人工智能的钟摆
本文来自文因互联CEO鲍捷博士2017年3月7日于弘毅年会所作的演讲
鲍捷:今天我讲的主题叫做《人工智能的钟摆》,这个题目脑洞比较大。其实坦白说,我今天不是真正在说人工智能是什么,主要是说一些人工智能的八卦。
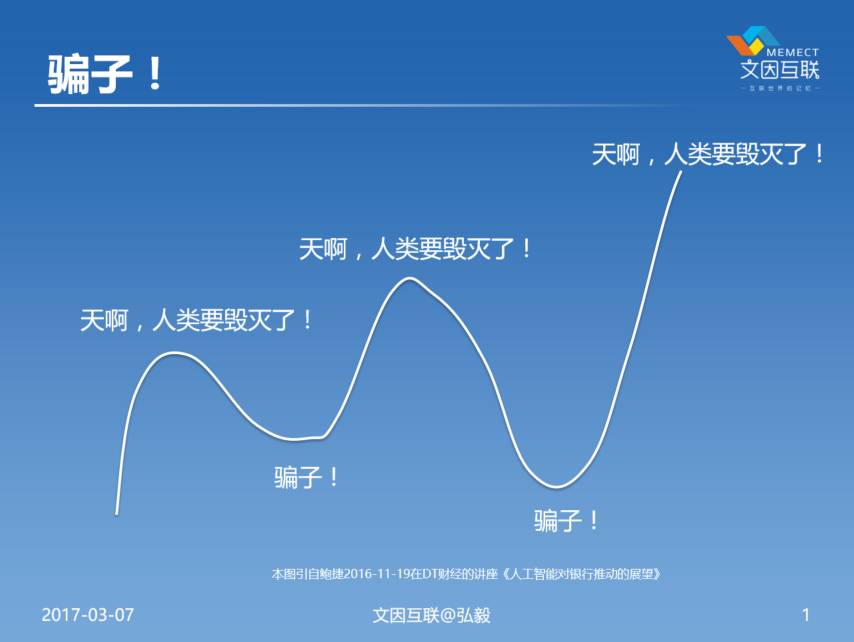
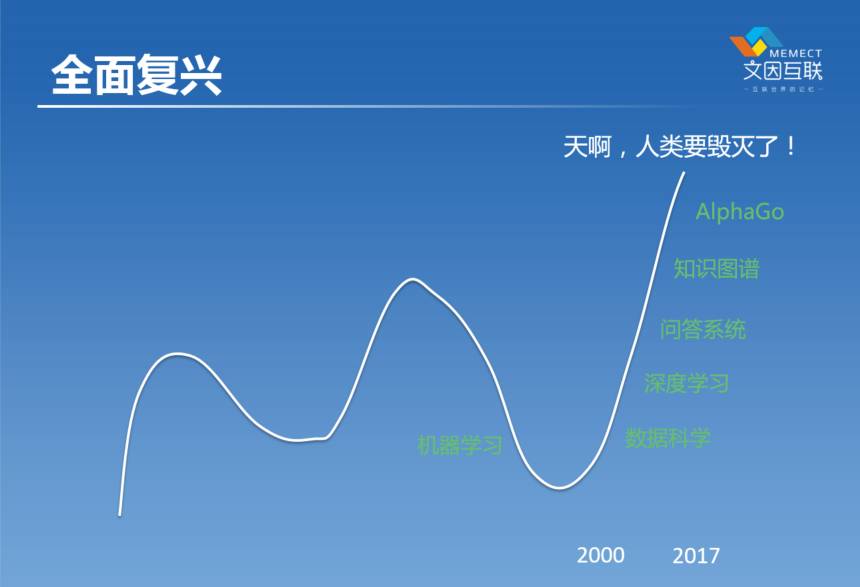
下面这个图是我在三个月之前在DT财经的讲座里面画的。这个图差不多就是过去30年来,我们整个领域的血泪史吧。媒体一会儿说你们这一群人要毁灭人类了,然后又过了十年说你们是一群骗子。我最早接触人工智能到今年已经20年时间,经历了两个轮回,被鄙视了两次。
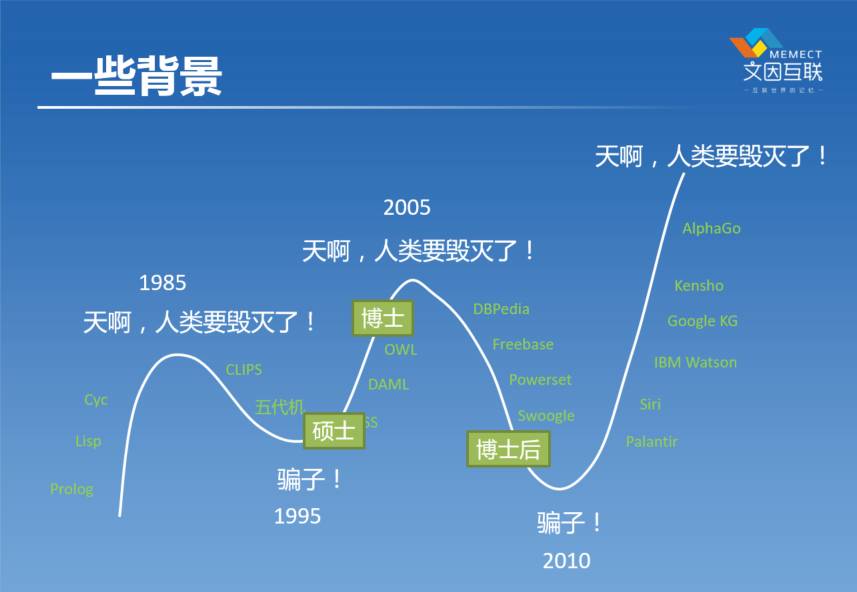
我在2001年硕士毕业的时候做的是神经网络,用神经网络做图像的识别。2001年去了美国,2007年拿到博士学位,在博士期间主要做的是逻辑方面的工作,当时把逻辑用到互联网上这个领域叫做语义网。毕业了之后去了伦斯勒理工学院做博士后,在那期间坚持做语义网的一些应用研究。
2009年的时候我在W3C,就是万维网联盟,帮助他们做了一个国际标准叫做OWL2,现在还是这个领域里最主要的国际标准。然后2010去了MIT,在那里主要做的是语义信息论。后来2012年在三星,参与设计了三星手机上的语音助手叫S—Voice,当然不是我一个人,很多人一起做的。
我从2013年开始创业,到2014年的时候做了一个东西叫【好东西传送门】。这个在中国的人工智能这个圈子里面有些知名度,是一个相当于技术领域的今日头条。后来以此为基础就开始做了一些其他的工作,2015年的时候,我跟我的团队一起回来做了文因互联这个公司,到2015年9月份的时候,主要是集中在金融的AI。
把刚才讲的这些事情映射到一开始看到的那个图上去,我在做硕士的期间就相当于人工智能第一个冬天正在走出去回暖的那个时候,所以我的硕士读得也很开心的。到了开始读博士的时候刚刚好,到了又一个顶点然后往下来,整个博士期间AI就是在往下走。到博士后毕业的时候又是一个冬天,在那个时候一起毕业的那一帮同学基本上都转行了,只有我一个人很坚持。我觉得这些事总是有价值的,所以一直坚持。后来坚持到了2010年前后,这事情开始往回转。到了现在大家开始说了,你们又要消灭人类了,所以这就是很常见的大家对人工智能两个误解,一是你们要消灭人类,然后过十年说你们是一群骗子。
关于AI的八卦
1.关于AI的三个问题
那我在今天开始更多八卦的事情之前,我问大家三件事情:
第一:有多少人相信你在工作有生之年会被机器取代的?(现场5位举手)
第二:有一个理论说2045年机器会超过人,有多少人相信这个论断?(现场6位举手)
最后一个:你们相信最终人类会被机器消灭掉吗?(现场1位举手)
根据现场大家的反应,其实感觉你们的危机感要比人工智能圈子里面的人要强。因为我在技术群里问他们这些问题的时候,这三个问题他们都是否定AI的答案。
2.AI三定律
这是我总结出来的人工智能三定律。
第一个定律是说 AI 不是 Artificial Intelligence,是 Artificial Idiocy。还有人说是动物智能(Animal Intelligence),我觉得这是比较靠谱的一个说法,就是现在我们所谓的人工智能,我们看到AlphaGo 这些东西,其实它都是很机械的一种,它只是速度很快,我觉得它的智能水准基本上就相当于一个蟑螂。我觉得能到蟑螂就算还不错了,然而它并没有真正达到人的智能,其实连高等动物的智能都达不到。
第二点在我们在说 Artificial Intelligence,其实大多数时候我们在说 『Artificial Artificial Intelligence』,它不是真正的智能,它只是一种对智能非常抽象的模仿,它离我们所谓的智能还差得非常非常的远。
第三点就是有多少人工就有多少智能。也就是说我们不可能有一台机器,我们放在这儿,然后它就可以很智能地回答我们一些问题,做很多事情。如果你是做过图像处理的,你就知道调参数是很重要的一点。我们去做知识库的时候更是这样,知识库构造的时候,你必须用人,只有人才有这样一种智力。在人工智能研究里面,很大一部分我们在研究,如何把人的智能从我们脑袋里面搬到机器里面去,所以跟大家想的——机器一下子就能智能——不一样。
这是人工智能三定律,回头还有一个第四定律,我们在最后的时候说。

3.AI的门派
今天由于可能时间有限,我们也不可能把人工智能的这些细节层面的东西说太多。今天以八卦为主,那么我先说说这个八卦的基础,就是说人工智能里面到底有哪些最基本的门派。其实通常大家说的有三个门派。
