何谓“人工智能”?如何做到“强人工智能”?
【导读】本文是工程师Narasimha Prasanna HN撰写的技术博文,主要介绍人工智能的概念,当前人工智能的水平,以及什么是强人工智能,当前实现强人工智能的方向。作者指出现有的监督学习的局限性,讲解了当前实现“部分强人工智能”的方法:强化学习,与动态编程和控制论的结合,深度Q学习。我们可以从中看到当前我们处于人工智能的什么阶段,我们推进人工智能的可能的方向。

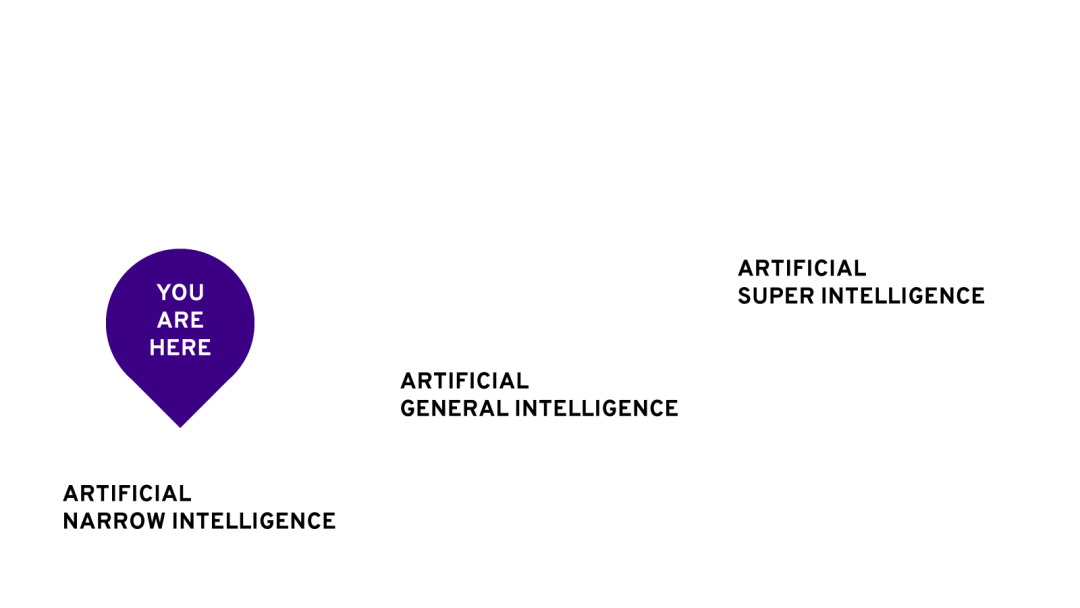
What is Artificial General Intelligence?
什么是人工智能?
人工智能是计算机科学(或科学)的一个分支,它能创建智能系统。 智能系统就是像人类一样拥有智能的系统。
人工智能科学并不新鲜,人工智能术语在古希腊和埃及的手稿中已经提到。 希腊人相信神 Hephaestus,也被称为铁匠之神,根据希腊神话中的 Hephaestus 为所有神制造智能武器,他们认为,人工智能的目标是帮助人们实现某种目标,能够 自动运行并预先编程以根据情况采用不同的方式作出对应的反应。
那么,人工智能这个词已经在娱乐领域流行起来,我们可以看到很多基于超级智能概念的电影。但是我们今天看到的人工智能系统与所谓的“超级智能”系统并不匹配。
真正AI和现有AI系统之间的区别:
如前所述,人工智能并不是一个新领域,许多哲学家和科学家自从人类社会以来都有对于AI的想象,但他们都受到他们时代技术的限制。今天,随着强大的超级计算机的出现,我们能够建立符合所需目的的AI系统。但是,他们真的很聪明吗?答案是否定的,他们不是。让我们看看为什么。
随着计算机的帮助和互联网上足够大的可用的数据集,所谓的机器学习就出现了。机器学习提供了一套使用AI的数学概念,可以在现实世界中实施。
神经网络,大致模拟人类大脑的工作,使机器从数据中学习。深度学习帮助很多科技巨头(如谷歌和苹果)经济地改善它们的产品,通过实施如脸部识别,语言理解,图像理解等众多新兴技术。但是,所谓的深度学习不是真正的智能。机器学习领域需要大量的数据集来学习或预测,这被称为监督学习。
所谓的监督式学习创造了一种智能幻觉,但它的核心只是一种数学优化。即使它具有对数据集进行决策和分类的能力,它的工作方式也非常狭窄。
我们非常熟悉创建监督学习系统的技巧。基于大数据集,监督学习系统学习在输入和输出之间映射,并因此可以预测未见输入的输出。但这不是我们的大脑实际做的,我们的大脑不需要10000张猫的图像来识别猫,甚至我们的大脑也可以做很多监督学习系统无法做到的事情。
监督学习的局限性:
尽管监督学习可以用来创造很多惊人的事情,但它有很多限制:
• 它的思维总是有限的,总是局限于特定的领域。
• 它的智能取决于您使用的训练数据集。
• 它不能被用于动态变化的环境中。
• 只能用于分类和回归。但不能解决控制问题。
• 它需要大量的数据集,如果数据集不够大,它缺乏准确性。获取数据集可能是一个问题。
什么是AGI?
AGI(强人工智能)是一个用于描述真正智能系统的术语。真正的智能系统具有普遍思考的能力,可以在不考虑任何以前的训练的情况下做出决定,这里的决策是基于他们自己学到的。设计这样的系统可能非常困难,因为今天的技术有限,但我们可以创建所谓的“部分AGI”。
强化学习
即使在今天,许多科学家也认为强化学习是实现所谓的AGI的一种方式。强化学习可以作为监督学习无法解决的问题的解决方案。让我们举一个简单的例子来理解“步行”这项基本任务,步行是一项我们非常自然而擅长的人类任务。婴儿学会自己走路,而不必搜索数据集,人类大脑可以通过从错误中学习来做到这一点。但一旦变得完美,它可以走数千步,甚至可以识别步长中的某个不一致。大脑采取的步骤总是最佳的,所采取的速度(或简单的步长)总是如此,应以最短的时间以相同的方式达到目的地,每个步骤所需的能量应该是最小的。所以步行的速度取决于能量以及到达目的地的速度。同样的步行问题可以应用于如机器人这样需要运动的领域。当然,如前所述,监督学习不能做到这一点。
