【AlphaGo核心技术-教程学习笔记03】深度强化学习第三讲 动态规划寻找最优策略
点击上方“专知”关注获取更多AI知识!
【导读】Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。Alpha Zero的背后核心技术是深度强化学习,为此,专知有幸邀请到叶强博士根据DeepMind AlphaGo的研究人员David Silver《深度强化学习》视频公开课进行创作的中文学习笔记,在专知发布推荐给大家!(关注专知公众号,获取强化学习pdf资料,详情文章末尾查看!)
叶博士创作的David Silver的《强化学习》学习笔记包括以下:
笔记序言:【教程】AlphaGo Zero 核心技术 - David Silver深度强化学习课程中文学习笔记
《强化学习》第三讲 动态规划寻找最优策略
《强化学习》第四讲 不基于模型的预测
《强化学习》第五讲 不基于模型的控制
《强化学习》第六讲 价值函数的近似表示
《强化学习》第七讲 策略梯度
《强化学习》第八讲 整合学习与规划
《强化学习》第九讲 探索与利用
以及包括也叶博士独家创作的强化学习实践系列!
强化学习实践一 迭代法评估4*4方格世界下的随机策略
强化学习实践二 理解gym的建模思想
强化学习实践三 编写通用的格子世界环境类
强化学习实践四 Agent类和SARSA算法实现
强化学习实践五 SARSA(λ)算法实现
强化学习实践六 给Agent添加记忆功能
强化学习实践七 DQN的实现
今天《强化学习》第三讲 动态规划寻找最优策略;
本讲着重讲解了利用动态规划来进行强化学习,具体是进行强化学习中的“规划”,也就是在已知模型的基础上判断一个策略的价值函数,并在此基础上寻找到最优的策略和最优价值函数,或者直接寻找最优策略和最优价值函数。本讲是整个强化学习课程核心内容的引子。
简介 Introduction
动态规划算法是解决复杂问题的一个方法,算法通过把复杂问题分解为子问题,通过求解子问题进而得到整个问题的解。在解决子问题的时候,其结果通常需要存储起来被用来解决后续复杂问题。当问题具有下列特性时,通常可以考虑使用动态规划来求解:第一个特性是一个复杂问题的最优解由数个小问题的最优解构成,可以通过寻找子问题的最优解来得到复杂问题的最优解;子问题在复杂问题内重复出现,使得子问题的解可以被存储起来重复利用。
马尔科夫决定过程(MDP)具有上述两个属性:Bellman方程把问题递归为求解子问题,价值函数就相当于存储了一些子问题的解,可以复用。因此可以使用动态规划来求解MDP。
我们用动态规划算法来求解一类称为“规划”的问题。“规划”指的是在了解整个MDP的基础上求解最优策略,也就是清楚模型结构的基础上:包括状态行为空间、转换矩阵、奖励等。这类问题不是典型的强化学习问题,我们可以用规划来进行预测和控制。
具体的数学描述是这样:
预测:给定一个MDP 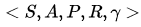

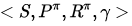
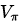
控制:给定一个MDP 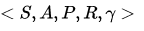
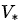
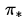
迭代法策略评估Iterative Policy Evaluation
理论
问题:评估一个给定的策略π,也就是解决“预测”问题。
解决方案:反向迭代应用Bellman期望方程
具体方法:同步反向迭代,即在每次迭代过程中,对于第 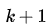