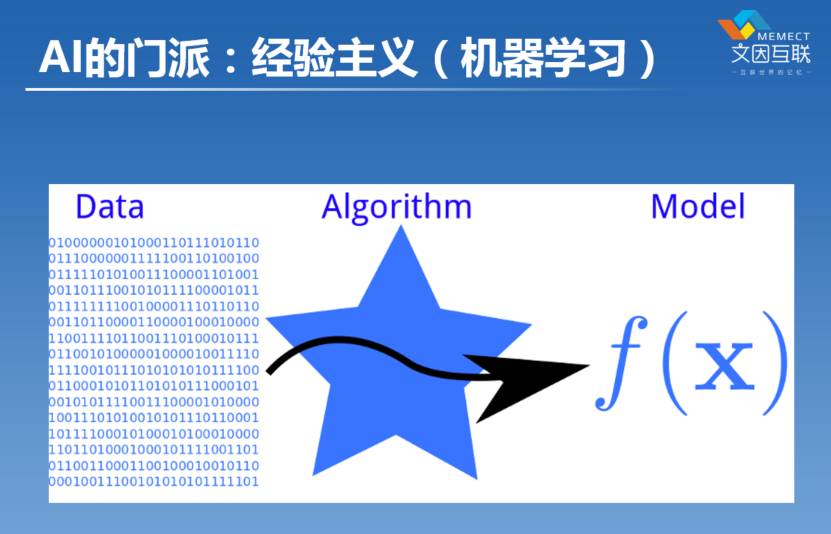
第一个门派我们称为经验主义,最经典的代表就是机器学习。机器学习可能有一万个不同的变种,我们把它抽象到最抽象的角度,其实就是这一幅图讲的东西,它就是在学习一个函数。我们高中时候都学过函数。输入是什么,输入就是图中“010101”这些数字,图像也好,声音也好,文本也好,都是数据。那通过所谓的算法,我们去逼近这个世界上存在的一个函数,这个就是机器学习。什么样的东西是函数呢?比如说我们在座的各位,我们大家每一个人都有一张脸,我们做一个人脸识别,我们识别出来这是女生,这是男生,这就是一个函数,这个函数的输出是0或者1,这是一个所谓的分类问题。当然现实中我们遇到的分类问题,会比这复杂很多,可能不是分两类,可能是分一千类。
还有像聚类问题。现在如果我们把屋子里边的人聚成两类,一类坐在这边,一类是坐在那边的,我们的这个位置,实际上就是所谓的一个分布,这就是另外一种类型的函数。所以机器学习就是我们有了一堆输入的数据,声音也好,图像也好,文本也好,我们把它变成一个数学上可以精准描述的,通过这个数据本身可以去预言的一种东西。通常这种东西就是概率,一个概率分布,这是机器学习目前这个阶段最常用的方法,所以这个经验主义,我们又通常把它称为统计主义。这是第一个大的门派。
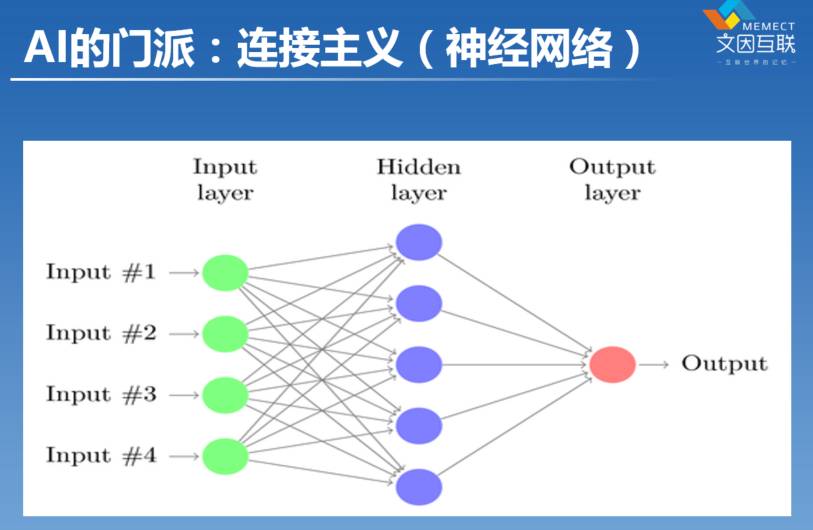
第二个门派就是现在最火的东西,深度学习。在我读研究生的时候,我们把它称为神经网络。实际上这个领域也不新,其实在40年代就已经有了,但中间也是经历了起起伏伏好几次。图中是最常见的一种神经网络。其实一个神经网络是很简单的,如果大家学习过矩阵的话,神经网络就是一堆矩阵。它是输入了一堆数字经过了一个矩阵的变化之后,变成了另外一堆数字;如果输入是一个向量,经过一个矩阵变成另外一个向量,实际上这就是神经网络的一个最基础的数学模型。
我们用图来表现就是上图这样子。比如那一堆线就是在代表一个矩阵。为什么把它称为神经网络呢?因为有人认为这个东西,跟我们大脑里面的神经元的数学模型是一样的。因为我们的神经元之间也是有很多突触,相互关联在一起,所以一个神经的脉冲可以从一个神经元传递到另外一个神经元,不断地去进行传导。到了40年代的时候,就有人说,为什么不可以把它抽象成一种程序呢?是不是有足够多的人工神经元构成在一起之后,就可以变成一个人工的神经网络 『Artificial Neural Network』。所以到了50年代的时候,大家觉得这个想法很棒。后来经过了很多的起起伏伏,待会我们在讲人工智能冬天的时候会接着来讲。
那现在大家听到的深度学习是什么意思?看这个神经网络,它其实是有三层,叫输入层,输出层,中间那个蓝色的叫做隐层。在80年代的时候,就曾经证明了像这样的一个神经网络模型,是世界上最强大的计算模型。大家肯定听说过图灵机这个概念吧,图灵机就是现在我们最强大的计算模型,这样一个非常简单的神经网络模型跟图灵机是等价的,这个数学上可以严格地进行证明。
所以发现了这个等价性之后,大家就说既然一层二层三层的隐层都是等价的,那我们就用一层就好了。但是后来大家发现遇到了很多问题,就是速度很慢,还有说我在一群样本上面,做了训练之后,我换了一些样本它的效果不好,这个用术语来说叫泛化能力不好。速度问题、泛化的问题,这个神经网络一直都解决不了,所以到了90年代大家说神经网络是骗子。一直到了大概十几年之后,到了2006年前后的时候,有人开始说其实我们可以把这个层数加深了,这就变成了深度网络了。当时由于计算能力也提升了,有一些算法上也做了提升之后,结果这样一个深度网络,大家发现这个效果真的很好,这就是现在的深度学习。所以深度学习也就是一种神经网络。

第三个门派叫做符号主义,有人也叫它理性主义。在不同的历史时期,我们叫它不同的说法。在四十年代、五十年代我们叫它逻辑,后来我们叫它知识,再后来叫它语义网,这两年叫它知识图谱。其实它都是一个门派传下来的东西,实际就是逻辑推理:如果鸡是一种鸟,鸟是一种动物,那鸡就是一种动物。就是这种大前提、小前提、结论,三段论。
在2000年前,亚里士多德就已经提出三段论了,所以逻辑并不是新的东西。在过去100多年时间里边,有很多的逻辑学家,从布尔到罗素最后到图灵,研究基于逻辑的通用计算模型,最终导致了计算机的产生。后来有人想,我们人是怎么思考的,能不能用逻辑模拟。
