容错和高性能如何兼得: Flink创始人谈流计算核心架构演化和现状

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
当前,流数据平台的普及率正在飙升。为了解决日益增长的实时数据处理需求,一些公司正在将其部分大数据基础架构转换为流式处理模型。 基于流数据的基础架构不仅能够更好地解决延迟敏感的数据处理业务需求,同时提供更多深入业务洞察 ; 另外,流式数据处理平台让传统的数据仓库建设更加简单灵活。
流式基础架构的关键部分是流计算引擎。优秀的流式计算引擎可以让业务即使在有状态计算的情况下,也能提供低延迟、高吞吐、强一致性。
在本文中,我们将深入探讨 Flink 的检查点机制如何工作,以及它如何取代旧架构以实现流容错和恢复。 我们测量 Flink 在各种类型的流媒体应用程序中的性能,并通过在 Apache Storm(一种广泛使用的低延迟流处理器)上运行相同系列的实验来进行效果对比。
在流式计算领域,同一套系统需要同时兼具容错和高性能其实非常难。 在传统的批处理中,当作业失败时,可以简单地重新运行作业的失败部分以修复由于之前失败导致的数据丢失。 这对于批处理是完全可行的,因为批处理的数据是静态的,可以从头到尾重放。 在连续的流式处理模型中,这种处理思路是完全不可行的。
原则上,数据流是无穷无尽的,不具有开始点和结束点。 一个带有 Buffer 缓存的数据流或许可以进行一小段的数据重放、重新计算 (即: 如果系统出错,系统可以尝试从在 Buffer 中缓存的数据流进行重新计算),但出错时希望从数据流最开始点进行重新计算是不切实际的(例如,一个流作业可以运行数月之久,当出现系统故障时候导致数据计算出错不可能参考批处理系统,从几个月前的数据开始计算)。 此外,与仅具有输入和输出的批处理作业相比,流式计算是有状态的。 这意味着除了输出之外,系统还需要备份和恢复部分计算 (我们称之为 Operator,下同) 状态。
由于这些问题带来的诸多复杂性,开源生态系统多个系统都在尝试多种方式来解决容错问题。容错机制的设计将对框架设计预计编程模型都有深远的影响,导致难以在现有的流式框架上类似插件机制一样扩展实现不一样的容错策略。因此,当我们选择流式计算内框架时,容错策略非常重要。
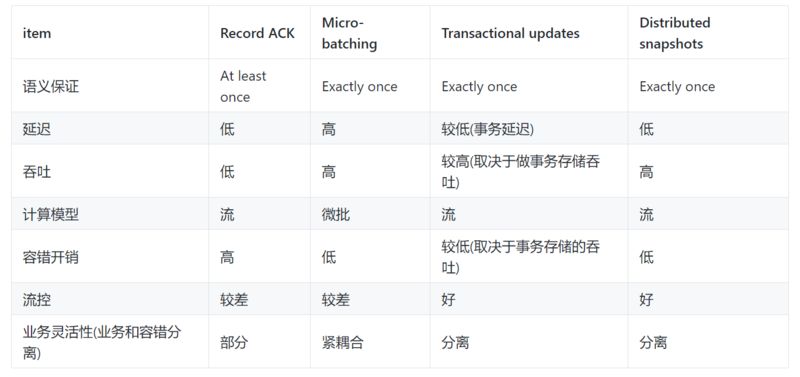
接下来,我们将讨论了容错流式架构的几种方法,从记录确认 (record-acknowledgements) 到微批处理 (micro-batching),事务更新(transactional updates)和分布式快照(distributed snapshots)。 我们将从以下几个维度讨论各个系统的优缺点,同时最终选出一个适合流式处理的最优 Feature 组合。 我们将讨论:
完全一次保证:故障后应正确恢复有状态运算符中的状态
低延迟:越低越好。 许多应用程序需要亚秒级延迟
高吞吐量:随着数据速率的增长,通过管道推送大量数据至关重要
强大的计算模型:框架应该提供一种编程模型,该模型不限制用户并允许各种各样的应用程序在没有故障的情况下,容错机制的开销很低
流量控制:来自慢速操作员的背压应该由系统和数据源自然吸收,以避免因消费者缓慢而导致崩溃或降低性能
我们遗漏了一个共同特征,即失败后的快速恢复,不是因为它不重要,而是因为(1)所有讨论的系统都是基于完全并行的分布式处理系统,恢复是基础能力;以及(2)在有状态的应用程序中,状态恢复的瓶颈通常在于存储而非计算框架。
