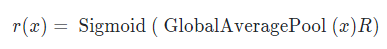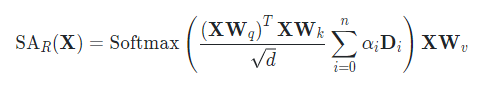![]()
©PaperWeekly 原创 · 作者 | 小马
单位 | FightingCV公众号运营者
研究方向 | 计算机视觉
写在前面
动态神经网络(Dynamic Network)是目前非常热门也非常具有落地价值的一个研究方向,因为相比于固定结构和参数的静态神经网络,动态神经网络能够根据根据不同的输入样本,自适应的为样本分配最合适的路径,因此动态网络往往比静态网络具有更高的精度、计算效率 ,受到了广大学术研究者和算法工程师的欢迎。
下面,在这篇文章中,我们将会详细介绍,在不同领域近几年动态网络的发展历程!
![]()
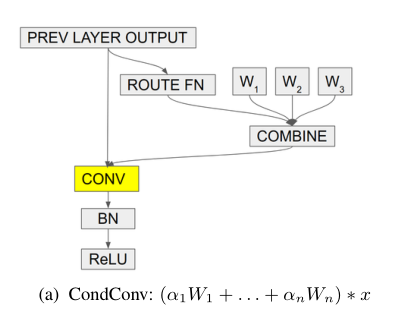
2.1 CondConv
![]()
论文标题:
CondConv: Conditionally Parameterized Convolutions for Efficient Inference
NeurIPS 2019
https://arxiv.org/abs/1904.04971
PyTorch代码:
https://github.com/xmu-xiaoma666/External-Attention-pytorch#5-CondConv-Usage
2.1.1 论文动机
这篇文文章的动机非常简单,目前增加模型容量的成本非常高,通常是增加网络的深度和宽度。通过增加了网络的深度和宽度,模型的参数量和计算量也会成倍的增长,这对于一些边缘设备的部署是非常不友好的。
作者发现,在卷积神经网络中,不论输入的样本是什么,相同的卷积核都作用于这些样本,这可能是次优的,因此,作者在本文中希望能够根据输入的样本,动态选择卷积核,从而提高模型的容量 。
具体来说,作者在设计的时候并行的设置了多个卷积核,然后设计了一个聚合函数,这些聚合函数能够根据输入的样本来动态聚合这些卷积核。由于只进行一次卷积,因此多出来的计算量其实只有计算量不同卷积核权重和聚合卷积核过程中产生的计算量,而这部分计算量相比于卷积的计算量其实是非常小的。
