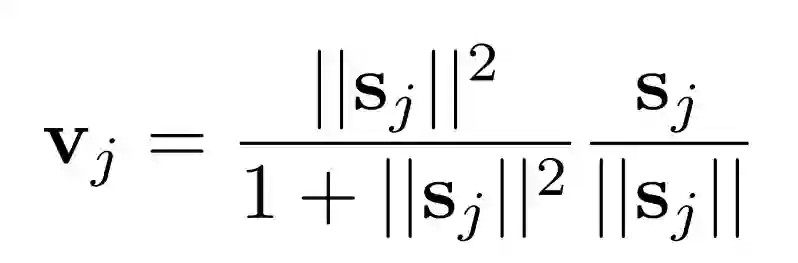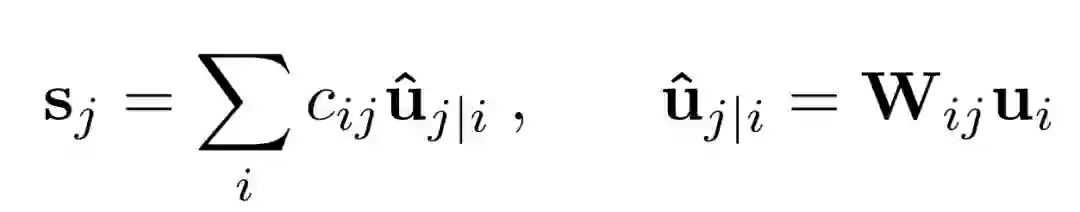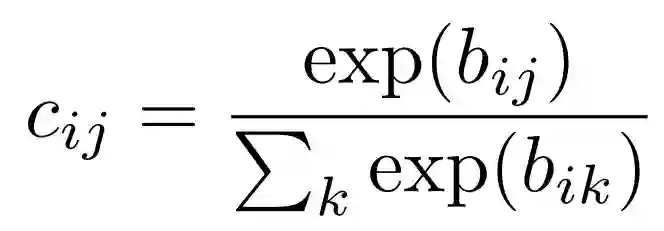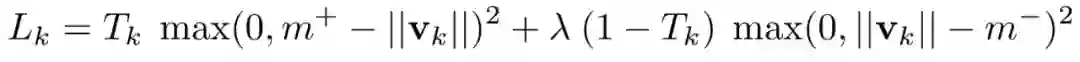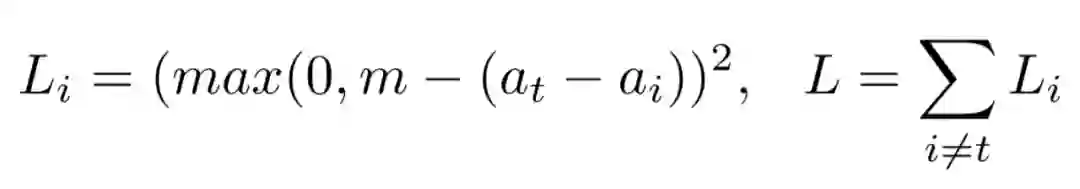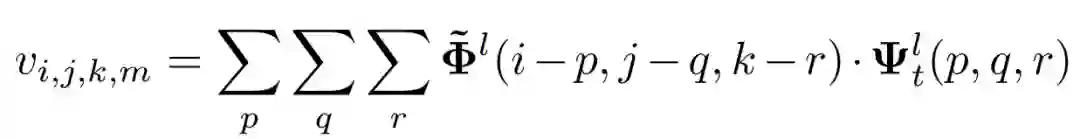本文以综述的形式,尽可能详细的向读者介绍胶囊网络的诞生,发展过程与应用前景。本文的内容以 Hinton 的标志性文章为基础,结合近年来发表在顶会顶刊的文章为补充,力图详细的让读者们了解胶囊网络的各种版本,熟悉它在不同领域的革命性突破,以及它在目前所存在的不足。
深度学习和人工神经网络已经被证明在计算机视觉和自然语言处理等领域有很优异的表现,不过随着越来越多相关任务的提出,例如图像识别,物体检测,物体分割和语言翻译等,研究者们仍然需要更多有效的方法来解决其计算量和精度的问题。在已有的深度学习方法中,卷积神经网络 (Convolutional Neural Networks) 是应用最为广泛的一种模型。卷积神经网络通常简称为 CNN,一般的 CNN 模型由卷积层 (convolutional layer), 池化层(pooling layer) 和全连接层 (fully-connected layer) 叠加构成。
在卷积的过程中,卷积层中的卷积核依次与输入图像的像素做卷积运算来自动提取图像中的特征。卷积核的尺寸一般小于图像并且以一定的步长 (stride) 在图像上移动着得到特征图。步长设置的越大,特征图的尺寸就越小,但是过大的步长会损失部分图像中的特征。此外,池化层也通常被作用于产生的特征图上,它能保证 CNN 模型在不同形式的图像中能识别出相同的物体,同时也减少了模型对图像的内存需求,它最大的特点是为 CNN 模型引入了空间不变性(spatial invariance)。
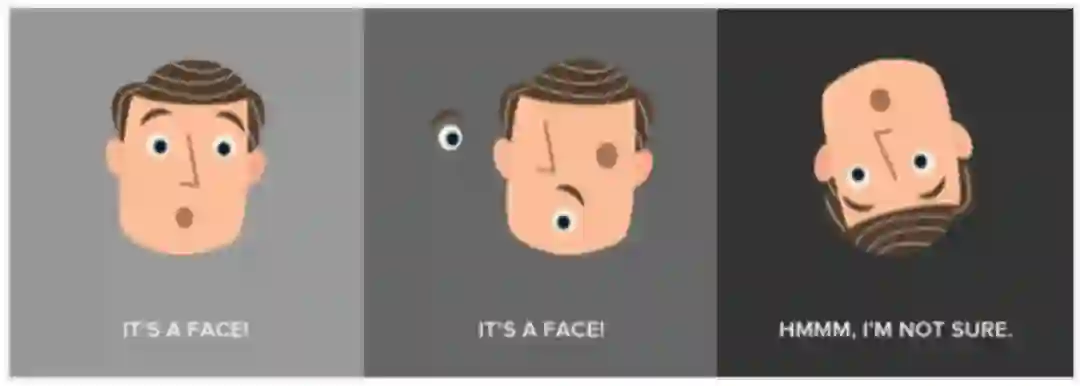
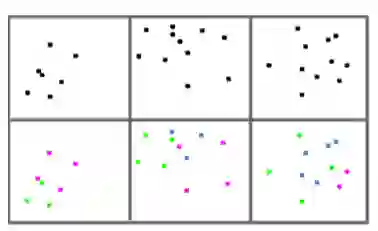
虽然 CNN 模型的提出取得了显著的成果并解决了许多问题,但是它在某些方面还是存在许多缺陷。CNN 最大的缺陷就是它不能从整幅图像和部分图像识别出姿势,纹理和变化。具体来说,由于 CNN 中的池化操作使得模型具有了空间不变性,因此模型就不具备等变(equivariant). 如下图所示,CNN 会把第一和第二幅图都识别为人脸,而把第三幅方向翻转的图识别为不是人脸。另外,池化操作使得特征图丢失了很多信息,它们因此需要更多训练数据来补偿这些损失。就特点上而言,CNN 模型更适合那些像素扰动极大的图像分类,但是对某些不同视角的图像识别能力相对较差。