虽然流处理已经在诸如金融等行业中广泛使用多年,但直到最近流式处理才能为大数据的基础设施的一部分。 这些都得益于开源的流式大数据处理引擎成熟和发展。 Apache Storm 是开源生态中第一个广泛使用的大规模流处理框架。 Storm 使用上游备份机制和记录确认机制来保证在失败后重新处理消息。 请注意,Storm 不保证状态一致性,任何可变状态处理都委托给用户来处理(Storm 的 Trident API 确保状态一致性,将在下一节中介绍)。
译者注: 以下内容理解需要读者一定的 Apache Storm 基础,请参看 Apache Storm 官方文档有关 Storm 关键概念的描述。
记录确认的容错方式如下:当前 Operator 处理完成每条记录时都会向前一个 Operator 发回针对这条记录处理过的确认。
Topology 的 Source(译者注: Storm 的 Source 节点指 Storm 一个作业中负责从流式源头读取数据的 Operator) 会保留其产生的所有记录备份用来处理 Fail 情况。 当源头一条记录的所有派生记录都被整个 Topology 处理完成,Source 节点就可以删除其备份;当系统出现部分 Fail 情况,例如一条记录并没有收到其下游的派生记录的确认,Source 就会重新发送该记录到下游的 Topology 以便重新进行计算。 这种处理机制可以保证整个处理过程不会丢失数据,但很有可能导致同一条记录被多次发送到下游进行处理(我们称之为“at least once”)。 Storm 使用一种巧妙的机制来实现这种容错方式,每个源记录只需要几个字节的存储来跟踪确认。 Twitter Heron 保持与 Storm 相同的确认机制,但提高了记录重放的效率(从而提高了恢复时间和整体吞吐量)。
单独的记录确认容错体系结构,无论其性能如何,都无法提供 exactly-once(精确一次) 的保证,Storm 将规避重复数据的问题交给了流式处理应用开发者去处理。 当然,对于某些应用程序而言,数据小部分重复可以接受的,但仍然有更多的场景无法接受数据不准确的情况。另外,Storm 的容错机制还带来了吞吐不够以及流控问题, 特别是在 backpressure(反压) 情况下,记录确认的容错方式会导致上游节点错误地认为数据处理出现了 Fail(实际上仅仅是由于 backpressure 导致记录处理不及时,而无法 ack)。上述 Storm 的种种问题最终演化出基于微批处理的流式架构。
上节讨论到,Storm 和以及更早前的流式传输系统无法提供对大规模应用程序至关重要的一些 Feature,特别是高吞吐量,快速并行恢复,以及托管状态的一次性语义。 这导致了下一阶段的流式系统演化。
之后,具备容错能力的下一个发展阶段到了微批处理,或者说流离散化 (stream discretization,即将连续的流切分为一个个离散的、小批次的微批进行处理)。这个出发点非常简单:流式处理系统中的算子都是在 record 级别进行计算同步和容错,由此带来了在 record 如此低层次上进行处理的复杂和开销。很简单嘛,我们就把连续的数据流不要切分到 record 级别,而是收敛切分为一批一批微批的、原子的数据进行类似 Batch 的计算。这样,每个 batch 的数据可能会成功或者失败处理,我们就对当前失败的这一小批数据进行处理即可。
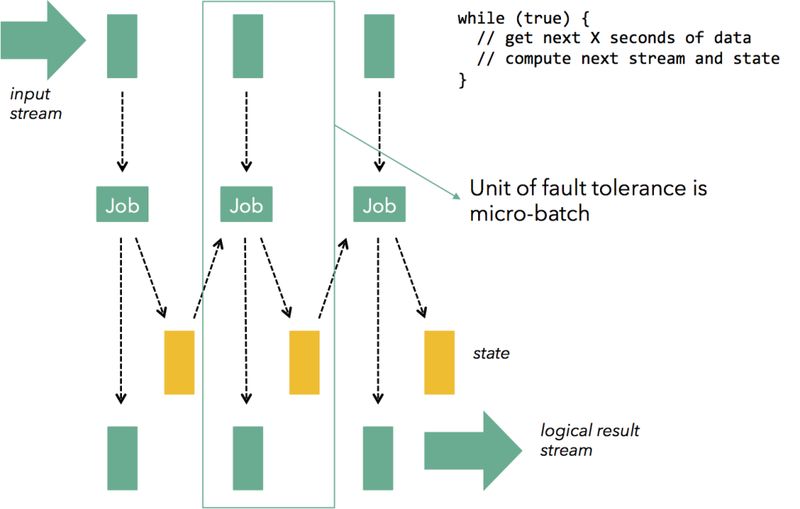
微批处理本质上一种批处理模型,显然可以利用现有的批处理引擎就可以完成流式计算。例如,可以在批处理引擎(Spark)提供流功能(这是 Spark Streaming 背后的基本机制),当前它也可以应用于流引擎之上(例如, Storm)提供一次性保证和状态恢复(这是 Storm Trident 背后的想法)。 在 Spark Streaming 中,每次的微批量计算都是一个 Spark 作业,而在 Trident 中,每个微批次都是一个大型记录,微批次中的所有记录都会合并进入一个大型记录。