如上图所示 ,在 ConvCond 中,每一个卷积层中有多个卷积核,作者为每一个卷积核分配了不同的权重,然后根据权重,将这些卷积核进行求和,得到最终的“动态卷积核”。对于“权重生成函数”,作者选用了一个非常简单的操作,即先将输入样本的空间维度进行 pooling,然后用全连接层降维到卷积核的数量,最后用 Sigmoid 函数求权重,如下所示:
![]()
论文标题:
Dynamic Convolution: Attention over Convolution Kernels
CVPR 2020 (Oral)
https://arxiv.org/abs/1912.03458
https://github.com/xmu-xiaoma666/External-Attention-pytorch#4-DynamicConv-Usage
2.2.1 论文动机
![]()
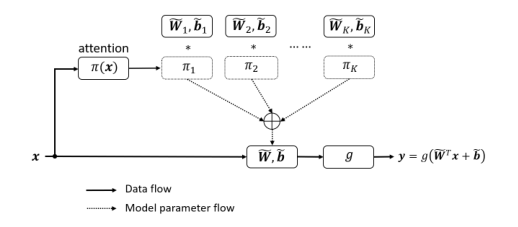
上图为目前动态卷积的示意图,能够将多个卷积核根据不同的输入样本以不同的权重进行聚合。但是作者发现,目前的动态卷积神经网络在优化上有一定的困难,因为他需要对所有的卷积核进行联合优化,势必会导致优化效率低下。
因此在本文中,作者提出了两个点来提高动态卷积的优化效率:1)让同一层所有卷积核权重的和为1 ;2)在训练早期能够尽可能优化每一个卷积核,使得所有卷积核都能被训练 。
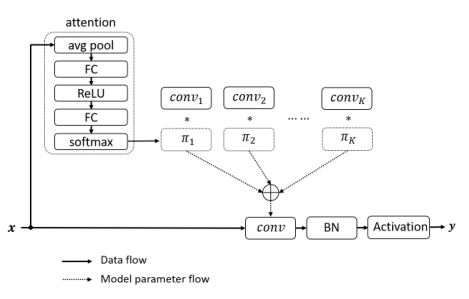
2.2.2 实现方法
![]()
本文的模型结构如上图所示,总体上来说和 CondConv 的结构非常像。但是作者根据上面提出的提高优化效率的两个点,对“权重生成函数”进行了更改。首先,为了让同一层所有卷积核权重为 1,作者将 CondConv 中的 Sigmoid 换成了 Softmax;其次,为了能够在训练早期能够尽可能训练好每一个卷积核,即权重尽可能平均,作者将 Softmax 中的温度参数变大,实验也表明,早期用更大的温度参数,然后逐渐降低温度参数能够达到更好的实验性能。
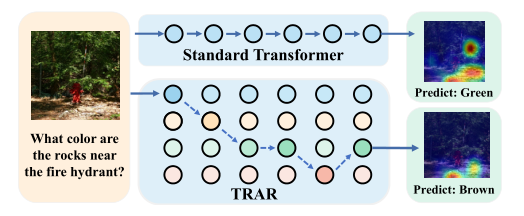
2.3 TRAR
![]()
论文标题:
TRAR: Routing the Attention Spans in Transformer for Visual Question Answering
ICCV 2021