![]()
图 1. 识别示意图。图源:https://www.spiria.com/en/blog/artificial-intelligence/deep-learning-capsule-network-revolution/
因此,在 2011 年,Hinton 和他的同事们提出了胶囊网络 (CapsNet) 作为 CNN 模型的替代。胶囊具有等变性并且输入输出都是向量形式的神经元而不是 CNN 模型中的标量值 [1]。胶囊的这种特征表示形式可以允许它识别变化和不同视角。在胶囊网络中,每一个胶囊都由若干神经元组成,而这每个神经元的输出又代表着同一物体的不同属性。这就为识别物体提供了一个巨大的优势,即能通过识别一个物体的部分属性来识别整体。
胶囊的输出通常为某个特征的概率及特性,这个概率和特性通常被叫做实例化参数。而实例化参数代表着网络的等变性,它使得网络能够有效的识别姿势,纹理和变化。比如,如果用 CNN 模型去识别一张脸,模型会将一张眼睛和鼻子位置颠倒的图片识别为人脸,但是,胶囊网络的等变性会保证特征图中位置的信息,因此,具有等变性的胶囊网络会在识别人脸时不仅考虑眼睛鼻子的存在,还会考虑它们的位置。Hinton 首先提出了胶囊网络的基础概念, 然后其余的作者又在此基础上做了其他的改进和应用。接下来的章节,我会对多个版本的胶囊网络进行详细的介绍。
(1) Transforming Auto-encoders
![]()
第一个被发表的胶囊网络即为 Transforming Auto-encoders [2]。它的提出是为了增加网络识别姿态的能力,其主要目标不是在图像中做物体识别,而是从输入图像中提取姿态然后以原始姿态输出变换后的图像。在这篇文章中,向量形式的胶囊首次被提出,其输出的向量既代表特征存在的概率又含有实例化参数。
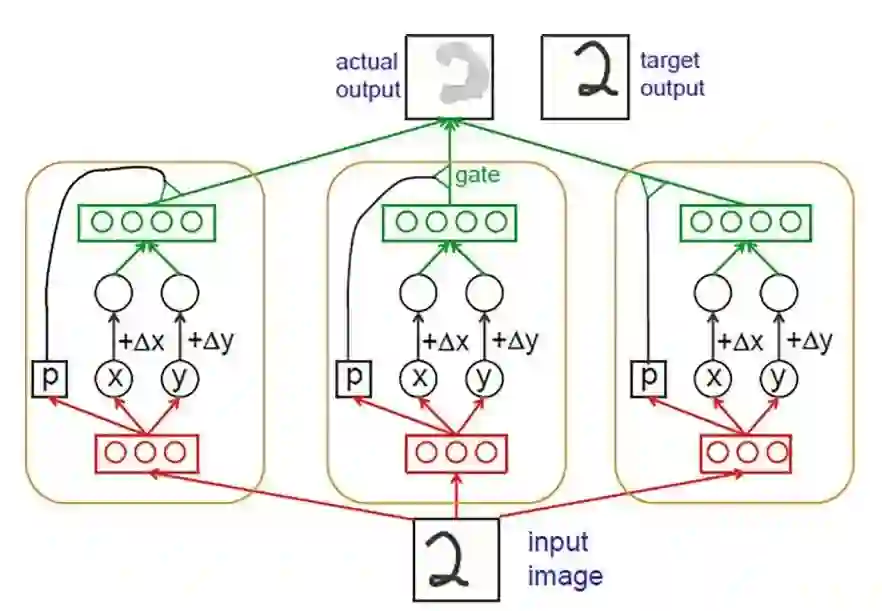
同时,胶囊也可分为不同的层级:低层 l 的可以叫做初级胶囊,高层 l+1 的可以叫做高层胶囊。低层胶囊从像素中提取姿态参数并且创建一个部分 - 整体的层次结构。这种部分 - 整体的层次结构是胶囊网络的一个优点,通过对其部分的识别,可以得到对整体的识别。要做到这一点,低级别胶囊所代表的特征必须具有正确的空间关系,才能在 l +1 层激活高级别胶囊。例如,让眼睛和嘴巴用较低水平的胶囊表示,如果他们的预测一致的话,一个胶囊代表人脸的高水平胶囊的会被激活,从而模型能做出正确的判断。Hinton 在 2011 年的论文中介绍了这种方法的一个简单例子,如图 2 所示。
![]()
图 2. Auto-encoder Capsule structure (Hinton et al., 2011).
