等来自产学研界大咖嘉宾,更多重磅嘉宾陆续确认中。
点击“预约”按钮,一键直达大会直播现场!
点这里关注我 👇 记得标星噢 ~