有一个计算机科学家麦卡锡,他在斯坦福大学,他就认为这个世界上的真理,就是人的思考是基于一种符号的形式来表现的。他说我只要把整个世界全部用符号系统来进行承载的时候,我不就可以表达整个世界了嘛?以这个思路往前走,当时的人是很兴奋的,比如说他们50年代的时候就想也许十年或者二十年之后,所有人类的智力问题,全部可以用这种逻辑方法来解决。在70年代的时候,他们确实取得了很多的成功。当时有一个逻辑分支叫定理证明,就有人写了一堆逻辑的程序,把《几何原理》这本书里所有的定理都证出来了。当时那种冲击跟今天我们看到AlphaGo那种冲击是一样的,觉得人工智能真的要毁灭世界了的感觉。但后来证明并没有,因为我们很快发现逻辑有它自己的问题。
以上就是三个大的人工智能学派的介绍。
三大学派的钟摆
但很不幸的是人工智能这些学派之间,它们也是相互瞧不起的,所以有一个门户之见。下面大体上是最近这十几年二十几年的鄙视链。在这个领域里头,其实差不多十年到十五年时间的时候,大家都会起起伏伏一次,三十年河东三十年河西。

在90年代的时候,那时候最牛逼的是知识,那时候有一个语言叫Lisp语言,在美国至少有200个公司在做Lisp的应用研究,就好像现在深度学习的研究一样。日本在那个时候,他们投了上千亿日元去开发这个五代机,因为他们相信这个东西是未来。那个时候神经网络还可以,其实神经网络最高峰的时候应该是80年代末的时候。机器学习当时是最Low的,大家看不起机器学习。
然后15年之后,2005年的时候也就是我读博士的时候,机器学习如日中天非常牛逼。知识消沉一段时间以后,又摇身一变变成了语义网,当时得到了美国和欧洲政府的上亿美元的资助,所以当时语义网很不错。当时最惨的就是神经网络了,当时几乎没有人用,谁也不说自己是神经网络。所以90年代末的时候,我当时开始学SVM,(注:SVM指的是支持向量机 Support Vector Machine,一种算法)当时大家说这是一种神经网络模型,后来过了十年之后就没有人这么说了,所有人都说SVM是一种机器学习的模型,不说是神经网络,因为拿不到资助。现在深度学习火了,又有人说SVM是神经网络了。
我去美国的时候,2001年,那时候是神经网络的一个低谷期。我去美国就是因为我的微博导师 Vasant Honavar 是做神经网络,所以我就申请跟他做。去了以后他就告诉我,咱们不能研究这个方向了,这个方向拿不到钱,你得换一个方向。那我想想换什么方向,最后我选到了语义网这个方向,结果等我毕业的时候,语义网热度低。所以说人的命运要看个人努力,但最主要的还是看历史的进程。
但是历史它是不断轮回的,你只要坚持是会有回报的。所以在神经网络最低谷的时候,Geoffrey Hinton——深度学习的鼻祖之一,他就一直不相信这个事情不行,他觉得就是可以,就是可以,他就不放弃,在几乎所有人都放弃了的时候他坚守。结果到了2012年的时候就被他搞成了,所以他现在变成了世界上最有影响力的一个人工智能研究者。到了2017年的时候,神经网络目前可以说是整个领域里面最牛逼的一个算法,在鄙视链的最上层。上个星期我去见另外一个投资机构的时候,他们就问我这个问题,什么叫人工智能,我给他看了一堆算法,他们说你这个不是人工智能,这里面为什么没有提到深度学习,在他的印象里面深度学习就是人工智能,人工智能就是深度学习。但其实不是。
知识这个领域,也在十年的消沉之中恢复起来了,摇身一变换了一个名字叫知识图谱。2012年前后几个大的公司,把这个东西带起来,现在反而是机器学习,在整个鄙视链里面往下降。这就是咱们的钟摆,就是人工智能整个领域是起起伏伏的,人工智能里面每个学派本身也是起起伏伏的。
这一幅图是我们领域里一个元老叫Church这个教授,他在2007年的一篇文章里面给出的。他统计了机器学习这种方法在ACL这个会议里面的比例(ACL就是美国计算语言协会的年会,这是这个领域里非常重要的一个学术会议)。我们可以看到,从80年代末到2005年这期间,整个统计的方法的比例是在不断提高的,从不到10%提高到接近90%,也代表了整个领域,在钟摆的这一摆大概花了差不多十几年的时间摆过来了。
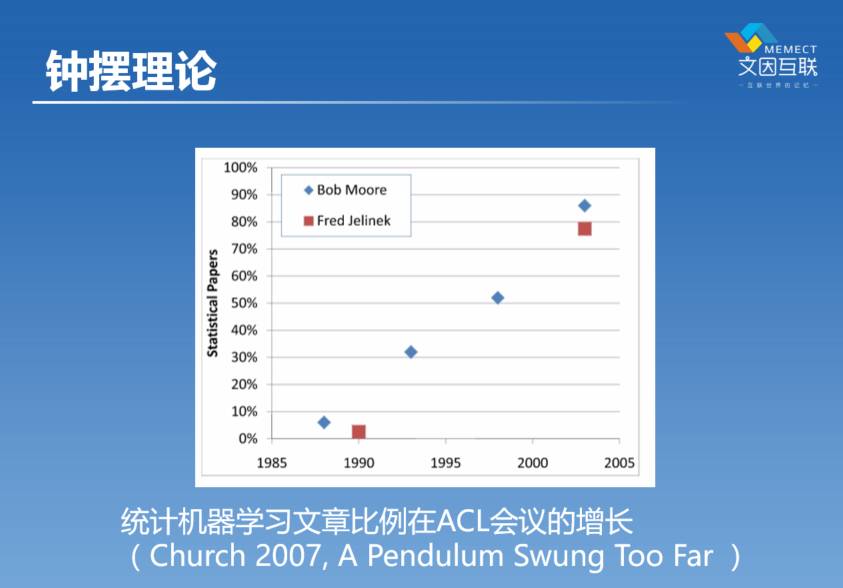
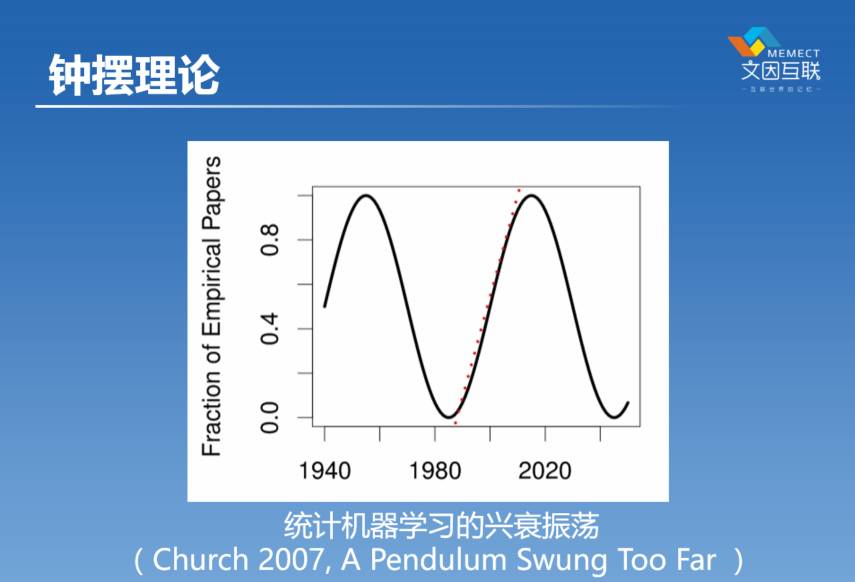
Church把这个机器学习的这个上升过程放到整个历史进程里面来看,大概从40年代到现在,他认为这个上升,实际上是对前面这20年下降的一个弥补。但他又认为有可能往后是往下掉的。事实上这篇文章从2007年到现在已经过了十年时间了,我们可以看到他的预言确实是对的,现在机器学习又在往下掉。所以你看现在的文章里,越来越多的在讲神经网络,在讲逻辑,在讲知识图谱。因为有了这样的起起伏伏,我们就有了所谓的“人工智能的冬天” ——AI Winter。到目前为止我们经历了人工智能的三次高潮、两次冬天,到底下面一个是什么,我们现在还不知道,但看看历史或许能够有助于帮助我们理解未来。
