句法分析综述

自然语言处理课程的第二天今天总算是补完了,课程的时间有限,但是内容繁多,而且都是能深挖的大坑,我的主要研究重点不在这里,所以无法展开,下面是我对这次课的简单介绍和笔记,来自深蓝学院。
按照百度百科的解释就是指对句子中的词语语法功能进行分析,例如“我来晚了”中,“我”是主语,“来”是谓语,“晚了”就是补语。这块内容其实在语言学等领域已经有比较深入的研究,但是随着数据的逐渐增多,这种分析就需要利用计算机自动化,句法分析就是这样诞生的。
那么句法分析到底有什么用呢?句法分析的结果是一句话的句子成分分析,其实就可以用来做知识发现和挖掘,例如“张三是李四的儿子”,通过句法分析,能够知道主谓宾等关系,能够抽取具体的消息,例如这里能够获取一个关系——张三和李四是父子关系,根据这些知识,无论是做知识图谱,还是做问答机器人等,都有大的作用,可见,句法分析是知识抽取的重要基础。
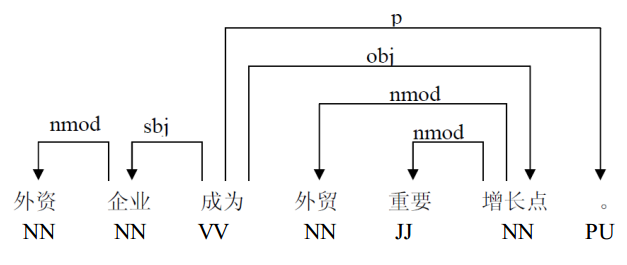
要深入研究句法分析,首先要知道,什么样的句法分析算是好的句法分析,所以句法分析方法的评价是首要思考的问题,目前进行句法分析,主要是用依存句法分析,其具体的评价指标有下面5种。
无标记依存正确率(UAS): 所有词中找到正确的头词所占的百分比,对于没有头词的根节点,只要根节点是对的,也将这个根节点算作其中(Nivre et al., 2004)
根正确率(RA): 所有句子中找到正确根的句子所占的百分比(Yamada and Matsumoto, 2003)
完全匹配率(CM): 所有句子中无标记依存结构完全正确的句子所占的百分比(Yamada and Matsumoto, 2003)
带标记依存正确率(LAS): 所有词中找到正确的头词并分配到正确标记的词所占的百分比,对于没有头词的根节点,只要根节点是对的,也将这个根节点算作其中(Nivre et al., 2004)
标记正确率(LA): 所有词中依存标记正确的词所占的百分比,只要根节点是对的,也将这个根节点算作其中(Nivre et al., 2004)
首先看看英文的,英文毕竟是目前自然语言处理的主力和焦点,而且英语具有相对严禁的语法结构。
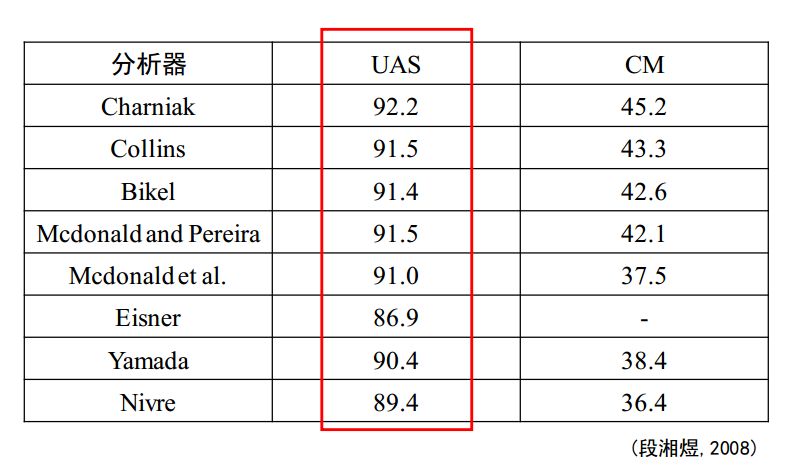
本身UAS的定义相比CM,就较弱,而且USA是无监督的方法,所以会比CM的正确率高很多。从CM看来,正确率不足50%,其实并不高,可见依存句法分析任重道远。
然后看中文,中文的自然语言处理相对比较难,一方面是中文本身的语法特性,另一方面中文分词的时候本就有误差,再进行句法分析会产生误差叠加。
