【开发】 用GAN来做图像生成,这是最好的方法
来源:AI科技评论
作者: 天雨粟,原文载于作者的知乎专栏——机器不学习
前言
在我们之前的文章中,我们学习了如何构造一个简单的 GAN 来生成 MNIST 手写图片。对于图像问题,卷积神经网络相比于简单地全连接的神经网络更具优势,因此,我们这一节我们将继续深入 GAN,通过融合卷积神经网络来对我们的 GAN 进行改进,实现一个深度卷积 GAN。如果还没有亲手实践过 GAN 的小伙伴可以先去学习一下上一篇专栏:生成对抗网络(GAN)之 MNIST 数据生成。
专栏中的所有代码都在我的 GitHub中,欢迎 star 与 fork。
本次代码在 NELSONZHAO/zhihu/dcgan,里面包含了两个文件:
dcgan_mnist:基于 MNIST 手写数据集构造深度卷积 GAN 模型
dcgan_cifar:基于 CIFAR 数据集构造深度卷积 GAN 模型
本文主要以 MNIST 为例进行介绍,两者在本质上没有差别,只在细微的参数上有所调整。由于穷学生资源有限,没有对模型增加迭代次数,也没有构造更深的模型。并且也没有选取像素很高的图像,高像素非常消耗计算量。本节只是一个抛砖引玉的作用,让大家了解 DCGAN 的结构,如果有资源的小伙伴可以自己去尝试其他更清晰的图片以及更深的结构,相信会取得很不错的结果。
工具
Python3
TensorFlow 1.0
Jupyter notebook
正文
整个正文部分将包括以下部分:
- 数据加载
- 模型输入
- Generator
- Discriminator
- Loss
- Optimizer
- 训练模型
- 可视化
数据加载
数据加载部分采用 TensorFlow 中的 input_data 接口来进行加载。关于加载细节在前面的文章中已经写了很多次啦,相信看过我文章的小伙伴对 MNIST 加载也非常熟悉,这里不再赘述。
模型输入
在 GAN 中,我们的输入包括两部分,一个是真实图片,它将直接输入给 discriminator 来获得一个判别结果;另一个是随机噪声,随机噪声将作为 generator 来生成图片的材料,generator 再将生成图片传递给 discriminator 获得一个判别结果。
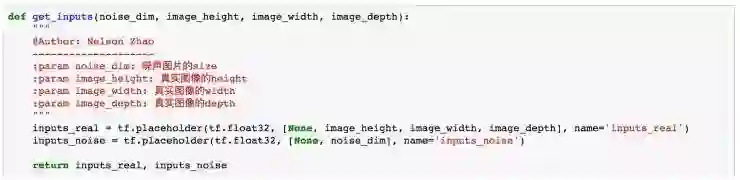
上面的函数定义了输入图片与噪声图片两个 tensor。
Generator
生成器接收一个噪声信号,基于该信号生成一个图片输入给判别器。在上一篇专栏文章生成对抗网络(GAN)之 MNIST 数据生成中,我们的生成器是一个全连接层的神经网络,而本节我们将生成器改造为包含卷积结构的网络,使其更加适合处理图片输入。整个生成器结构如下:

我们采用了 transposed convolution 将我们的噪声图片转换为了一个与输入图片具有相同 shape 的生成图像。我们来看一下具体的实现代码:
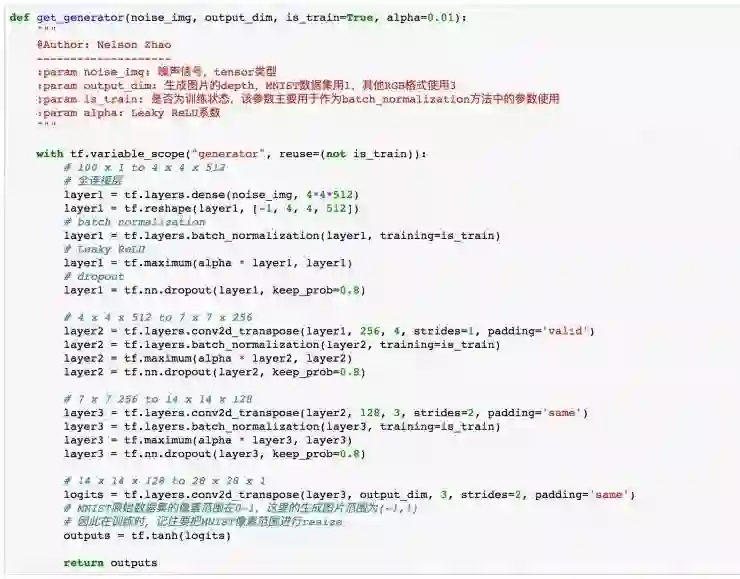
上面的代码是整个生成器的实现细节,里面包含了一些 trick,我们来一步步地看一下。
首先我们通过一个全连接层将输入的噪声图像转换成了一个 1 x 4*4*512 的结构,再将其 reshape 成一个 [batch_size, 4, 4, 512] 的形状,至此我们其实完成了第一步的转换。接下来我们使用了一个对加速收敛及提高卷积神经网络性能中非常有效的方法——加入 BN(batch normalization),它的思想是归一化当前层输入,使它们的均值为 0 和方差为 1,类似于我们归一化网络输入的方法。它的好处在于可以加速收敛,并且加入 BN 的卷积神经网络受权重初始化影响非常小,具有非常好的稳定性,对于提升卷积性能有很好的效果。关于 batch normalization,我会在后面专栏中进行一个详细的介绍。
完成 BN 后,我们使用 Leaky ReLU 作为激活函数,在上一篇专栏中我们已经提过这个函数,这里不再赘述。最后加入 dropout 正则化。剩下的 transposed convolution 结构层与之类似,只不过在最后一层中,我们不采用 BN,直接采用 tanh 激活函数输出生成的图片。
在上面的 transposed convolution 中,很多小伙伴肯定会对每一层 size 的变化疑惑,在这里来讲一下在 TensorFlow 中如何来计算每一层 feature map 的 size。首先,在卷积神经网络中,假如我们使用一个 k x k 的 filter 对 m x m x d 的图片进行卷积操作,strides 为 s,在 TensorFlow 中,当我们设置 padding='same'时,卷积以后的每一个 feature map 的 height 和 width 为


上面的代码中我也标注了每一步 shape 的变化。
Discriminator
Discriminator 接收一个图片,输出一个判别结果(概率)。其实 Discriminator 完全可以看做一个包含卷积神经网络的图片二分类器。结构如下:
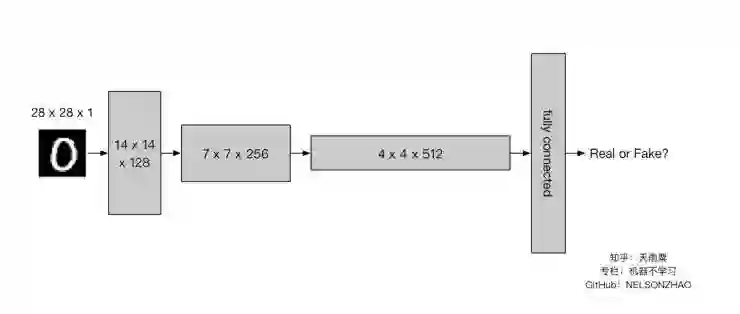
实现代码如下:
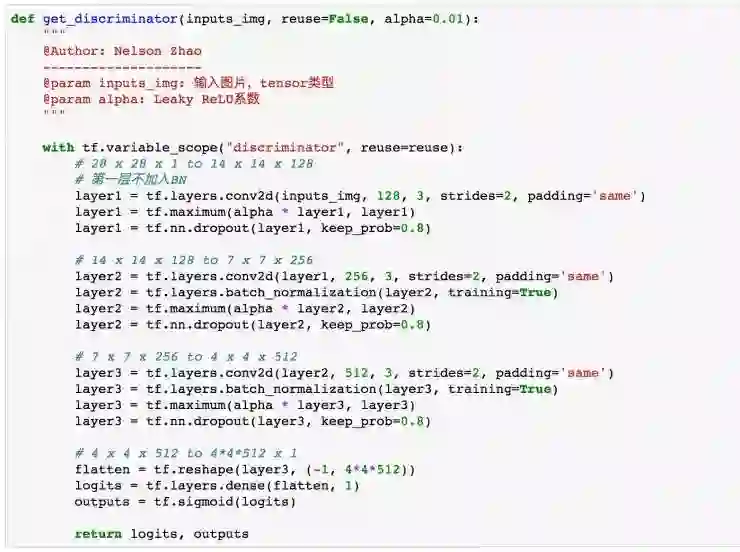
上面代码其实就是一个简单的卷积神经网络图像识别问题,最终返回 logits(用来计算 loss)与 outputs。这里没有加入池化层的原因在于图片本身经过多层卷积以后已经非常小了,并且我们加入了 batch normalization 加速了训练,并不需要通过 max pooling 来进行特征提取加速训练。
Loss Function

