想了解机器学习?这 3 种算法你必须要知道
点击上方“CSDN”,选择“置顶公众号”
关键时刻,第一时间送达!
假设有一些数据相关的问题亟待你解决。在此之前你听说过机器学习算法可以帮助解决这些问题,于是你想借此机会尝试一番,却苦于在此领域没有任何经验或知识。 你开始谷歌一些术语,如“机器学习模型”和“机器学习方法论”,但一段时间后,你发现自己完全迷失在了不同算法之间,于是你准备放弃。
朋友,请坚持下去!
幸运的是,在这篇文章中我将介绍三大类的机器学习算法,针对大范围的数据科学问题,相信你都能满怀自信去解决。
在接下来的文章中,我们将讨论决策树、聚类算法和回归,指出它们之间的差异,并找出如何为你的案例选择最合适的模型。
有监督的学习 vs. 无监督的学习
理解机器学习的基础,就是要学会对有监督的学习和无监督的学习进行分类,因为机器学习中的任何一个问题,都属于这两大类的范畴。
在有监督学习的情况下,我们有一个数据集,它们将作为输入提供给一些算法。但前提是,我们已经知道正确输出的格式应该是什么样子(假设输入和输出之间存在一些关系)。
我们随后将看到的回归和分类问题都属于这个类别。
另一方面,在我们不知道输出应该是什么样子的情况下,就应该使用无监督学习。事实上,我们需要从输入变量的影响未知的数据中推导出正确的结构。聚类问题是这个类别的主要代表。
为了使上面的分类更清晰,我会列举一些实际的问题,并试着对它们进行相应的分类。
示例一
假设你在经营一家房地产公司。考虑到新房子的特性,你要根据你以前记录的其他房屋的销售量来预测它的售价是多少。你输入的数据集包括多个房子的特性,比如卫生间的数量和大小等,而你想预测的变量(通常称为“目标变量”)就是价格。预测房屋的售价是一个有监督学习问题,更确切地说,是回归问题。
示例二
假设一个医学实验的目的是预测一个人是否会因为一些体质测量和遗传导致近视程度加深。在这种情况下,输入的数据集是这个人的体质特征,而目标变量有两种:
1 表示可能加深近视,而 0 表示不太可能。预测一个人是否会加深近视也是一个有监督学习问题,更确切地说,是分类问题。
示例三
假设你的公司拥有很多客户。根据他们最近与贵公司的互动情况、他们近期购买的产品以及他们的人口统计数据,你想要形成相似顾客的群体,以便以不同的方式应对他们 - 例如向他们中的一些人提供独家折扣券。在这种情况下,你将使用上述提及的特征作为算法的输入,而算法将决定应该形成的组的数量或类别。这显然是一个无监督学习的例子,因为我们没有任何关于输出会如何的线索,完全不知道结果会怎样。
接下来,我将介绍一些更具体的算法......
回归
首先,回归不是一个单一的监督学习技术,而是一个很多技术所属的完整类别。
回归的主要思想是给定一些输入变量,我们要预测目标值。在回归的情况下,目标变量是连续的 - 这意味着它可以在指定的范围内取任何值。另一方面,输入变量可以是离散的也可以是连续的。
在回归技术中,最流行的是线性回归和逻辑回归。让我们仔细研究一下。
线性回归
在线性回归中,我们尝试在输入变量和目标变量之间构建一段关系,并将这种关系用条直线表示,我们通常将其称为回归线。
例如,假设我们有两个输入变量 X1 和 X2,还有一个目标变量 Y,它们的关系可以用数学公式表示如下:
Y = a * X1 + b*X2 +c
假设 X1 和 X2 的值已知,我们需要将 a,b 和 c 进行调整,从而使 Y 能尽可能的接近真实值。
举个例子!