作者用一个使用二维图像和输出仅为 x 和 y 胶囊的简单例子来解释这个网络的工作流程。网络一旦确定并且完成学习过程,网络将同时获取一幅图像和所需的位移 Dx 和 Dy,之后网络就可以输出具有指定位移的目标图像。该网络由许多独立的胶囊组成,它们会在最后一层相互融合生成有位移的图像。每个胶囊都有自己的逻辑 “识别单元”(图 2 中的红色部件),作为计算三个数字 x, y, 和 p 的隐藏层,这些被称为“识别单元” 的初级胶囊会将信息送到更高层次胶囊中。
其中输出 p 表示特征在胶囊中的概率。胶囊也有自己的 “生成单元”(图 2 中的绿色) 用于计算该胶囊对变换图像的贡献。如图所示,“生成单元”的输入为 x+Dx 和 y+Dy,“生成单元”对输出图像的贡献乘以 p,而那些不活动的胶囊则对输出图像没有影响。auto-encoder 之所以能产生正确的输出图像,关键在于每个活动胶囊所计算的 x 和 y 值都对应着实体本身实际的 x 和 y 的位置,因此,我们就大可不必事先非得知道这个实体本身的坐标原点。
为了演示这个方法的有效性,作者训练了一个有 30 个胶囊的网络,每个胶囊都有 10 个识别单元和 20 个生成单元。每个胶囊都能看到 MNIST 数字集的整体。输入和输出图像都分别在 x 和 y 方向上随机位移 - 2,-1,0,1,2,并且网络还将 Dx,Dy 作为了附加输入。
![]()
图 3. 上图:最上一行是输入图片;中间一行是输出图片;最下一行是变换正确的图片。下图:前 7 个胶囊的前 20 个生成单元的输出权值 (Hinton et al., 2011)。
此外,如果每个胶囊有 9 个实数输出,那这些输出可以被看做 3*3 的矩阵,那么网络就可以用来完成二维仿射变换(平移,旋转,缩放和剪切)。使用矩阵乘法的另外一个优势是,它会使得处理 3D 图像变得更加容易。于是作者做了初步试验来衍生至计算机图形学,实验也取得了不错的效果,如下图所示。
![]()
图 4. 左:训练数据的输入,输出和目标立体;右:训练数据中无样本车型的输入,输出和目标立体 (Hinton et al., 2011)。
(2) Dynamic routing between capsules
![]()
2017 年,下一个版本的胶囊网络被提出,它定义了一个胶囊为一组具有实例参数的神经元,这些神经元代表着活跃的向量,向量的长度表示特征存在的概率 [3]。在一个活跃的胶囊内的神经元的活动代表了存在于图像中一个特征的实体。这些属性可以包括许多不同类型的实例化参数如姿态 (位置,大小,方向),变形,速度,反照率,色调,纹理等。向量输出的长度通过施加一个矢量运算使得它的胶囊的方向保持不变,但是长度为单位长度,目的是为了缩小了它的规模。因为一个胶囊的输出是一个矢量,这让使用强大的动态路由使得信息在胶囊间传输变得可能。
在路由过程中,输出矢量被路由到所有可能的父节点,并且这些矢量通过乘以总和为 1 耦合系数缩小了尺度。对于每一个可能的父结点,胶囊通过自己的输出和一个权值矩阵相乘计算出一个“预测向量”。如果该预测向量与父结点的输出有较大的标量积,那么自顶向下的反馈结构就会增加了父节点的耦合系数而减少其他父节点的压力。这样的反馈机制进一步增加了胶囊的预测向量和父节点输出的标量积,从而增加了胶囊的贡献。这种“routing-by-agreement” 的方式应该比最原始的最大池化实现路由的形式要有效得多。
这个版本的胶囊网络相比上一个最大的改进是不再需要姿态数据作为输入,它主要由卷积层 (Convolutional layer),初级胶囊层 (Primary capsule layer) 和分类胶囊层 (Class capsule layer) 组成。卷积层使用特征学习检测器的版本,这在图像解释中被证明是十分有用的。初级胶囊层是第一层胶囊层,分类胶囊层为最后一个胶囊层。输入图像的特征提取是由卷积层来完成,随后提取的特征被送入初级胶囊层。
