何恺明团队的“视频版本MAE”,高效视频预训练!Mask Ratio高达90%时效果也很好!

文 | 小马
源 | 我爱计算机视觉
本篇文章分享论文『Masked Autoencoders As Spatiotemporal Learners』,由何恺明团队提出视频版本的 MAE,进行高效视频预训练!Mask Ratio 高达 90% 时效果很好!
详细信息如下:

论文链接:
https://arxiv.org/abs/2205.09113
项目链接:尚未开源
![]() 1.摘要
1.摘要![]()
 1.摘要
1.摘要本文研究了Masked Autoencoders(MAE)在概念上对视频时空表示学习的简单扩展。作者随机mask视频中的时空patch,并学习Autoencoders以像素为单位重建它们。
有趣的是,本文的MAE方法可以学习强表示,几乎没有时空诱导偏置,时空不可知随机的mask表现最好。作者观察到,最佳掩蔽率(mask ratio)高达90%(而图像的掩蔽率为75%),这支持了该比率与数据信息冗余相关的假设。较高的掩蔽率会造成较大的加速比例。作者使用vanilla Vision Transformers报告了几个具有挑战性的视频数据集的竞争结果。
通过实验,作者观察到,MAE的表现大大优于有监督的预训练。此外,作者还报告了在真实世界中未经处理的Instagram数据上进行训练的结果。本文的研究表明,masked autoencoding的一般框架(BERT、MAE等)可以是一种使用最少领域知识进行表征学习的统一方法。
![]() 2.Motivation
2.Motivation![]()
深度学习社区正在经历一种趋势,即统一解决不同领域问题的方法,如语言、视觉、言语等。在架构方面,transformer已成功地引入计算机视觉,并被确立为语言和视觉的通用构建块。对于自监督表征学习,BERT中的去噪/屏蔽自动编码(masked autoencoding)方法已被证明对从图像中学习视觉表征有效。为了统一方法,针对特定问题只引入了较少的领域知识,这促使模型几乎完全从数据中学习有用的知识。
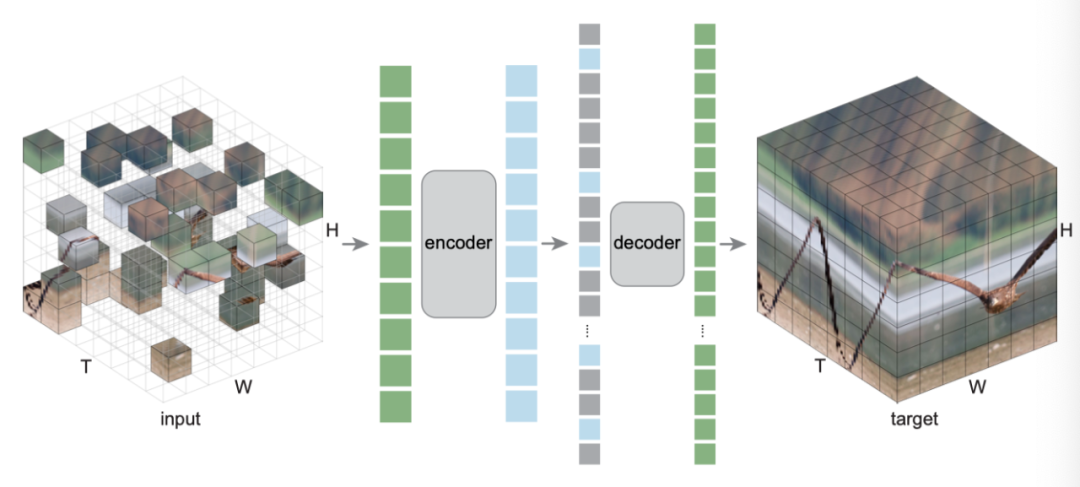
遵循这一理念,作者研究将MAE扩展到时空表征学习问题。本文的方法很简单:作者随机屏蔽视频中的时空patch,并学习自动编码器来重建它们(如上图)。本文的方法具有最小的领域知识:唯一的时空特异归纳偏差是embedding patch及其位置;所有其他组件对问题的时空性质都是不可知的。
特别是,本文的编码器和解码器都是普通的视觉Transformer,没有分解或层次结构,本文的随机mask采样对时空结构是不可知的。本文的方法预测像素值,并且不使用额外的问题特定tokenizer。简而言之,本文的方法简单地应用于时空patch集。尽管归纳偏差最小,但本文的方法取得了强有力的实证结果,表明可以从数据中学习有用的知识。

