一年一版本,Sublime Text 3.2 正式发布
今天 Sublime HQ 正式发布了 Sublime Text 3.2 版本,距离上个重要版本(Sublime Text 3.1)更新已过去了将近一年的时间。
△Sublime Text 3.2
据官方介绍,该版本值得关注的新特性包括:
完美集成 Git
直观显示文件的增量变化(incremental diffing)
针对主题功能的变更和改进
对代码块(block caret)的支持
语法高亮新增对 Clojure, D, Go, Lua 语言的支持
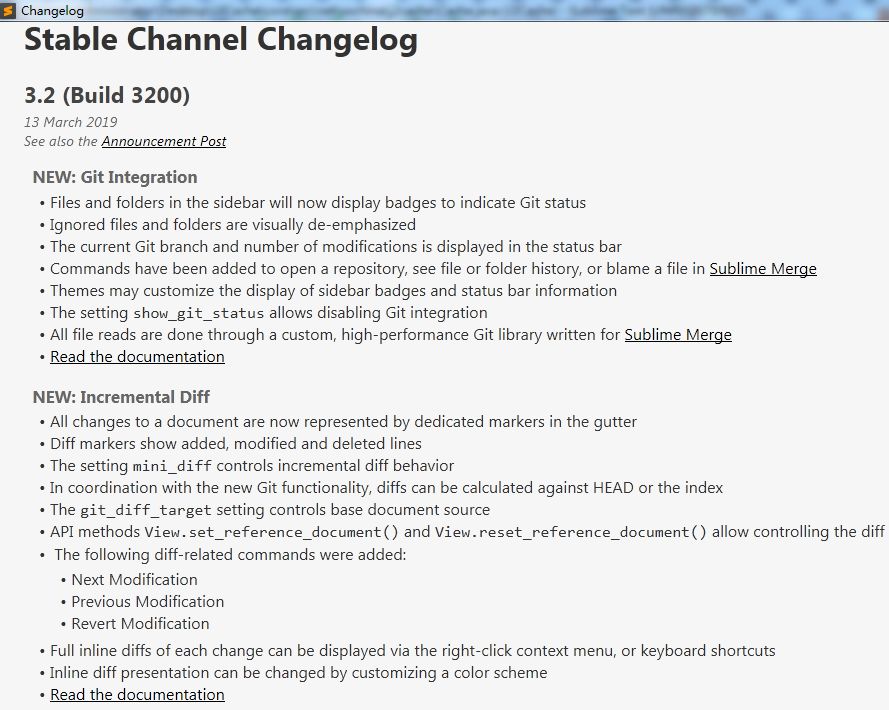
△3.2 更新日志
除此之外还有一系列的其他功能增强、稳定性改进和性能提升。
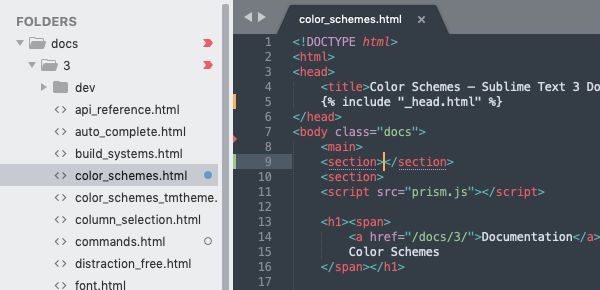
△该图显示了侧栏的 Git 状态标记,以及在编辑器中添加、修改和删除的行
详情请查看 https://www.sublimetext.com/blog/articles/sublime-text-3-point-2
Sublime Text 3.2 下载地址 https://www.sublimetext.com/3
开源中国征稿开始啦!
开源中国 www.oschina.net 是目前备受关注、具有强大影响力的开源技术社区,拥有超过 200 万的开源技术精英。我们传播开源的理念,推广开源项目,为 IT 开发者提供一个发现、使用、并交流开源技术的平台。
现在我们开始对外征稿啦!如果你有优秀的技术文章想要分享,热点的行业资讯需要报道等等,欢迎联系开源中国进行投稿。投稿详情及联系方式请参见:我要投稿


「好看」一下,分享给更多人↓↓↓
登录查看更多
相关内容

Git 是一个为了更好地管理 Linux 内核开发而创立的分布式版本控制和软件配置管理软件。 国内外知名 Git 代码托管网站有:
http://GitHub.com
http://Coding.net
http://code.csdn.net ...





相关VIP内容
相关资讯
相关论文