https://openaccess.thecvf.com/content/ICCV2021/papers/Zhou_TRAR_Routing_the_Attention_Spans_in_Transformer_for_Visual_Question_ICCV_2021_paper.pdf
https://github.com/rentainhe/TRAR-VQA/
2.3.1 论文动机
目前,Transformer 只能感知全局感受野,而对于像 VQA 和 REC 这样任务,捕获局部的对象对于最终模型的推理也是非常重要的,但是对于不同目标,需要配备不同大小的感受野。而直接配置多感受野的 Transformer 会导致计算量和显存的骤增。
因此,作者在本文中提出了动态路由方案,能够根据不同样本输入,来自适应的选择感受野,并且选择感受野的方法通过 mask 来实现,因此每一层只需要计算一次 Self-Attention,计算非常轻量级。
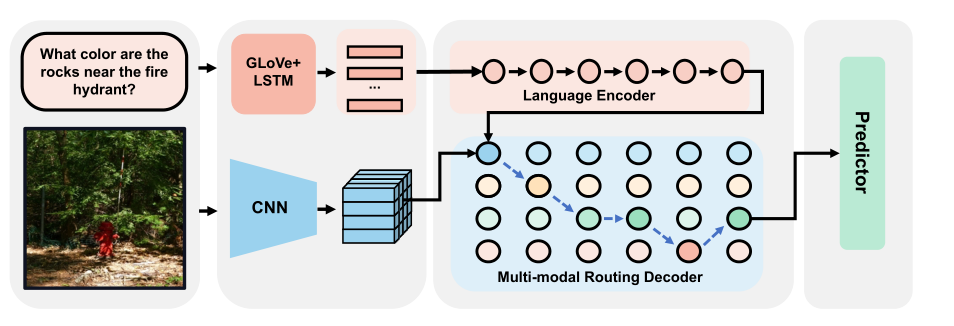
如上图所示,作者首先对图像和文本进行编码,然后图像信息在进行 Self-Attention 的时候,用不同的 mask 来限制不同的感受野大小。由于有多个感受野,每个感受野有其特定的权重,因此,动态 Self-Attention 的计算可以表示如下:
![]()
在计算每条路径的权重时,作者也是采用了类似 SENet 的方法先进行空间上的 pooling,然后用 MLP 和 Softmax 获得每条路径的权重:
![]()
由于作者在本文中并没有进行多次 Self-Attention,引入的计算量只是聚合 mask 和计算 mask 权重的计算量,因此是一个轻量级的动态网络。
论文标题:
Learning Dynamic Routing for Semantic Segmentation
CVPR 2020 (Oral)
https://arxiv.org/abs/2003.10401
https://github.com/Megvii-BaseDetection/DynamicRouting
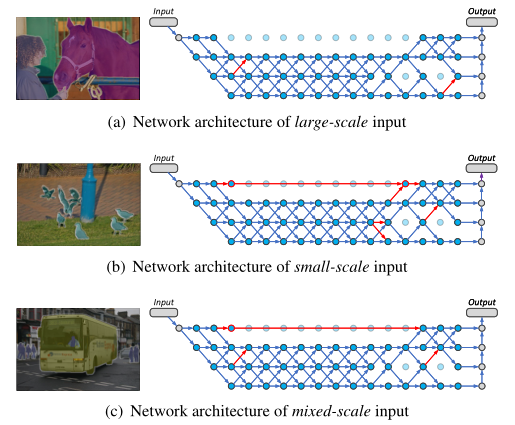
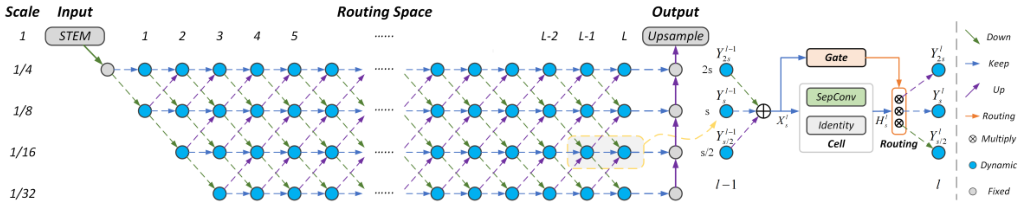
