被 GANs 虐千百遍后,我总结出来的 10 条训练经验

利用这些技巧,让你的GAN旅程更平坦
原标题 | 10 Lessons I Learned Training GANs for one Year
作者 | Marco Pasini
翻译 | had_in(电子科技大学)
编辑 | Pita // 查看本文更多内容,可点击底部阅读原文
介绍
一年前,我决定开始探索生成式对抗网络(GANs)。自从我对深度学习产生兴趣以来,我就一直对它们很着迷,主要是因为深度学习能做到很多不可置信的事情。当我想到人工智能的时候,GAN是我脑海中最先出现的一个词。

GANs生成的人脸(StyleGAN)
但直到我第一次开始训练GAN时,我才发现了这种有趣算法的双面性:训练极其困难。确实,在我尝试之前,我从论文上和其他人的尝试中了解到这一点,但我一直认为他们夸大了一个本来很小但很容易克服的问题。
事实证明我错了。
当我尝试生成与传统的MNIST案例不同的东西时,我发现影响GAN有很大的不稳定性问题,并且随着我花在寻找解决方案上的时间的增加,这变得非常困扰我。
现在,在花费了无数天的时间研究已知的解决方案,并尝试提出新的解决方案之后,我终于可以说我至少对GAN项目中收敛的稳定性有了更多的掌控,您也可以。我不奢望你仅用10分钟就解决这个问题,并在每一个项目中达到很完美的收敛结果(或用博弈论的话语表达,即纳什平衡),但我想要给你一些技巧和技术,你可以利用这些技巧让你的GAN旅程更平坦,耗时更少,最重要的是,少一些的困惑。
GANs 的现状
自生成对抗性网络提出以来,研究人员对其稳定性问题进行了大量的研究。目前已有大量的文献提出了稳定收敛的方法,除此之外,还有大量的冗长而复杂的数学证明。此外,一些实用的技巧和启发在深度学习领域浮出水面:我注意到,这些未经证明,并没有数学解释的技巧,往往非常有效,不可丢弃。
随着稳定性的提高,生成现实图像的方面也有了重大飞跃。你只需要看看来自英伟达的StyleGAN和来自谷歌的BigGAN的结果,就能真正意识到GANs已经发展到了什么程度。

