【论文笔记】用于Web级推荐系统的图卷积神经网络

近来,图卷积神经网络的出现,使得应用图结构数据进行推荐(例如,利用用户到项目的交互图以及社交图)有了新的进展,但是将训练图结构化数据的节点(node)嵌入扩展到具有数十亿个节点和数百亿个边缘的图形,还是一项个很大的挑战。本篇论文的作者基于random walks策略,提出了一个高度可扩展的图卷积(GCN)框架—PinSage,将图结构化数据的深度学习方法扩展到具有数十亿用户的Web级推荐任务中。


论文地址:
https://arxiv.org/pdf/1806.01973.pdf
动机
传统基于GCN的推荐系统需要在训练期间对完整图拉夫拉斯算子进行计算,当基础图具有数十亿个节点且结构不断发展时无法进行计算,导致GCN很难扩展。因此,作者提出了一个高度可扩展的GCN框架-PinSage,可以运行在一个包含30亿个节点和180亿个边缘的大型图形上。
核心思想
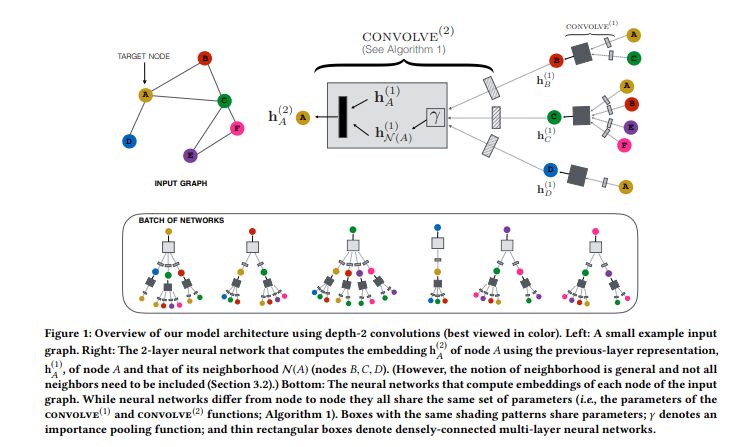
PinSage的核心思想是使用局部图卷积来表示图结构化数据(Pinterest上的pin和board组成二分图)的节·点(node)。并且使用多个卷积模块来将节点局部的邻域特征信息进行聚合,来生成这个节点的 embedding。这些 embedding 可以用于推荐系统,通过最近邻查找来生成推荐,或是作为用评分来推荐的机器学习系统的特征。
丨最近邻查找:给定一个查询物品 q,使用 K-近邻的方式来查找查询物品 embedding 的 K 个邻居的嵌入
符号表示
Pinterest:是世界上最大的图片社交分享网站,用户可以共享和保存其他用户和组织共享的照片。
pins:可以理解为Pinterest中用户发布的帖子(相当于item),用 I 表示
board:包含了pins组成的集合,分类储存pins.用C表示。
V = I ∪C:表示图中的所有节点集合,pin 和 board 节点不做区分。
u:表示图结构中的目标节点
x_u:表示特征,包括视觉特征或者上下文信息。
N(u):表示节点的邻域集合(相邻节点)
h_v:节点u的邻域节点v的embedding表示
h_u:节点u的的embedding表示
框架
PinSage算法使用局部卷积模块对节点生成 embeddings。首先输入节点的特征,然后通过神经网络进行学习,神经网络会变换并聚合整个图上的特征来计算节点的 embeddings。主要分为三部分,获得目标节点的邻域节点集合、局部卷积获得新的节点embedding以及多个卷积模块的聚合。
Importance-based neighborhoods
在PinSage算法中,作者定义了基于重要性的邻域,采用随机游走(random walks)的策略来生成节点u的领域,将节点u的邻域定义为对节点u影响最大的T个节点。并且通过计算随机游走对顶点的访问次数的 𝐿1 归一化值来定义领域节点的重要性,按对顶点的访问次数排序后取top-T个节点作为当前节点的领域。
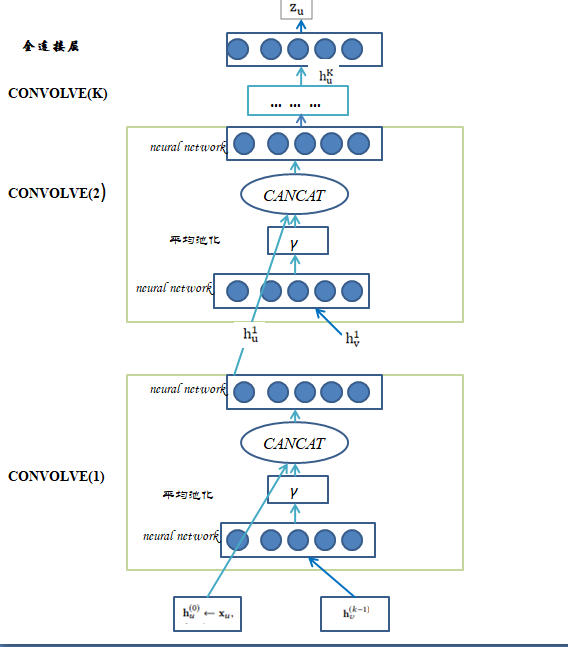
局部卷积模块(CONVOLVE)
在得到顶点的邻域节点集合之后,如何获得该顶点的embedding呢?为了生成顶点u的embedding,文章提出了局部卷积的概念,得到特定的节点的包含有限邻域节点的子图,在子图上构造局部卷积,然后同一卷积层的不同节点共享同样的局部卷积参数。
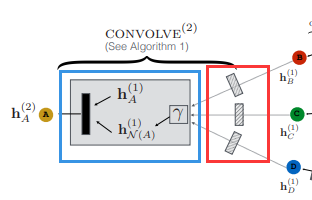
局部卷积操作是算法中最核心的部分,输入为目标节点u的embedding h_u以及节点u对应邻域节点的embedding h_v,输出为包含邻域信息的节点u的新的embedding。