语义分割是一个对图像大小的分辨率非常敏感的任务,对于小目标,需要用较大的分辨率对其进行处理;对于大目标,可以使用相对较小的分辨率减少计算量。但是目前无论是 NAS 和手工设计的网络,对于所有的样本都采用了相同的处理方式,因此分辨率的变化都是相同的。为了能够让网络能够感知不同尺度分布的图片,作者采用了动态路由的思想,让网络能够根据图片的内容,在网络中自适应的根据图片的内容进行图像分辨率的调整,从而达到较高的计算效率和计算性能 。
本文的结构如上图所示,作者首先用一个 STEM 层降低图片的分辨率,然后在后面的网络都都设置了四个候选分辨率,图片能够根据当前的输入特征来动态选择是保持当前分辨率还是增大或者缩小分辨率。
由于较大的分辨率可以达到更好的性能,因此网络在训练时可能会尽可能选择更大的分辨率,从而造成计算性能的浪费。为了达到更好的 trade-off,作者在损失函数中加了一项计算资源的约束,使用模型在计算资源和性能上达到更好的平衡。
2.5 DRConv
论文标题:
Dynamic Region-Aware Convolution
CVPR 2021
论文地址:
https://arxiv.org/abs/2003.12243
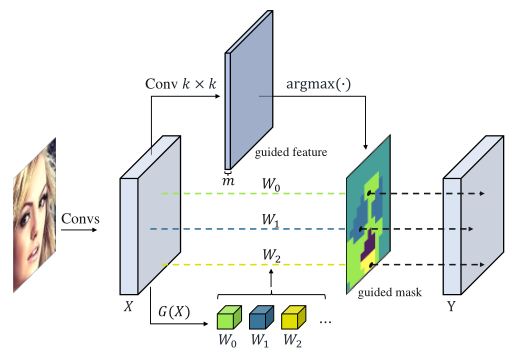
之前的静态卷积网络,对于样本的每一个像素都采用了相同的卷积核,导致模型容量较低;为了克服这个缺点,有一些工作提出为每一个像素采用不同的卷积,这会造成两个问题:第一,参数量的骤增;第二,失去了平移不变性。为了能够兼顾这两者的优点,如上图所示,作者采用了动态网络的思想,首先根据输入的特征生成几个候选卷积核,然后根据每个像素的内容,动态为每个像素位置,选择最合适的卷积核 。
文章的大致思想就是,根据输入的特征,利用卷积来生成 guided mask,然后根据这些 guided mask 来为不同的像素位置选择卷积核。
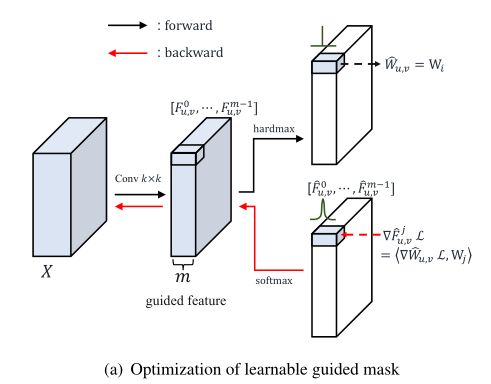
由于在生成 mask 的时候用到了 argmax,导致这一步是不可微的。为了得到这一步的导数,作者采用了 softmax 来模拟了 argmax 的导数,使得反向传播可以进行。
![]()
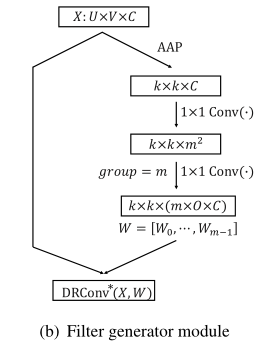