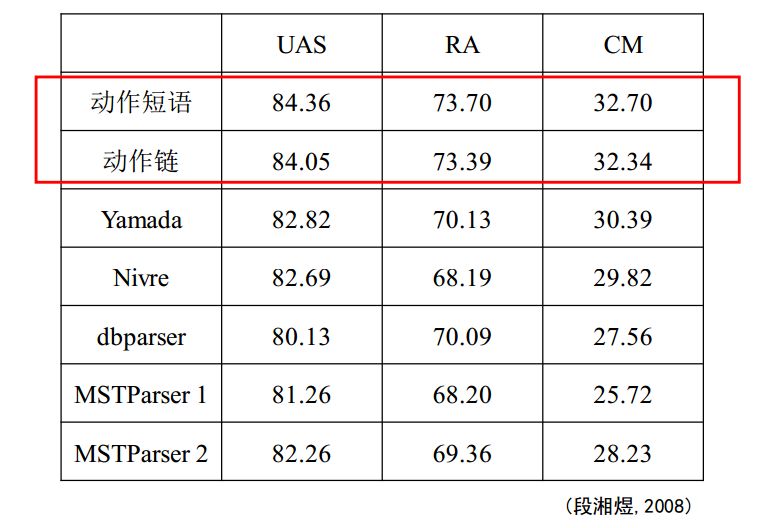
可以明显地看到,UAS和CM相比英文会更加低,说明中文的难度会比英文高,目前的潜力仍比较强。
综上所述,目前虽然已经有比较丰富的方法,但是准确度还有比较大的上升空间。
纠结了很久,想了要怎么写,要是详细些,这就不是公众号,是书了,要是不详细写,又怕你们骂我,于是我想了一个比较中和的方案,那就是我弄综述,参考文献给你们,有兴趣的你们自己去看,你们觉得怎么样?
句法分析,尤其针对依存句法分析,主要有基于动态规划,基于决策,基于融合的方法,当然还有一些扩展性的方法。
基于动态规划的方法
基于动态规划的方法,其实就是直接对依存树进行分析。早期,采用的方法是将依存图中的节点看作短语结构中的节点,从而可以应用上下文无关文法中成熟的CKY算法(Gaifman, 1965),然而时间复杂度非常可怕地达到了O(n5),后来提出了双词汇语法,其方法主要分为产生式方法(Eisner, 1996)和判别式方法(McDonald et al., 2005; McDonald, 2006),成功地将复杂度降低到O(n3)。
生成式和判别式和机器学习里面的生成和判别相同,生成式方法采用联合概率模型生成一系列依存句法树并赋予其概率分值,然后采用相关算法找到概率打分最高的分析结果作为最后的输出,说白了就是把概率分布求出来,然后根据概率分布进行下一步的分析和决策,在句法分析中将词与词之间的依存关系看作是成分结构,用类似于短语结构句法分析的方法来获取依存关系,其优点是能够得到每种决策的概率关系,决策更加全面,但是缺点是毕竟在相同的信息下,相比判别式整体决策精度可能会下降,其信息消耗花在进行计算概率分布上太多,导致最后拍板的时候受到约束。
判别式将依存分析看作是在一个依存图上寻找最大生成树(MST)的问题,该生成树满足上述三个约束条件:连通、单一父节点、无环,并不需要求概率分布,相比生成式,其优点是操作更为简单,可以运用更多的机器学习方法,而且出现下溢的情况更少(计算机在计算10的负好多次方的时候会出现下溢情况,精度会大大下降),复杂度相对较低,最终精度偏高。

基于决策的方法
基于决策的方法把分析过程看成是分析序列,建立词之间的联系,Covington(2001) 将决策的过程从句子的左端开始,逐个接受每个词,并尝试连接每个词与先前的词并将其作为头词或依存词,这种算法简单易懂,但是穷举法计算低效而且受到语料库约束较大;Yamada和Matsumoto(2003)通过将关系分为左依存、右依存和无依存三种情况进行动作分析从而得到句法结构;Nivre和Scholz(2004)在Yamada和Matsumoto(2003)的基础上提出新的数据结构和动作分析方法,依存句法分析器主要由一个三元组