人工智能的冬天 AI-Winter
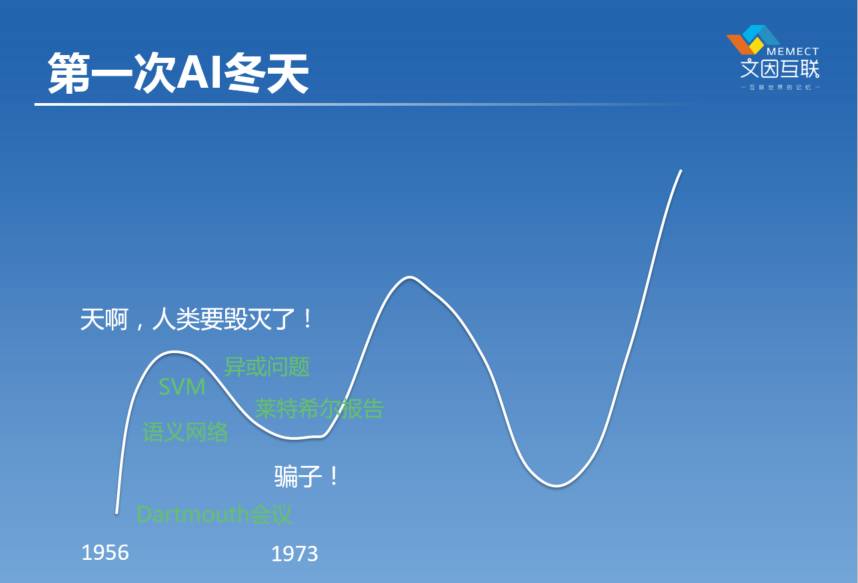
人工智能的发源是1956年在Dartmouth学院。Dartmouth学院在美国东北部一个小城市,那在一年他们办了一个暑期班,有那么几个人,其中有西蒙,还有麦卡锡(John McCarthy)、明斯基(Marvin Minsky)。他们当时有的是做逻辑的,有的是做数学的,当时还没有计算机科学这个概念,大家都是从不同的领域来的。但是大家都有这么一个想法,我们可以用计算机来模拟人的思考。
所以大家在一起就1956年他们花了大概一个多月的时间,在Dartmouth学院这个地方一起讨论,最后就形成了这个学科。形成这个学科之后,大家非常兴奋,以前从来没有想过机器可以模仿人的智能,所以当这一件事情已经发生了之后,大家就觉得好像我们对于用机器来解决我们现在面临的各种复杂的问题,已经有答案了。60年代的时候,我们有了语义网络,有了SVM,有了逻辑,有了神经网络,我们有了各种统计的方法,我们用了很多算法,感觉好像胜利呼之欲出了,所以当时的人非常非常的乐观。应该是明斯基说的,他的想法是说,“十到十五年之内我们可以解决所有的智能问题”。从下棋开始,所有问题我全部能解决掉。
但是转头到了70年代的时候,大家逐渐发现了,其实有很多很多的问题我们都解决不了,比如大家发现一个问题叫“异或问题”,这什么意思呢?我们在进行分类的时候,比如说我们这个屋子里面,如果把男生和女生画一条线,画一条直线,我们能不能把这个区别开来的,可以的,从我手指这里划一根线就可以分出来,所以这是一个叫做线性可分问题,但是有很多这种划分问题,可能不是线性的可分。
我不知道各位的籍贯是多少,但是我假设我们没有办法,画一条线,把在座的所有的南方人和北方人划分开来,因为大家坐的很散。那像这样的问题通常我们就称为“异或问题”,就是一条直线没有办法来切分的问题。当时是明斯基他发了一篇文章,他说神经网络没有办法解决异或问题,当时大家就傻眼了,真的连这么一个问题都解决不了,那还谈什么人工智能。后来到了1973年的时候,就有一个人,他是兰德咨询公司请来的叫莱特希尔,他写了一个报告,他全面分析了整个人工智能界,最后他得出来负面的结论。莱特希尔报告被很多人都相信了,尤其是政府。结果导致今后差不多十年的时间,人工智能界根本拿不到钱,这是第一次人工智能的冬天,大概有十年的时间。
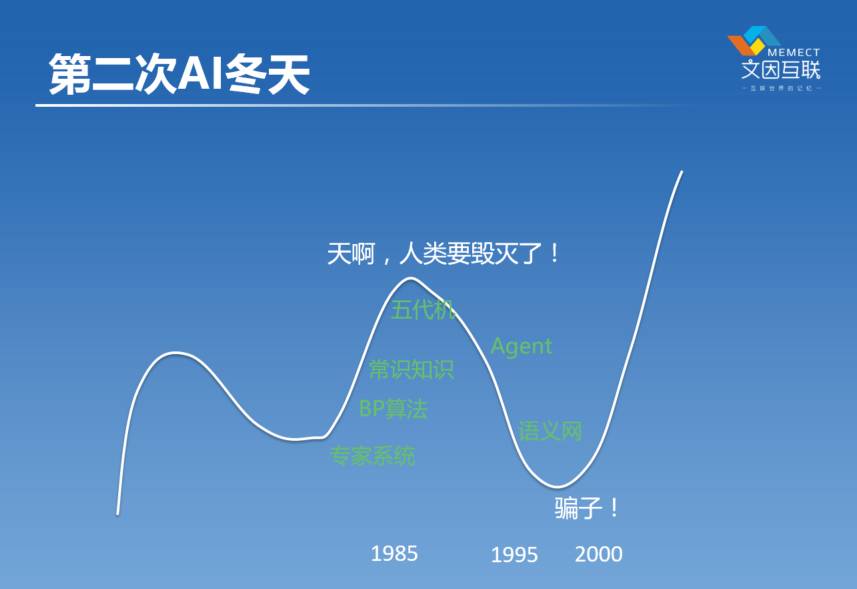
其实底层的很多工作,大家还是在继续的。要说人工智能这个行业,大家从媒体上来讲的时候,包括从政府来看的时候,会有所谓的冬天和夏天。但是这个世界上永远有一群意志很坚定的人,就像Geoffrey Hinton这样的人,他不被外界所有的事情所转移的,他就相信这个事情。所以不管AI是冬天也好,夏天也好,明斯基、西蒙、麦卡锡包括他们的徒子徒孙们,一直都在坚定推进这个理念往前走。
推进了十几年,到1985年的时候,我们又迎来了一个新的春天。所以在70年代末有了专家系统,后来到1985年的前后的时候,神经网络有一个算法叫做BP算法,误差反向传播算法。后来有了常识知识,常识库。一直到了80年代末到90年代初的时候,有了日本的五代机计划,一浪一浪把人工智能又推向了一个新的高潮。当时大家觉得人类又要毁灭了,又是这种感觉,但其实并没有。90年代,大家又发现,不是这样的。BP算法发展到90年代初期的时候,虽然解决了所谓的异或问题,但是大家发现它是没有办法去解决所谓的局部最优问题。
局部最优问题是什么?比如说,我们在寻找屋子里面,最高的位置在哪块,可能在天花板某一个位置上,但是我们通常在人工智能里面,我们去寻找这样一个所谓全局最优问题的时候,我们看我们的周围哪一个点比现在这个点高。如果这个点高,我们就往前走一步。假设说这儿有一个小蚂蚁,它在找这个屋子最高的点,它看到这里有一瓶矿泉水,它看这个点比我现在高,那么就往上爬,爬爬爬,爬到矿泉水瓶顶上去了,它再没有办法往上爬了。这个问题是BP上好像没有办法解决的问题,当时的学者想了很多办法,很多招。我在整个硕士期间,其实都在想克服这个问题,然而并没有。其他的千千万万的科研人员,也没有找到解决这个问题的一般办法。
第二个问题刚才我已经提到了叫泛化问题,还有一个速度问题,实际上神经网络在所谓的BP算法那个时候是很笨的。它会反反复复地遇到一些任务,然后它会把这些任务重复一万遍,因为它跟那种所谓的逻辑的方法是不一样的,它是一个黑箱算法。