与动态编程和控制论的结合
正如我们熟悉的那样,动态编程是为任何问题获得最佳解决方案的一种方法。动态规划一直是解决旅行商问题和与图论相关的其他问题的最成功算法之一。这种方法使用迭代方法,其中一组解决方案可以在一个或多个步骤中找到,然后算法的剩余部分决定采取哪种解决方案作为最优解决方案。
动态规划方程:动态规划的标准方程称为Bellman方程。这个方程可以应用于所有的决策问题,例如,在旅行推销员问题中,给定一组城市及其距离,问题是获得一条穿过所有城市至少十一条的最短路径。 Bellman方程可以表示为:
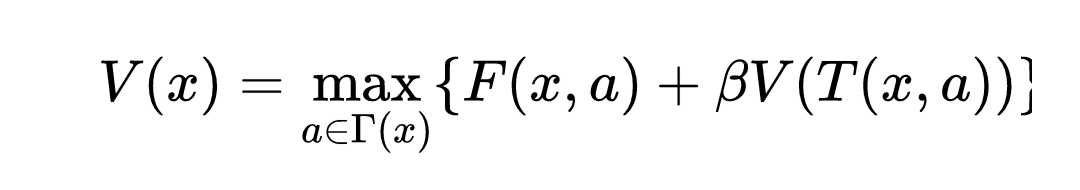
这个方程涉及到找到一个函数V(x,a),这个函数的目标是为每个状态x选择一个动作,这样这个动作a对于状态x总是最优的。 这是解释贝尔曼方程的简单方法。 所有当今广泛使用的强化学习算法都是动态可编程的,意味着它们都采用Bellman方程。 稍后我们将看到有关Deep-Q算法,这与Bellman方程相似。 一些强化学习算法遵循马尔可夫决策规则,如SARSA算法等。在这种情况下,它们在随机空间中采用Bellman方程的形式,如下所示:
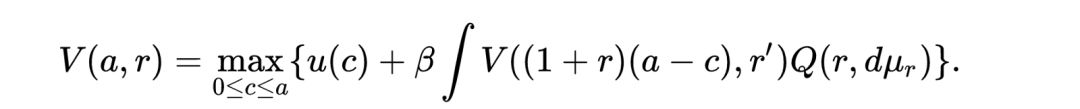
深度Q学习:
Google的Deepmind在2015年发表了一篇关于所谓的Deep Q Learning算法的非常有趣的论文。这种算法在人类难以完成的大多数任务中都能够胜任。该算法能够胜过2600多个Atari游戏。
他们的工作代表了有史以来第一位能够在不需要任何人为干预的情况下不断调整行为的通用人工智能体,这是寻求强AI的主要技术步骤。
该智能体是使用称为Q学习的算法开发的,Q学习算法的核心是Bellman方程,所以它遵循动态规划的方法。
实践方法:每个强化学习问题都包含以下组件:
• Agent:学习算法或任何能够学习的智能体。
• 环境:它是部署代理的地方或空间。例如:地球是一个人类是Agent的环境。一个环境由一系列状态,行动和奖励形成的明确定义的规则组成。
• 状态:Agent在任何实例中的有效位置称为状态。Agent可以通过执行操作从一个状态转换到另一个状态。如果对于该状态正确,则进行行动,获得奖励。
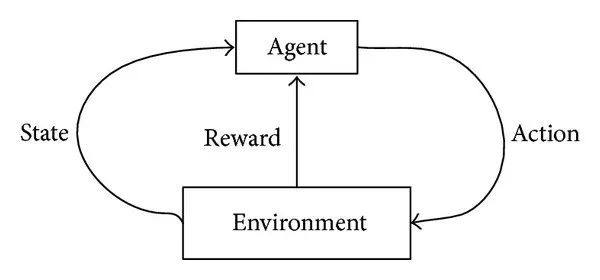
• 奖励:奖励是指环境为特定行为定义的结果。 如果行动正确,奖励是积极的,否则就是消极的。
任何Agent的长期目标是理解环境然后最大化奖励。 奖励可以被最大化,只有它是积极的,积极的奖励,反过来是对该状态的正确行动的结果。 所以最大化问题用简单的术语来处理以下顺序:
• 给定一个有效的状态,,产生一个随机行动。
• 假设动作是正确的,并且转换到下一个随机状态。
• 计算转换的奖励。
• 如果奖励是积极的,记住该状态的行动,因为它是适当的行动,但不是最佳行动。
• 如果奖励是消极的,则放弃该行为。
• 从获得的一组最佳行动中,确定最大奖励的最佳行动。
• 为环境中的每个状态执行此操作。
该等式可以如下给出:
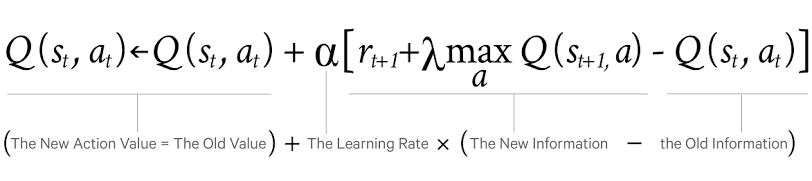
意思是,Q值即状态动作值取决于旧值+新信息与旧信息之间的差异。旧信息已经存在于记忆中,而新信息是通过最大化从行动中学到的奖励而获得的。因此,在许多强化学习问题中,我们构建了一个可以学习状态与行为之间映射的神经网络,如果行动是积极的。一旦训练结束,我们可以部署网络,以便为任何有效的状态创建正确的行为,从而最大限度地获得回报。
MountainCar示例:
OpenAI 的GYM包提供了一套Agent可以接受训练的环境,Mountain Car是一个很好的例子,可以使用强化学习进行改善。这场比赛的目标是成功登山。
我们可以从零开始实施Q学习,或者我们可以简单地使用Keras-rl。 Keras-rl只是一组API,可以使用预先编写的算法。

如图所示。到4000个迭代结束时,你已经学会了产生足够的加速度来爬山。
代码如下:
import gym
import numpy
from keras.layers import Dense, Flatten
from keras.layers import Activation
from keras.models import load_model, Sequential
from keras.optimizers import Adam
from rl.agents import DQNAgent
from rl.memory import SequentialMemory
from rl.policy import EpsGreedyQPolicy
from rl.callbacks import Callback
env = gym.make('MountainCar-v0')
def Network():
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(40))
model.add(Activation('relu'))
model.add(Dense(40))
model.add(Activation('relu'))
model.add(Dense(40))
model.add(Activation('relu'))
model.add(Dense(env.action_space.n))
model.add(Activation('linear'))
return model
pass
# policies:
# callback
class EpsDecayCallback(Callback):
def __init__(self, eps_policy, decay_rate=0.95):
self.eps_policy = eps_policy
self.decay_rate = decay_rate
def on_episode_begin(self, episode, logs={}):
self.eps_policy.eps *= self.decay_rate
policy = EpsGreedyQPolicy(eps=1.0)
memory = SequentialMemory(limit=500000, window_length=1)
agent = DQNAgent(
model=Network(), policy=policy, memory=memory, enable_double_dqn=False,
nb_actions=env.action_space.n, nb_steps_warmup=10, target_model_update=1e-2
)
agent.compile(
optimizer=Adam(lr=0.002, decay=2.25e-05), metrics=['mse']
)
agent.fit(
env=env,
callbacks=[EpsDecayCallback(eps_policy=policy, decay_rate=0.975)],
verbose=2,
nb_steps=600000
)
agent.save_weights('model.hdf5')
agent.test(env=env, nb_episodes=100, visualize=True)