由BigGAN生成的图像
在阅读并尝试了许多来自论文和实践者的技巧之后,我整理了一个列表,列出了在训练GAN时应该考虑和不应该考虑的问题,希望能让您对这个复杂且有时冗长的主题有进一步的了解。
1. 稳定性和容量
当我开始我的第一个独立的GAN项目时,我注意到在训练过程的开始阶段,判别器的对抗损失总是趋于零,而生成器的损失却非常高。我立即得出结论,有一个网络没有足够的“容量”(或参数数量)来匹配另一个网络:所以我立马改变了生成器的架构,在卷积层上添加了更多的滤波器,但令我惊讶的是,什么改变都没有。
在进一步探究网络容量变化对训练稳定性的影响后,我没有发现任何明显的相关性。两者之间肯定存在某种联系,但它并不像你刚开始想象的那么重要。
因此,如果你发现自己的训练过程不平衡,而且也没有出现一个网络的容量明显超过另一个网络时,我不建议将添加或删除滤波器作为主要解决方案。
当然,如果您对自己网络的容量非常不确定,您可以在网上查看一些用于类似场景的架构案例。
2. 早停法(Early Stopping)
在GANs训练时,您可能会遇到的另一个常见的错误是,当您看到生成器或鉴别器损失突然增加或减少时,立即停止训练。我自己也这么做过无数次:在看到损失增加之后,我立刻认为整个训练过程都被毁了,原因在于某些调得不够完美的超参数。
直到后来,我才意识到,损失函数往往是随机上升或下降的,这个现象并没有什么问题。我取得了一些比较好的、实际的结果,而生成器的损失远远高于判别器的损失,这是完全正常的。因此,当你在训练过程中遇到突然的不稳定时,我建议你多进行一些训练,并在训练过程中密切关注生成图像的质量,因为视觉的理解通常比一些损失数字更有意义。
3. 损失函数的选择
在选择用于训练GAN的损失函数时,我们应该选择哪一个呢?
近期的一篇论文解决了这个问题(论文地址:https://arxiv.org/abs/1811.09567),该论文对所有不同的损失函数进行了基准测试和比较:出现了一些非常有趣的结果。显然,选择哪个损失函数并不重要:没有哪个函数绝对优于其他函数,GAN能够在每种不同的情况下学习。
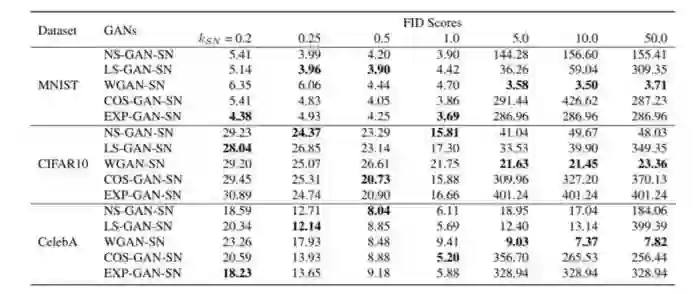
论文结果:损失较少的即为更好的(https://arxiv.org/abs/1811.09567)
因此,我的建议是从最简单的损失函数开始,留下一个更具体和“最先进”的选择作为可能的最后一步,正如我们从文献中了解到的那样,您很可能会得到更糟糕的结果。
4.平衡发生器和判别器的权重更新
在许多GAN论文中,特别是一些早期的论文中,在实现部分中经常可以看到,作者更新一次判别器时,都更新两次或三次生成器。
在我的第一次尝试中,我注意到在不平衡训练的情况下,判别器网络几乎每次都超过生成器(损失函数大大减少)。因此,当我知道到即使是极其优秀的论文作者也会有类似的问题,并采用了一个非常简单的解决方案来解决它时,我对自己所做的事情充满信心。
但在我看来,通过不同的网络权重更新来平衡训练是一个目光短浅的解决方案。几乎从不改变生成器更新其权重的频率,成为了我稳定训练过程的最终解决方案:它有时可以推迟不稳定性的出现,但直到收敛都无法解决它。当我注意到这种策略无效时,我甚至试图使它更加动态化,根据两个网络的当前丢失状态来改变权值更新进度;直到后来我才发现,我并不是唯一一个试图走这条路的人,和其他许多人一样,我也没有成功地克服不稳定性。
直到后来我才明白,其他技术(稍后在本文中解释)对提高训练稳定性的作用要大得多。
5. Mode Collapse问题和学习率
如果您正在训练GANs,您将肯定知道什么是Mode Collapse。这个问题在于生成器“崩溃”了,并且总是将每一个输入的隐向量生成单一的样本 。在GAN的训练过程中,这是一个相当常见的阻碍,在某些情况下,它会变得相当麻烦。