虽然我们用矢量输出胶囊和“routing-by-agreement” 取代 CNNs 的标量输出和 max-pooling,我们仍然希望在不同空间中提取我们所学到的知识。对于初级胶囊,有关位置信息的 “位置编码” 胶囊是活跃的。随着胶囊等级的上升,越来越多的位置信息被 “速率编码” 包含在胶囊输出向量的实值分量中。这种从 “位置编码” 到“速率编码”的转变,还有高级胶囊包含更复杂的实体和拥有更多的自由度共同表明了胶囊的维度应该随着深度逐渐增加。
这个版本最重要的就是动态路由的提出。首先,我们想要一个胶囊的输出向量的长度来表示这个实体在胶囊中存在的概率。因此我们使用非线性的 “squashing” 函数,以确保向量归一化到 0 和 1 之间。
![]()
具体来说,每个在初级胶囊层 l 的胶囊为 ui, 它将空间信息编码到实例化的参数中,ui 的输出被送入下一层 l+1, 下一层有 j 个胶囊。由 ui 变换到 uj 根据了相对应的权值矩阵 Wij. sj 是所有初级胶囊输出 j 的权值总和,vj 是压缩 (squashing) 后的值,这个压缩函数确保输出的长度在 0 和 1 之间。cij 是耦合系数,它保证了来自 l 层的 i 个胶囊连接到 l+1 层的 j 个胶囊。在每次迭代中,cij 会不断被 bij 更新。其过程和伪代码如下图:
![]()
![]()
![]()
图 5. Dynamic routing between capsules (Sabour et al., 2017)
在高级胶囊中,当该数字出现在图像里,类数字 k 就会有有一个很长的实例化向量。在文章里,一个边缘损失函数被提出,其表达式如下
![]()
这里 Tk=1, m+=0.9 并且 m-=0.1,系数为 0.5,总损失就是所有数字胶囊损失函数的总和。
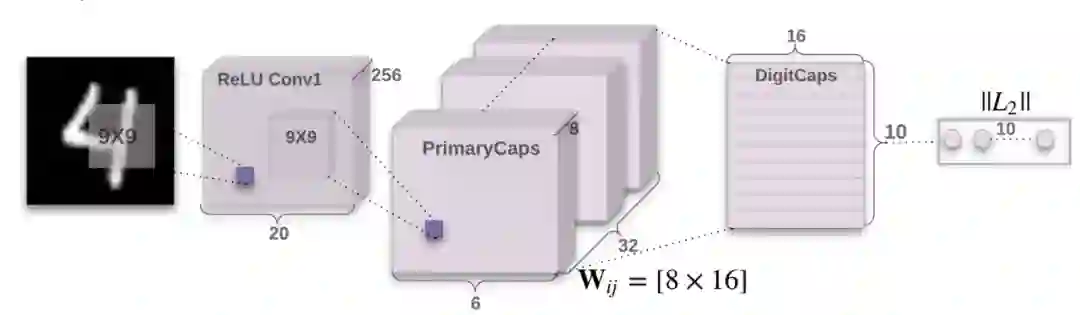
在以上条件下,作者设计了 CapsNet 的初步框架,如图 6 所示。
![]()
图 6. 3 层结构的 CapsNet. 由卷积层和 ReLU 层构成的浅层网络,由卷积层和变换层构成的初级胶囊层和数字胶囊层共同组成 CapsNet(Sabour et al., 2017)。
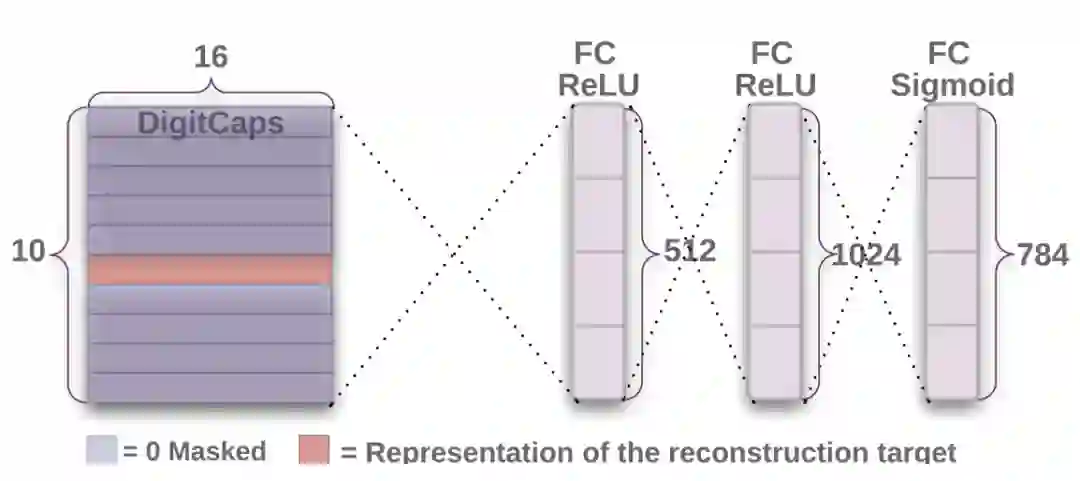
除此之外,作者还设计了一个译码器来重构输入的数字,这个重构的过程也可以作为模型训练过程中的约束项。其结构如图 7 所示。
![]()
图 7. 从数字胶囊层重构图像(Sabour et al., 2017)。
当然,CapsNet 也取得了相当不错的效果。在文章中,作者展示了重构的图像和在 MNIST 数据集上的识别结果可达到 99.23%。我们挑选了部分直观的结果进行展示。
![]()
图 8. 输入图像与重构图像(Sabour et al., 2017)。
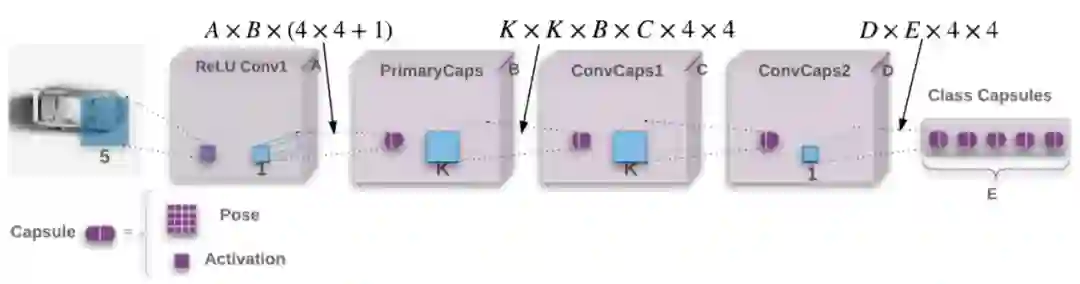
(3) Matrix capsules with EM routing
![]()
与使用向量输出不同,Hinton 等人在 2018 年提出用矩阵表示胶囊的输入和输出 [4]。这一想法对减小胶囊之间的变换矩阵大小十分必要。因为使用向量作为输出时可能需要 n*2 个元素,但是用矩阵则只需要 n。这个版本采用期望最大化算法 (Expectation Maximization algorithm) 代替动态路由。
具体来说,胶囊中特征实体存在的概率用参数 a 来替代上一个版本中向量的长度,这有助于避免压缩函数被认为是“不客观或不明智的”。每个胶囊 M 都有一个 4x4 姿态矩阵和激活概率 a, 在 L 层的胶囊 i 和 L+1 层的胶囊 j 之间,胶囊通过一个 4x4 的变换矩阵 Wij 相互连接,变换矩阵只存储参数和进行学习。胶囊 i 的姿态矩阵与变化矩阵点积后得到胶囊 j 的姿态矩阵,可以表示为 Vij=MiWij。在 L+1 层中所有胶囊的姿态和激活概率都通过非线性路由的方法来连接,并更新 Vij 和 ai。这个非线性路由的方法就是文中介绍的 Expectation Maximization algorithm, 它动态的迭代的更新了 L+1 的参数。