局部卷积操作最要包含三个步骤:
step1:通过神经网络对节点u对应邻域节点 v 的embedding值 h_v进行映射,得到u的邻域集合的表示(上图中的红色框),并且通过平均池化操作(图中的γ)来考虑邻域节点的重要性(权重为在生成邻域集合时的𝐿1 归一化值)。
step2:对节点u的embedding表示与邻域节点的embedding表示h_{N(u)}通过 concate操作拼接起来,送入神经网络进行映射,得到节点u的新的embedding表示(上图中蓝色方框)。
step3:对输出的节点u的embedding做L2归一化。,
Stacking convolutions
在使用局部卷积得到节点的embedding表示之后,文章提出在每个节点上堆叠卷积来获得更多表示节点 u的局部邻域结构信息。简言之,将上一个局部卷积模块的输出(节点的embedding表示)传入下一个卷积模块作为输入。具体流程如下:

在堆叠卷积模块主要包含两部分,第一部分获得每一层节点的邻域集合(1-6步);第二部分是循环计算每一层的CONVOLVE,并在最后一层通过全连接层进行映射得到最终的embedding(8-17)。
丨卷积层的权重在节点间共享,在层与层之间不共享
训练
负样本采样
为了使模型训练获得好的参数,在负样本采样中,作者并没有在整个样本集上均匀采样,而是提出了“hard negative items”对于每个正训练样本(物品对(q,i))加入了”hard”负例(与查询物品 q 有某种关联,但是又不与物品 i 有关联的物品),下图为查询物品、正例以及“hard”负例示例:

丨Note:在训练的第一轮未加入”hard”负例
损失函数
模型要学习的参数为每个卷积层的权重和偏置(Q^(k),q^(k),W^(k),w^(k),∀k∈{1,…,K});最后的全连接层的参数( G^1,G^2,g)。文章中选择 max-margin ranking loss 作为损失函数进行优化,学习这些参数。优化目标为最大化正例之间的内积(查询项q的embedding与推荐的相关项i的embedding之间的距离),确保负例之间的内积(查询项q的embedding与不相关物品的embedding之间的距离)小于通过提前定义好的边界划分出的正例的内积。对于单个节点对的embeddings (z_q,z_i):(q,i)∈L 的损失函数为:
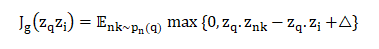
其中:
(q,i)∈L ,表示当查询 q时,物品 i是一个好的推荐候选项。
P_n(q) 表示物品 q 的负样本分布
Δ 表示 margin 超参数
MapReduce 架构
为了避免节点在针对不同的目标节点生成 embedding 的时候被很多层重复计算多次,作者提出了 MapReduce 架构来避免重复架构问题。假设输入(”layer-0”)节点是 pins/items(layer-1 节点是 boards/contexts)。MR 有两个关键的组成部分:
一个 MapReduce 任务将所有的 pins 投影到一个低维隐空间中,在这个空间中会进行聚合操作(算法1,第一行)
另一个 MR 任务是将结果的 pins 表示和他们出现在的 boards 的 id 进行连接,然后通过 board 的邻居特征的池化来计算 board 的 embedding
并且,为了避免冗余计算,文中对于每个顶点的隐向量只计算一次。在获得 boards 的 embedding 之后,使用两个以上的 MR 任务,用同样的方法计算第二层 pins 的 embedding。
实验
参数设置
为了验证不同的参数对于模型效率的影响,文中进行了不同的batch size与邻域数量T的对比实现,表3、表4分别为为不同的batch size 与T值时,模型的对比结果:
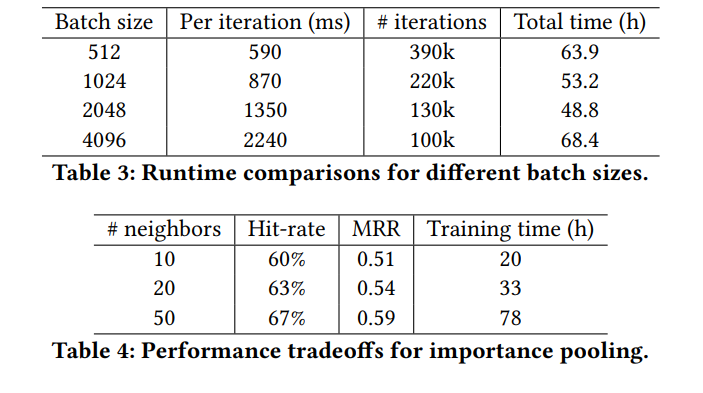
batch size : 为2048时训练效率最高
学习率:第一轮增大到一个峰值,再指数级减小
邻域T的大小:T=50是模型效果最好
所有卷积层的输出维度都相同,且与最后的全连接层输出的维度相同。
数据集
文中实验部分使用了12亿对正样本(每个batch有500个负样本和每个pin有6个hard负样本)。使用70%的标记样本(包含20%的board(以及这些board有关的所有的pins))作为训练集,10%的标记样本在调整超参数时使用,20%用于离线测试。
特征提取
Pinterest的每个pin的特征包含图片和一组文本注释(标题,说明)。为了得到每个pin q生成特征表示x_q,文中将视觉embedding(4,096个维度),文本注释embedding(256个维度)以及图中节点/pin的log值拼接起来。其中:
视觉embedding从使用VGG-16架构的分类网络的第六个全连接层得到。
文本注释embedding使用基于Word2Vec的模型进行训练模型,其中注释的上下文由其他与每个pin相关的注释组成。
评价指标
hit-rate:评估推荐的前 K个 items 中,有多少是能够命中用户实际偏好的。
Mean Reciprocal Rank (MRR):评估查询项目q的推荐项目中项目j的排名
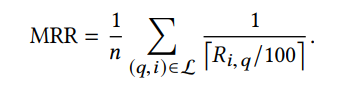
实验结果
为了更好地评估PinSage算法的性能,作者对比了以下基于内容的,基于图的深度学习方法,表1为模型对比结果:
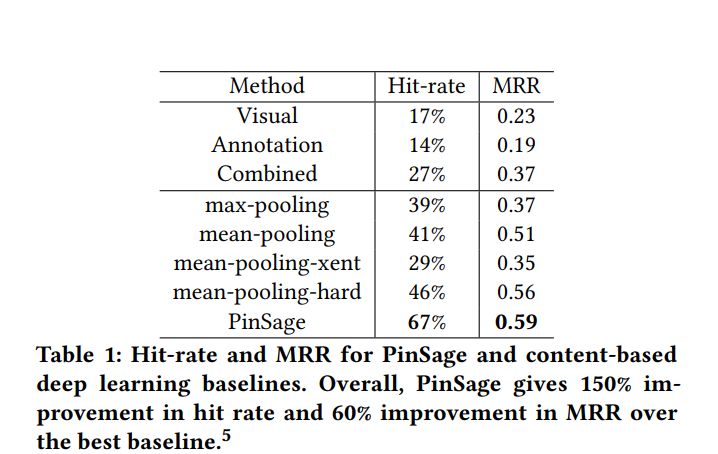
在表1中可以得到将视觉信息和文本信息结合起来要比单独使用一种信息要好得多(相对于视觉/注释,结合方法的改进幅度为60%)。
除了对比不同模型的hit-rate与MRR之外,文中还进行了用户研究(user study)来证明PinSage的有效性。用户研究即:向用户展示查询pin的图像,以及通过不同的推荐算法检索到的两个pin。然后要求用户选择两者中的哪一个候选pin与查询pin更相关。表2为各个模型的对比结果:
结论
PinSage是一种高度可扩展的GCN算法,能够为包含数十亿个对象的Web规模图中的节点学习嵌入。PinSage证明了图卷积方法可能会对推荐系统的发展产生影响,并且PinSage将来可以进一步扩展,以解决其他大规模的图表示学习问题,包括知识图推理和图聚类。
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