假设我们拥有著名的 Iris 数据集,它提供了一些方法,能通过花朵的花萼大小以及花瓣大小判断花朵的类别,如:Setosa,Versicolor 和 Virginica。
使用 R 软件,假设花瓣的宽度和长度已给定,我们将实施线性回归来预测萼片的长度。
在数学上,我们会通过以下公式来获取 a、b 值:
SepalLength = a * PetalWidth + b* PetalLength +c
相应的代码如下所示:
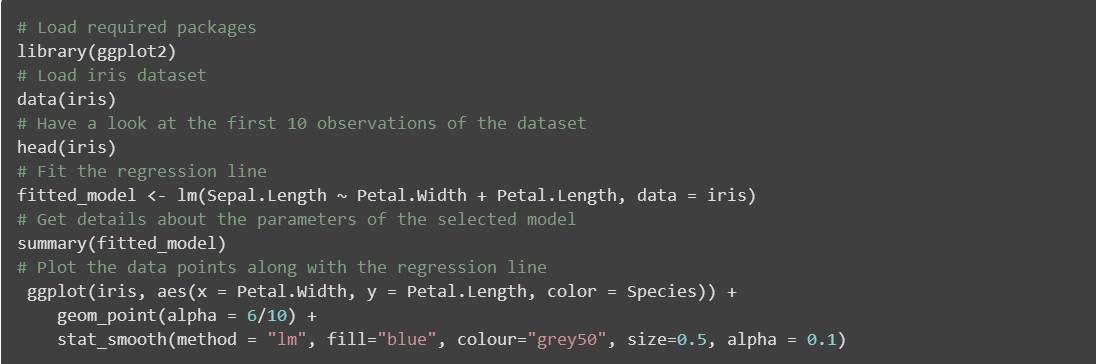
线性回归的结果显示在下列图表中,其中黑点表示初始数据点,蓝线表示拟合回归直线,由此得出估算值:a= -0.31955,b = 0.54178 和 c = 4.19058,这个结果可能最接近实际值,即花萼的真实长度。
接下来,只要将花瓣长度和花瓣宽度的值应用到定义的线性关系中,就可以对花萼长度进行预测了。
逻辑回归
主要思想与线性回归完全相同。不同点是逻辑回归的回归线不再是直的。
我们要建立的数学关系是以下形式的:
Y=g(a*X1+b*X2)
g() 是一个对数函数。
根据该逻辑函数的性质,Y 是连续的,范围是 [0,1],可以被解释为一个事件发生的概率。
再举个例子!
这一次我们研究 mtcars 数据集,包含 1973-1974 年间 32 种汽车制造的汽车设计、十个性能指标以及油耗。
使用 R,我们将在测量 V/S 和每英里油耗的基础上预测汽车的变速器是自动(AM = 0)还是手动(AM = 1)的概率。
am = g(a * mpg + b* vs +c):

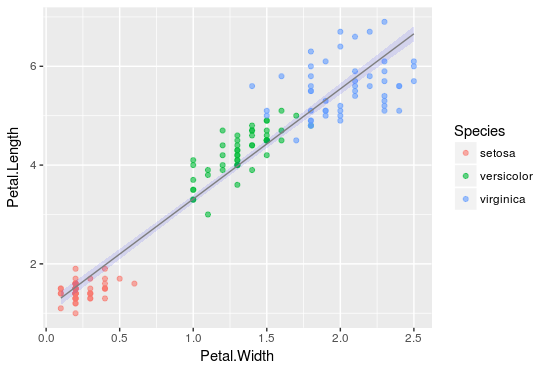
如下图所示,其中黑点代表数据集的初始点,蓝线代表闭合的对数回归线。估计 a = 0.5359,b = -2.7957,c = - 9.9183
我们可以观察到,和线性回归一样,对数回归的输出值回归线也在区间 [0,1] 内。
对于任何新汽车的测量 V/S 和每英里油耗,我们可以预测这辆汽车将使用自动变速器。这是不是准确得吓人?