在本文中,这些候选卷积核也是根据输入样本动态生成的,生成方式如上图所示,首先进行 Average Pooling,然后用卷积生成更高维度的特征,最后用 reshape 为多个卷积核。
2.6 RANet
论文标题:
Resolution Adaptive Networks for Efficient Inference
CVPR 2020
https://arxiv.org/abs/2003.07326
代码地址:
https://github.com/yangle15/RANet-pytorch
2.6.1 论文动机
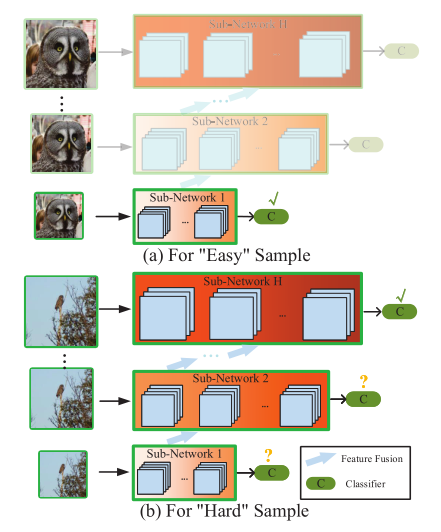
目前静态的网络对于不同难度的样本都分配了相同的计算量,这就会导致对简单样本分配太多计算资源,造成浪费;对困难样本分类了太少的计算量,导致精度太低。
为了解决这个问题,作者提出了自适应分辨率网络 RANet,在这个网络中,模型首先会用一个小网络对样本用小分辨率进行分类,如果置信度足够高,则退出网络;否则将输出特征和更大分辨率的图片输入到下一个网络中,直到经历过了所有网络或者置信度足够高,则退出网络。
这样,简单样本就可以占用更少的计算资源,而复杂样本会占用更多的计算资源,并且小分辨率的计算结构能够用于下一个子网的进一步计算量,不会浪费。
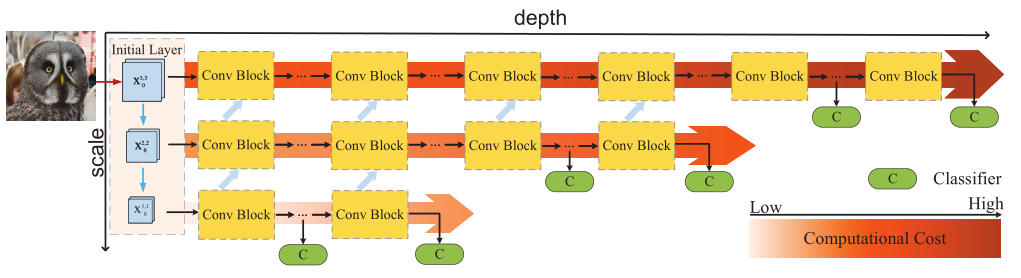
本文的大致结构如上图所示,网络分为多个分辨率的子网,每个分辨率子网中有多个分类器,如果低分辨率的分类器达到足够高的置信度则退出网络,节省计算量;否则继续用更高的计算量处理,直到置信度更高,或者经过了所有网络。
![]()
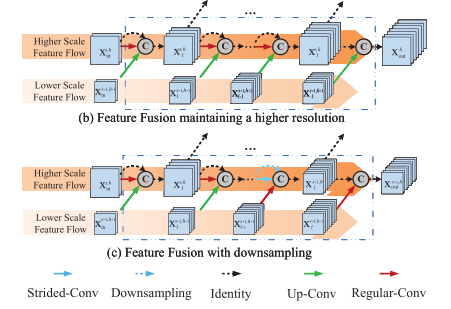
每个子网的结构如上图所示,当前模块生成的特征除了输入到下一个模块,还会输入到更高的分辨率中,从而重复利用特征,充分利用计算资源。
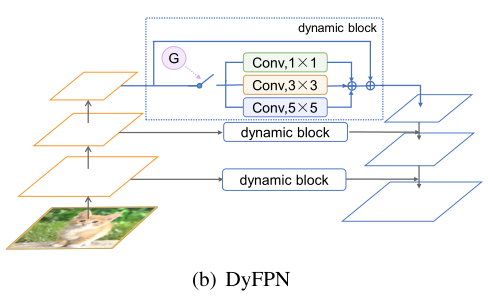
2.7 DyFPN
![]()
论文标题:
Dynamic Feature Pyramid Networks for Object Detection
https://arxiv.org/abs/2012.00779
代码地址:
https://github.com/Mingjian-Zhu/DyFPN
2.7.1 论文动机
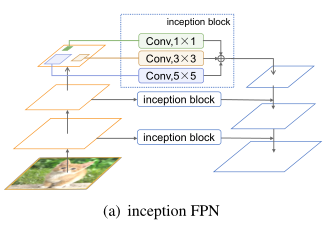
对于目标检测来说,感知多尺度的信息是非常重要的,因此作者尝试将 Inception 结构加入到了 FPN 中,但是 Inception FPN 在每一次计算中都会用到所有的卷积,导致计算效率非常低。因此,为了提高计算效率,作者借鉴了动态网络的思想,在每次前向传播的时候,根据输入样本的信息来动态选择用哪个卷积进行处理。
本文的结构如上图所示,由三个部分组成:Inception 结构,动态 gate 和残差连接。Inception 结构用于构建多尺度建模的路由空间;动态 gate 用于生成路由信号。由于这里在前向传播的时候只能选择一个卷积核,因此作者也采用了 Gumbel Softmax Trick,来解决 argmax 不能求梯度的问题。另外,为了平衡计算量和性能直接的平衡,作者也像《Learning Dynamic Routing for Semantic Segmentation》一样,在损失函数中加了一项用于限制计算量的子项。
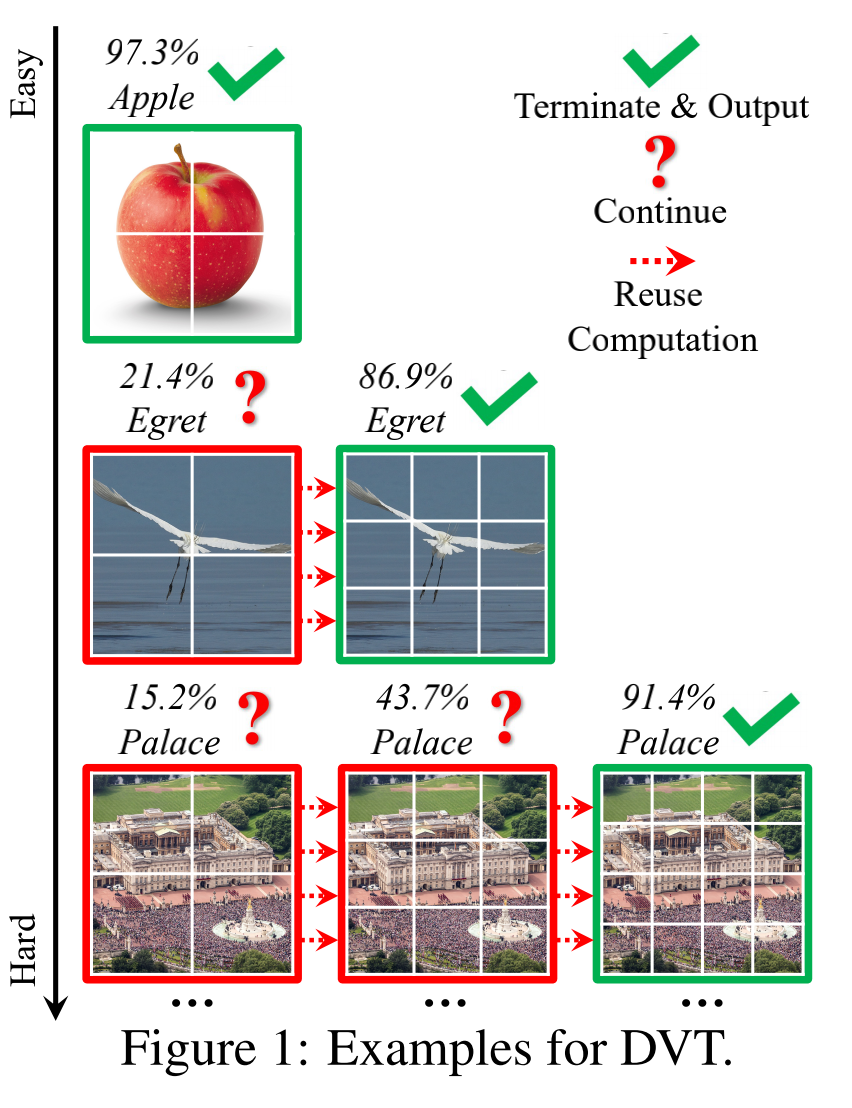
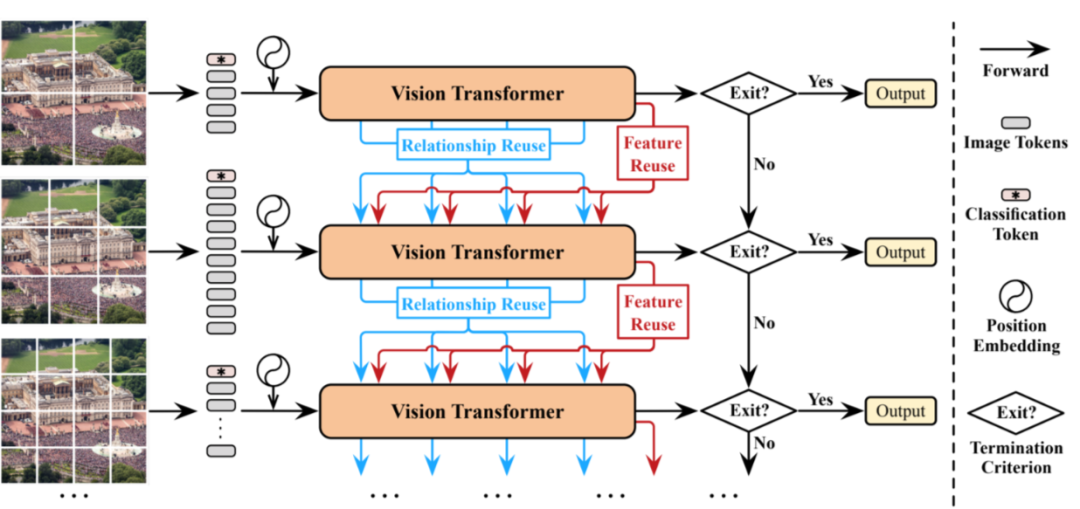
2.8 Dynamic Vision Transformers
![]()
论文标题:
Not All Images are Worth 16x16 Words: Dynamic Vision Transformers with Adaptive Sequence Length
NeurIPS 2021
https://arxiv.org/abs/2105.15075
代码地址:
https://github.com/blackfeather-wang/Dynamic-Vision-Transformer
2.8.1 论文动机
在 ViT 中,对于所有样本都采用了 14x14 个 patch,没有区分样本的难度。但是对于简单样本,这样分 patch 的方法可能太奢侈了,对于复杂样本,这样的分 patch 可能不够精细。 因此为了达到更高的性能和更高的计算效率,作者借鉴了动态网络的思想,根据样本的难度,来动态分配 patch 的分割方式。
