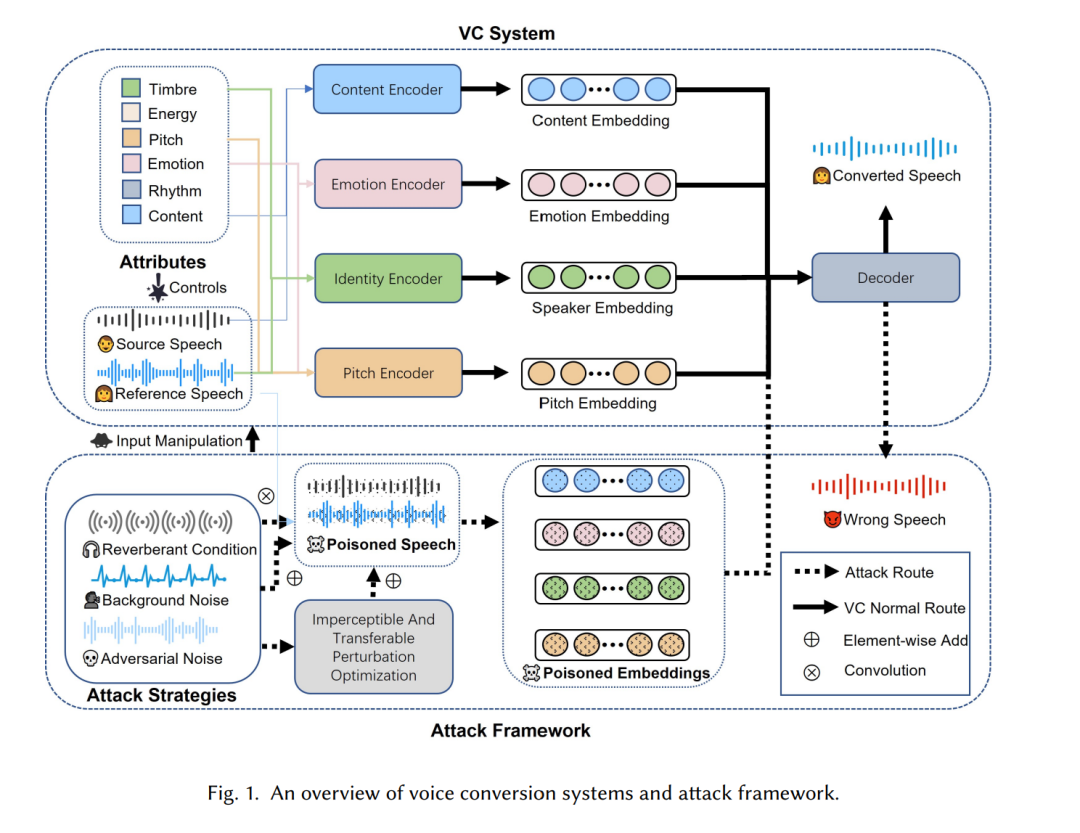
身份、口音、风格和情感是人类语音的重要组成部分。语音转换(Voice Conversion,VC)技术通过处理来自两个说话人的语音信号,并结合提示词、情感标签等辅助模态信息,在保持语言内容不变的同时,将一种副语言特征转换为另一种。近年来,VC 模型在生成质量和个性化能力方面取得了快速进展。这些发展引起了学界和工业界的广泛关注,并推动了其在多种应用场景中的使用,包括隐私保护、逝者声纹复现以及构音障碍语音恢复等。
然而,由于训练数据通常较为干净,现有 VC 模型往往只能学习到非鲁棒特征。这导致其在真实世界场景中面对退化语音输入时表现不佳,例如存在附加噪声、混响、对抗攻击,甚至是微小扰动的情况。因此,VC 系统在实际部署中迫切需要具备更强的鲁棒性。尽管近期已有研究尝试探索 VC 系统面临的潜在攻击方式及相应的防御机制,但对于 VC 模型在输入操控条件下鲁棒性的系统性理解仍然存在显著空缺。 围绕这一问题,仍有诸多关键疑问有待回答:例如,不同形式的输入退化攻击在多大程度上会改变 VC 模型的期望输出?现有防御方法从哪些角度应对这些攻击,又应如何根据其防御状态进行分类?攻击与防御策略是否仍存在进一步优化的空间?