下面我们来介绍一下 EM 算法的具体过程,假设我们已经确定了某一层中所有胶囊的姿态矩阵和激活概率 a,现在要决定哪个胶囊激活和连接高一层的胶囊,并且分配每个活动的低级胶囊到一个活动的高级胶囊。每一个高级层中的胶囊对应于高斯分布和低级层中每个活动胶囊 (转换为向量) 对应于一个数据点。在作者运用最小长度原则来描述时,作者做出了一个选择,即在激活某个高级别的胶囊时,使用了一个固定的代价函数用来编码其均值和方差。于是,为了确定 L+1 层中胶囊的姿态矩阵和激活概率,作者在知道 L 层姿态矩阵和激活概率后使用了 3 次迭代的 EM 算法,其伪代码如下图所示。
![]()
在制定了基本方法之后,作者提出了网络的整体框架。模型起始于一个 5x5 且有 32 个通道步长为 2 的卷积层,后面跟着 ReLU 的非线性层。所有的其他层都是初始胶囊层。每个 B=32 姿态矩阵为 4x4 的初级胶囊会从更低的胶囊中学习线性变换。初级胶囊的激活函数是通过应用 sigmoid 函数产生的。在初级胶囊之后是两个 3x3 的卷积胶囊层(K=3),每层 32 胶囊类型(C=D=32),步长分别为 2 和 1。卷积的最后一层胶囊连接到最后的分类胶囊层,每个类别有一个胶囊。
![]()
路由算法在每一对相邻的胶囊层之间使用,对于卷积胶囊层,L + 1 层的每个胶囊只向 L 层内其感受域内的胶囊发送反馈。因此,L 层中每个胶囊的卷积实例最多接收到来自 L + 1 层中每个胶囊的卷积核大小的反馈。L 层的边界附近的实例图像接收到的反馈较少,角落的每个胶囊类型只接收到一个反馈。
为了降低训练对模型初始化和超参数的敏感性,网络使用 “扩散损失函数” 来直接最大化目标类(at)和其他类激活之间的差距,这里设置 m=1,其计算方法如下。
![]()
作者用了一个数据集 smallNORB 对网络的性能进行了验证,其结果相比 CNN 模型有明显的提高。
![]()
以上的三个版本的胶囊网络均是 Hinton 和他的团队发表的成果。这一章我们介会绍其他几个对于胶囊网络所做的改进。他们分别是:(1) Stacked Capsule Autoencoders; (2) DeepCaps; (3) Visual-textual Capsule Routing。它们分别是发表在 2019 年的 NeurIPS, CVPR 和 2020 年的 CVPR。
(1) Stacked Capsule Autoencoders
![]()
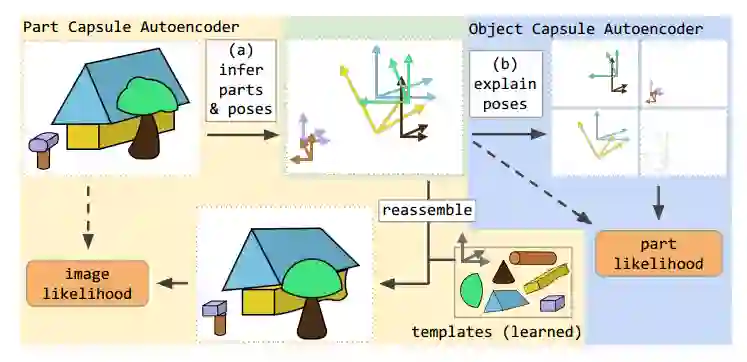
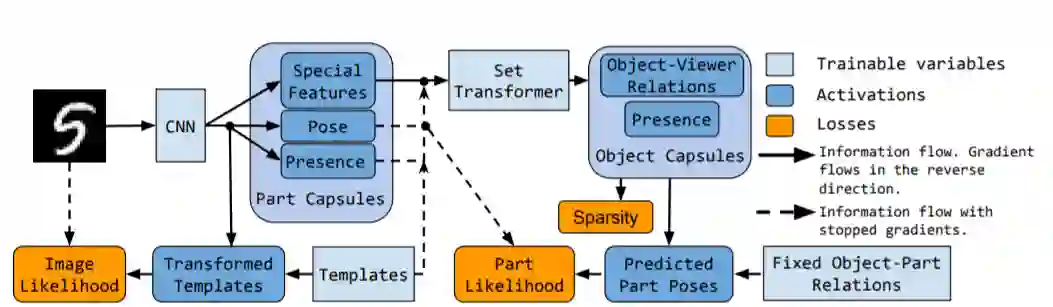
这篇文章的思想是,物体是由一系列几何部分组成,因此,可以用一个无监督的胶囊自动编码器来明确各个部分之间的几何关系,进而推理出对象 [5]。因为这些关系不依赖于视角,所以这个模型对于任意视角的图片都具有很强的鲁棒性。总体而言 unsupervised capsule autoencoder(SCAE)的实行主要分为两个阶段。
第一阶段, 该模型使用 PCAE 直接从图像中预测部分模版存在的概率和姿态,并试图通过重新排列部分模板重建原始图像。第二阶段,SCAE 使用 OCAE 预测一些物体胶囊的参数,并试图组织和发现部分和姿势为一组更小的对象,这对于重建图像十分重要。在这个模型中,由现成的神经编码器来实现推理过程,这点与以前的胶囊网络都不相同。其具体的原理如图 11 所示。
![]()