MAE的文献中假设,掩蔽自动编码方法中的掩蔽率(即移除token的百分比)与问题的信息冗余有关。例如,自然图像比语言具有更多的信息冗余,因此最佳掩蔽率更高。本文对视频数据的观察支持这一假设。作者发现,视频的MAE最佳掩蔽率为90%(如上图所示),高于对应图像的75%掩蔽率。这可以理解为自然视频数据在时间上相关的结果。极端的情况是,如果一个视频有T个相同的静态帧,则对所有时空patch进行1/T的随机采样将显示出大部分静态帧。因为在自然视频中,慢动作比快动作更容易发生,所以根据实验观察,掩蔽率可能非常高。
掩蔽率越高,实际解决方案越有效。MAE仅对可见token应用编码器之后,90%的掩蔽率将编码器时间和内存复杂性降低到<1/10。结合一个小型解码器,MAE预训练与编码所有token相比,理论上可以减少7.7倍的计算量。事实上,计算量大到数据加载时间成为新的瓶颈;即便如此,作者还是记录到了4.1倍的wall-clock加速。如此显著的加速对于大规模且耗时的视频研究非常重要。
作者报告了在各种视频识别数据集上的强大结果。MAE预训练极大地提高了泛化性能:在Kinetics-400上,与从头开始的训练相比,它将ViT-Large的准确率提高了13%,而总的来说,它需要更少的wall-clock训练时间(预训练加上微调)。本文的MAE预训练可以大大超过其监督的预训练对手。通过使用vanilla ViT,本文的方法与以前采用更多领域知识的SOTA法相比,取得了具有竞争力的结果。作者还报告了使用MAE对100万个随机、未经处理的Instagram视频进行预训练的结果。这些结果表明,在一个统一的框架下,视频的自监督学习可以以类似于语言和图像的方式进行。
![]() 3.方法
3.方法![]()
本文的方法是MAE对时空数据的简单扩展,目标是在通用和统一的框架下开发该方法,尽可能少地使用领域知识。
Patch embedding
根据原始ViT,给定一个视频片段,作者将其划分为一个规则的网格,其中包含时空中不重叠的patch。patch通过线性投影进行铺展和嵌入。位置嵌入添加到嵌入patch中。patch和位置嵌入过程是唯一具有时空感知的过程。
Masking
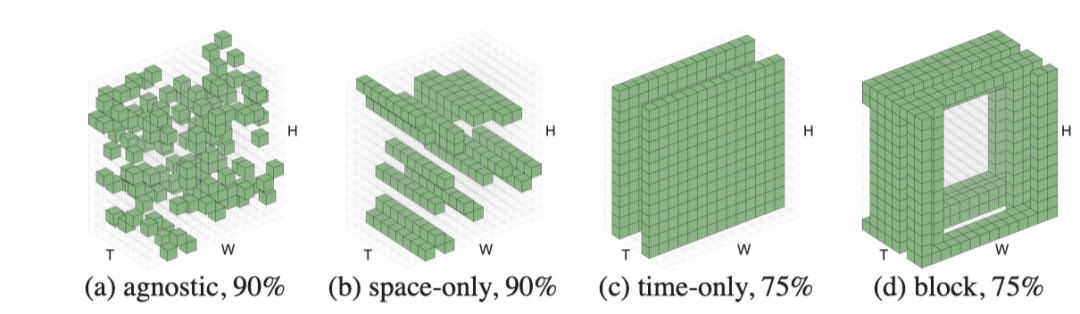
作者从嵌入的patch集中随机抽取patch。这种随机抽样与时空结构无关,如上图a。这种结构不可知的采样策略类似于1D中的BERT和2D中的MAE。
MAE中假设最佳掩蔽率与数据的信息冗余相关。对于非结构化随机掩蔽,BERT对语言使用了15%的掩蔽率,而MAE对图像使用了75%的掩蔽率,这表明图像比语言有更多的信息冗余。本文对视频的实证结果支持这一假设。作者观察到视频的最佳掩蔽率为90%。这符合通常的假设,即由于时间相干性,自然视频比图像具有更多的信息冗余。下图显示了本文方法在掩蔽率为90%和95%的未知验证数据上的MAE重建结果。
时空不可知采样可以比结构感知采样策略更有效。如上图b和c所示,仅空间或仅时间采样可能保留较少的信息,并产生非常困难的预训练任务。例如,掩蔽率为87.5%的8帧仅进行时间采样意味着只保留一帧,这就提出了一项非常具有挑战性的任务,即仅在给定一帧的情况下预测未来和过去。作者观察到,结构感知采样的最佳掩蔽比通常较低。相比之下,时空不可知采样更好地利用了有限数量的可见patch,因此允许使用更高的掩蔽率。