从整体而言,基于决策的方法模型直观清晰,但是决策过程是贪婪的,局部的,精度收到很大限制,误差还会传递,所以仍存在较大问题。

基于融合的方法
机器学习中有基本的支持向量机、决策树等优秀的方法,但是却各有问题,于是提出了bagging,而基于融合的方法,将上述两个方法的优点结合。
基于搜索策略融合的方法(Duan et al., 2007)认为整个决策式依存句法分析过程可以看作是马尔科夫链。在每一步分析中会有若干个候选分析动作。句法分析的目标是在马尔科夫假设下寻找最有可能的分析动作序列,这样既可以利用丰富的上下文特征,又从全局的视角对决策动作建模,而算法的复杂度介于决策式方法和动态规划方法之间。按照他的说法进行实验得到的精度是这样的,可见优化了不少。
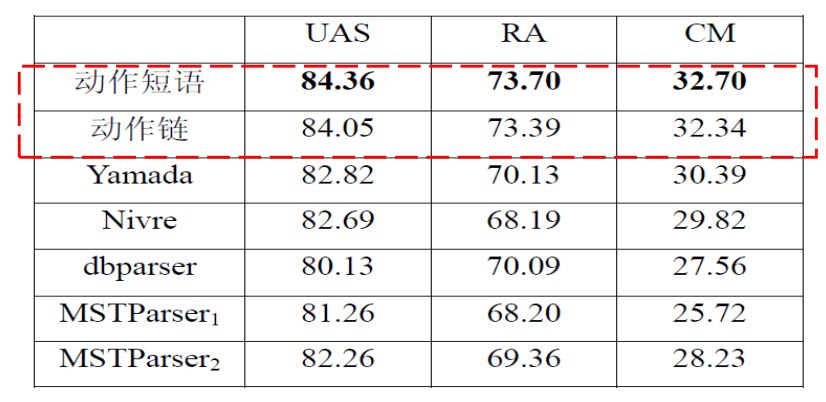
基于特征的融合方法(Nivre and McDonald, 2008)在McDonald和Nivre(2007)的“不同的句法分析器产生不同的错误”观点下提出两种思路,如下图所示(符号太复杂所以我就截图了):

最后还有基于模型的融合方法,Zhang和Clark(2008)将动态规划的方法和决策的方法进行加权组合。
扩展性工作
受限于树库规模较小,尤其是有标注的材料太少,所以句法分析的性能一直受到严重限制,目前有部分学者开始在有限的标注材料和较多的无标注材料下,使用半监督或者无监督的方法。

前人尚且已经在句法分析上有丰硕的成果,但是下面几个方面仍有巨大的研究价值和研究潜力。
句法分析的准确度仍十分有限;
句法分析的评价指标是否合理目前尚无定论,CoNLL仍有一些问题,而且有人针对多个角度,例如语种等,有无更加灵活的机制;
句法分析的鲁棒性仍不够高,和评价指标的灵活性类似;
句法分析的速度,目前仍无法投入大数据的实现,然而速度和精度的两大矛盾体的存在性导致两者相互制约;
运用在互联网中的研究仍处起步阶段,主要针对句法分析的下游技术,面向信息抽取的句法分析,面向社区问答的句法分析等;
句法分析并不是上游技术,需要依赖分词、词性标注等关键技术,这些技术同样具有较大误差等问题,于是误差的传递下句法分析的性能受到较大约束。
句法分析不是我的主要研究重点,也没太关注过这个重点,经过一些相关材料的阅读和学习,感觉还是有很大的研究空间,后续可能会有一些深入的阅读,扩充自己的知识面,也让自己应对各种问题多了一把新的有力武器。
参考文献
[1] M. Bansal and D. Klein. 2011. Web-scale Features for Full-Scale Parsing. In ACL-HLT.