图 11. Stacked Capsule Autoencoders:(a) 部分胶囊将分割输入为部分和姿态,这些姿势随后被放射变换的模板用来重建输入图像;(b) 对象胶囊试图把推理出的姿态对应到物体,因此找出潜在的结构信息。
具体来说,将一幅图像分割成多个部分并不是件容易的事,所以作者从抽象像素和部分发现阶段开始,提出 CCAE(Constellation Capsule Autoencoder),它使用二维点作为部分,给出它们的坐标作为系统的输入。CCAE 学习将点集进行建模成为熟悉星座,每一个点都是由独立的相似变换来变形。CCAE 能在事先不知道星座的数量和形状的情况下学会给每个点分配对应的星座。之后作者还提出了 PCAE( Part Capsule Autoencoder ),它学着从图像中推理出它的部分和姿势。最后,叠加 OCAE( Object Capsule Autoencoder),OCAE 与 CCAE 高度相似。
在 CCAE 中,一组二维输入点如图 12 所示,首先对其进行编码到 K 个对象胶囊中,一个对象胶囊 k 包含着一个胶囊特征向量 ck,它的存在概率 ak 在 0 到 1 之间,然后还存在在一个 3x3 的对象 - 观察者关系矩阵,矩阵代表着对象和观察者之间的仿射矩阵。
![]()
图 12. 超过三个点的在不同位置,不同尺度和方向的无监督分割。
在 PCAE( Part Capsule Autoencoder )中,与 CCAE 只有二维点(XY 轴)输入不同,每个部分胶囊 m 都包含有一个 6 维姿态(2 个旋转,2 个翻译,尺度和裁剪),一个存在概率变量 dm 和一个独特的个体。作者将部分发现问题改变为了自动编码,编码器学习和推断不同部分胶囊的姿态和存在,而解码器学习图像每个部分的模板 Tm。如果一个部分存在,对应的模板将被仿射转换成推测姿势。最后,转换后的模板被安排到图像中,紧接着在后面的 OCAE 中进行处理。
在 OCAE( Object Capsule Autoencoder)中,在确定了部分及其参数之后,我们希望发现其中可以组合的对象。为此,使用连接姿势 xm、特殊特征 zm 和扁平模板 Tm(它传达部分胶囊的实体)作为 OCAE 的输入。首先,将部分胶囊存在概率 dm 输入到 OCAE 中,其次,dm 也被用来衡量部分胶囊的似然对数。因此, 每一个部分 - 姿势被解释为一个从物体 - 胶囊中得到的独立的混合预测。
![]()
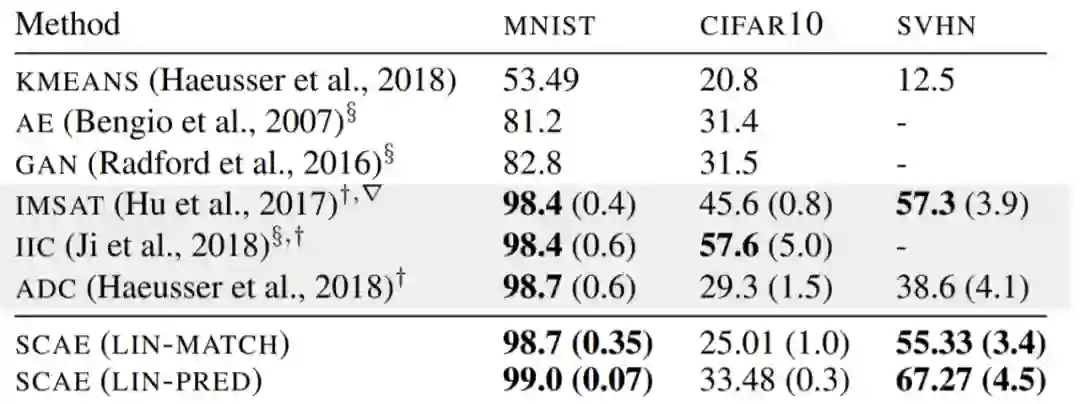
最后,作者一样做了对该方法的评估,我们选择其在 MNIST, CIFAR10,SVHN 三个数据集中的实验结果来说明,在第 1,3 个数据集中,效果明显较好,但在第二个数据集中,识别率还是不高。
![]()
![]()
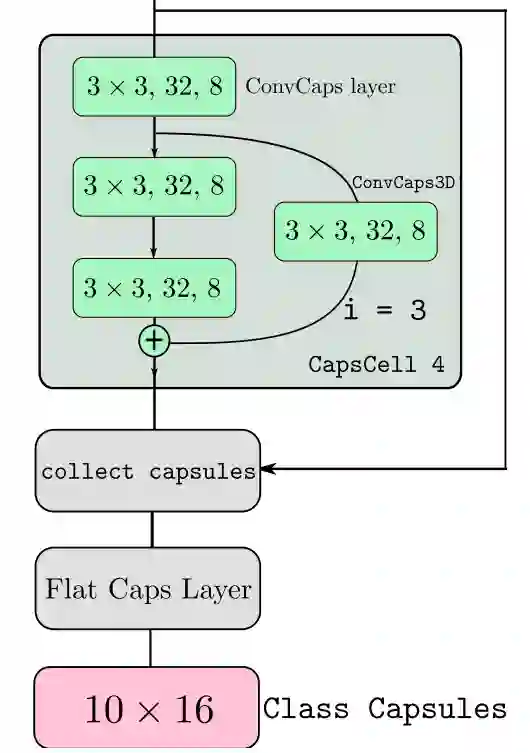
顾名思义,这个版本胶囊网络使得能使结构变得更深,进而能够处理更为复杂的数据 [6]。此外,在这篇文章中还有一个 3D-convolution-inspired routing 算法被提出,用于减少参数。该网络的主要特点就是在结构上的改变,引入了专门针对胶囊的 3D 卷积,并且使用了残差网络的结构。
当前,动态路由的主要缺点之一是目前形式只能在胶囊间实现完全连接的方式而它不能以卷积的方式连接两个胶囊。因此需要有一种新的针对 3D 卷积的动态路由方式被提出。在 V 中,每个元素能被以 3D 卷积的方式得到,其计算过程如下。
![]()
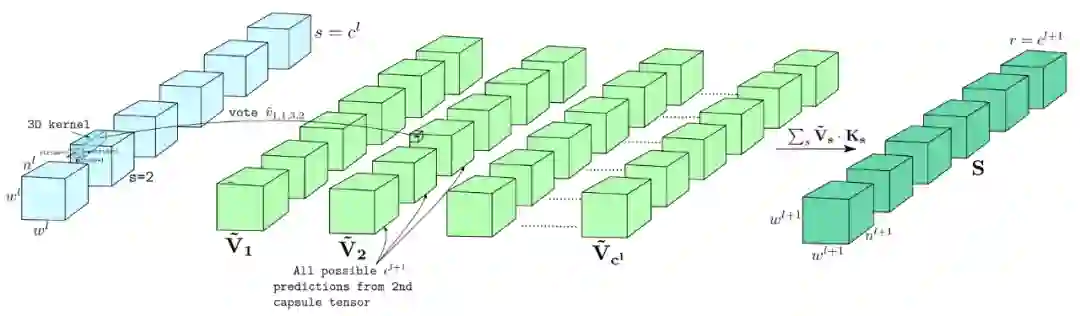
如果使用以前的路由方式,卷积运算得到的特征图只具有局部特征,因此,相邻的胶囊共享相似的信息。作者提出可以从第 l 层到第 l + 1 层的胶囊间通过排列一个胶囊块而不是分别路由第 l 层的每个胶囊就路由来消除这种冗余。这一修改结果大大减少了参数的数量。类似地,使用 3D 卷积核变换,一个子集的胶囊在一个区块进行一次投票,可以实现了局部投票。例如,3×3×8 的核会把相邻的 9 个结果变成 1 票。换句话说,在第 l 层中,低层实体可以用一个胶囊或者几个相邻的胶囊表示,因此,不是分别路由它们到一个更高级别的胶囊,而是把它们组合在一起来路由。下图为 3D 卷积中的路由方式。