决策树
决策树是我们要研究的第二种机器学习算法。它们被分成回归树和分类树,因此可以用于监督式学习问题。
无可否认,决策树是最直观的算法之一,因为它们模仿人们在多数情况下的决策方式。他们基本上做的是在每种情况下绘制所有可能路径的“地图”,并给出相应的结果。
图形表示有助于更好地理解我们正在探讨的内容。
基于像上面这样的树,该算法可以根据相应标准中的值来决定在每个步骤要采用的路径。算法所选择的划分标准以及每个级别的相应阈值的策略,取决于候选变量对于目标变量的信息量多少,以及哪个设置可以最小化所产生的预测误差。
再举一个例子!
这次测验的数据集是 readingSkills。它包含学生的考试信息及考试分数。
我们将基于多重指标把学生分为两类,说母语者(nativeSpeaker = 1)或外国人(nativeSpeaker= 0),他们的考试分数、鞋码以及年龄都在指标范围内。
对于 R 中的实现,我们首先要安装 party 包:
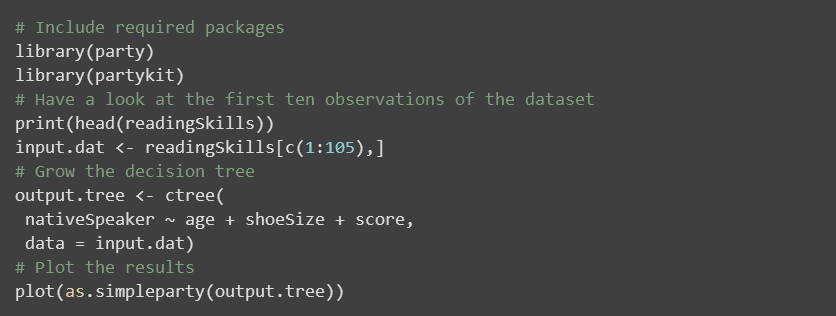
我们可以看到,它使用的第一个分类标准是分数,因为它对于目标变量的预测非常重要,鞋码则不在考虑的范围内,因为它没有提供任何与语言相关的有用的信息。
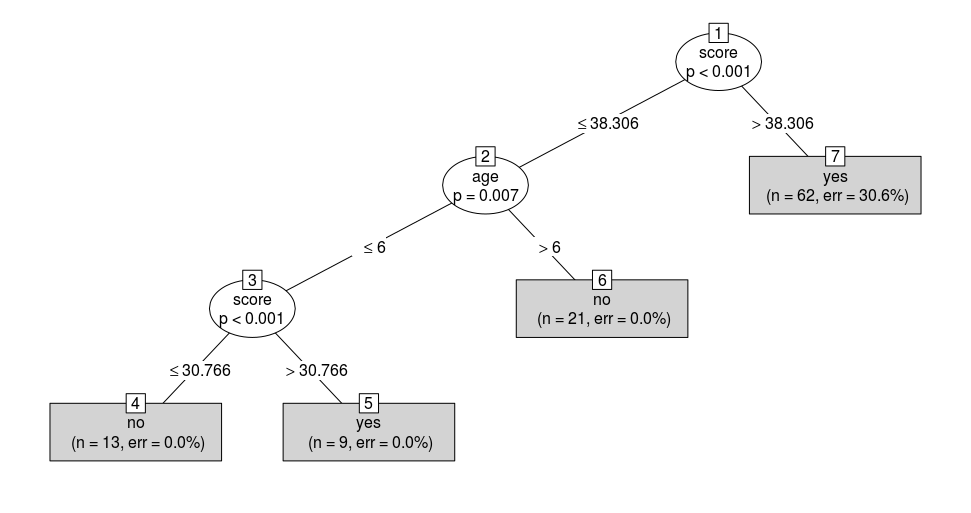
现在,如果我们多了一群新生,并且知道他们的年龄和考试分数,我们就可以预测他们是不是说母语的人。
聚类算法
到目前为止,我们都在讨论有监督学习的有关问题。现在,我们要继续研究聚类算法,它是无监督学习方法的子集。
因此,只做了一点改动......