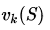
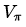
也可以异步反向迭代,即在第k次迭代使用当次迭代的状态价值来更新状态价值。
公式为:
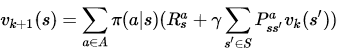
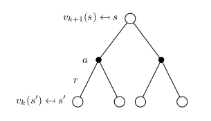
即:一次迭代内,状态s的价值等于前一次迭代该状态的即时奖励与所有s的下一个可能状态s' 的价值与其概率乘积的和,如图示:
公式的矩阵形式是:
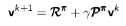
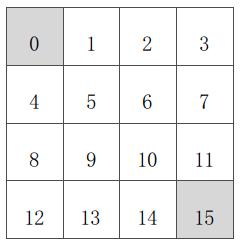
示例——方格世界
已知:
状态空间S:如图。S1 - S14非终止状态,ST终止状态,下图灰色方格所示两个位置;
行为空间A:{n, e, s, w} 对于任何非终止状态可以有东南西北移动四个行为;
转移概率P:任何试图离开方格世界的动作其位置将不会发生改变,其余条件下将100%地转移到动作指向的状态;
即时奖励R:任何在非终止状态间的转移得到的即时奖励均为-1,进入终止状态即时奖励为0;
衰减系数γ:1;
当前策略π:Agent采用随机行动策略,在任何一个非终止状态下有均等的几率采取任一移动方向这个行为,即π(n|•) = π(e|•) = π(s|•) = π(w|•) = 1/4。
问题:评估在这个方格世界里给定的策略。
该问题等同于:求解该方格世界在给定策略下的(状态)价值函数,也就是求解在给定策略下,该方格世界里每一个状态的价值。
迭代法求解(迭代法进行策略评估)

状态价值在第153次迭代后收敛
在实践环节,我们将使用Python对此问题进行求解演示。
如何改善策略
通过方格世界的例子,我们得到了一个优化策略的办法,分为两步:首先我们在一个给定的策略下迭代更新价值函数:
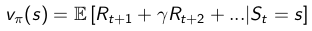
随后,在当前策略基础上,贪婪地选取行为,使得后继状态价值增加最多:
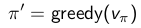
在刚才的格子世界中,基于给定策略的价值迭代最终收敛得到的策略就是最优策略,但通过一个回合的迭代计算价值联合策略改善就能找到最优策略不是普遍现象。通常,还需在改善的策略上继续评估,反复多次。不过这种方法总能收敛至最优策略 
这就是接下来要介绍的策略迭代。
策略迭代 Policy Iteration
在当前策略上迭代计算v值,再根据v值贪婪地更新策略,如此反复多次,最终得到最优策略 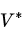
贪婪 指的是仅采取那个(些)使得状态价值得到最大的行为。
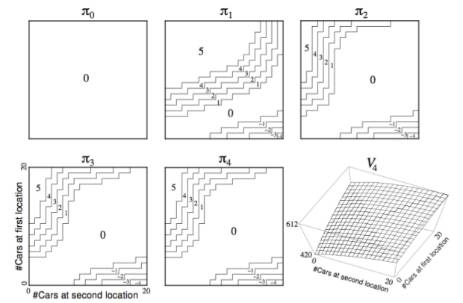
示例——连锁汽车租赁
举了一个汽车租赁的例子,说明如何在给定策略下得到基于该策略的价值函数,并根据更新的价值函数来调整策略,直至得到最优策略和最优价值函数。
一个连锁汽车租赁公司有两个地点提供汽车租赁,由于不同的店车辆租赁的市场条件不一样,为了能够实现利润最大化,该公司需要在每天下班后在两个租赁点转移车辆,以便第二天能最大限度的满足两处汽车租赁服务。
已知
状态空间:2个地点,每个地点最多20辆车供租赁
行为空间:每天下班后最多转移5辆车从一处到另一处;
即时奖励:每租出1辆车奖励10元,必须是有车可租的情况;不考虑在两地转移车辆的支出。
转移概率:求租和归还是随机的,但是满足泊松分布 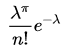
衰减系数 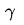
问题:怎样的策略是最优策略?