基于微批处理的系统可以实现上面列出的相当多的需求(确切一次保证,高吞吐量),但它们还有很多不足之处:
编程模型:为了实现其目标,例如,Spark Streaming 将编程模型从流式更改为微批处理。 这意味着用户不能再在检查点间隔的倍数之外的时段中窗口数据,并且模型不能支持许多应用程序所需的基于计数或会话窗口。 这些都是应用程序开发人员需要的需求。具有可以改变状态的连续运算符的纯流模型为用户提供了更大的灵活性。
流量控制:使用基于时间的数据切分为微批的处理方式仍然具有 backpressure 固有问题。 如果某个下游的 Operator 处理较慢(例如,计算密集型 Operator 处理性能跟不上或者向外部存储写出数据较慢),此时如果负责数据流切分的 Operator 速度快于下游的阻塞节点,就会导致数据切分比原有的配置时间更长。 这导致越来越多的批次在内存排队等待被处理,最终内存 OOM,或者微批的时间间隔增大导致数据不精确。
延迟:微批处理显然加大了流计算延迟,一个微批作业的延迟最好情况也只能到微批的间隔时间。 通常情况下,亚秒级别的延迟对于一些简单应用程序足够,但一个较为复杂的流式处理任务,例如单个作业内部存在多个阶段,每个阶段存在大量分布式数据 shuffle 情况,很容易将整个作业延迟拉长的数秒甚至数十秒。
微批处理模型的最大限制可能是它连接了两个不应连接的概念:应用程序定义的窗口大小和系统内部恢复间隔。 假设一个程序(下面是示例 Flink 代码)每 5 秒聚合一次记录:

这些应用非常适合微批量模型。 系统累积 5 秒的数据,对它们求和,并在对流进行一些转换后聚合计算。 下游数据应用程序可以直接使用上述 5 秒聚合的结果进行数据消费,例如在仪表板上显示。 但是,现在假设 backpressure 效应开始起作用(例如,由于计算密集型的 transformRecords 函数),或者 devops 团队决定通过将间隔增加到 10 秒来控制作业的吞吐量。 然后,在出现 backpressure 情况下,微批量大小不受控制地动态进行改变,或者直接变为 10 秒。 这意味着下游应用程序(例如,包含最近 5 秒统计的 Web 仪表板)读取的聚合数据是错误的,下游应用程序需要自己处理此问题。 这样,流计算系统由于性能或者吞吐问题,直接导致了运行数据错误。
微批处理可以实现高吞吐量和一次性保证,但这些功能室以丧失低延迟,流量控制和纯流式编程模型为代价滴。 显然,我们需要思考清楚的是,是否有可能实现两全其美:在保持持续计算 (continuous process) 的运算符模型的所有优势,同时兼备一致性、高吞吐量等优势。 后面讨论的后续流式架构实现了这种 Feature 的组合,并将微批处理作为流式处理的基本模型。
注意:通常微批处理被认为是一次处理一条记录的替代方法。 这是见文生义的做法:所谓的连续计算并不是连续地一次处理一条记录。 实际上,所有精心设计的流计算系统(包括下面讨论的 Flink 和 Google Dataflow)在通过网络传输之前会缓冲许多记录,同时又具备流式连续处理能力。
如何做到鱼和熊掌兼得?在保持连续计算模型(低延迟,反压流控,状态管理等)的好处,同时保证做到数据处理的准确一致。一种强大而不失优雅的方式是原子地记录数据的处理以及状态的更新 (译者注: 类似数据的 WAL 日志)。 一旦系统出现 Fail,可从记录的日志中恢复我们需要的中间计算状态和需要处理数据。
在 Google Cloud Dataflow 中实现类似的模型。 系统将计算模型抽象为一次部署并长期运行持续计算的 Operator DAG。 在 Dataflow 中,数据的 shuffle 是流式的而非批模式,同时计算结果亦不需要物化 (数据的计算结果放在内存中)。 这种模型不仅解决了流式计算低延迟问题,同时还天然支持自然流量控制机制,因为 DAG 不同阶段的 Operator 之间存有中间结果的 Buffer,这些中间缓冲区可以缓解反压,直到反压恶化到最源头的 Operator,即 DataFlow Source 节点。而基于 Pull 模型的流式数据源,如 Kafka 消费者可以处理这个问题,即 Source 节点的中间结果 Buffer 会出现积压导致读取 Kafka 变慢,但不会影响上游的流数据采集。 系统还支持一套干净的流编程模型,支持复杂的窗口,同时还提供对状态的更新操作。 值得一提的是,这套流编程模型包含微批量模型。
例如,下面 Google Cloud Dataflow 程序(请参阅:https://cloud.google.com/dataflow/model/windowing )会创建一个会话窗口,如果针对某个 Key 在 10 分钟内都没有数据达到,则会触发该会话窗口 (译者注: 例如某个用户在访问 APP 期间中断了 10 分钟没有操作)。 而间隔 10 分钟后,如果新的数据到达,系统将创建一个新的会话窗口。

这种数据的处理方式在流式模型中很容易实现,但在微批量模型中很难实现,因为数据窗口的定义不对应于固定的微批量大小。
这种架构中的容错设计如下:通过 Operator 的每个中间记录,和本 Operator 计算带来的状态更新,以及有本条记录派生的新记录,一起做一次原子事务并提交到事务性日志系统或者数据库系统。 在系统出现失败的情况下,之前数据库的记录将被重放,用于恢复计算的中间状态,同时将丢失没有来得及计算的数据重新读取进行计算。
Apache Samza 遵循类似的方法,但只能提供 at-least-once 保证 ,因为它使用 Apache Kafka 作为后台存储。 Kafka(现在)不提供事务,因此对状态和派生流记录的更新不能作为原子事务一起提交。
事务更新体系结构具有许多优点。 事实上,它实现了我们在本文开头提出的所有需求。 该体系结构的基础是能够频繁地写入具有高吞吐量的分布式容错存储。 分布式快照(在下一节中进行了解释)将拓扑的状态作为一个整体进行快照,从而减少了对分布式存储的写入量和频率。
提供 exactly-once 流式处理语义保证的核心问题就是 确定当前流式计算的状态 (包括正在处理的数据,以及 Operator 状态),生成该状态的一致快照,并存储在持久存储中。如果可以经常执行状态保存的操作,则从故障恢复意味着仅从持久存储中恢复最新快照,将源头 Source 回退到快照生成时刻再次进行”播放”。Flink 的状态算法在这篇论文有详细说明,以下我们给出一个简单总结。
Flink 的快照机制基于 Chandy 和 Lamport 于 1985 年设计的算法,用于生成分布式系统当前状态的一致快照(请参阅此处的详细介绍 ),不会丢失信息且不记录重复项。 Flink 使用的是 Chandy Lamport 算法的一个变种,定期对正在运行的流拓扑的状态做快照,并将这些快照存储到持久存储(例如,存储到 HDFS 或内存中文件系统)。 这些做快照的频率是可配置的。
