在小公司如何做一名成功的数据科学家?

大数文摘出品
来源:medium
编译:王媛媛、刘思佳
小公司需要数据科学家么?
可能只有长期混迹数据圈的老司机才有资格回答这个问题。
本文作者Randy Au,已经在15-150人规模的公司工作了近12年,被冠于“数据分析师、工程师、偶尔还有科学家”的各种头衔。
作者是社会科学出身,有一些自然语言处理,应用数学和工商管理经验。总而言之,什么都会一点。
以下是他关于此问题的看法:
成为第一个“数据全能选手”

小公司不需要数据科学家,但他们需要一个“数据全能选手”。他们可能称这项工作为“数据科学家/工程师/分析师/忍者”,诸如此类。
一家20-60人规模的公司,有足够的客户,丰富的数据和专业化的岗位,只需要招一个能够使用数据来提供有用的业务洞察力的人。
职位的头衔不重要,但职位描述往往是各种各样的混合:
理解我们拥有的数据
帮助构建我们的数据系统
帮助我们进行数据驱动/运行实验
发展业务
可能与任何事物相关或不相关的教育/认证
通常情况下他们并不完全了解需要怎样的人才。只有一种普遍意义上的“我们有数据,看起来很有用,但是缺少转化为价值的技能。”
实际上,在这个职位上的人需要同时做两件大事:
今天-帮助公司取得成功
明天-打造数据驱动型公司
今天-帮助公司取得成功

初创公司充满了不确定性。他们不确定客户是谁,生产系统可能很困难,不知道客户对产品做了什么,不知道如何使用拥有的数据做出决策,不知道拥有的数据是否有用。
对问题的巧妙回答可以带来更明智的决策,并希望每个人都梦想成为神话般的曲棍球棒。难题是大多数问题都不适宜用花哨的方法。有用的通常是老办法和基于定性方法而不是定量。
在优化现有流程时,大多数DS方法都是最强大的,它们可以在获取客户,转化客户,客户粘度和客户支出等方面实现5%,10%甚至25%的增长。A / B测试,推荐系统,ML分类器,所有这些都有助于优化。收益是真实的,可量化的,并且可能是显着的,但早期可能会更重要的事要做。
早期最大的影响往往是业务洞察。洞察力从根本上改变了公司做的事情。它们来自很常见的事情,例如研究用户偏好/行为,为销售人员揭示新的营销概念,或帮助产品团队意识到Twitter上最受憎恨的功能实际上被90%的付费客户使用。
我对“帮助公司”角色的看法是:“数据全能选手”是一种力量倍增器 。企业内部的人有问题,工作就是帮助他们解决问题。
成为第一个“数据全能选手”=成为“有数据的科学家”
作为一名科学家对我来说意味着你遇到一个难题,一个研究型问题,你可以用任何方法来找到对这个问题的坚实答案。
作为数据科学家,我们倾向于使用定量方法和从系统收集的数据来回答问题,但这不是获得洞察力的唯一途径。有时你精尽全力观察或询问用户(定性方法),或者你出去收集数据(实验和调查),或者你盯住别人(竞争分析)。
一个好的科学家不会通过他们的方法来定义自己,第一个数据全能选手(或者任何数据全能选手)也不会。
我们的目标是满足紧迫的业务需求:“为什么没有人使用我们的产品?”“我们的回报怎么这么高?”我们是否应该进行这种昂贵的销售呢?““是什么导致客户流失?”“什么是客户的终身价值,是什么推动了这一点?”
明天-打造数据驱动型公司
我看到的一个常见的陷阱是来自数据科学计划的人加入这些职位,期望使用像Spark这样的性感东西并应用RNN来完成他们的工作。但很遗憾,不匹配是非常残酷的。
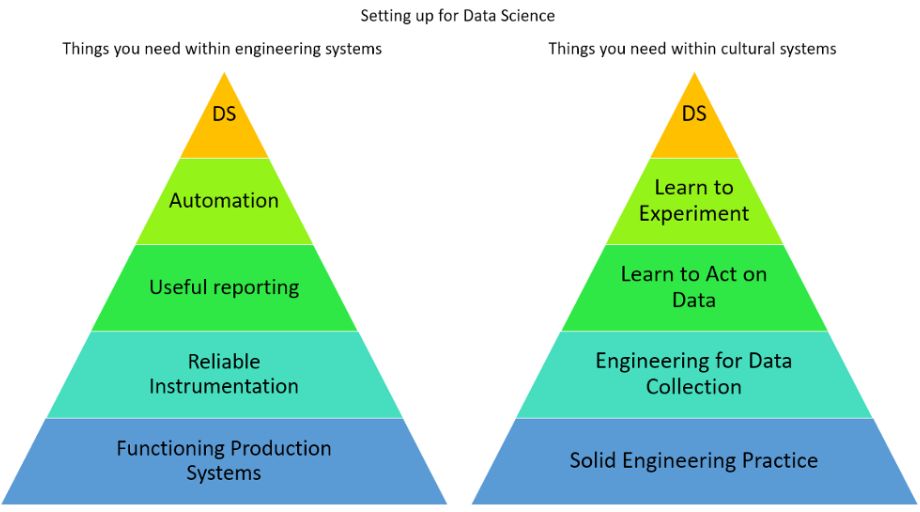
花哨的“数据科学”方法依赖于大量的东西,不要指望每一层在移动到下一层之前都“完成”。把颜色想象成“ 花费的时间”。
作为第一个被雇用为处理数据的人,金字塔的任何一层都不太可能是坚固的。这是一个多年,跨职能,全公司的努力才得以实现。并行培养这些技能是工作的重要部分。
请注意,在典型的业务中,无论底层的稳定性如何,你都会尝试同时在金字塔上下执行操作。我已经为脆弱的新系统构建了大量的仪表板和分类器,你也会这样做。
固态生产系统和工程实践
比如在一个坚固的“工程驾驶室”,如果系统出现故障,而且无法获得真正测量系统的行为,这时候此会希望根据需要提供帮助。
你拥有的“数据工程师”头衔越多,在帮助构建坚固系统方面所扮演的角色就越重要。人们自然会问你关于输入的问题,如PostgresSQL vs MySQL,AWS vs GCP,Spark vs Redshift等,帮助这些可以增加持久延续的价值。如果没有足够的Eng资源则必须自己来设置系统并运行它们。
可靠的仪器仪表
获得可靠的仪器数据人员最关键的事情。这是一个无休止的程序,从挑选框架(多个)到收集系统和用户数据,确保工程师学习如何实现事物而不计算错误,确保数据库和日志正在做正确的事情(TM),并确保你在计算你认为正确的东西。
同时专门添加系统用来收集和报告数据,这些将需要由某人(也许是你)组合和管理。
在文化方面,会不断有人来询问数据的可靠性以及如何处理这些信息,他们会要求解释和深度剖析系统,直到他们自己非常了解。
当你制作报告时,这种文化培训本身就是一个漫长的过程,人们发现与其他系统不一致并且得到的结果与他们对现实的看法不相符时,可能现实是错误的,也可能是正确的。
报告和处理数据