求解方法:从一个确定的策略出发进行迭代,该策略可以是较为随意的,比如选择这样的策略:不管两地租赁业务市场需求,不移动车辆。以此作为给定策略进行价值迭代,当迭代收敛至一定程度后,改善策略,随后再次迭代,如此反复,直至最终收敛。
在这个问题中,状态用两个地点的汽车存量来描述,比如分别用c1,c2表示租赁点1,2两处的可租汽车数量,可租汽车数量同时参与决定夜间可转移汽车的最大数量。
解决该问题的核心就是依据泊松分布确定状态<c1,c2>的即时奖励,进而确定每一个状态的价值。
策略改善——理论证明
1. 考虑一个确定的策略:
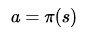
2. 通过贪婪计算优化策略:
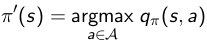
3. 这会用1步迭代改善状态s的q值,即在当前策略下,状态s在动作π’(s)下得到的q值等于当前策略下状态s所有可能动作得到的q值中的最大值。这个值一般不小于使用当前策略得到的行为所的得出的q值,因而也就是该状态的状态价值。
4. 如果q值不再改善,则在某一状态下,遵循当前策略采取的行为得到的q值将会是最优策略下所能得到的最大q值,上述表示就满足了Bellman最优方程,说明当前策略下的状态价值就是最优状态价值。
5. 因而此时的策略就是最优策略。
注:ppt上有数学公式证明。
思考:很多时候,策略的更新较早就收敛至最优策略,而状态价值的收敛要慢很多,是否有必要一定要迭代计算直到状态价值得到收敛呢?
修饰过的策略迭代 Modified Policy Iteration
有时候不需要持续迭代至最有价值函数,可以设置一些条件提前终止迭代,比如设定一个Ɛ,比较两次迭代的价值函数平方差;直接设置迭代次数;以及每迭代一次更新一次策略等。
价值迭代 Value Iteration
优化原则 Principle of Optimality
一个最优策略可以被分解为两部分:从状态s到下一个状态s’采取了最优行为 
定理:一个策略能够使得状态s获得最优价值,当且仅当:对于从状态s可以到达的任何状态s’,该策略能够使得状态s’的价值是最优价值:
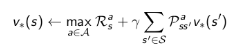
确定性的价值迭代 Deterministic Value Iteration:
在前一个定理的基础上,如果我们清楚地知道我们期望的最终(goal)状态的位置以及反推需要明确的状态间关系,那么可以认为是一个确定性的价值迭代。此时,我们可以把问题分解成一些列的子问题,从最终目标状态开始分析,逐渐往回推,直至推至所有状态。
示例——最短路径
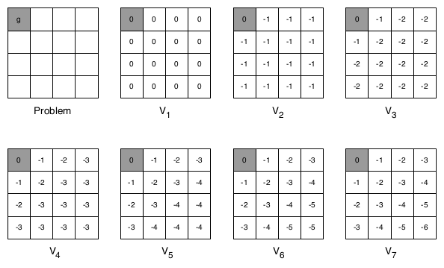
问题:如何在一个4*4的方格世界中,找到任一一个方格到最左上角方格的最短路径
解决方案1:确定性的价值迭代
简要思路:在已知左上角为最终目标的情况下,我们可以从与左上角相邻的两个方格开始计算,因为这两个方格是可以仅通过1步就到达目标状态的状态,或者说目标状态是这两个状态的后继状态。最短路径可以量化为:每移动一步获得一个-1的即时奖励。为此我们可以更新与目标方格相邻的这两个方格的状态价值为-1。如此依次向右下角倒推,直至所有状态找到最短路径。
解决方案2:价值迭代
简要思路:并不确定最终状态在哪里,而是根据每一个状态的最优后续状态价值来更新该状态的最佳状态价值,这里强调的是每一个。多次迭代最终收敛。这也是根据一般适用性的价值迭代。在这种情况下,就算不知道目标状态在哪里,这套系统同样可以工作。
价值迭代 value iteration
问题:寻找最优策略π
解决方案:从初始状态价值开始同步迭代计算,最终收敛,整个过程中没有遵循任何策略。
注意:与策略迭代不同,在值迭代过程中,算法不会给出明确的策略,迭代过程其间得到的价值函数,不对应任何策略。
价值迭代虽然不需要策略参与,但仍然需要知道状态之间的转移概率,也就是需要知道模型。
小结 - 动态规划
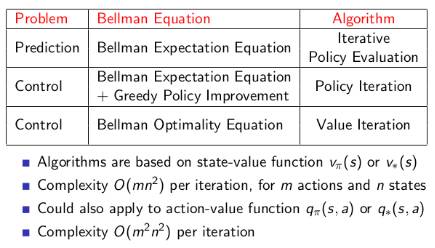