这类似于微批处理方法,其中两个检查点之间的所有计算都作为一个整体原子地成功或失败。 然而,这个就是两者唯一的类似点。 Chandy Lamport 算法的一个重要特点是我们永远不必按流处理中的“暂停”按钮,用来等待检查点完成后安排下一次 Batch 数据处理。 相反,常规数据处理始终保持运行,而状态持久化仅在后台发生。 以下引用原始论文,
全局状态检测算法应该被设计在基础 (业务) 计算之上:它必须与此基础 (业务) 计算同时并行进行,但不能侵入改变基础 (业务) 计算。
因此,该架构结合了遵循真正的持续计算模型(低延迟,流量控制和真正的流编程模型)和高吞吐量的优点,并且也是 Chandy-Lamport 算法可证明的一次性保证。 除了持久化有状态计算的状态(每个其他容错机制也需要这样做)之外,这种容错机制几乎没有开销。 对于小状态(例如,计数或其他统计摘要),这种持久化开销通常可忽略不计,而对于大状态,状态持久化间隔需要流计算应用开发者在吞吐量和恢复时间之间进行权衡。
最重要的是,该架构将应用程序开发与流量控制、吞吐量控制分开。 更改快照持久化的间隔时间对流作业的结果完全没有影响,因此下游应用程序可以安全地依赖于接收正确的结果。
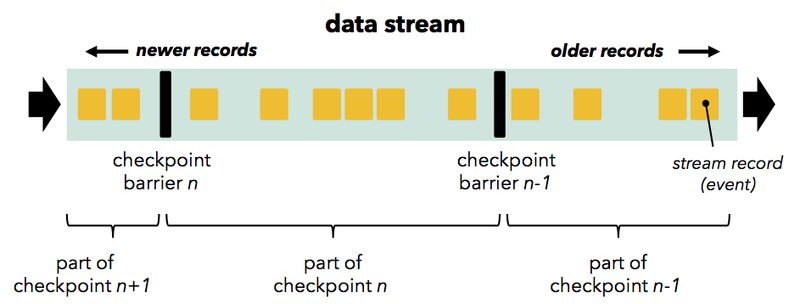
Flink 的检查点机制基于 stream barriers(可以理解为Chandy Lamport 中的“标记”),这些 barrier 像正常的业务数据一样在 Operator 和 Operator 之间的数据管道中流动。 Flink 的检查点的描述来自于 Flink 社区文档 ) 。
Barrier 在 Source 节点中被注入到普通流数据中(例如,如果使用 Apache Kafka 作为源,Barrier 将与 Kafka 的读取偏移对齐),并且作为数据流的一部分与数据记录一起流过下游的 DAG。 Barrier 将业务数据流分为两组:当前快照的一部分(Barrier 表示检查点的开始),以及属于下一个快照的那些组。
Barrier 流向下游并在通过 Operator 时触发状态快照。 Operator 首先将 Barrier 与所有传入的流分区(通常 Barrier 具有多个输入)对齐,上游来源较快的流分区将被缓冲数据以等待来源较慢的流分区。 当 Operator 从每个输入流分区都收到 Barrier 时,它会检查其状态(如果有)并写入持久存储,这个过程我们称之为状态写检查。一旦完成状态检查点,Operator 就将 Barrier 向下游转发。 请注意,在此机制中,如果 Operator 支持,则状态检查点既可以是异步(在写入状态时继续处理),也可以是增量(仅写入更改)。
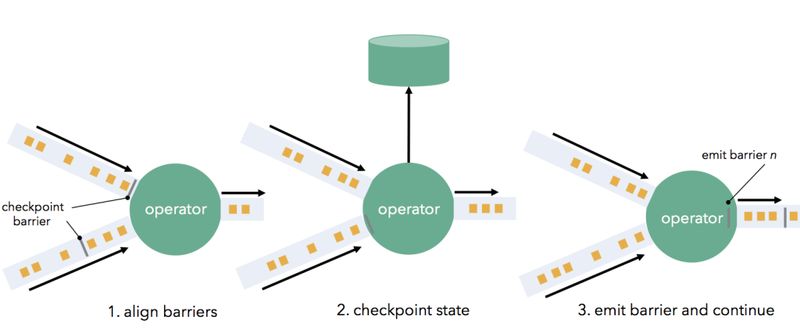
一旦所有数据写出端 (即 Flink Sink 节点) 都收到 Barrier,当前检查点就完成了。 故障恢复意味着只需恢复最新的检查点状态,并从最新的 Barrier 记录的偏移量重新启动 Source 节点。 分布式快照在我们在本文开头所要达到的所有需求中得分很高。 它们实现了高吞吐量、一次性保证,同时保留了连续的 Operator 模型、低延迟以及自然流量控制。
我们从这篇文章开始,列出了来自分布式流体系结构的需求。下表总结了我们讨论的每个体系结构如何支持这些功能。
为了进一步说明 Apache Flink™的性能,我们设计了一系列实验,用以研究 Flink 的吞吐,延迟以及容错机制的影响。下面所有实验均在 Google Compute Engine 上进行,使用 30 个实例,每个实例包含 4 核和 15GB 内存。所有 Flink 测试均使用截至 7 月 24 日的最新代码修订版进行,所有 Storm 测试均使用 0.9.3 版。如有需要,大家可以在此处找到用于评估的所有代码。