[2] W. Chen, J. Kazama, K. Uchimoto and K. Torisawa. 2009. Improving Dependency Parsing with Subtrees from Auto-Parsed Data. In EMNLP.
[3] J. Eisner. 1996. Three new probabilistic models for dependency parsing: an exploration. In COLING.
[4] J. Hall, J. Nivre and J. Nilsson. 2006. Discriminative classifier for deterministic dependency parsing. In ACL.
[5] L. Huang, W. Jiang and Q. Liu. 2009. Bilingually-constrained (monolingual) shift-reduce parsing. In EMNLP.
[6] T. Koo, X. Carreras and M. Collins. 2008. Simple semi-supervised dependency parsing. In ACL.
[7] R. McDonald, K. Crammer, and F. Pereira. 2005. On-line large-margin training of dependency parsers. In ACL.
[8] J. Nivre and R. McDonald. 2008. Integrating graph-based and transition-based dependency parsers. In ACL.
[9] W. Jiang and Q. Liu. Dependency parsing and projection based on word-pair classification. In ACL, 2010.
[10] Y. Zhang and S. Clark. 2008. A tale of two parsers: investigating and combining graph-based and transition-based dependency parsing using beam-search. In EMNLP.
[11] H. Zhao, Y. Song, C. Kit and G. Zhou. 2009. Cross language dependency parsing using a bilingual lexicon. In ACL.
[12] G. Zhou, J. Zhao, K. Liu and L. Cai. 2011. Exploiting web-derived selectional preference to improve statistical dependency parsing. In ACL-HLT.
[13] R. Hwa, P. Resnik, A. Weinberg, C. Cabezas, and O. Kolak. Bootstrapping parsers via syntactic projection across parallel texts. In NLE, 2005.
[14] D. Klein and C. Manning. Corpus based induction of syntactic structures: Models of dependency and constituency. In ACL, 2004.
[15] J. Nivre and M. Scholz. Deterministic dependency parsing of english text. In COLING, 2004.
[16] J. M. Eisner. Three new probabilistic models for dependency parsing: an exploration. In COLING, 1996
[17] K. Ganchev, J. Gillenwater, and B. Taskar. Dependency grammar induction via bitext projection constraints. In ACL, 2009.
[18] R. McDonald and J. Nivre. 2007. Characterizing the errors of data-driven dependency parsing models. IN EMNLP.
[19] J. Nivre and R. McDonald. 2008. Integrating graph-based and transition-based dependency parsing. In ACL.
[20] L. Huang and K. Sagae. 2011. Dynamic programming for linear-time incremental parsing. In ACL. T. Koo and M. Collins. 2010. Efficient third-order dependency parsers. In ACL.
[21] K. Hayashi, T. Watanabe, M. Asahara, and Y. Matsumoto. Third-order variational reranking on packed-shared dependency forests. In EMNLP.
[22] 段湘煜. 基于分析动作建模的依存句法分析. 中国科学院自动化研究所博 士论文, 2008年
[22] 鉴萍. 依存句法分析方法研究与系统实现. 中国科学院自动化研究所博士 论文, 2010年
[23] 宗成庆. 统计自然语言理解. 清华大学出版社, 2008年
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏





