从词嵌入到含义嵌入:概览含义向量表示方法
词嵌入方法在众多自然语言处理任务中得到了广泛的应用。然而,词嵌入方法将多义词合并为单一表示,因此并不精确。为了更好地区分同一单词的不同含义,人们转而提出了含义嵌入(sense embeddings)。卡迪夫大学的Jose Camacho-Collados和剑桥大学的Mohammad Taher Pilehvar最近发表了论文(arXiv:1805.04032v2),概览了含义向量表示的主要方法。
意义合并缺陷
词嵌入方法的主要缺陷是无法很好地处理多义词。由于在词嵌入方法中,每个单词表示为语义空间中的一个向量,因此它将多义词的不同义项合并为单一表示,这就导致了意义合并缺陷(meaning conflation deficiency):
词嵌入无法有效捕捉同一单词的不同义项,即使这些义项都在训练语料中出现过。
语义上无关的单词,被多义词拉扯到一起(见下图)。
合并缺陷违反了欧几里得空间的三角不等性,削弱了单词空间模型的有效性。
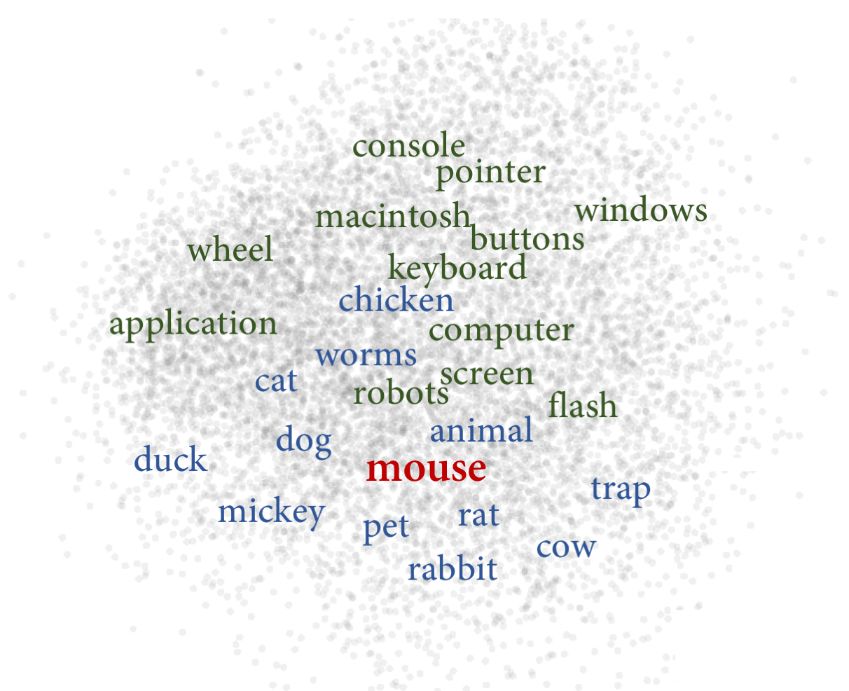
语义上无关的rabbit(兔)和computer(计算机)因mouse(老鼠/鼠标)牵扯到一起
因此,人们开始寻找直接建模词义的方法。最早的建模方法,依赖于人工编制的意义清单(例如WordNet)。近年来,通过分析文本语料推导词义差别的无监督表示模型渐渐流行。下面我们将分别介绍这两种范式。
基于知识的语义表示
这一范式利用外部资源中的知识建模语义。首先,我们将概览主要的外部资源。接着,我们将简要介绍一些使用外部资源改进词向量的方法。最后我们重点介绍构建基于知识的含义表示的方法。
知识资源
WordNet是NLP和语义表示学习中使用最为广泛的资源之一。WordNet可以看成一个语义网络。其中的节点为synset(同义词集),例如,表示“脊柱”这一概念的synset包括spinal column、vertebral column、spine、backbone、back、rachis六个词汇。synset之间的联系(例如上位关系和部分整体关系)则为节点的边。Open Multilingual Wordnet等项目则致力于将WordNet扩展到其他语言。
Wikipedia(维基百科)是最著名的协同构建资源。它是世界上最大的多语言百科,支持超过250种语言。而且,它还在持续更新之中,例如,英语维基百科每天新增将近750篇新文章。另外,Wikimedia基金会还运营Wikidata项目,一个面向文档的语义数据库,为维基百科和其他wikimedia项目提供共享数据。类似的项目有DBpedia,致力于结构化维基百科的内容。
BabelNet将WordNet连接到包括维基百科在内的协作构建的资源。BabelNet的结构和WordNet类似,只不过synset包含多个语种。synset间的联系来自WordNet及其他资源(例如维基百科的超链接和Wikidata)。
ConceptNet结合了WordNet、Wiktionary、DBpedia等资源的语义信息。和WordNet、BabelNet不同,ConceptNet的主要语义单元是词汇而不是synset。
PPDB(Paraphrase Database)基于图结构,以词组为节点,以词组间的相互关系为边。
知识增强词向量方法
知识增强词表示(knowledge-enhanced word representation)利用知识资源改进现有的词向量表示,加上文本语料中未包含的信息。
知识增强词表示,主要有两种思路,一为修改模型的目标函数,以便在学习过程中纳入知识资源的信息,一为在后处理阶段改进预训练的词嵌入。
后者通常称为retrofitting(改装)。其直觉为,在词向量空间中,移动知识资源中联系密切的单词对应的向量表示,使其更为接近。retrofitting模型的主要目标函数为最小化下式:
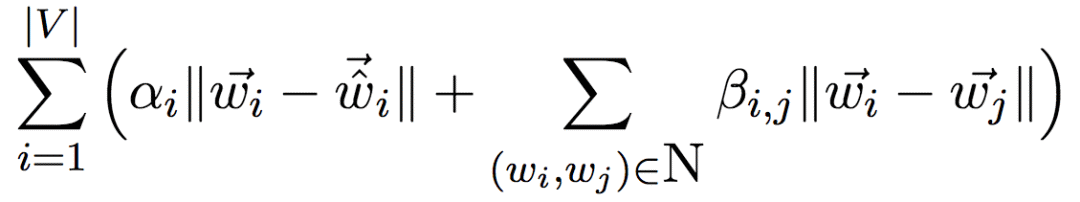
上式中,|V|表示词汇量,N是给定的语义网络(知识资源),语义网络的形式为单词对的集合,wi和wj为预训练模型的词嵌入,戴帽wi为输出词嵌入,αi、βi,j为可调整的控制系数。
基于知识的含义表示
基于知识的含义表示(knowledge-based sense representations)的基本思路是利用知识资源的信息拆分(de-conflating)词表示为含义表示。
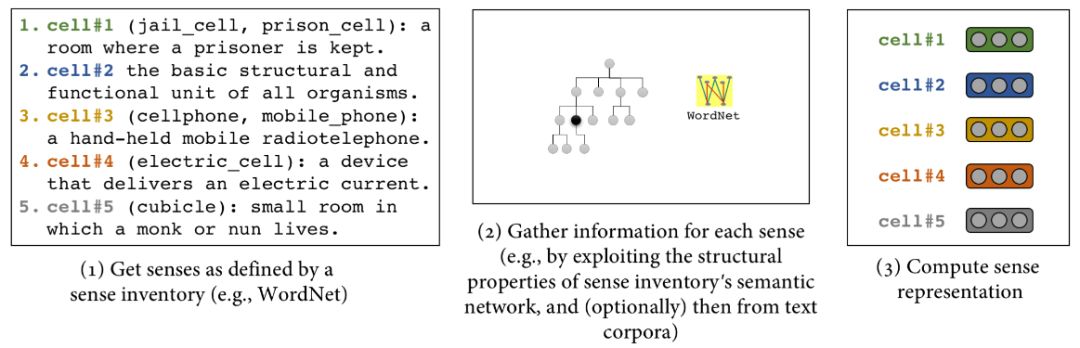
知识资源的信息主要有两种表示形式,文本定义和语义网络。
在很多方法中,文本定义作为初始化含义表示的主要信号使用。例如,根据文本定义,对含义相近的预训练词嵌入取均值,作为初始化含义嵌入(Chen等,2014,A Unified Model for Word Sense Representation and Disambiguation)。再如,基于文本定义,利用卷积神经网络架构初始化含义嵌入(aclweb/P15-2003)。
和之前知识增强词向量方法类似,基于语义网络,通过修改目标函数或后处理词嵌入,可以从词嵌入拆分出含义嵌入。
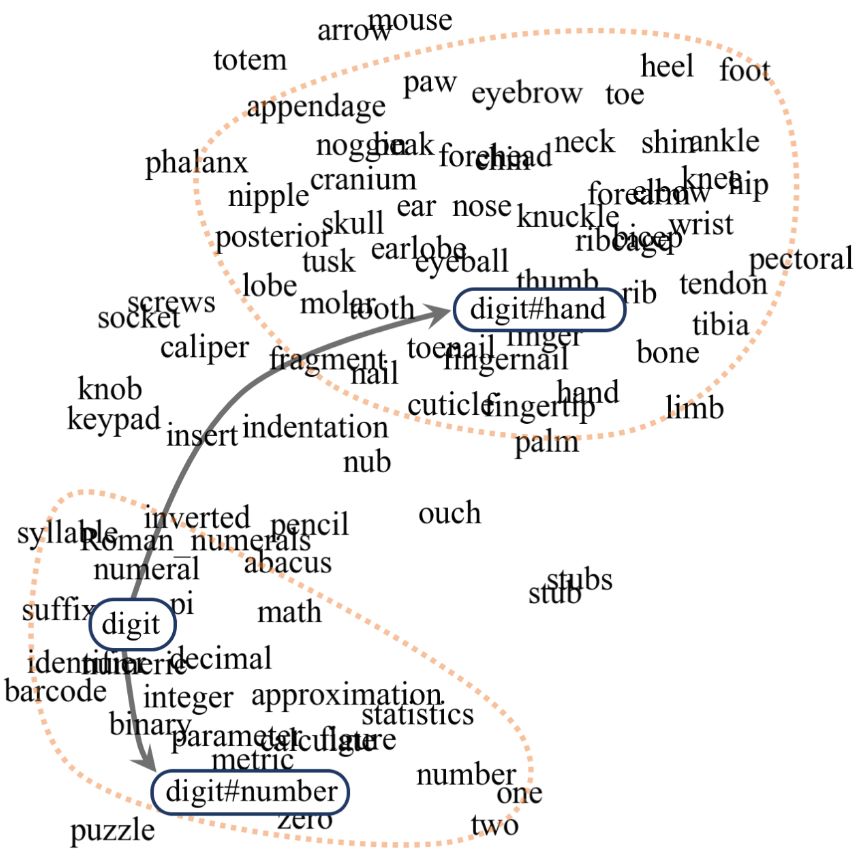
digit既可以指手指(digit#hand),也可以指数字(digit#number)
前者的例子有Mancini等在2016年底的工作(arXiv:1612.02703),修改了Word2Vec的目标函数,在同一向量空间中同时学习词嵌入和含义嵌入。