![]()
以下为对应的动态路由的伪代码,使得胶囊网络能够减少参数,并且能够在两个卷积层之间进行参数的更新。
![]()
此外,整个网络的结构还参考了残差网络,其的部分典型结构如图 15 所示。
![]()
同样的,该网络也添加了一个解码器。解码器网络由反卷积层组成,它利用从 DeepCaps 模型中提取的实例化参数来重新构造输入数据。与全连通层解码器相比,这个解码器捕获了更多的空间关系,而重建这些图像,该解码器,也能用于正则化胶囊网络。此外,使用二元交叉熵作为损失函数也能提高网络的性能。
![]()
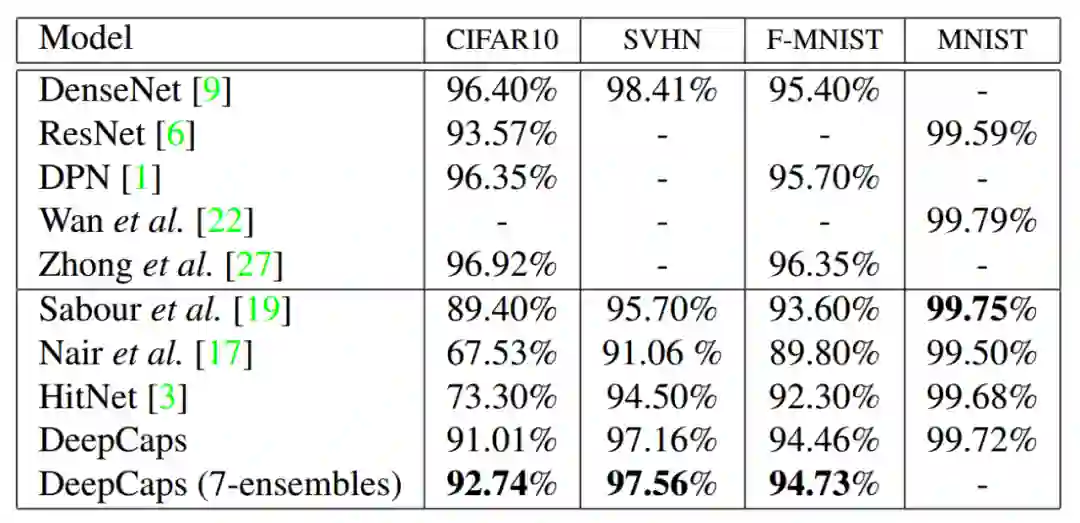
最后,在实验结果上,作者使用了 CIFAR10, SVHN 和 Fashion-MNIST 数据集作为验证,并展示了解码器重新显示的图像结果。其结果如下。
![]()
![]()
图 17. 解码器显示的结果。左边为其他文章中用的全连接解码器,右边为该网络实现的解码器。
(3) Visual-textual Capsule Routing
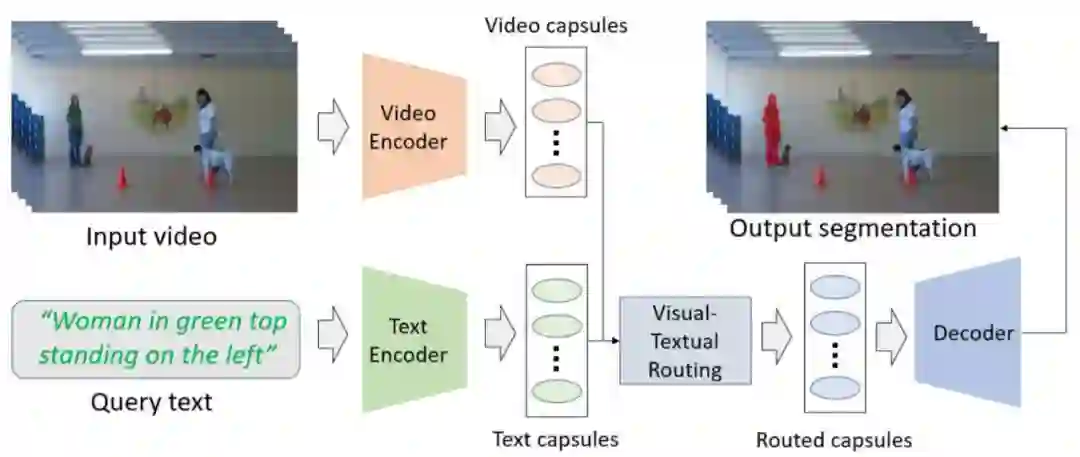
![]()
该文提出了一种使用胶囊网络通过自然语言问题探测视频中演员和动作的方法,具体为在视频和句子输入中存在共同的实体,使用动态路由可以找到这些实体之间的相似性,网络模型学习了这些相似性并生成一个统一的视觉 - 文本的胶囊表示 [7]。首先,文章展示了整个处理方法的步骤如下。
![]()
对于一个给定的视频,我们想要定位一个输入文本所查询中演员和动作,从视频和文本查询中提取初级胶囊,然后联合一个 EM 路由算法创建高级胶囊,进一步用于定位选择的演员和行动。胶囊代表着实体和路由采用的高维滤波学习这些实体之间的部分到整体的关系。
在这篇文章中,作者提出的方法是在视频和句子中存在相同的实体,输入和路由可以找到这些实体之间的相似性。本文的方法允许网络学习一套同时包含视觉输入和句子输入的实体(胶囊),通过这些实体,胶囊路由发现视频和句子输入对象之间的相似性,生成一个统一的视觉 - 文本的胶囊表示。
该文最大的特点就是提出了视频 - 文本的胶囊路由方法如下:
![]()
图 19. 视频 - 文本的胶囊路由,输入到路由过程的是视频胶囊的姿态矩阵和激活,其中利用了 EM Routing 进行了参数的更新。
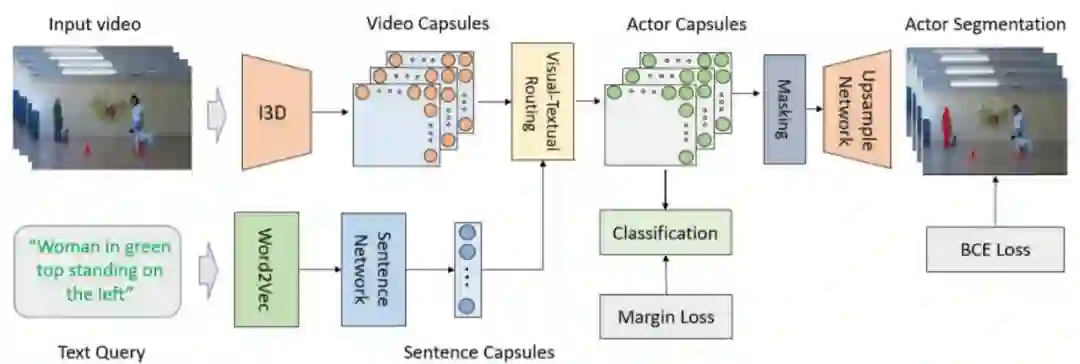
![]()
图 20. Visual-textual Capsule Routing 网络结构。
胶囊中包含视频帧中的空间时间特征,并且胶囊也包含着自然语言中的文本。这些胶囊被路由到一起以创建胶囊来表示图像中演员的形象,视觉 - 文本的胶囊通过掩模版和上采样网络共同来创建一个能够用文本指定演员的二值化分割图像。
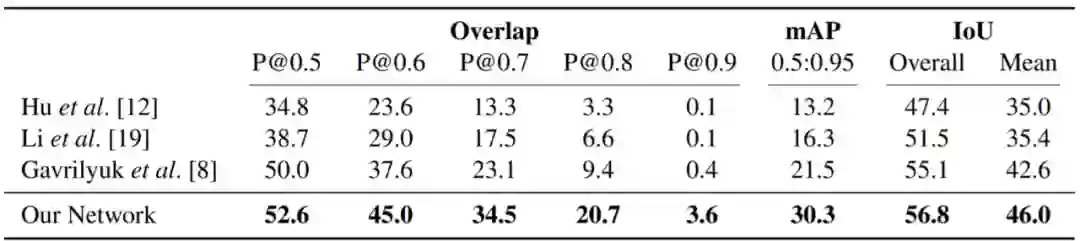
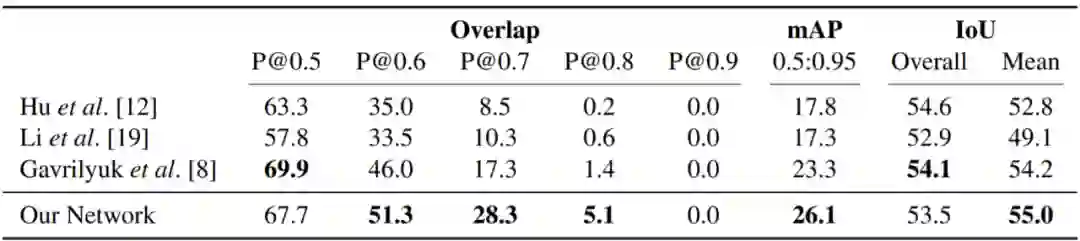
接下来,作者也做了相关实验进行了对该网络效果的验证。以下是 A2D 数据集和 JHMDB 数据集的评估结果。
![]()
![]()
![]()
图 21. 定性的结果。句子查询颜色与切分颜色对应,第一行包含只使用像素级的注释的分段,第二行包含从网络训练使用所有帧上的边框标注的分段。
胶囊网络的出现打开了多个领域研究者的新思路,它可以被用来解决天文学,自动驾驶,机器翻译,手写字符和文本识别,目标检测,情绪检测等等任务 [1]。具体来说,以图像表示的交通数据适合用 CapsNets 来预测交通流量和异常驾驶等。
随着社交媒体的广泛使用,用户的图片和视频可能被伪造,现有的检测方法无法在视频和图像中检测多种形式的伪造,但是使用 CapNets 能够有效的减少过拟合和提高检测的精度。
对于自然语言处理的任务,CapsNet 也被证明能够比传统 CNN 更有效地处理主谓宾之间的关系。在健康医疗等方向上,CapsNet 也能有效提取健康系统中实体之间语义关系,并能很好的处理数量量小,数据不平衡等问题。自动驾驶汽车将大大受益于 CapsNets,传感器数据将收集需要处理的闪光和速度,以便允许汽车在一瞬间做出决定。得益于 GPU, TPU 等硬件的快速发展,相信胶囊网络在其他不同领域的应用会越来越多。
胶囊是深度学习的新概念,与 CNN 和传统的网络神经网络相比,它产生了不错的效果。CNN 分类器在对抗干扰数据时并不健壮,然而,CapsNets 被证明对不良数据的适应力更强,而且还能适应输入数据的仿射变换。
同时,胶囊网络也已经被证明能够减少训练时间,和最小化参数。尽管胶囊网络的表现在某些方面优于 CNN,但也有他们的运作不是很理想的领域(例如大数据集和背景复杂的输入图像)。这些灰色区域需要得到了研究人员的进一步关注和改进。本文的目的是综述胶囊网络的现状,揭示许多的架构和实现方法。虽然目前关于胶囊网络的论文很多,但是胶囊网络本身还是有更多地方需要被研究和挖掘。
1. Patrick, Mensah Kwabena , et al. "Capsule Networks – A survey." (2019).
2. Hinton, Geoffrey E. , A. Krizhevsky , and S. D. Wang . "Transforming Auto-encoders." Artificial Neural Networks & Machine Learning-icann -international Conference on Artificial Neural Networks Springer, Berlin, Heidelberg, 2011.
3. Sabour, Sara , N. Frosst , and G. E. Hinton . "Dynamic Routing Between Capsules." (NIPS 2017).
4. Hinton, Geoffrey E., Sara Sabour, and Nicholas Frosst. "Matrix capsules with EM routing." international conference on learning representations (2018).
5. Kosiorek A R , Sabour S , Teh Y W , et al. Stacked Capsule Autoencoders[J]. NIPS 2019.
6. Rajasegaran, J. , Jayasundara, V. , Jayasekara, S. , Jayasekara, H. , Seneviratne, S. , & Rodrigo, R. . (CVPR 2019). Deepcaps: going deeper with capsule networks.
7. Bruce McIntosh, Kevin Duarte, Yogesh S Rawat, Mubarak Shah. (CVPR 2020). Visual-Textual Capsule Routing for Text-Based Video Segmentation.
本文作者为周宇,目前在华中科技大学攻读计算机博士学位。主要研究方向是深度学习下的表情识别。希望能和研究方向相似的研究者们一起交流,共同进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击阅读原文,提交申请。