Mode Collapse的例子
如果你遇到这种情况,我建议你最直接的解决方案是尝试调整GAN的学习速度,因为根据我的个人经验,我总是能够通过改变这个特定的超参数来克服这个阻碍。根据经验,当处理Mode Collapse问题时,尝试使用较小的学习率,并从头开始训练。
学习速度是最重要的超参数之一,即使不是最重要的超参数,即使是它微小变化也可能导致训练过程中的根本性变化。通常,当使用更大的Batch Size时,您可以设置更高的学习率,但在我的经验中,保守一点几乎总是一个安全的选择。
还有其他方法可以缓解Mode Collapse问题,比如我从未在自己的代码中实现过的特征匹配(Feature Matching)和小批量判别(Minibatch Discrimination),因为我总是能找到另一种方法来避免这种困难,但如果需要,请自行关注这些方法。
6. 添加噪声
众所周知,提高判别器的训练难度有利于提高系统的整体稳定性。其中一种提高判别器训练复杂度的方法是在真实数据和合成数据(例如由生成器生成的图像)中添加噪声;在数学领域中,这应该是有效的,因为它有助于为两个相互竞争的网络的数据分布提供一定的稳定性。我推荐尝试使用这种方法,因为它在实践中一般比较有效(即使它不能神奇地解决您可能遇到的任何不稳定问题),而且设置起来只需要很少代价。话虽如此,我开始会使用这种技术,但过了一段时间后就放弃了,而是更喜欢其他一些在我看来更有效的技术。
7. 标签平滑
达到相同目的的另一种方法是标签平滑,这种方法更容易理解和实现:如果真实图像的标签设置为1,我们将它更改为一个低一点的值,比如0.9。这个解决方案阻止判别器对其分类标签过于确信,或者换句话说,不依赖非常有限的一组特征来判断图像是真还是假。我完全赞同这个小技巧,因为它在实践中表现得非常好,并且只需要更改代码中的一两个字符。
8. 多尺度梯度
当处理不是太小的图像(如MNIST中的图像)时,您需要关注多尺度梯度。这是一种特殊的GAN实现,由于两个网络之间的多个跳连接,梯度流从判别器流向生成器,这与传统的用于语义分割的U-Net类似。
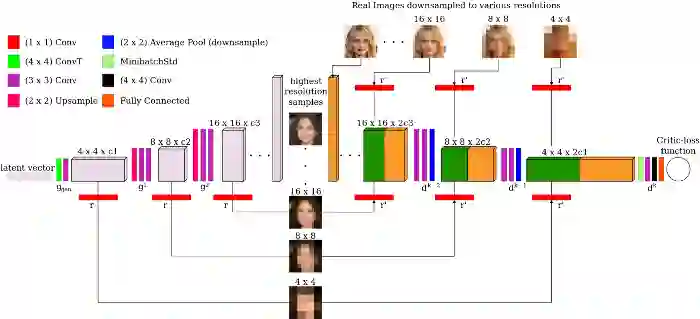
MSG-GAN架构
多尺度梯度论文的作者能够通过训练GAN直接生成高清晰度的1024x1024图像,没有任何特别大的问题(Mode Collapse等),而在此之前,只有Progressively-Growing GAN(英伟达,ProGAN)才有可能。我已经在我的项目中实现了它,我得到了到一个更稳定的训练过程以及更有说服力的结果。查看论文(https://arxiv.org/abs/1903.06048)以获得更多的细节,并尝试它!
9. 双时间尺度更新规则
当我说双时间尺度的更新规则(TTUR)时,您可能认为我说的是GAN训练中使用的一种复杂而清晰的技术,但是完全不是这样。这种技术只是为了让生成器和鉴别器选择不同的学习率,仅此而已。在首次引入TTUR的论文中(https://arxiv.org/abs/1706.08500),作者提供了一个该算法收敛于纳什平衡的数学证明,并证明了使用不同的学习率实现了一些较有名的GAN(DCGAN, WGAN-GP),并取得了最先进的结果。
但是当我说到“使用不同的学习速率”时,我在实践中真正的应该怎么做呢?一般来说,我建议为判别器选择一个更高的学习率,而为生成器选择一个更低的学习率:这样一来,生成器必须用更小的更新幅度来欺骗判别器,并且不会选择快速、不精确和不现实的方式来赢得博弈。为了给出一个实际的例子,我经常将判别器的学习率选为0.0004,将生成器的学习率选为0.0001,我发现这些值在我的一些项目中表现得很好。请记住,在使用TTUR时,您可能会注意到生成器有更大的损失量。
10. 谱归一化
在一些论文中,如介绍SAGAN(或Self - Attention GAN)的论文中,表明谱归一化是应用于卷积核的一种特殊的归一化,它可以极大地提高训练的稳定性。它最初只在判别器中使用,后来被证明如果用于生成器的卷积层也是有效的,我可以完全赞同这个策略!
我几乎可以说,发现和实现谱归一化使我的GAN旅程出现了方向性的改变,直率地讲,我没有看到任何理由不使用这种技术:我可以保证它会给你一个更好和更稳定的训练结果,同时让您关注其他更加有趣的方面的深度学习项目!(详见这篇论文:https://arxiv.org/abs/1802.05957)
结论
许多其他技巧,更复杂的技术和体系结构都有望解决GANs的训练问题:在本文中,我想告诉您我个人的发现并实现了哪些方法来克服遇到的障碍。
因此,如果您在学习这里介绍的每种方法和技巧时,发现自己陷入了困境,那么还有更多的资料需要研究。我只能说,在花了无数的时间研究和尝试了所有可能的解决GAN相关问题的方法之后,我对我的项目更加自信了,我真的希望你们也能这样做。
最后,衷心感谢您阅读并关注这篇文章,希望您能获得一些有价值的东西。
via https://towardsdatascience.com/10-lessons-i-learned-training-generative-adversarial-networks-gans-for-a-year-c9071159628

IJCAI 2019现场直播 正在进行中,扫码即可观看。