说到聚类,如果我们有一些初始数据需要支配,我们会想建立一个组,这样一来,其中一些组的数据点就是相同的,并且能与其他组的数据点区分开来。
我们将要学习的算法叫做 K-均值聚类(K-Means Clustering),也可以叫 K-Means 聚类,其中 k 表示产生的聚类的数量,这是最流行的聚类算法之一。
还记得我们前面用到的 Iris 数据集吗?这里我们将再次用到。
为了更好地研究,我们使用花瓣测量方法绘制出数据集的所有数据点,如图所示:
仅仅基于花瓣的度量值,我们使用 3-均值聚类将数据点聚集成三组。
那么3-均值,或更普遍来说,k-聚类算法是怎样工作的呢?整个过程可以概括为几个简单的步骤:
初始化步骤:例如 K = 3 簇,这个算法为每个聚类中心随机选择三个数据点。
群集分配步骤:该算法通过其余的数据点,并将其中的每一个分配给最近的群集。
重心移动步骤:在集群分配后,每个簇的质心移动到属于组的所有点的平均值。
步骤 2 和 3 重复多次,直到没有对集群分配作出更改为止。用 R 实现 k-聚类算法很简单,可以用下面的代码完成:
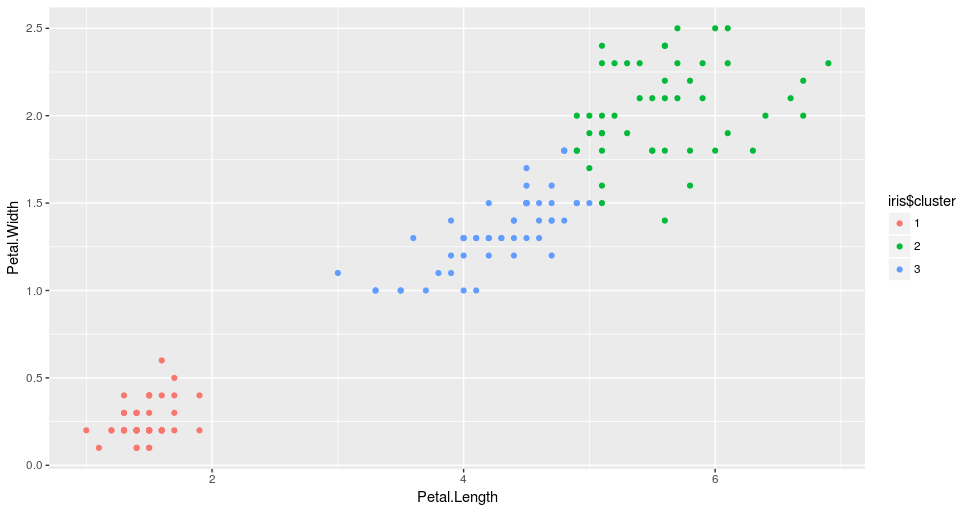
从结果中,我们可以看到,该算法将数据分成三个组,由三种不同的颜色表示。我们也可以观察到这三个组是根据花瓣的大小分的。更具体地说,红点代表小花瓣的花,绿点代表大花瓣的花,蓝点代表中等大小的花瓣的花。
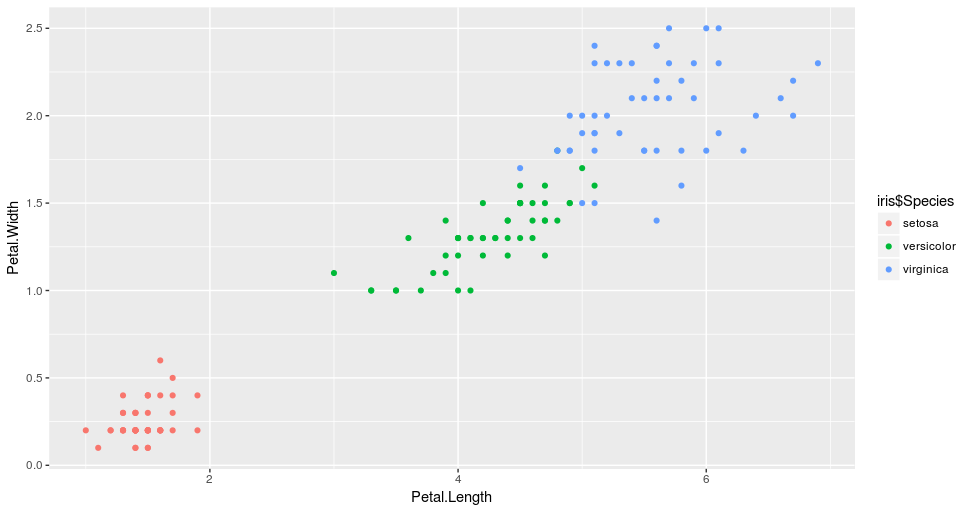
在这一点上需要注意的是,在任何聚类中,对分组的解释都需要在领域中的一些专业知识。在上一个例子中,如果你不是一个植物学家,你可能不会知道,k-均值做的是用花瓣大小给花分组,与 Setosa、 Versicolo r和 Virginica 的区别无关!