什么叫黑箱呢?比如说我们每一个人的大脑就是一个黑箱,你看到我在说话,但是其实你并不知道我脑子里是怎么想事情的。我们看一本书的时候是不一样的,这一本书每一个字我们都是能看得到的,这个东西就叫白箱。但是神经网络是一个黑箱,所以一个黑箱算法你只知道它行。为什么行?如果它不行怎么改一点?一点办法都没有,它没有真正的结构在里头。这就是当时在90年代的时候,我们遇到的困难,当时谁也找不到办法,上万的人去找这个解决方案,谁都没有找到,所以这个领域进入了第二个冬天,大家就被称为骗子,90年代中期到晚期的时候。
这里还列了另外两个概念叫 Agent 和语义网,其实他们是在知识这个领域里面的一些努力。语义网在逻辑整个往下走的时候,就有人就想能不能到网络上,在互联网运行。我们之前的逻辑的研究都是面向什么军工、医药这些事情上面,有人想这个东西有没有可能用到互联网上去呢。就有人开始试了,就是以前网上这些内容,都是给人读的,那我们能不能用一些机器帮我们读网页。这会有什么好处呢?因为网页太多了,就像大家看这个股转书或者看报告,根本看不过来,能不能让机器帮我们读呢。就是这么个想法。他们是想用在这种千家万户都需要的事情上,比如说旅游、医疗这些事情上面。这个领域就称为语义网,这个是2000年的时候成立的。
经过了差不多十几年不懈的努力,人工智能整个领域里又从低谷里跳出来了。尤其是在90年代的时候,互联网可以说改变了一切,互联网改变了人工智能。在有互联网之前,很多年的时候已经有了所谓的机器学习的算法了,但是机器学习一直都没有起来,90年代反而起来了,大家知道为什么呢?因为数据量大了。有了互联网,我们第一次有了非常廉价地获取数据的这种方式。
在有互联网之前,比如说我们当时在90年代的时候,学习机器学习的时候,我们根本找不到数据集,当时有加州大学埃尔文分校做了机器学习的一个数据集,大概是三四十个这样的数据集,都是人工去收集下来的。当时我们就用那么小的数据集做实验,现在看简直是不值一提,但当时收集数据是非常的昂贵、昂贵到大家都做不到。但互联网改变了这一切,所以在90年代末开始机器学习就飞升起来了。
另外就是跟其他的领域产生了交叉,比如说跟大数据,后来演化出了数据科学。深度学习,如前所述,在2006年到2012年之间兴起来了。多说几句为什么深度学习能解决之前的问题呢?对于这个问题,不同的学者有不同的看法,在我个人看来,深度学习它之所以能够解决掉原来我们BP算法不能解决的各种问题,就在于它把原来一个很黑箱很黑箱的东西,就是我们不知道它是如何工作的一个东西,变成了相对而言更加有结构了。
我们之前在进行神经网络计算的时候,同一个子任务可能要算一万遍。但是有了深度学习之后,它分了很多层之后,实际上它每一层可以处理不同的任务,实际上就意味着我们可以把每一个问题分解,然后分解之后有一部分子问题,会反反复复用到的子问题,我们可以重用。当我们可以重用子问题的时候,我们整个计算的时间,就降下来了。
比如说我们用人脸识别做例子,我们一看到这个人,我就知道他是一个人,我们人很厉害。但是机器怎么做呢?首先它要是看一个一个的像素点的,我们每一个脸都是由很多很多个点组成的,几千万个点,然后这个点构成了什么?比如嘴唇它是一条线,因为机器首先知道这是一条线,那这里又有一条线,中间还有一条线。那机器怎么知道这个是嘴唇,这个是嘴,它要通过这些线,然后纹理、颜色,每一个都是所谓的特征。然后它可以判断出来,这一块地方,它把它称为嘴。同样这一块是鼻子,这一块是眼睛。
那么我们在进行人脸识别的时候,如果机器它能够事先训练出来一个,比如说鼻子的模型,比如说嘴巴的模型,那我们就可以重用这个模型,我们要想训练一个鼻子的模型,我们应该先训练什么呢,我们要训练识别这个线条阴影纹理,这些线条阴影纹理的这些模型,本身又是可以被重用的。所以说就变成了一层一层的叫所谓的特征的学习,那这样一来我们就把这个问题变成了一个可以被分而治之的问题,这就是深度学习的基本原理,这是我个人的理解。不知道有多少人听说过叫动态规划这个算法。在我看来虽然深度学习不是动态规划,但是它背后的机理跟动态规划非常接近的地方就是重用。
后来在2011年的时候问答系统也出现了突破,当时IBM Watson系统,在参加危险边缘(注:一个百科知识抢答游戏节目)的时候,击败了人类世界冠军。以前谁也没有想到百科知识抢答,机器可以答得比人好。但是实际上我们做到了,之所以能够做到,还就是基于之前我们机器学习的长足的进步,还有信息检索的进步,还有之前提到的另外一个技术叫语义网的进步,这十几年的努力。所以我们看到,语义网虽然是在人工智能低谷之前开始的,也是一样的,这么多人坚定地推进,终于在10年之后,我们得到了回报。
人工智能的未来?