Loss 部分分别计算 Generator 的 loss 与 Discriminator 的 loss,和之前一样,我们加入 label smoothing 防止过拟合,增强泛化能力。
Optimizer
GAN 中实际包含了两个神经网络,因此对于这两个神经网络要分开进行优化。代码如下:
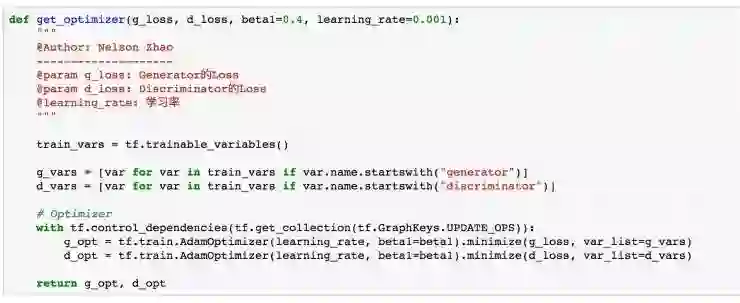
这里的 Optimizer 和我们之前不同,由于我们使用了 TensorFlow 中的 batch normalization 函数,这个函数中有很多 trick 要注意。首先我们要知道,batch normalization 在训练阶段与非训练阶段的计算方式是有差别的,这也是为什么我们在使用 batch normalization 过程中需要指定 training 这个参数。上面使用 tf.control_dependencies 是为了保证在训练阶段能够一直更新 moving averages。具体参考 A Gentle Guide to Using Batch Normalization in Tensorflow - Rui Shu。
训练
到此为止,我们就完成了深度卷积 GAN 的构造,接着我们可以对我们的 GAN 来进行训练,并且定义一些辅助函数来可视化迭代的结果。代码太长就不放上来了,可以直接去我的 GitHub 下载。
我这里只设置了 5 轮 epochs,每隔 100 个 batch 打印一次结果,每一行代表同一个 epoch 下的 25 张图:

我们可以看出仅仅经过了少部分的迭代就已经生成非常清晰的手写数字,并且训练速度是非常快的。

上面的图是最后几次迭代的结果。我们可以回顾一下上一篇的一个简单的全连接层的 GAN,收敛速度明显不如深度卷积 GAN。
总结
到此为止,我们学习了一个深度卷积 GAN,并且看到相比于之前简单的 GAN 来说,深度卷积 GAN 的性能更加优秀。当然除了 MNST 数据集以外,小伙伴儿们还可以尝试很多其他图片,比如我们之前用到过的 CIFAR 数据集,我在这里也实现了一个 CIFAR 数据集的图片生成,我只选取了马的图片进行训练:
刚开始训练时:

训练 50 个 epochs:
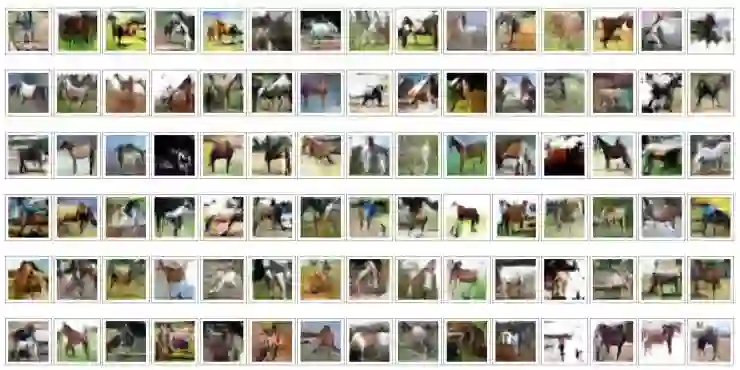
这里我只设置了 50 次迭代,可以看到最后已经生成了非常明显的马的图像,可见深度卷积 GAN 的优势。
我的 GitHub:NELSONZHAO (Nelson Zhao)
上面包含了我的专栏中所有的代码实现,欢迎 star,欢迎 fork。
☞ 【学界】邢波团队提出contrast-GAN:实现生成式语义处理
☞ 【专栏】阿里SIGIR 2017论文:GAN在信息检索领域的应用
☞ 【学界】康奈尔大学说对抗样本出门会失效,被OpenAI怼回来了!