因此,如果我们再次绘制数据,这一次由它们的物种着色,我们将看到集群中的相似性。
总结
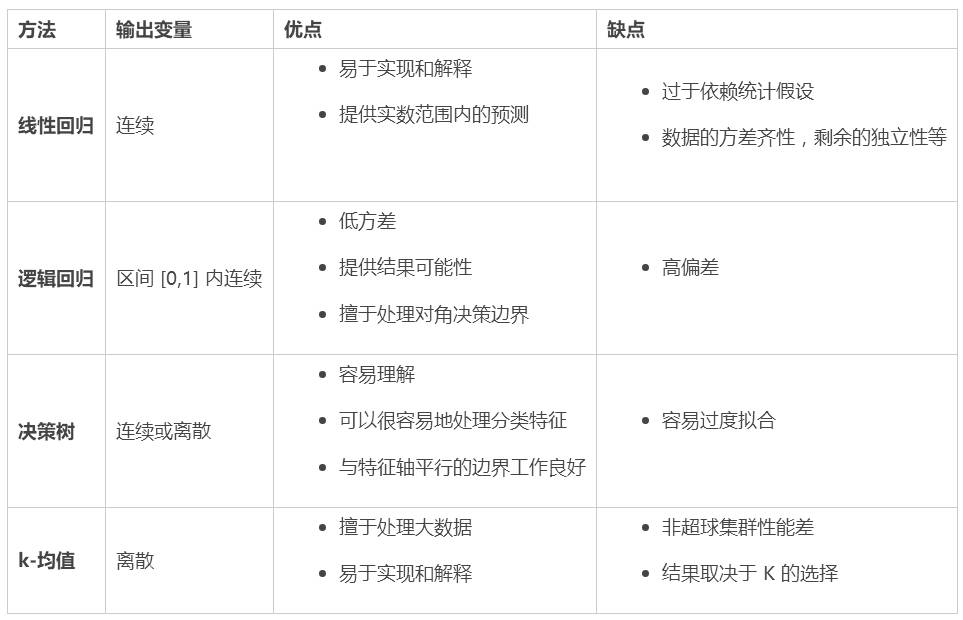
我们从一开始就走了很长的路。我们已经谈到回归(线性和逻辑)、决策树,以及最后的 K-均值聚类。我们还在R中为其中的每一个方法建立了一些简单而强大的实现。
那么,每种算法的优势是什么呢? 在处理现实生活中的问题时你该选择哪一个呢?
首先,这里所提出的方法都是在实际操作中被验证为行之有效的算法 - 它们在世界各地的产品系统中被广泛使用,所以根据任务情况选用,能发挥十分强大的作用。
其次,为了回答上述问题,你必须明确你所说的优势究竟意味着什么,因为每个方法的相对优势在不同情况下的呈现不同,比如可解释性、鲁棒性、计算时间等等。
在目前只考虑方法的适当性和预测性能情况下,对每种方法的优缺点进行简简单的总结:
现在,我们终于有信心将这些知识落实到一些现实问题中了!






