迁移学习理论与实践
↑ 点击蓝字 关注极市平台

极市导读
随着越来越多的机器学习应用场景的出现,而现有表现比较好的监督学习需要大量的标注数据,标注数据是一项枯燥无味且花费巨大的任务,所以迁移学习受到越来越多的关注。本文阐述了迁移学习的理论知识、基于ResNet的迁移学习实验以及基于resnet50的迁移学习模型。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
迁移学习:深度学习未来五年的驱动力?

迁移学习的使用场景
深度卷积网络的可迁移性

迁移学习的使用方法
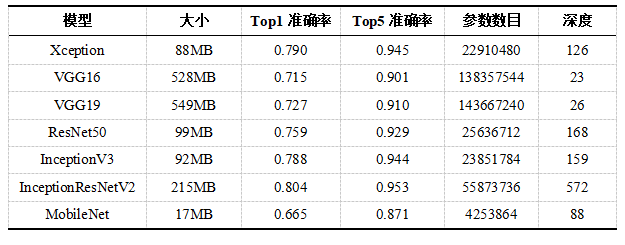
基于ResNet的迁移学习实验
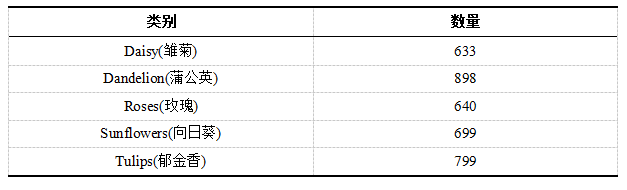
# 导入相关模块
import os
import pandas as pd
import numpy as np
import cv2
import matplotlib.pyplot as plt
from PIL import Image
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import keras
from keras.models import Model
from keras.layers import Dense, Activation, Flatten, Dropout
from keras.utils import np_utils
from keras.applications.resnet50 import ResNet50
from tqdm import tqdm
提取数据标签
def generate_csv(path):
labels = pd.DataFrame()
# 目录下每一类别文件夹
items = [f for f in os.listdir(path)]
# 遍历每一类别文件夹
for i in tqdm(items):
# 生成图片完整路径
images = [path + I + '/' + img for img in os.listdir(path+i)]
# 生成两列:图像路径和对应标签
labels_data = pd.DataFrame({'images': images, ‘labels’: i})
# 逐条记录合并
labels = pd.concat((labels, labels_data))
# 打乱顺序
labels = labels.sample(frac=1, random_state=42)
return labels
# 生成标签并查看前5行
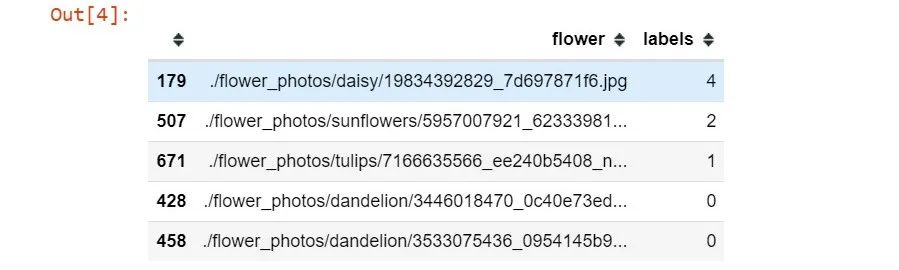
labels = generate_csv('./flowers/')
labels.head()
图片预处理

# resize缩放
img = cv2.resize(img, (224, 224))
# 转换成RGB色彩显示
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.xticks([])
plt.yticks([])
 图9.6 缩放后的效果
图9.6 缩放后的效果
# 定义批量读取并缩放
def read_images(df, resize_dim):
total = 0
images_array = []
# 遍历标签文件中的图像路径
for i in tqdm(df.images):
# 读取并resize
img = cv2.imread(i)
img_resized = cv2.resize(img, resize_dim)
total += 1
# 存入图像数组中
images_array.append(img_resized)
'iamges have resized.')
return images_array
# 批量读取
images_array = read_images(labels, (224, 224))
准备数据
# 转化为图像数组
X = np.array(images_array)
# 标签编码
lbl = LabelEncoder().fit(list(labels['labels'].values))
labels['code_labels']=pd.DataFrame(lbl.transform(list(labels['labels'].values)))
# 分类标签转换
y = np_utils.to_categorical(labels.code_labels.values, 5)
# 划分为训练和验证集
X_train, X_valid, y_train, y_valid =
train_test_split(X,y,test_size=0.2, random_state=42)
# 训练集生成器,中间做一些数据增强
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.4,
height_shift_range=0.4,
shear_range=0.2,
zoom_range=0.3,
horizontal_flip=True
)
# 验证集生成器,无需做数据增强
val_datagen = ImageDataGenerator(
rescale=1./255
)
# 按批次导入训练数据
train_generator = train_datagen.flow(
X_train,
y_train,
batch_size=32
)
# 按批次导入验证数据
val_generator = val_datagen.flow(
X_valid,
y_valid,
batch_size=32
)
基于resnet50的迁移学习模型
# 定义模型构建函数
def flower_model():
base_model=ResNet50(include_top=False,weights='imagenet', input_shape=(224, 224, 3))
# 冻结base_model的层,不参与训练
for layers in base_model.layers:
layers.trainable = False
# base_model的输出并展平
model = Flatten()(base_model.output)
# 添加批归一化层
model = BatchNormalization()(model)
# 全连接层
model=Dense(2048,activation='relu', kernel_initializer=he_normal(seed=42))(model)
# 添加批归一化层
model = BatchNormalization()(model)
# 全连接层
model=Dense(1024,activation='relu', kernel_initializer=he_normal(seed=42))(model)
# 添加批归一化层
model = BatchNormalization()(model)
# 全连接层并指定分类数和softmax激活函数
model = Dense(5, activation='softmax')(model)
model = Model(inputs=base_model.input, outputs=model)
# 指定损失函数、优化器、性能度量标准并编译
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# 调用模型
model = flower_model()
# 使用fit_generator方法执行训练
flower_model.fit_generator(
generator=train_generator,
steps_per_epoch=len(train_data)/32,
epochs=30,
validation_steps=len(val_data)/32,
validation_data=val_generator,
verbose=2
)

推荐阅读




登录查看更多
相关内容

迁移学习(Transfer Learning)是一种机器学习方法,是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。迁移学习(TL)是机器学习(ML)中的一个研究问题,着重于存储在解决一个问题时获得的知识并将其应用于另一个但相关的问题。例如,在学习识别汽车时获得的知识可以在尝试识别卡车时应用。尽管这两个领域之间的正式联系是有限的,但这一领域的研究与心理学文献关于学习转移的悠久历史有关。从实践的角度来看,为学习新任务而重用或转移先前学习的任务中的信息可能会显着提高强化学习代理的样本效率。
专知会员服务
134+阅读 · 2020年7月10日
Arxiv
0+阅读 · 2021年1月29日
相关VIP内容
专知会员服务
134+阅读 · 2020年7月10日
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月29日