☞ 警惕人工智能系统中的木马、病毒 ——深度学习对抗样本简介
☞ 【生成图像】Facebook发布的LR-GAN如何生成图像?这里有一篇Pytorch教程
☞ 【智能自动化学科前沿讲习班第1期】国立台湾大学(位于中国台北)李宏毅教授:Anime Face Generation
☞ 【变狗为猫】伯克利图像迁移cycleGAN,猫狗互换效果感人
☞ 【论文】对抗样本到底会不会对无人驾驶目标检测产生干扰?又有人发文质疑了
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【专栏】基于对抗学习的生成式对话模型的坚实第一步 :始于直观思维的曲折探索
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【最新】OpenAI:3段视频演示无人驾驶目标检测强大的对抗性样本!
☞ 【论文】CVPR 2017最佳论文出炉,DenseNet和苹果首篇论文获奖
☞ 【深度学习】解析深度学习的局限性与未来,谷歌Keras之父「连发两文」发人深省
☞ 苹果重磅推出AI技术博客,CVPR合成逼真照片论文打响第一枪
☞ 【Ian Goodfellow 五问】GAN、深度学习,如何与谷歌竞争
☞ 【巨头升级寡头】AI产业数据称王,GAN和迁移学习能否突围BAT垄断?
☞ 【高大上的DL】BEGAN: Boundary Equilibrium GAN
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【最全GAN变体列表】Ian Goodfellow推荐:GAN动物园
☞ 【DCGAN】深度卷积生成对抗网络的无监督学习,补全人脸合成图像匹敌真实照片
☞ 【开源】收敛速度更快更稳定的Wasserstein GAN(WGAN)
☞ 【Valse 2017】生成对抗网络(GAN)研究年度进展评述
☞ 【开源】谷歌新推BEGAN模型用于人脸数据集:效果惊人!
☞ 【深度】Ian Goodfellow AIWTB开发者大会演讲:对抗样本与差分隐私
☞ 论文引介 | StackGAN: Stacked Generative Adversarial Networks
☞ 【纵览】从自编码器到生成对抗网络:一文纵览无监督学习研究现状
☞ 【论文解析】Ian Goodfellow 生成对抗网络GAN论文解析
☞ 【推荐】条条大路通罗马LS-GAN:把GAN建立在Lipschitz密度上
☞【Geometric GAN】引入线性分类器SVM的Geometric GAN
☞ 【GAN for NLP】PaperWeekly 第二十四期 --- GAN for NLP
☞ 【Demo】GAN学习指南:从原理入门到制作生成Demo
☞ 【学界】伯克利与OpenAI整合强化学习与GAN:让智能体学习自动发现目标
☞ 【人物 】Ian Goodfellow亲述GAN简史:人工智能不能理解它无法创造的东西
☞ 【DCGAN】DCGAN:深度卷积生成对抗网络的无监督学习,补全人脸合成图像匹敌真实照片
☞ 带你理解CycleGAN,并用TensorFlow轻松实现
☞ PaperWeekly 第39期 | 从PM到GAN - LSTM之父Schmidhuber横跨22年的怨念
☞ 【CycleGAN】加州大学开源图像处理工具CycleGAN
☞ 【SIGIR2017满分论文】IRGAN:大一统信息检索模型的博弈竞争
☞ 【贝叶斯GAN】贝叶斯生成对抗网络(GAN):当下性能最好的端到端半监督/无监督学习
☞ 【贝叶斯GAN】贝叶斯生成对抗网络(GAN):当下性能最好的端到端半监督/无监督学习
☞ 【GAN X NLP】自然语言对抗生成:加拿大研究员使用GAN生成中国古诗词
☞ ICLR 2017 | GAN Missing Modes 和 GAN
☞ 【学界】CMU新研究试图统一深度生成模型:搭建GAN和VAE之间的桥梁
☞ 【专栏】大漠孤烟,长河落日:面向景深结构的风景照生成技术
☞ 【开发】最简单易懂的 GAN 教程:从理论到实践(附代码)
☞ 【论文访谈】求同存异,共创双赢 - 基于对抗网络的利用不同分词标准语料的中文分词方法
☞ 【LeCun论战Yoav】自然语言GAN惹争议:深度学习远离NLP?
☞ 【争论】从Yoav Goldberg与Yann LeCun争论,看当今的深度学习、NLP与arXiv风气
☞ 【观点】Yoav Goldberg撰文再回应Yann LeCun:「深度学习这群人」不了解NLP(附各方评论)
☞ PaperWeekly 第41期 | 互怼的艺术:从零直达 WGAN-GP
☞ 【谷歌 GAN 生成人脸】对抗创造新艺术风格,128 像素扩展到 4000
☞ 【原理】只知道GAN你就OUT了——VAE背后的哲学思想及数学原理