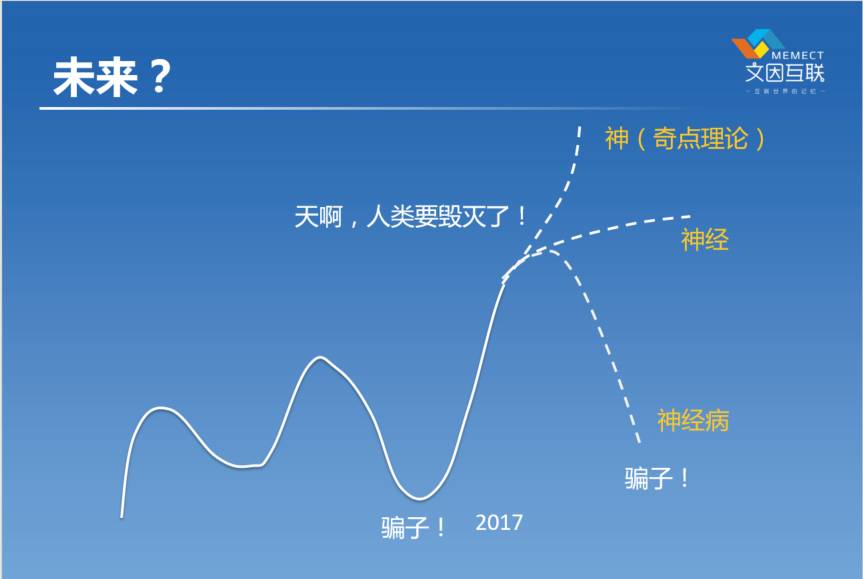
再后来,我们有了知识图谱,有了AlphaGo,尤其是最近一两年,大家又开始喊人类要毁灭了,机器要取代分析师,机器要取代交易员了。真的是这样吗?我觉得未来有三种情况。
一种可能就是“神”。现在大家常听说的奇点理论。假设人工智能会指数发展,库兹韦尔提出的,知乎上有人总结出一个“吓尿指数”,就是说人类的技术在他看来,就是不停指数地往上增长的。如果按照这个理论往前走,到了2045年的时候,机器就把人干掉了。你想,我们之前花了几十年的时间,我们才到了今天,如果是指数,我们可能要经过20年,就经历过去100年的进步,那会是什么样的局面?这个理论对不对?不知道。
另外两个可能的理论,一个就是神经。像我们这些人,我们都自称为“人奸”,我们公司有一副对联叫“不要问机器为你做了什么,问问你为机器做了什么”,横批是“脱碳入硅”。我们从碳基生物变成硅基生物。当然这些是开玩笑。“神经”的真正意义,是指机器帮我们做一些繁琐而相对简单的脑力劳动,帮助我们构造人类社会的神经系统。
但是最悲惨的应该是说变成一个神经病。我们又被发现做不了很多事,别人发现我们是骗子。我们现在如果说要取代分析师,能做到吗?过了5年发现做不到,十有八九,别人会说我们是骗子。因为之前已经被说了两次了,所以做人工智能总的来说还是比较淡定的,尤其是做得越久的人,越习惯于被人说是骗子。
这三个可能性,我觉得具体到哪一种,不取决于人工智能这个领域的研究者本身,可能更多取决于像我和各位这样的互动。如果大家觉得人工智能会是第一种结局的话,那么最终就有可能是最后一种结局,这是“双输”的结局。如果大家觉得人工智能无所不能,大家就会发现我们是骗子。如果一个行业,大家能够真正理性地去看它,我更认为中间那个所谓的“神经”会是我们的结局,这一种结局是对大家最有利的,让这个领域坚定地往前走,然后一点一点地往前推进。
人工智能的经济学
这是我自己的一个看法,刚才我们回顾了人工智能各种各样的起起伏伏,我们也看到了它的鄙视链不停地变化。我自己不停地在想,为什么会有这种变化?到底是什么原因导致了各种不同的算法?有的时候这个算法好一点,有的时候那个算法好一点。我的理解是,我们看人工智能的时候,不能仅仅从数字的角度来看这个问题,因为学者也不是生活在真空当中的,我们都是要钱来养活的。那么钱怎么来的?实际上是个经济学问题。
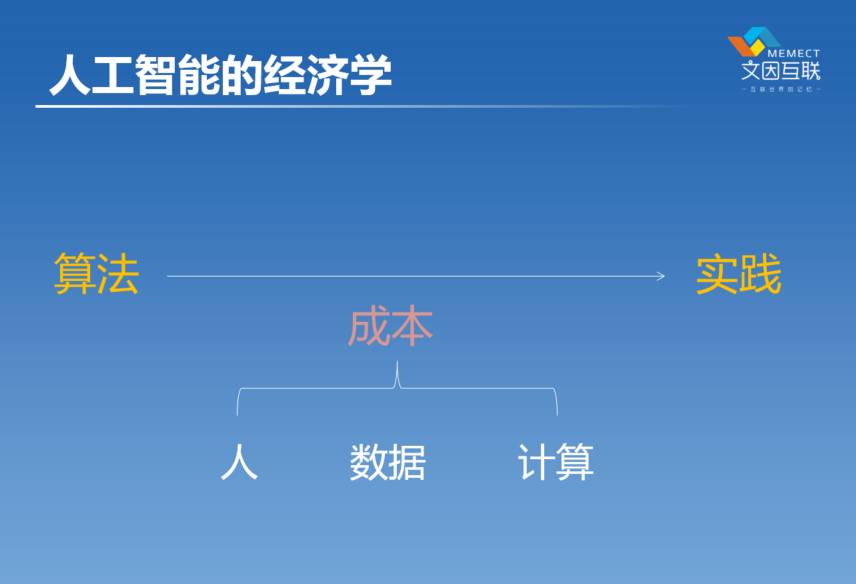
我们从一个算法到实践,都需要付出成本,我们怎么降低这个过程的成本,在我看来是人工智能这个算法能不能有生命力的关键。我把成本分为三个大的部分,人的成本、数据的成本、计算的成本。计算的成本是很好理解的,机器跑的时候要费电、机器要花钱,现在我们虽然有了云计算了,那还是个机器,也是要花钱的。好在我们有摩尔定律,这个成本是不停地指数在下降的,这个是非常坚定的在过去几十年不停的变化,这是好办的。
我们再回过头来说数据,其实在十年之前,大家都还不太看重这个事情,可以说从90年代末之后十年时间,机器学习起来了,虽然起来了,大家还是不理解为什么起来了,后来到了2009年,还是什么时候,谷歌写了一篇文章,名字就叫做《数据的不可思议的有效性》。在他们看来,你搞什么算法都没用,你只要有足够多的数据就行了。你只要有足够多的数据,最后所有的算法,结果都是一样的。
谷歌是一个非常富有的公司,它可以以非常低的成本占有非常多的数据,所以它有资格、有底气说这句话,在这之后,也就引发了所说的对数据的影响。大家后来都变成这么想了,我不去研究算法了,我就研究数据,后来有了深度学习以后,大家对数据的迷信就更深了。因为以前我们要做一个什么算法,还得去搞一个语义专家,比如下棋就要有下棋的专家。1997年的时候,IBM深蓝去下国际象棋的时候,确实是找了很多行业专家去研究象棋的定式是什么样的,然后做特征。后来去年AlphaGO下围棋的时候,这些东西完全都没有了,AlphaGO团队里没有什么真正的围棋专家的。一个围棋棋盘19乘19,361个点,每个点,他们总结了48种特征。我们知道围棋的定式肯定不止48种,以他们的计算机科学家的能力,他们能找到48种特征,然后他们就不再去找了,让机器去找更多的特征。这个时候,数据的作用就起来的。像AlphaGO是对16万局的对弈数据做了学习,大概3000多万个落子点的学习,在此基础上,它就打败了李世石。所以这就是数据的力量,慢慢就变成了大数据迷信,只要我们有了数据,其他什么东西都无所谓。
但是这个数据迷信,在我们面临的很多新的问题上面,还是解决不了的。比如说像我们在自然语言处理里头,或者在网络搜索里头,我们解决不了数据问题,即使数据多,我们也很难解决。比如实时的问答的问题,比如说Siri,有多少人在用苹果的手机?几乎所有人。有多少人经常的用Siri?有2个,那还是一个小的比例。其实苹果它有非常多的数据,它为什么还是解决不了这个问题?因为仅仅有数据是解决不了这种丰富的结构的问题的。
我们把世界上的问题分成两种,最粗暴的来分,一类是猫和狗能解决的问题,一类是猫和狗解决不了的问题。什么是猫和狗能解决的问题?比如说人脸识别,是一个猫能解决的问题。狗认得自己的主人,所以连条狗都认得自己的主人。那么机器认得了自己的主人,自己能做人脸识别有什么奇怪的呢?那么狗能够读书吗?不能。为什么?因为那是人类创造出来的东西,那是一种有极其丰富结构的东西,所以说现在这个深度学习,它对于自然的特征的处理,比如说语音或者图象,它是很棒的。但它对于更加丰富的知识结构,其实它是很难去发现的,这是有一个它不能够处理的边界在那里。数据是有用的,但是数据不能迷信。
我们怎么去解决大数据也解决不了的问题?实际上就回到了第三个点,人类成本。几乎所有的最重要的知识库都是人创建出来的,比如说维基百科,比如说之前各种纸的百科全书、教科书,我们看到的所有的书都是人写出来的,基本上还没有机器写出来的。我们看到了,现在在网上有很多所谓的机器新闻,但是有多少人会把这些机器写的新闻变成一本书,大家会愿意看吗?通常机器写的东西是转瞬即逝,毫无价值的东西,因为机器是无法往下洞察的。机器到目前为止,它写出来的这些所谓的文章也好、新闻也好,它不具备所谓的知识的沉淀的意义。
