微软发现了一个超简单的NLP上分技巧,还发了ACL2022 ??
文 | QvQ
编 | Sheryc_王苏
今天给大家介绍一篇来自工业界巨头微软的工作,这篇论文真是把资本家的嘴脸暴露的一览无余:用最低的成本,创造最高的收益(狗头.jpg)
文章从头到尾就阐述了一个结论:通过在输入文本中拼接与之最相似的已标注数据,能大幅度提升模型性能。
实验结果表明,这种简单的方法可以在各种包括摘要生成、机器翻译、语言建模和问答等任务上都有更好的表现。
论文题目:
Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data
论文链接:
https://arxiv.org/abs/2203.08773
源码:
https://github.com/microsoft/REINA
![]() 预备知识
预备知识![]()
 预备知识
预备知识在自然语言处理中,通过从大型语料库中利用检索的方法获取与输入相关的文本信息来作为补充,通常可以较为显著的提升模型性能。这是因为通过检索,模型收获了额外的与输入相关的知识。因此,基于检索的方法已成功地应用于许多任务,如开放领域问答、机器翻译等。
然而,这些方法都需要建立大规模语料库的索引,并且检索会显著地增加计算负担。例如,机器翻译的kNN-MT模型的生成速度比传统的MT模型慢两个数量级。
那么有什么既可以获取额外知识,又能高效训练的办法吗?
![]() 核心思路
核心思路![]()
对于给定输入,通过检索从语料库中收集与输入最相似的信息,然后将检索结果与输入结合,一同输入到自然语言处理模型中。
具体来说,和把大象放进冰箱的步骤数量一致,分为如下三步:
-
为语料库索引 建立键值对列表,即 ; -
给定输入 ,依据键值对 寻找与 最相似的k个键值 并取出其对应的 ; -
将检索结果 与输入 拼接并一同送入模型中进行训练。
于是乎,模型从原始输入
变化为:
其中, 为检索得到的键值对。
没了吗?
没了....
以上就是最核心的思路。但是别急,虽然这些步骤看上去只有“拼接”这一步操作与之前不同,但这个框架还没有解决所有的问题。大规模语料库的索引效率问题如何解决?如何寻找最相似的键值对?这需要对本文的细节一探究竟。
![]() 一些细节
一些细节![]()
建立索引库
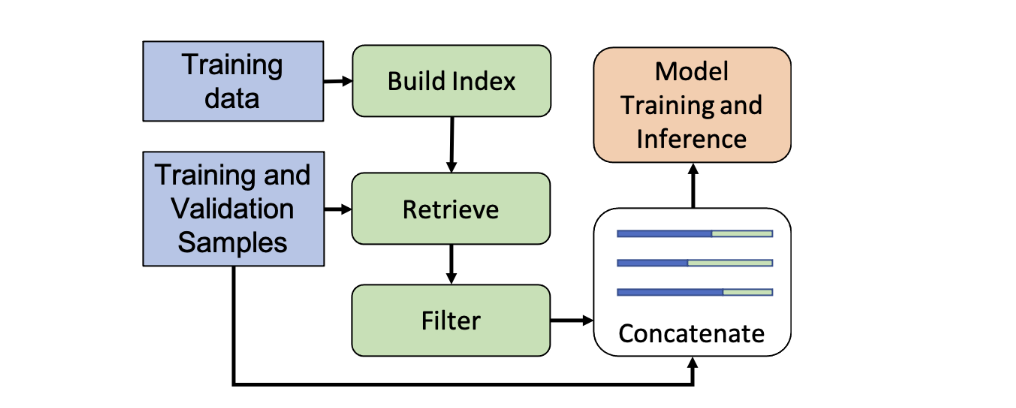
如果从大型语料库中检索的话,计算开销较大。所以,本文提出直接从有标签的训练集数据中检索,即REtrieval from traINing datA。(?,好家伙,这就是REINA的由来呗,没缩写硬凑呗?)
这里实际上就是把训练集中每一行的输入 与其对应的ground-truth label转化为 格式。训练集的规模远小于大型语料库,这就解决了索引效率问题。说了这么多,合着就一行代码搞定啊...