为回答上述问题,本文从输入操控的视角对现有攻击与防御方法进行了系统分类,并从可懂度、自然度、音色相似性以及主观感知四个维度评估了退化输入语音对 VC 系统性能的影响。最后,本文总结了当前研究中仍然存在的开放问题,并展望了未来可能的研究方向。
1 引言
高保真且个性化的音频生成始终是音频领域的研究热点。语音合成作为一项从多种输入信号(如语音、语言、情感、歌曲等)中提取表征信息并以语音形式呈现的任务,长期以来受到社会各界的广泛关注。其中,语音转换(Voice Conversion,VC)是一类典型的风格迁移技术,其目标是在保留源说话人语言内容的前提下,将源语音的表达方式转换为具有目标说话人旋律特征的语音表现形式 [87]。换言之,VC 模型通过修改源说话人的副语言特征(如音高、音色和风格),同时保持与说话人无关的语言内容信息不变。
通常,根据任务类型的不同,大量 VC 工作可以归纳为三类:说话人语音转换(speaker VC)、情感语音转换(emotional VC)以及歌声转换(singing VC)。作为基础说话人 VC 任务的变体,情感 VC 与歌声 VC 面临更高的挑战。情感 VC 侧重于在保留其他信息的同时迁移目标说话人所表达的情感状态;而歌声 VC 则更加关注音高、能量以及歌手风格等基础要素的建模。因此,这两类任务对特征解耦能力提出了更高要求。进一步地,说话人 VC 已扩展至多种细分任务,例如低资源语音转换、方言转换、耳语转语音以及语音翻译中的子模块等。这些丰富的任务形式引起了学术界的广泛兴趣,并推动了多样化技术的发展,为语音转换在音频编辑 [100]、构音障碍语音恢复 [93]、隐私保护 [23] 以及数据增强 [83] 等多种应用场景奠定了基础。
然而,现有大量 VC 研究主要依赖于干净语音数据进行训练,在真实世界场景中往往因神经网络对附加噪声、混响、对抗攻击,甚至微小扰动的脆弱性而表现不佳,产生不理想甚至非预期的结果。近期研究表明,基于 L∞L_\inftyL∞ 范数约束 [41,99]、FGSM 方法 [18]、GAN 框架 [25]、频带掩码 [62]、频率反向声压级 [114] 以及心理声学模型 [55] 生成的对抗样本,均证明了对 VC 模型实施攻击的可行性。其中,最成功的对抗噪声甚至能够在保持隐蔽性的情况下改变语音内容和说话人身份 [14],并具备对未知 VC 模型的迁移能力或在实时场景下的高攻击效率。
此外,诸如白噪声、街道噪声等加性噪声,以及通过 pyroomacoustics 工具包模拟的卷积噪声,也会对转换后的语音数据引入失真。这类退化会导致一系列偏差,例如语言内容的错误表征以及情感变化的模糊化,从而潜在地影响个体特征的表达效果或患者病理语音的矫正效果。为应对这些隐性威胁,研究者逐步提出了诸如高频噪声消除 [67]、噪声不变表征学习 [26,112] 以及级联预训练模型策略 [20,21] 等方法。根据是否对退化输入语音进行预处理,这些策略可进一步划分为主动防御与被动防御两类。主动防御通过在训练阶段学习鲁棒的特征分布,以提升 VC 模型对未知数据的适应能力;而被动防御则依赖多种语音增强技术,在语音输入 VC 模型之前对其进行清洗处理。尽管这些方法已展现出一定成效,该研究方向仍缺乏统一的理论框架与系统性的综合研究。因此,对现有工作进行系统归纳,并探索在真实世界场景下实现鲁棒 VC 的潜在策略,具有重要研究价值。
从历史上看,语音转换研究主要聚焦于方法演进 [84]、网络结构选择 [6] 以及生成对抗网络等新兴生成技术 [24]。尽管近年来已有综述涉及深度伪造检测 [49] 和语音克隆相关术语 [2],但针对 VC 系统鲁棒性的专门分析仍然缺失。这与自然语言处理 [97]、自动语音识别 [27] 以及说话人验证 [104] 等相关领域形成鲜明对比,这些领域已积累了大量关于系统鲁棒性的综述研究。如表 1 所示,尽管其他音频领域已受益于系统化的安全性分析,但针对语音转换系统鲁棒性的综合性综述仍然极为匮乏。不同于以往较为零散的讨论 [43],本文系统性地探讨了三类语音操控技术,重点分析对抗攻击策略及其防御特征。
本文的主要贡献总结如下: * 据我们所知,本文是首篇系统性聚焦于输入数据操控条件下语音转换模型鲁棒性的综合综述,旨在引导学界关注这一关键但长期被忽视的研究方向。 * 我们基于输入操控技术提出了一种新的 VC 脆弱性分类体系,并构建了统一的评估框架,融合了可懂度、音色相似性与主观感知等多维指标,以规范鲁棒性评测。 * 我们展望了构建鲁棒 VC 模型的潜在路径,包括在不可感知性、攻击成功率与迁移性之间取得平衡的更强攻击策略,以及结合大规模语音模型的主动与被动防御机制。本文期望为安全 VC 架构的设计提供参考。
本文结构安排如下:第 2 节介绍语音转换系统的背景知识,包括解耦语音特征的低维表示提取、语音转换任务类型以及副语言参数调控;第 3 节从输入操控角度综述语音转换中的攻击方法分类;第 4 节阐述鲁棒 VC 系统的概念,并介绍现有的被动与主动防御方法;第 5 节介绍常用数据集、评测框架及实验结果;第 6 节总结语音转换面临的主要挑战,并讨论鲁棒 VC 研究的未来发展方向;最后一节对全文进行总结。