如果我们要想解决Siri这个问题,我们必须让Siri更加深入地去理解人。比如说这是女生喜欢的东西,这是男生喜欢的东西,你的偏好是什么,你的上下文是什么?这件事情是很难仅仅通过数据学习得到,它必须通过其他的人贡献出来的知识才能做。所以这就到了第三个成本了,人的成本。我经常开个玩笑,我们现在人工智能所面临的各种问题,如果我们发生世界大战的话,都解决掉了。为什么?因为如果我们打世界大战,政府马上就会抓1000万个壮丁来标注数据,可以帮我们把所有问题解决掉。目前我们不可能用这种方法来做,我们必须还是要用经济学的方法,用市场能够接受的方法来解决这个问题,降低人的成本,这也是整个知识工程领域大家一直在想的事情,如何降低成本。
人机交互的意义
我这里就提出我的第四定律,其实这是我的假设,目前不是学术界统一认识的观点,只是基于我过去差不多20年的个人的经历。我认为这个东西,如果我要列人工智能第四定律就是这个。在我看来人工智能的关键是采集人的智能,我们如何能够让人的脑子里面的知识更快地进入机器里面,是解决我们面临的很多困境的根本方法。
刚才提到了互联网带来的数据是为什么机器学习兴起的原因。我们深入去想一想,再前面的那些原因是什么?我们可以追溯到鼠标的发明者,这是一个很长的链条了。我们有了鼠标,我们才有了图形用户界画,我们有了图形用户界画,我们才会有了Web,你能想象一个没有图形用户界面的浏览器是什么样子吗?这东西是存在的,真的是存在的。比DOS还要再老,这样一种东西,会让普通的千家万户的人去用吗?不可能。正是有了前面人机交互的进步,所以我们才会有了千家万户的,每个人都会用的互联网,所以才会有了数据,所以统计机器学习才成为可能。
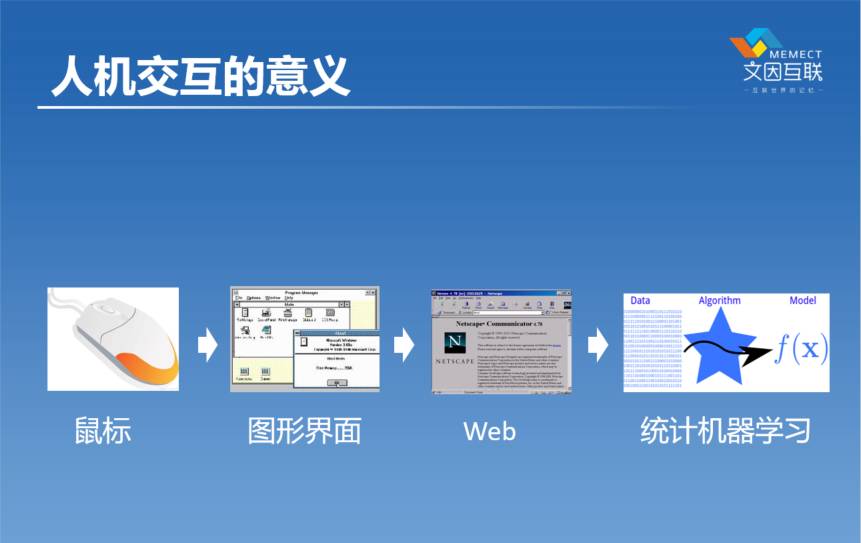
我这里列了另外两个技术,这两个技术到目前为止,基本上不为人所知的,只有非常少的人知道这两个技术。在我看来,这两个技术对于人工智能将来的意义是不亚于鼠标和图形用户界面的。
第一个技术叫分面浏览器。当我们有了非常多的数据之后,我们怎么去尽快地找到我们需要的数据?我们现在通常用的叫做搜索引擎,搜索引擎有啥问题?我可以说几个问题。第一,假如说我现在问你,自然语言处理的公司在新三板上有哪些?你能搜得到吗?比如说一个公司它是做实体识别的,它是自然语言处理的公司吗?同样,如果你要问我一个金融问题,我也回答不出来,因为我没有那个领域的知识。现在的搜索引擎,它必须要求这个人有这个知识、知道这个关键词,才能找到这个东西。能不能让机器帮助我把一部分知识的负担给转移过去,不需要我知道这么多东西,让机器知道些东西,这是第一点。
第二点,我们在搜谷歌和百度的时候,经常搜搜搜词不对,回去换一个词,后来一搜,搜个东西看到有一个点,看了一下这个文章,这个文章里头又有一个词挺有意思的,选中了,鼠标右键一点接着搜,跳跳跳、往前跳,这是个什么过程?探索。我们从一个点跳到另外一个点,又跳到另外一个点,这是在一个复杂的知识网络结构上面,我们在不断地发现新的世界的过程,所以分面浏览器不是搜索引擎,是探索引擎。
在我看来人工智能往前走,我们追求的不仅仅是算法。回到人工智能第四定律,如何采集人的智能,在我看来是把人工智能往前推进的一个核心的方法论。分面浏览器和探索引擎,就可能是这样一种东西。这完全是一个假说,没有任何证据,因为这个东西还没有发生。我在文因互联跟我们的团队一起就想把这个东西变成事实,但这是一个很长期的事情。我们现在是在金融这个领域里面去做,比如说我们把各种各样的股转书、研报,放在一个探索引擎里面去,试图来帮助用户,让他们不要去记住这么多东西,让机器来帮助你发现这些东西。我们现在还没有走到那一步。
第二个叫图谱编辑器,我们之前把它称为本体编辑器。这个东西从某种程度上来说,它的商业价值已经被证明了。有一家公司叫 Palantir,Palantir市值是120亿。我们现在回到刚刚开始的地方,有一个词大家并没有注意到的,就是我做的一份工作语义WiKi,它其实是一个协作式的知识的编辑系统,让很多人在一起能够一起写东西,我们当时把它称为叫知识编辑系统,现在我们已经把它称为叫做图谱编辑系统了。所以Palantir,他的想法是说人有一部分知识,机器有一部分知识,我们把人机放在一起作为一个系统画龙点睛,机器画龙,人来点睛,人去发现那些事物背后最难发现的那些点。最早的应用领域在情报领域,最早是CIA投资他们来做这个事情的,最后他们发现这个东西在整个商业智能里头,在反欺诈金融领域里面都有很大的作用,Palantir现在有一半的收入是来自金融领域。

在我看来,不管是抓本拉登也好,还是抓麦道夫反欺诈也好,都还并没有真正能够把这个技术的真正的威力爆发出来。我们去对比另外一个领域,EXCEL电子表格。回到70年代末,电子表格刚刚出现的时候,70年代末的时候已经有数据库了,为什么还会有电子表格?电子表格跟数据库比有什么新鲜的地方?不就是一堆格子吗?有啥新鲜的? 我觉得最大的区别在于,数据库是为机器设计的,电子表格是为人设计的。
我们在研究数据库的时候,我们天天想的是这个查询能不能更快一点,我们下面搞了一大堆索引,能够让SQL跑得更快一点。对于电子表格而言,我们关心的是什么问题?这个数据这么排序不对,换一种排序,两列放得太远了,眼睛看不过来,得这样看,能不能放这儿?从这一列拖到这儿。在这个问题中,我们服务的是人,作为一种猿,我们的认知能力非常非常得有限,比金鱼强一点,但还是不行。那我们就要用各种各样的工具来帮助我们,提升我们的认知能力,这是电子表格帮助我们做的事情。
那么电子表格是帮助我们在一个框框上面,表格上面做到了这些事情,一个平面的东西。图谱能帮我们做什么?立体的东西。在我们表格上面所看不到的那些背后的关联,我们现在是用图来表示的,这个是图谱能够帮助我们发现的。所以我认为图谱编辑器往前走,极有可能创造出一个比电子表格还要大的business出来的,Palantir 只是走了一小步,我坚信往后会有更大的成果。
这只是随便举了两个例子,就是分面浏览器和图谱编辑器。在我看来这两个东西都是有可能像鼠标一样,带来非常巨大的人工智能的突破的东西。
未来迷信:奇点?智神?