Autoencoding
我们的编码器是一种普通的ViT,仅适用于可见的嵌入patch集。这种设计大大减少了时间和内存复杂性,并带来了更实用的解决方案。90%的掩蔽率将编码器复杂度降低到<1/10。本文的解码器是另一种基于编码patch集和一组mask token的联合的普通ViT。解码器特定的位置嵌入被添加到此集合中。因为解码器被设计成比编码器小,所以虽然解码器处理整个集合,但其复杂性小于编码器。在本文的默认设置中,与完全编码相比,整个autoencoder的复杂度降低了7.7倍。
解码器预测像素空间中的patch。原则上,可以简单地预测一个完整的时空patch(例如,t×16×16);在实验中,作者发现预测patch的单个时间片(16×16)是足够的,这样可以保持预测层的大小可控。本文预测了原始像素或其每个patch的归一化值。训练损失函数是预测与其目标之间的均方误差(MSE),在未知patch上求平均值。编码器和解码器对问题的时空结构不可知。与SOTA结构相比,本文的模型没有层次结构或时空分解,只依赖于全局自注意力,从数据中学习有用的知识。
![]() 4.实验
4.实验![]()
Performance
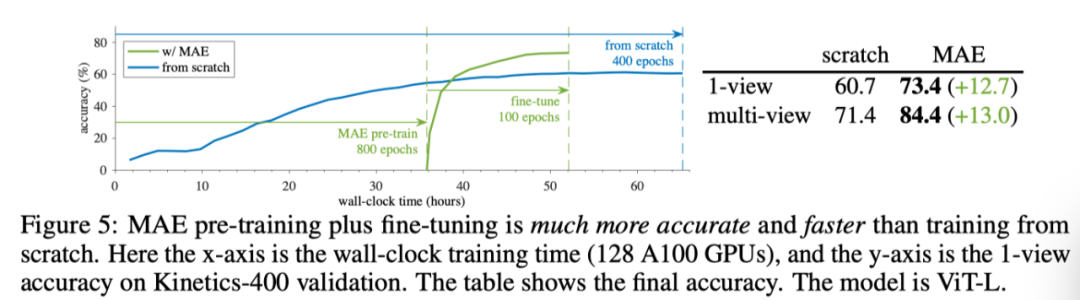
上图展示了使用标准ViT-L将MAE预训练与无预训练(即从头开始的训练)进行比较的结果。相比之下,使用MAE预训练800个epoch,相同ViT-L达到84.4%的准确率,与从头开始的训练相比,绝对值大幅增加13.0%。这一差距远大于图像识别任务的差距(∼ 3%),表明MAE预训练更有助于视频识别。
除了精度增益外,MAE预训练还可以降低总体训练成本,800 epoch MAE预训练仅需35.8小时。由于预训练,需要16.3小时的短时间微调,可以获得良好的精度。总体训练时间可以比从头开始的训练更短。这表明MAE是一种实用的视频识别解决方案。
Ablation experiments
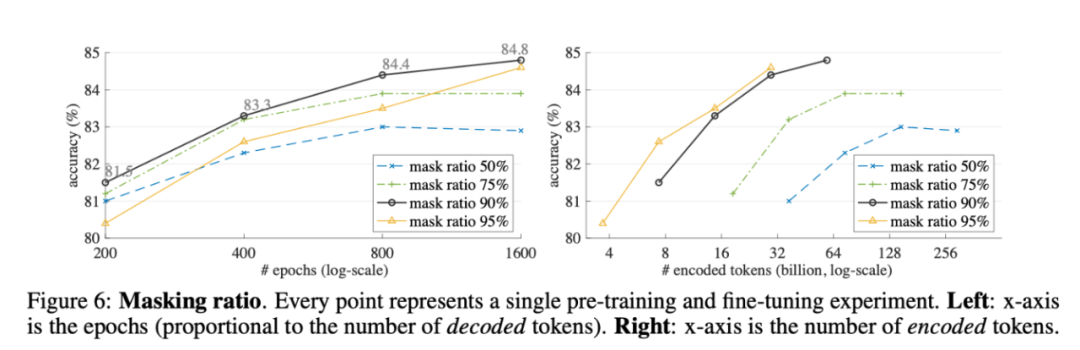
上图显示了掩蔽率与预训练周期的联合影响。90%的比例效果最好。95%的比例表现得出奇地好,如果训练足够长的时间,这可以会赶上。较高的掩蔽率导致编码器编码的token较少;为了更全面地查看,作者绘制了编码token总数和准确率的影响(上图右侧)。在这一衡量标准下,90%和95%的比率表现密切。
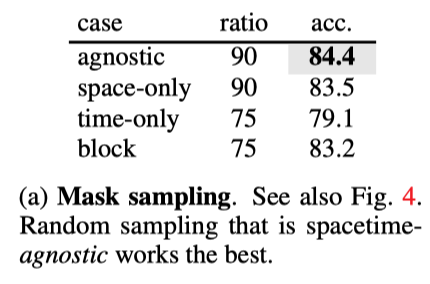
上表展示了不同mask策略的实验结果,可以看出随机采样的效果最好。
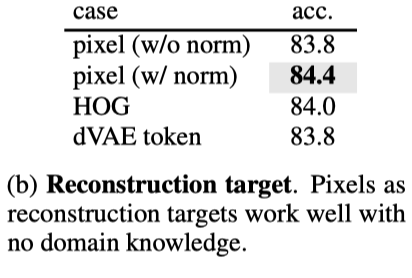
图展示了不同重建目标的实验结果。