同时,为了更好进行横向比较,我们也提供了在 Apache Storm 上面运行相同程序的结果。如前面文章所介绍,Apache Storm 曾经是最广泛使用的流式处理系统之一,它核心机制是实现了"记录确认 (译注: record acknowledgements)"以及"微批处理 (译注: mini-batch)"。(后者是通过 Storm Trident 实现)
我们在 Google 云上,组建 30 台机器总计 120Core 的集群,用来测量 Flink 和 Storm 对两个不同程序的吞吐量。 第一个程序是并行流式 grep 任务,它在流中搜索包含与正则表达式匹配的字符串的事件。grep 应用程序具备的特征能够让 grep 非常容易做到并行处理,并且基于流分区进行伸缩。
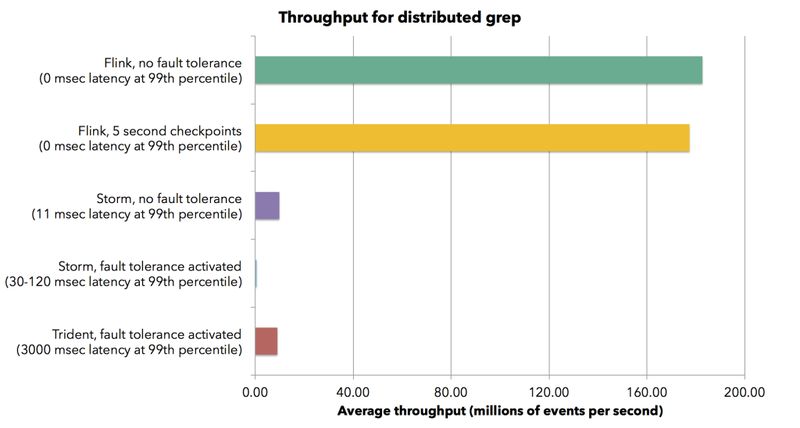
在 Flink 集群上,我们可以看到 Flink 每核每秒平均有 150 万条记录的持续吞吐量,这使 Flink 集群总吞吐量达到每秒 1.82 亿记录。Flink 的计算延迟为零,因为作业不涉及网络,也不涉及微批处理。而当打开 Flink 的容错机制,并设定每 5 秒做一次快照,可以看到的是 Flink 吞吐量有轻微降低(小于 2%)。可以说,Flink 优秀的容错机制并不会引入任何计算延迟。
在 Storm 集群上,当我们关闭记录确认机制(即没有任何数据准确性保证),Storm 处理吞吐能力是每核每秒约 82000 条记录,99% 的处理延迟在 10 毫秒以内,因此整个 Storm 集群的总吞吐量为每秒 57 万条记录。当启用记录确认(即保证数据至少处理一次,at-least-once)时,Storm 的吞吐量降至每核每秒 4700 条记录,同时 Storm 的延迟也增加到 30-120 毫秒。 接下来,我们使用 Storm Trident,其微批量大小为 200000 个元组。 Trident 实现了每核每秒 75000 条记录的吞吐量(集群总吞吐量与 Storm 原生处理机制在关闭容错机制情况下整体吞吐量大致相同)。然而,这个集群吞吐性能是以 3000 毫秒的延迟(99% 的百分位数是 3000ms)为代价换来的。
我们看到 Flink 的吞吐量比 Trident 高出 20 倍以上,吞吐量比 Storm 高 300 倍,在如此高吞吐情况下,Flink 还保证了计算延迟几乎为零。另外,我们还看到,Flink 规避了微批处理模型,因此 Flink 的高吞吐量并不会以牺牲延迟为代价 。 Flink 可以将 Source 节点和 Sink 节点链接 (Chain) 在一起,从而将数据在 Flink 内部传递优化为在单个 JVM 里面交换下数据记录的句柄而已。
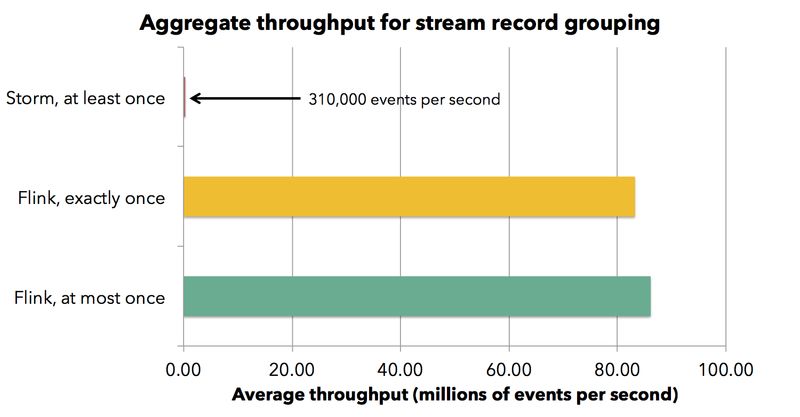
之后,我们还进行了如下实验,将计算集群核心数量从 40 个扩展到 120 个。因为 Grep 程序是一个易于并行处理的逻辑,因此所有框架处理能力理论上都能够做到线性扩展。现在让我们再做一个稍加不同的实验,它按数据业务主键执行流分组,从而实现通过网络对数据流进行混洗 (Shuffle)。同样,我们仍然在 30 台机器的集群中运行此作业,集群硬件系统配置与以前完全相同。Flink 集群的吞吐能力如下,当关闭快照检查点是每核每秒大约 720000 条记录,当打开快照检查点后降至 690000 条记录每秒。 请注意,Flink 在每个检查点均备份所有 Operator 的状态,而 Storm 则完全不支持这种功能。 此示例中的状态相对较小(状态主要是计数和摘要,每个检查点每个运算符的数量小于 1MB)。 Storm 在打开记录确认情况下,具有每核心每秒约 2600 条记录的吞吐能力。