from collections import defaultdict :)
检索算法
对于检索,本文用BM25算法来找出与输入 最相似的 个句子。文中说主要是看上了它的检索速度之快。果然,最trick的提点的技巧,往往只需要最朴素的算法:)
KV定义 & 组合形式
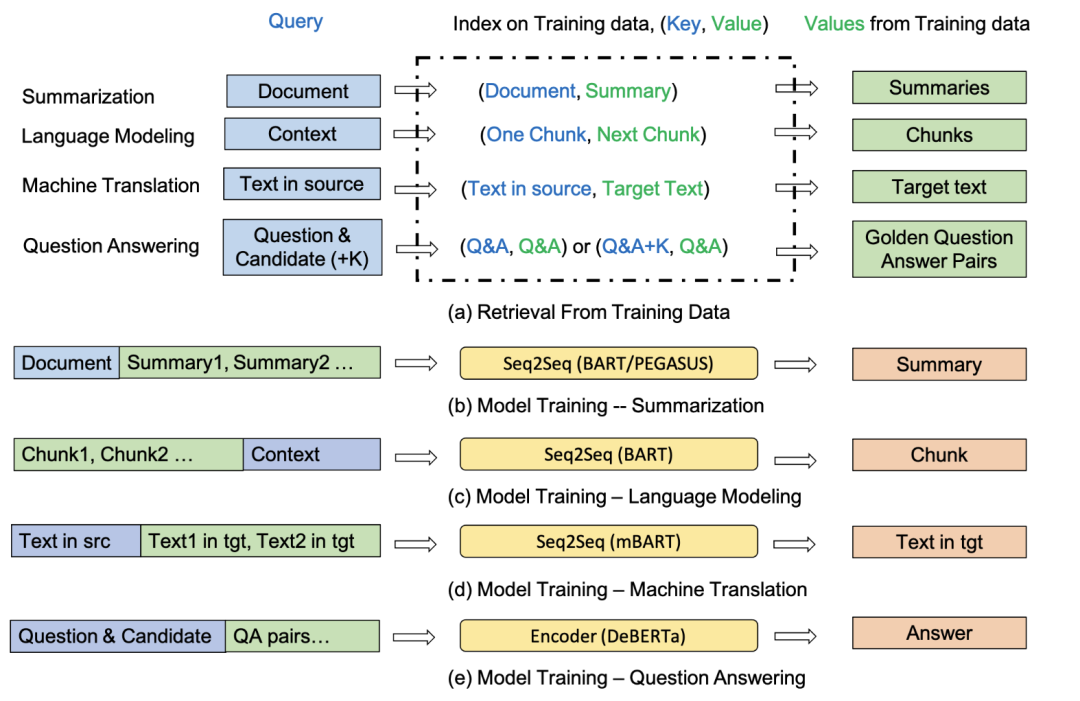
接下来的就是比较关键的步骤了。对于不同任务如何定义 对,以及检索到的 对以何种形式与 组合似乎大有说法。根据任务的不同,输入所拼接的索引内容也不尽相同:
摘要生成
摘要生成任务是为给定的文档生成摘要。
首先将训练数据转为的 对。对于给定文档 ,从训练数据中检索出与之最相似的k个文档下标,取出其对应摘要与输入 进行拼接,即:
这里没有选择拼接相似文档本身的原因显而易见:文档本身太…长…了…
语言模型
语言模型任务通常是生成给定单词/序列的概率。在本文中使用基于Seq2Seq的方法,即给定上一个文本块 ,我们预测下一个文本块 。
这里的索引是 为每一对上下文块建立索引 ,最后与输入拼接的时候同样只拼接 ,即输入为 。
机器翻译
这没什么好说的,原句与译文组成 对,最后与输入拼接的时候同样只拼接译文 ,即输入为:
问答
问答任务这里关注的是从多个选项里选择最正确答案的问答任务。
该任务中,索引是为唯一正确的答案建立kv问答对。但是与上述任务不同的是该任务将索引得到最相似的数个 对直接与输入拼接,即输入为。
训练 & 预测
训练阶段:考虑到在训练阶段BM25算法可能检索到原输入 ,所以需要过滤掉原输入 对应的 对,以防止数据泄露。
预测阶段:无需过滤。
![]() 实验
实验![]()
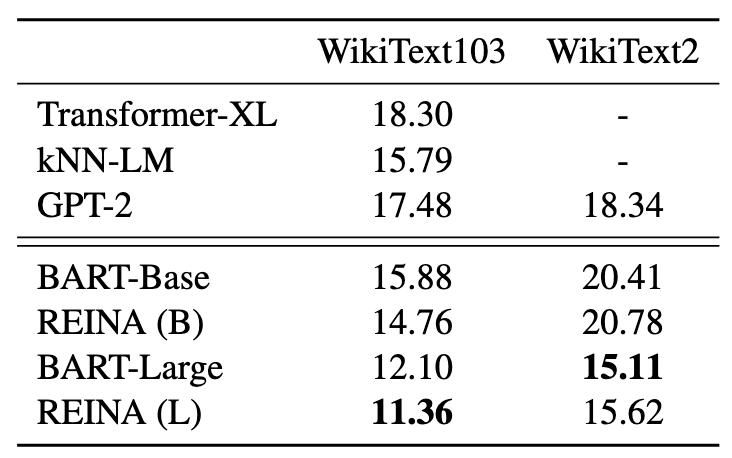
Summarization