后者的例子包括:
Jauhar等在2015年对retrofitting方法的扩展(Ontologically Grounded Multi-sense Representation Learning for Semantic Vector Space Models)
Johansson和Pina在2015年提出,后处理预训练词嵌入可以看起一个优化问题:多义词嵌入可以分解为其含义嵌入的组合,同时含义嵌入应该靠近其语义网络中的邻居。(aclweb/N15-1164)他们使用了SALDO语义网络(一个瑞典语语义网络),不过他们的方法可以直接扩展到其他语义网络。
Rothe和Schütze在2015年提出的AutoExtend,一个自动编码器架构,该架构主要基于以下两个限制:词向量对应于其含义向量之和,synset向量对应于其词汇/含义之和。例如,词向量digit对应于digit(手指)和digit(数字)两个含义向量之和,synset向量“预订”对应于含义向量reserve、hold、book之和。即:
其中,s表示含义,w表示词,y表示synset。
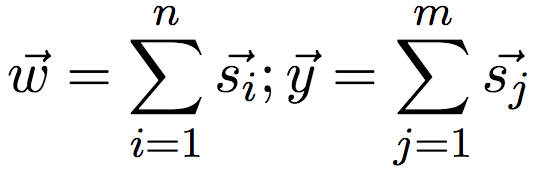
无监督含义表示
基于知识的含义表示依赖人工编制的意义清单,因此在某些场景下受到限制,例如,语料缺乏相应的外部知识资源。近年来,随着算力的提升和机器学习技术的发展,无监督含义表示渐渐流行。
无监督含义表示方法的核心是词义推导,也就是基于文本语料自动识别单词的可能含义。其背后的直觉为,既然我们可以通过上下文学习单词的表示,那么我们同样可以通过上下文学习单词的不同含义。
这一方向早期的工作是双阶段模型(two-stage model),即首先推导出含义,然后学习其表示。
双阶段模型
这方面的先锋之一是Schütze在1998提出的上下文分组识别(context-group discrimination)。其基本的思路是,聚类多义词出现的上下文,然后基于上下文相似性自动推断其含义。(aclweb/J98-1004)

后续这个方向的研究大多沿袭Schütze这一工作的思路,只不过改变了上下文表示形式和聚类算法(Schütze使用了最大期望算法)。
2010年,Reisinger和Moone直接聚类上下文,也就是将上下文表示为一元语法的特征向量,而不是词向量,大大降低了计算负担,使这一基于聚类的方法能够用于较大的语料。另外,他们还使用了movMF聚类算法,这是一种和k-均值类似的算法,不过它允许使用聚类特定的聚集参数控制语义的广度,以更好地建模聚类尺寸的偏斜分布。(dl.acm/1858012)
类似地,Huang等在2012年改进了基于聚类的含义表示技术,通过idf加权平均词向量得到上下文向量,并使用球形k均值聚类。然后根据聚类标注单词的用例,并基于此学习含义表示。(aclweb/P12-1092)
双阶段模型的问题在于,聚类和含义表示学习均基于上下文,这两者有潜在的相似性,分两个阶段单独进行浪费了这一潜在的相似性,也浪费了算力。因此,最近的研究大部分转向了联合训练(joint training),即同时进行推断和表示学习。
联合模型
Neelakantan等在2014年提出了MSSG(Multiple-Sense Skip-Gram)模型,扩展了Skip-gram嵌入模型。和前面提到的工作类似,MSSG也通过聚类形成单词的含义表示。不过,聚类和含义表示学习是同时进行的。在训练阶段,每个单词的预期含义是动态选择的,选择和上下文最接近的含义。与此同时,Tian等在2014年提出了一个基于Skip-gram的含义表示技术,将Skip-gram模型中的词嵌入替换为有限混合模型,其中每个模型对应单词的一个原型(prototype)。(aclweb/C14-1016)
Yang Liu等主张上面的技术在推断含义表示时仅仅使用了单词的局部上下文,因此是有局限的。为了应对这一问题,他们在2015年提出了TWE模型(Topical Word Embeddings)。其中,每个单词在不同主题下可能有不同的词嵌入,主题则通过基于全局计算的潜主题建模。Pengfei Liu等提出的NTSG模型( Neural Tensor Skip-gram)应用了同样的想法,只不过引入了张量以更好地学习单词和主题之间的关系。Nguyen等在2017年提出了TWE的一个扩展,MSWE模型,TWE在给定上下文中会选取最合适的含义,而MSWE则使用权重混合表示给定上下文中单词和不同含义的关联程度。
出于实现的简单性,联合模型往往假定每个单词有固定数目的含义(使用启发式算法猜测数目)。然而这一假定和实际情况并不相符,单词的含义数量可能差别很大。虽然在WordNet 3.0中,大约80%的单词为单义词,不到5%的单词有3个以上含义。然而,如果我们重点关注常用词,则情况大不相同。常用词大都是多义词,而且其含义数量分布比较分散。

SemCor数据集中常用词的含义数量分布
之前提到的MSSG模型考虑了这一点,使用的是一种实时非参数聚类算法,对某个单词而言,仅仅在与现有含义的相似性低于某个阈值时才创建新含义。Bartunov等在2015年提出的AdaGram模型(Adaptive Skip-gram,自适应Skip-gram模型),则基于非参数贝叶斯方法实现了动态多义(dynamic polysemy)。
另外,以上的联合模型都有一个缺陷,推断含义所用的上下文仍然为可能有歧义的词向量,而不是含义向量。换句话说,这些联合模型都不是纯粹的基于含义的模型。
有鉴于此,Qiu等在2016年提出了一个纯含义模型(aclweb/D16-1018),同时,这一模型也将去歧义上下文从之前的小窗口扩展至整个句子。Lee和Chen在2017年提出的MUSE模型则是另一个Skip-gram的纯含义扩展,MUSE使用了强化学习方法。
多语语料
由于歧义通常并不跨语言,比如中文分别使用“老鼠”和“鼠标”,没有英文中mouse的歧义问题。因此我们可以利用多语语料对单词的翻译进行聚类,然后基于翻译聚类构建含义嵌入表示。这一方法在机器翻译(Machine Translation)领域尤为常用。
与下游应用的集成
文本的表示通常只是第一步,要完成NLP任务,通常还需要后续处理。目前而言,词嵌入可以很方便地集成到下游应用中,而含义嵌入在这方面还处于婴儿期。
Pilehvar等在2017年的研究(aclweb/E17-2062)表明,当输入文本足够庞大的时候,基于知识的含义嵌入能够提升文本分类的效果,但在大多数数据集上,使用预训练的含义嵌入相比词嵌入,表现没有明显的提升。
2015年,Li和Jurafsky提出了一个框架(arXiv:1506.01070),可以将无监督含义嵌入集成到多项自然语言处理任务中。然而,他们发现无监督含义嵌入并没有显著优势,增加词嵌入的维度可以取得相近的效果。
2018年,Peters等提出了学习深度双向语言模型(LSTM)的内部状态所得的词向量。(arXiv:1802.05365)他们发现,这一上下文词表示(contextualized word representations)可以很容易地加入现有的模型,并显著提升问答(question answering)、文本蕴涵(textual entailment)、情感分析(sentiment analysis)等6个NLP问题上当前最先进模型的表现。
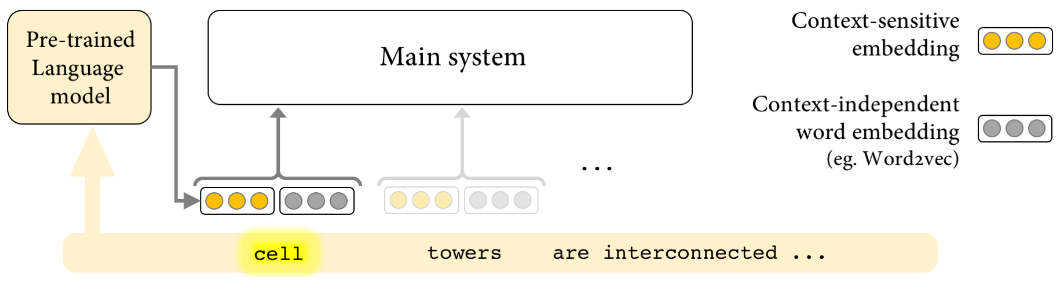
黄色表示上下文敏感嵌入,灰色表示上下文无关嵌入
和(上下文无关)词嵌入不同,上下文词表示是动态的,其表示因所出现的上下文环境的不同而不同。上下文词表示的直觉是,语言模型单元隐式地根据上下文区分了多义词的具体含义。
结语
本文概览了直接基于文本语料推断含义(无监督)及使用外部含义清单(基于知识)的含义表示模型。其中一些模型已经在实践中取得了不错的效果,但含义表示模型仍有很大的提升空间。例如,大部分模型只在英语语料上测试过,只有少数模型涉及英语以外的语料。再如,含义表示模型集成到下游应用的最佳策略尚不明确,同时预先去歧义是否必要也不确定。
含义的定义和正确的范式仍然是一个开放问题。含义需要是离散的吗?含义需要依赖知识资源或含义清单吗?含义可以根据上下文动态学习吗?这些问题仍有待探索。
原文地址:https://arxiv.org/abs/1805.04032