延迟
一个大数据系统能否处理大规模数据量肯定至关重要。 但在流式处理系统中,另外一个特别重要的点在于计算延迟。 对于欺诈检测或 IT 安全等应用程序,在毫秒级别能够进行事件处理意味着可以避免业务损失,一套流式处理系统最低只能优化到 100 毫秒的延迟通常意味着前述问题只能在业务损失发生的事后才能发现,而此时的问题发现对于我们避免业务损失实际上意义已经不大了。
当应用程序开发人员评估一套流式处理系统性能延迟时,他们通常需要一个底层处理系统告之他们延迟分布情况。我们设计一个实验,测量业务主键聚合场景下作业的延迟分布情况,该作业由于存在主键聚合,因此需要流式系统内部数据跨网络混洗。下图显示了延迟分布情况,包括延迟中位数、延迟第 90% 位数、第 95% 分位数、第 99% 分位数(所谓第 99% 分位数的 50 毫秒延迟,意味着 99%的元素延迟不超过 50 毫秒)。
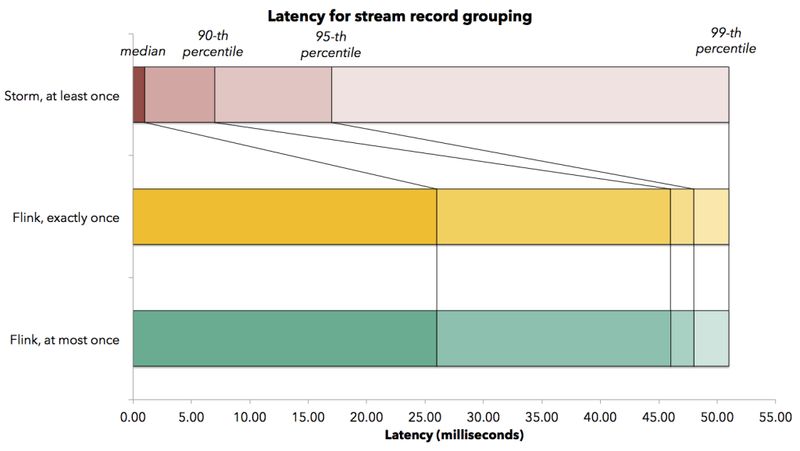
值得注意的是,Flink 在以最大吞吐量运行时,其处理中值延迟为 26 毫秒,第 99 百分位延迟为 51 毫秒,这意味着 99%的延迟都低于 51 毫秒。 当我们打开 Flink 的检查点机制(打开 exactly-once 的状态更新保证)并没有增加明显的延迟。但此时,我们确实看到处于较高百分位数的延迟增加,有观察到的延迟大约为 150 毫秒。这类情况主要原因是流在对齐所消耗的延迟,此时的 Operator 在等待接收所有输入的 Barrier(译注: 关于 Barrier 部分,请参考 https://ci.apache.org/projects/flink/flink-docs-master/internals/stream_checkpointing.html 这篇文章)。Storm 具有非常低的中值延迟(1 毫秒),并且第 99 百分位延迟也是 51 毫秒。
对于大多数应用程序而言,重要的是能够在可接受的延迟中维持较高吞吐量,延迟的具体需求取决于特定应用程序的业务要求。 在 Flink 中,用户可以使用称之为 Buffer Timeout 的机制来调整延迟。为了提高性能,Flink 的 Operator 在将数据发送到下一个 Operator 之前会将数据暂存在缓冲区。通过指定缓冲区超时时间,例如设定 10 毫秒,我们可以告诉 Flink 当面临 1) 缓冲区已满 2)10 毫秒已过 的情况下发送当前缓冲区所有的数据。 通常来说设定一个较低的缓冲区超时间将优化流式处理的延迟,但随之而来的是会降低相应的计算吞吐量。 在上面的实验中,我们将 Flink 缓冲区超时设置为 50 毫秒,这解释了为什么第 99 百分位的是 50 毫秒。
我们再进一步解释下延迟是如何影响 Flink 中的吞吐量。因为设定较低的延迟时间将不可避免地意味着缓存数据的减少,因此必然会产生一定的吞吐量成本。 下图显示了不同缓冲区超时时间设置下的 Flink 吞吐量情况。 该实验再次使用流记录分组聚合的作业。
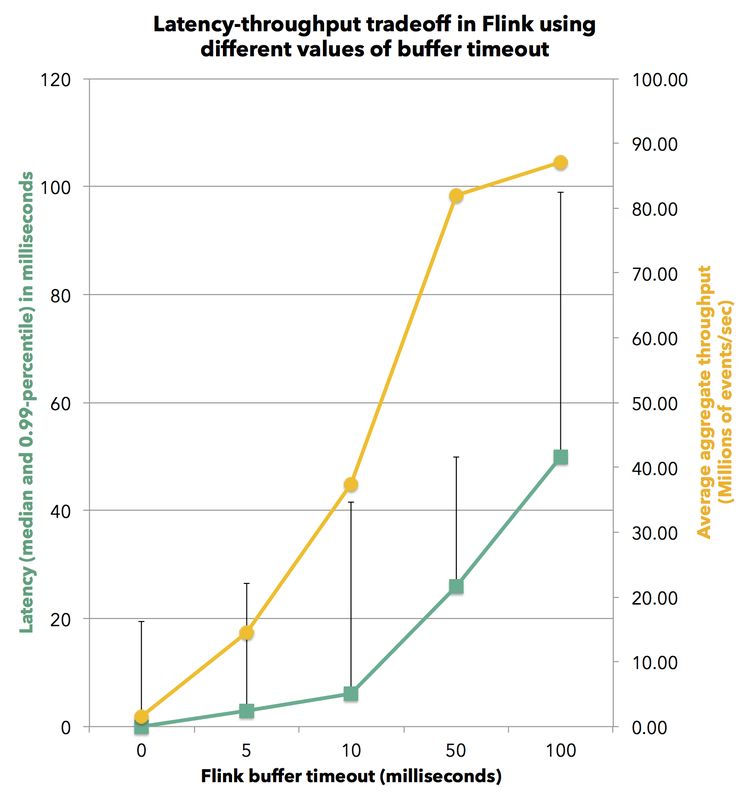
如果指定缓冲区超时时间为零,处理的记录会立即转发到下游的 Operator 而不会进行缓冲。 如此的延迟优化,Flink 可以实现 0 毫秒的中值延迟,以及 99% 延迟在 20 毫秒以下。当然,随之带来相应的吞吐量是每核每秒 24500 记录处理能力。当我们增加缓冲区超时时间,我们会看到延迟增加,吞吐量会同时增加,直到达到吞吐量峰值,缓冲区填充速度超过缓冲区超时到期时间。例如,设置 50 毫秒的缓冲区超时时间,Flink 系统将达到每核每秒 750000 条记录的峰值吞吐量,99% 的处理延迟在 50 毫秒以下。