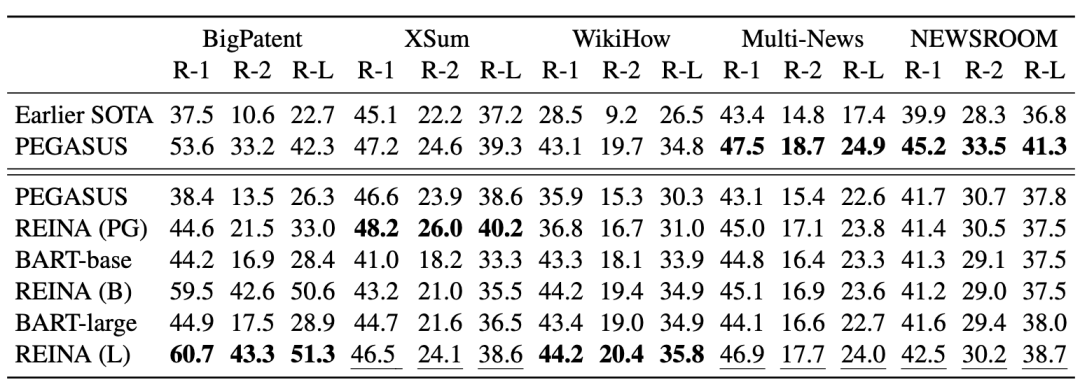
Language Modeling
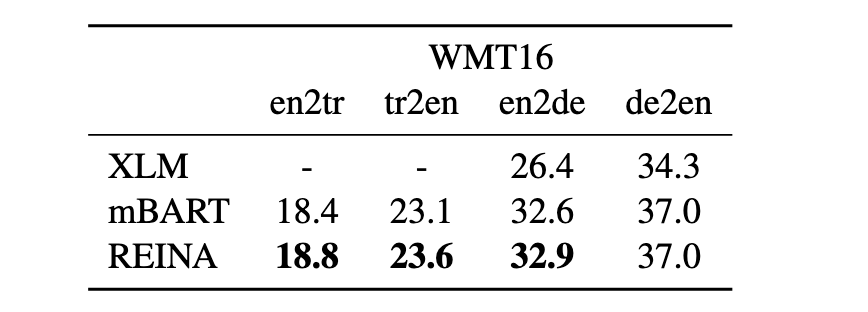
Machine translation
Question answering
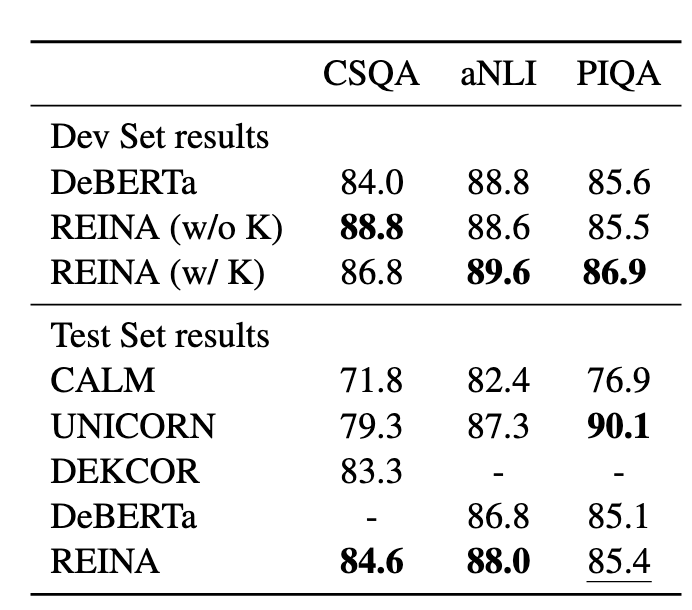
可以看到,REINA在多个任务的多个数据集上都取得不错的提升,有效的证明了该方法虽然简单但还是非常work的~
![]() 小编锐评
小编锐评![]()
本文算是一篇数据增强方面的工作,其原理也比较容易理解:即使有数亿个参数,模型也不能记住训练数据中的所有范式。因此,提取相关训练数据作为输入,可以显式地提供所需的一些候补信息,以提高模型的推理性能。可以预见到该方法同样试用于few-shot learning。
说句题外话,这种思路应该早在10年前就在工业界中应用了,与搜索中click-query真是如出一辙...
这种浓浓工业界文风的文章,有时候很容易让人“失望”。要么大力出奇迹,要么简单到“可耻”却有用!但是不得不说,这种提点的trick你难道不想在工作中一试吗?
不说了,我先去了~
萌屋作者:乐乐QvQ。
硕士毕业于中国科学院大学,前ACM校队队长,区域赛金牌。竞赛混子,Kaggle两金一银,国内外各大NLP、大数据竞赛Top10。校招拿下国内外数十家大厂offer,超过半数的SSP。目前在百度大搜担任搜索算法工程师。知乎ID:QvQ
作品推荐:
 萌屋作者:乐乐QvQ。
萌屋作者:乐乐QvQ。
后台回复关键词【入群】
加入卖萌屋NLP、CV与搜推广求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【