view
rawAlgorithm.py
hosted
with ❤ by GitHub
import gym
import numpy
from keras.layers import Dense, Flatten
from keras.layers import Activation
from keras.models import load_model, Sequential
from keras.optimizers import Adam
from rl.agents import DQNAgent
from rl.memory import SequentialMemory
from rl.policy import EpsGreedyQPolicy
from rl.callbacks import Callback
env = gym.make('MountainCar-v0')
def Network():
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(40))
model.add(Activation('relu'))
model.add(Dense(40))
model.add(Activation('relu'))
model.add(Dense(40))
model.add(Activation('relu'))
model.add(Dense(env.action_space.n))
model.add(Activation('linear'))
return model
pass
# policies:
# callback
class EpsDecayCallback(Callback):
def __init__(self, eps_policy, decay_rate=0.95):
self.eps_policy = eps_policy
self.decay_rate = decay_rate
def on_episode_begin(self, episode, logs={}):
self.eps_policy.eps *= self.decay_rate
policy = EpsGreedyQPolicy(eps=1.0)
memory = SequentialMemory(limit=500000, window_length=1)
agent = DQNAgent(
model=Network(), policy=policy, memory=memory, enable_double_dqn=False,
nb_actions=env.action_space.n, nb_steps_warmup=10, target_model_update=1e-2
)
agent.compile(
optimizer=Adam(lr=0.002, decay=2.25e-05), metrics=['mse']
)
agent.fit(
env=env,
callbacks=[EpsDecayCallback(eps_policy=policy, decay_rate=0.975)],
verbose=2,
nb_steps=600000
)
agent.save_weights('model.hdf5')
agent.test(env=env, nb_episodes=100, visualize=True)
参考文献:
https://towardsdatascience.com/what-is-artificial-general-intelligence-5b395e63f88b
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



