推出一个半月,斯坦福SQuAD问答榜单前六名都在使用BERT
机器之心报道
作者:李亚洲、李泽南
BERT 成为了你做 NLP 时不得不用的模型了……吗?
今日,机器之心小编在刷 Twitter 时,发现斯坦福自然语言处理组的官方账号发布了一条内容:谷歌 AI 的 BERT 在 SQuAD 2.0 问答数据集上取得了全新的表现。该账号表示,目前榜单上的前 7 个系统都在使用 BERT 且要比不使用 BERT 的系统新能高出 2%。得分等同于 2017 年 SQuAD 1.0 版本时的得分。此外,哈工大讯飞联合实验室的 AoA 系统要比原 BERT 高出 2% 左右。

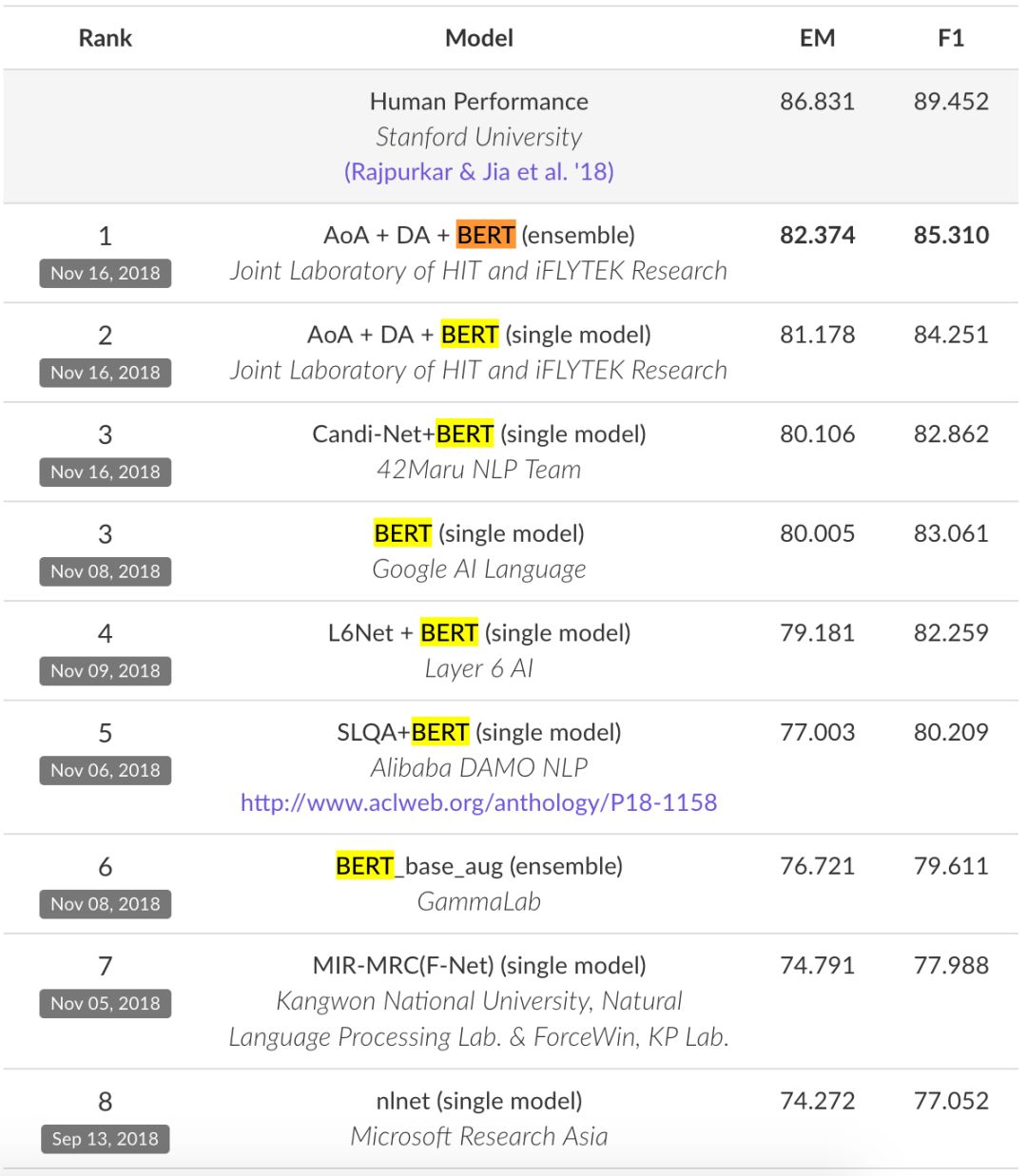
然后小编就从 SQuAD 2.0 榜单上发现了前六名的系统:
哈工大讯飞联合实验室的 AoA+DA+BERT(集成)系统;
AoA+DA+BERT(单模型)系统;
韩国创业公司 42Maru NLP 团队的 Candi-Net+BERT(单模型)系统;
谷歌 AI 的 BERT(单模型)系统;
Layer 6 AI 的 L6Net+BERT(单模型)系统;
阿里巴巴达摩院 NLP 团队的 SLQA+BERT(单模型)系统;
金融壹账通 Gamma 实验室 BERT_base_aug(集成模型)。
如今牢牢占据前几名的系统几乎都在使用 BERT,让我们不得不感叹 BERT 的影响力之大。但同时也想知道使用 BERT 时付出的计算力,毕竟 BERT 的作者在 Reddit 上也曾表示预训练的计算量非常大,「OpenAI 的 Transformer 有 12 层、768 个隐藏单元,他们使用 8 块 P100 在 8 亿词量的数据集上训练 40 个 Epoch 需要一个月,而 BERT-Large 模型有 24 层、2014 个隐藏单元,它们在有 33 亿词量的数据集上需要训练 40 个 Epoch,因此在 8 块 P100 上可能需要 1 年?16 Cloud TPU 已经是非常大的计算力了。」
为什么人们拿来 BERT 都在刷 SQuAD?
斯坦福问答数据集(SQuAD)是目前机器阅读领域的重要基准,是由众多数据标注者从维基百科文章中提取问题形成的。回答这些问题可能需要引用相关段落中的一部分,也有一些问题是无法回答的。
2018 年 6 月,斯坦福大学推出了 SQuAD 2.0 版本。新版本在 SQuAD 1.1 版 10 万个问题的基础上又加入了 5 万个新问题,新加入的内容均为与数据标注者提出的可回答问题类似的不可回答问题。想要在 SQuAD 上取得好成绩,人工智能系统必须在可行的条件下回答问题,并在确定段落内容无法支持问题时选择不回答。对于现有模型来说,SQuAD2.0 是一项具有挑战性的自然语言理解任务。
如此难的基准测试,看来需要更强大的模型才能通关,而 BERT 貌似成为了当前最好的选择。让我们看看 BERT 的论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》是怎么写的:

BERT 是一种新型语言表征模型,意为来自 Transformer 的双向编码器表征(Bidirectional Encoder Representations from Transformers)。与此前的语言表征模型(Peters et al., 2018; Radford et al., 2018)不同,BERT 旨在基于所有层的左、右语境来预训练深度双向表征。因此,预训练的 BERT 表征可以仅用一个额外的输出层进行微调,进而为很多任务(如问答和语言推断任务)创建当前最优模型,无需对任务特定架构做出大量修改。
BERT 的概念很简单,但实验效果很强大。它刷新了 11 个 NLP 任务的当前最优结果,包括将 GLUE 基准提升至 80.4%(7.6% 的绝对改进)、将 MultiNLI 的准确率提高到 86.7%(5.6% 的绝对改进),以及将 SQuAD v1.1 的问答测试 F1 得分提高至 93.2 分(提高 1.5 分)——比人类表现还高出 2 分。
我们只需要一个额外的输出层来对预训练 BERT 进行微调就可以用它来满足各种任务,无需针对特定任务对模型进行修改,这就是 BERT 模型能在大量 NLP 任务上取得突破的原因。

拓展阅读:
BERT 论文:https://arxiv.org/pdf/1810.04805.pdf
每日精选教程,扫码开启订阅,每天18:00及时速递。