仪表板和报告不是一项有趣的工作,更不幸的是,它通常是整个公司人员每天观察公司健康状况的唯一方式,因此投资是必要的,目标是把可操作的信息交给可以采取行动的人。
一开始,大多数仪表板和报告都是手动的,需要大量的迭代才能达到需求。虽然,自动化是一个很好的选择,但洞察力也是需要着重考虑的。
技术方面并不复杂,有许多服务平台可用于生成报告和仪表板,同时甚至可以使用自定义代码执行操作。
诀窍是让所有数据系统一起玩(HaHa),并在业务增长时最小化维护仪表板和报告的成本。
文化方面是事物有趣的地方。当你正在训练在这里的人们变得更加数据化,这也需要多年的工作和实践。
这里涉及大量的教育。你将教人们如何阅读A / B测试的结果,重要的差异意味着什么,解释信心或预测间隔是什么,解释为什么该图表“只是一个估计。你会提出有关样本量的问题,并且经常需要教会处理问题的方法。
如果人们关注仪表板上的数字,人们应该怎么做?就个人而言,我告诉他们来跟我讨论。他们的担忧可能是一个研究问题(或一个错误),而这就是研究“黄金”。这些人是这部分业务的领域专家,而我只是一个用SQL的书呆子。
自动化与实验

随着时间的推移,你将设置新功能何时消失的指标和仪表板。人们不可避免地会对功能的表现感到失望。
一旦人们习惯了获取信息并且可能会运行一些A / B测试用来使结果令人失望,那么当测试数据与人们的假设相反时,就会花费大量时间来验证数字是否正确。
有用的仪表板应该高度自动化,人们习惯使用数据来做出决策。
另一件有趣的事情我注意到,不管结果如何,在这个阶段,公司可以顺利地运行实验。他们学会设计他们知道自己会成功的测试(低风险),或者他们会“测试”他们100%知道他们将会发布的事情。
现在,作为科学家你可以通过这种行为呼唤人们。无论测试结果如何,它们都可以完全启动。虽然激进的变化往往测试不佳,但应该明确说明意图。
最后,数据科学
在经过漫长的旅程之后公司本身已经转变为数据驱动。他们有假设能够可靠地收集数据,并根据结果做出深思熟虑的决策。他们也更自给自足,可以阅读(并且可能创建)带有一些指导的仪表板,并且学会了何时担心以及如何提出问题。
在金字塔下面总会有更多事情需要做,但至少现在事情并没有随时发生。
现在你可以考虑打破花哨的算法......
或者也许有一个需要构建的数据仓库,因为你现在有太多系统导致分析查询无法进一步加速。
相关报道:
https://towardsdatascience.com/succeeding-as-a-data-scientist-in-small-companies-startups-92f59e22bd8c
志愿者介绍
后台回复“志愿者”加入我们