我们的最后一个实验开始测试做快照检查点机制的正确性保证以及故障恢复的开销。我们需要运行一个需要强一致性的流式程序,并定期杀死工作节点。
这个实验的测试程序受到网络安全 / 入侵检测等用例的启发,并使用规则来检查事件序列的有效性(例如,身份验证令牌,登录,服务交互)。该程序从 Kafka 并行地读取事件流,并通过生成一些实体标识(例如,IP 地址或用户 ID)作为主键进行分组。 对于每个事件,流式处理程序会根据一些业务规则校验事件的顺序性(例如,“服务交互”必须在“登录”之前)。 对于乱序,或者说无效的事件序列,程序会发布警报。如果没有 exactly-once 的语义保证,人为制造的故障将直接产生无效的事件序列并导致程序发布错误警报。
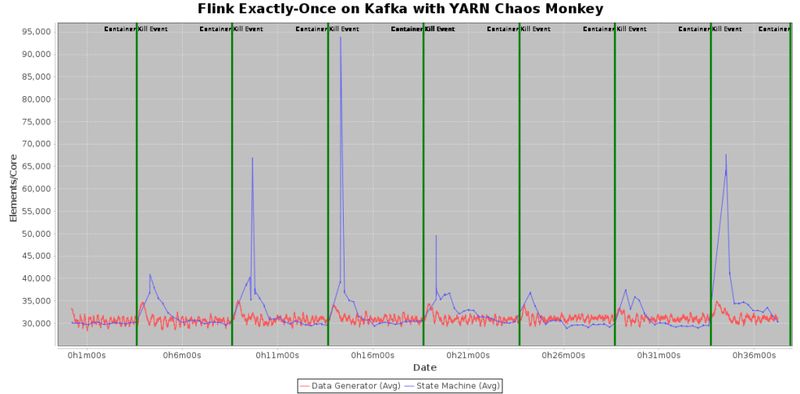
同样,我们在一个 30 节点的集群中运行这个程序,其中“YARN chaos monkey”进程每 5 分钟将随机杀死一个的 YARN 容器。 我们保留备用 worker(即 Flink 中的 TaskManagers),这样系统可以在发生故障后立即获取到新资源并运行作业,而无需等待 YARN 启动新的容器。接着,Flink 将重新启动失败的 worker 并在后台将其加入到 Flink 调度集群中,以确保备用 worker 始终可用。
为了保证能够模拟出我们期待的效果,我们开发了并发的数据生成器,这些生成器将以每核每秒 30000 的速率生成数据,并将数据推送到 Kafka。 下图显示了数据生成器的速率(红线),以及从 Kafka 读取事件并使用规则验证事件序列的 Flink 作业的吞吐量(蓝线)。
在 dataArtisans 公司,我们正在研究 Flink 流处理的几个重大功能,并希望很快将它们作为下一个 Flink 版本的一部分提供。(译注: 这篇文章写于 2015 年,因此下面作者提到的 Flink Feature 实际上已经全部实现)。
现在,Flink 的主节点(称为 JobManager)是单点故障。 我们正在引入具有备用主节点的主高可用性,该节点使用 Apache Zookeeper 进行主 / 备用协调。
我们正在向 Flink 添加按事件时间处理乱序事件的能力,即创建记录时的时间戳而不是处理时的时间戳,以及 Watermark 的引入。
我们正在开发一个完全重新设计的管理接口,该接口提供用户可以在运行时观察底层运行细节,并获取统计信息,例如累加器 (accumulators)。 如果您对此感兴趣并希望了解有关 Apache Flink™,Google Cloud Dataflow 以及其他技术和实际用例的更多信息,请注册 Flink Forward 2015。
陈守元(花名:巴真)阿里巴巴产品专家。阿里巴巴实时计算团队产品负责人,2010 年毕业即加入阿里集团参与淘宝数据平台建设,近 10 年的大数据从业经验,开源项目 Alibaba DataX 发起人,当前负责阿里实时计算产品 Flink 的规划与设计,致力于推动 Flink 成为下一代大数据处理标准。
原文链接:
https://data-artisans.com/blog/high-throughput-low-latency-and-exactly-once-stream-processing-with-apache-flink

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!