上图展示了加入不同数据增强的实验结果。

由于本文的方法计算速度快,需要采用重复采样来减少数据加载开销。上表报告了其影响。重复使用2到4次可将wall-clock速度提高1.8倍或3.0倍,因为加载和解压缩的文件可重复使用多次。

上表展示了Decoder深度和宽度的影响。
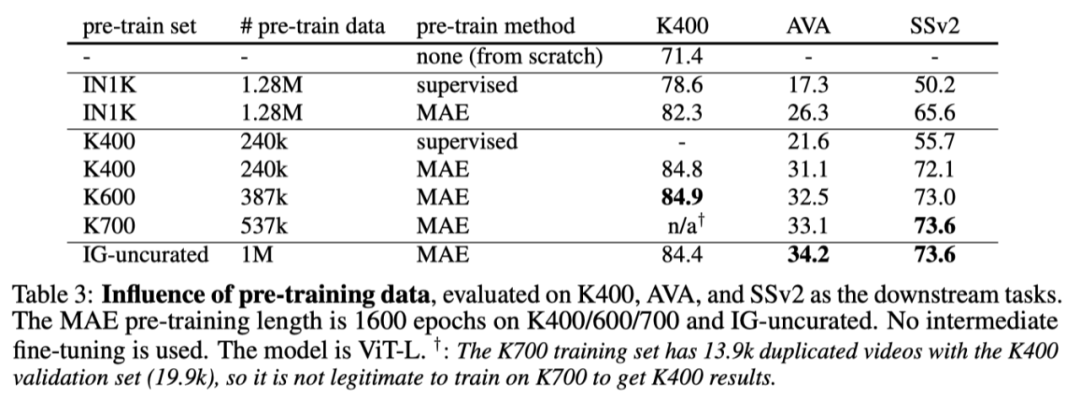
上表研究了不同数据集的预训练,并将其迁移到各种下游任务。
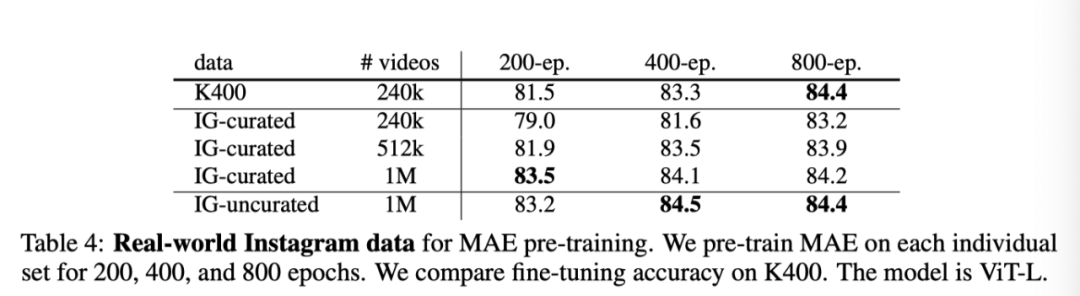
上表展示了用于MAE预训练的真实Instagram数据。作者对每一组MAE进行200、400和800个epoch的预训练,并比较了K400上的微调精度。模型为ViT-L。
![]() 5.总结
5.总结![]()
作者探索了MAE对视频数据的简单扩展,得出了一些有趣的观察结果:
-
用最小的领域知识或归纳偏差学习强表示是可能的。这符合ViT工作的idea。与BERT和MAE类似,视频上的自监督学习可以在概念统一的框架中解决。 -
本文的实验表明,掩蔽率是一般掩蔽自动编码方法的一个重要因素,其最佳值可能取决于数据的性质(语言、图像、视频等)。 -
作者报告了关于真实世界、未经评估数据的预训练的结果。
尽管得到了这些观察结果,但仍然存在一些悬而未决的问题。本文研究的数据规模比语言对应的数据规模小几个数量级。虽然本文的方法在很大程度上提高了自监督学习的效率,但高维视频数据仍然是扩展的主要挑战。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1]https://arxiv.org/abs/2205.09113
 后台回复关键词【入群】
后台回复关键词【入群】