今天晚上八卦就讲完了,还是回到预言未来这件事情上来。《奇点临近》这本书肯定有很多人听说过,库兹韦尔的书,这个人是一个江湖术士,我不会推荐大家看这本书。他所说的所谓2045年奇点临近这个理论,以我自己的看法,我认为是不成立的。因为人工智能,大家已经看到了,真的不会指数性往上增长。
我觉得很有可能的,虽然是很不幸的,是10年之后,可能更多人叫我们是骗子。因为最近几年是太热、太热了。《未来简史》这本书,它的副标题叫“从智人到智神”,这本书有多少人听说过?4个。我也是前天才买了一本,在来的火车上还在读。我之前读了《人类简史》这本书,《人类简史》那里面讲了很多人类的未来会怎么走,《未来简史》接着往前推他的推论。但是在我看来,他讲的东西,我也不是很信服的,因为他在讲人和机器最后会融合,我们的大脑,我们的四肢全部变成一个机器,搞成一个怪物出来,他把这个东西称为“智神”。

我不太相信这个观点,在我看来,我还是跳到《社会机器》这本书讲吧。我比较信奉“社会机器”这个理论,当然我是有偏爱的,为什么我相信这个理论?因为这两位老先生是我的导师,所以我是他们这个学派。上面这个先生叫James Hendler,是我博士后期间的第一位导师,他是语义网的创始人。“社会机器”-Social Machines这个理论是下面这位先生提出的,他叫 Tim Berners-Lee,他是Web的发明人,就是整个万维网的发明人。今天大家每个人每天上网,要感谢他在1990年的时候,做出的这个发明。Tim Berners-Lee,在我看来,是当代对人类的历史进程有最大的影响力的人之一,真正的哲学家,真正的思想家。在1999年的时候,他写了一本书,在这里面提出来了“社会机器”这个概念,就是说我们人类组织在一起变成了一个社会,以后社会的成员不仅仅是咱们人类,还会有机器。我们大家为什么天天没事就在刷手机?因为现在机器真的变成我们不可分割的一部分了,所以说整个社会不仅仅是由人类组成的,越来越多的机器也会参与进来,作为我们人类和人类之间的媒介也好、中介也好。
我们人类应该做什么事情?我们人类最大的能力就是创造性,机器可以做什么?机器最大的特点就是不厌其烦。我在公司里面,跟我们那些小姑娘重复地说,如果你遇到任何一件让你烦的事情,请你告诉我,我一定有办法把这件事情干掉。所有让人烦的事情,最终都会被机器干掉,最终我们人类就只去做那些有创造性的东西了。所以人类负责创造,机器负责管理,这就是“社会机器”这个概念。Tim Berners-Lee发明了万维网这个东西,他认为未来会变成社会机器。
跟了他们几年之后,我又把它往前推了一步,这只是我个人的见解。在我看来,我们是怎么到那一步的?比如我们今天在谈话的时候,我们之间的信息传输率是多少?每秒钟几个比特,可能比任何机器之间都要慢,我们最慢的调制解调器,也是3600kb/s,比我们要快至少1000多倍,所以人类的通信能力是非常非常低下的。
包括我们的记忆能力也非常非常低下。为什么手机短信的验证码是六位?大家想过吗?七位咱们就记不住了,只能记住六位,所以咱们这个脑子是非常有限的。就这么一个脑子消耗掉我们20%的能量,多么的可怕,多么低效的东西。最终会是什么样?当我们的能力非常低下的时候,我们肯定需要用机器来提升我们的能力,所以说我们人类之所以现在大家天天早上刷微信、晚上刷微信,不停地在刷微信,就是因为我们要用机器提升我们的通讯能力,提升我们记忆的能力。
我的名片上面写了,叫互联世界的记忆。这就是在遥远的未来,我们的一个愿景,能不能让机器来提升我们的记忆能力?当然也有其他的公司会说,我们能不能用机器来提升我们的通讯能力?最终就是走向社会机器。机器帮助我们做好那些我们做不好的事情。或者说,如果说《未来简史》里所提到的很多东西能够变成事实,机器真的将来有一天跟人类变成一体了,不是把我们每一个人变成了机器人,而是把我们整个社会变成一个机器。我们的社会,我们的通信系统变成了一个机器,我们把几十亿人加在一起变成一个机器,这可能是比这两个理论更靠谱的一个理论,这可能是很遥远、很遥远的未来,可能100年之后才会出现的事情。基于我们现在能够看到的,我觉得就是在我有生之年,我们能够预言到的事情。
Web、Semantic Web、Semantic Wiki,是Tim Berners-Lee在1990年的时候,他在发明Web的时候,他写了一个项目计划书,就提到这三样东西。但他没有用这三个词,这三个词是我总结出来的。第一步,我们要Internet+超文本,Internet是60年代就有的技术,Internet加上超文本,就是我们现在天天在互联网上看到的那个Web技术。然后我们有了Web之后再加上所谓的元数据,元数据是什么?就是数据的数据。比如说我们打开一本字典,字典每一个词条后面有解释,那个解释就叫元数据。如果我们把全世界的万事万物都给它一个解释,那就是有了语义网。如果我们有了语义网,再加上一个探索引擎,就变成了Semantic Wiki。
这是Tim Berners-Lee在20多年前的时候,他设想的一个东西。当我们在实践的过程中,我们发现计划赶不上变化,变化是什么?我们花了大概十年的时间实现了第一代的Web,叫做文档的Web。到了2000年的时候已经很成功了,已经出现了亚马逊和雅虎这样伟大的企业。后10年,我们曾经以为是Semantic Web,后来发现并没有,变成了Social Web,是Twitter、Facebook这样的公司起来了,把社会互联起来了。
过去不到10年,2010年到2020年这时间内,我们把它称为Data Web,就是大数据。实际上大数据所对应的,并不仅仅是数据量大,而是我们有了越来越多的数据,越来越多的元数据,我们可以进行自动化,我们可以有很多任务不用我们人完全去干了,机器可以帮我们去做一些简单的事情。
为什么能有今日头条?今日头条是一个内容分发网络,实际上它背后是一个推荐引擎,为什么能有推荐引擎?因为有了数据,我们可以做自动化才能有这样。这就是为什么百度很紧张的原因,百度也提出,我也要做分发网络。这是历史了。我们现在正在历史的转折点,我们把前面称作Web的上半场,Web的下半场是什么?在我看来,从2020年到2030年,主旨应该是智能化。我们有了很多很多元数据之后,我们往后真的可以去实现一些现在看起来很炫、很酷的东西,不仅仅是下棋了。比如说大家现在面临投资的问题,说 AlphaGo 现在真的威胁到各位了吗?我想现在并没有。但是真的有可能在10年之后,会威胁到大家。可能对于高级分析师,大家还能再多撑一段时间,但是很多初级分析师的工作,真的有可能在10年到15年的时间内被取代掉,比如写报告这些事情,分析报告这件事情,真的有可能被机器干掉,这是智能化。
这个词是我自己杜撰出来的,叫 Meme Web,就是机器增强的群体智能。归根结底,如果我们仅仅从机器的角度来看这个世界是不够的,回到人工智能第四定律,所有的智能都是从人类来的,我们能够把人组合在一起变成一个社会,才是真正能够让我们的所谓的智能系统达到最大化的状态,我把这个东西称为机器增强的群体智能。这也是2040年,可能那时候我已经快退休了,能达到这个目标,这也是我毕生追求的目标。
这就是我们文因互联的长期的愿景,虽然这个愿景跟我们现在做的很多很多的事情是没有关系的,但这也是激励着我们这些人,为什么奋不顾身的去投入到这个可能称为“骗子”行业的根本原因,因为这件事情太酷了。


加入智能金融交流群
添加微信群管理员微信号 qgyx123,附上姓名、所属机构、部门及职位,审核后管理员会邀请您入群。