预测问题:在给定策略下迭代计算价值函数。控制问题:策略迭代寻找最优策略问题则先在给定或随机策略下计算状态价值函数,根据状态函数贪婪更新策略,多次反复找到最优策略;单纯使用价值迭代,全程没有策略参与也可以获得最优策略,但需要知道状态转移矩阵,即状态s在行为a后到达的所有后续状态及概率。
使用状态价值函数或行为价值函数两种价值迭代的算法时间复杂度都较大,为
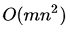
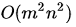
动态规划的一些扩展
异步动态规划 Asynchronous Dynamic Programming
几个可能改进的点子
原位动态规划(In-place dynamic programming):直接原地更新下一个状态的v值,而不像同步迭代那样需要额外存储新的v值。在这种情况下,按何种次序更新状态价值有时候会比较有意义。
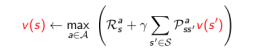
重要状态优先更新(Priortised Sweeping):对那些重要的状态优先更新。
使用Bellman error:
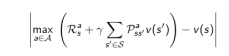
来确定哪些状态是比较重要的。Bellman error 反映的是当前的状态价值与更新后的状态价值差的绝对值。Bellman error越大,越有必要优先更新。对那些Bellman error较大的状态进行备份。这种算法使用优先级队列能够较得到有效的实现。
Real-time dynamic programming:更新那些仅与个体关系密切的状态,同时使用个体的经验来知道更新状态的选择。有些状态虽然理论上存在,但在现实中几乎不会出现。利用已有现实经验。
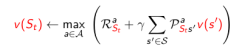
St是实际与Agent相关或者说Agent经历的状态,可以省去关于那些仅存在理论上的状态的计算。
采样更新 Sample Backups
动态规划使用full-width backups。意味着使用DP算法,对于每一次状态更新,都要考虑到其所有后继状态及所有可能的行为,同时还要使用MDP中的状态转移矩阵、奖励函数(信息)。DP解决MDP问题的这一特点决定了其对中等规模(百万级别的状态数)的问题较为有效,对于更大规模的问题,会带来Bellman维度灾难。
因此在面对大规模MDP问题是,需要寻找更加实际可操作的算法,主要的思想是Sample Backups,后续会详细介绍。这类算法的优点是不需要完整掌握MDP的条件(例如奖励机制、状态转移矩阵等),通过Sampling(举样)可以打破维度灾难,反向更新状态函数的开销是常数级别的,与状态数无关。
近似动态规划 Approximate Dynamic Programming
使用其他技术手段(例如神经网络)建立一个参数较少,消耗计算资源较少、同时虽然不完全精确但却够用的近似价值函数:
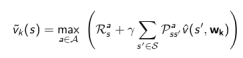
注:本讲的内容主要还是在于理解强化学习的基本概念,各种Bellman方程,在实际应用中,很少使用动态规划来解决大规模强化学习问题。
敬请关注专知公众号(扫一扫最下方二维码或者最上方专知蓝字关注),以及专知网站www.zhuanzhi.ai, 第一时间得到的《强化学习》第四讲 不基于模型的预测!
作者简介:
叶强,眼科专家,上海交通大学医学博士, 工学学士,现从事医学+AI相关的研究工作。
特注:
请登录www.zhuanzhi.ai或者点击阅读原文,
顶端搜索“强化学习” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与强化学习的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“强化学习” 就可以获取深度强化学习知识资料全集(论文/代码/教程/视频/文章等)的pdf文档!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请感兴趣的同学,扫一扫下面群二维码,加入到专知-深度强化学习交流群!

请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