![]()
这篇文章的总体设计思想和黄高老师的《Resolution Adaptive Networks for Efficient Inference》很像,首先先用粗粒度的方式进行分 patch,然后输出到 Vision Transformer 中,根据置信度判断是否要退出,如果置信度没有达到标准,那么就将处理结果和更细粒度分 patch 的图片输入到下一个 ViT 中,直到满足置信度要求,或经过了所有网络为止。
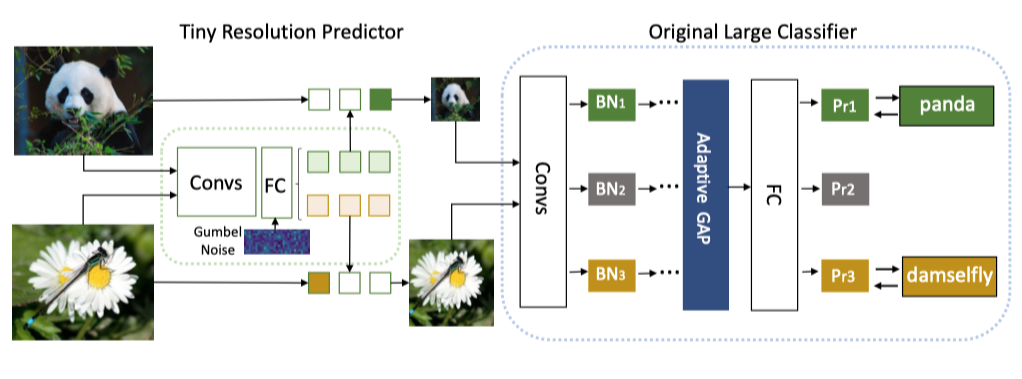
2.9 Dynamic Resolution Network
![]()
论文标题:
Dynamic Resolution Network
NeurIPS 2021
论文地址:
https://arxiv.org/abs/2106.02898
2.9.1 论文动机
![]()
这篇文章的 Motivation 和《Resolution Adaptive Networks for Efficient Inference》相似,作者认为不同样本应该以不同分辨率处理,简单样本的分辨率可以较小一些,复杂样本的分辨率可以较大一些 ,从而达到更好的计算量和模型性能之间的平衡。
本文的模型结构如上图所示,主要由两部分组成:用于预测输入样本分辨率的分辨率预测器和用于分类的基础网络。首先分辨率预测器用一个非常简单的网络对不同的样本生成合适的分辨率结果,并根据这个分辨率结果,将输入的图片 resize 到相应的大小,然后将 resize 之后的图片输入到基础网络中,这些图片具有不同的分辨率。
由于不同分辨率的图片通常具有不同的统计量,为了能够适应不同分辨率的训练,作者在基础网络中设置了多个 BN,每个 BN 对应一个候选分辨率,从而能够在不引入太多计算量和参数量的情况下,考虑不同分辨率的数据分布。
总结
目前,动态网络的研究非常火热,已经渗透到了各个任务中,并且也达到了非常好的效果,尤其是在平衡计算量和性能方面展现出了非常高的水平。相信在将来,动态网络除了能够成为更高效的网络之外,还能促进其他方向的发展。比如,对于多任务,根据目标任务来动态选择网络等等。
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()