谷歌大作:自动改良反向传播算法,训练速度再提升!
点击上方“公众号”可以订阅哦!

来源:新智元
编辑:肖琴、三石
【导读】大神 Geffery Hinton 是反向传播算法的发明者,但他也对反向传播表示怀疑,认为反向传播显然不是大脑运作的方式,为了推动技术进步,必须要有全新的方法被发明出来。今天介绍的谷歌大脑多名研究人员发表的最新论文Backprop Evolution,提出一种自动发现反向传播方程新变体的方法,该方法发现了一些新的方程,训练速度比标准的反向传播更快,训练时间也更短。
论文地址:
https://arxiv.org/pdf/1808.02822.pdf
大神 Geoffrey Hinton提出的反向传播算法是深度学习的基石。
1986 年,Geoffrey Hinton 与人合著了一篇论文:Learning representations by back-propagation errors,30 年之后,反向传播算法成了这一波人工智能爆炸的核心。
但去年,Hinton 在接受采访时表示,他对反向传播算法 “深感怀疑”,认为应该彻底抛弃反向传播,另起炉灶。Hinton 认为,反向传播不是大脑运作的方式,我们的大脑显然不需要对所有数据进行标注。为了推动进步,必须要有全新的方法被发明出来。
尽管Hinton、以及无数研究者仍未提出全新的、能够代替传播的方法,但最近机器学习自动搜索方法取得很多成功,反向传播算法的变体也得到越来越多的研究。
柏林工业大学、谷歌大脑的多名研究人员在最新发表的论文 Backprop Evolution,提出一种自动发现反向传播方程新变体的方法。研究人员使用领域特定语言将更新的方程描述为原函数列表。

具体来说,研究人员采用一种基于进化的方法来发现新的传播规则,这些规则在几个epoch的训练之后可以最大限度地提高其泛化表现。他们发现了一些新的方程,它们的训练速度比标准的反向传播更快,训练时间更短,并且在收敛时类似标准反向传播。
反向传播算法是机器学习中最重要的算法之一。已有研究对反向传播方程的变体进行了一些尝试,并取得一定程度的成功 (e.g., Bengio et al. (1994); Lillicrap et al. (2014); Lee et al. (2015); Nøkland (2016); Liao et al. (2016))。但尽管有这些尝试,反向传播方程的修改并没有得到广泛应用,因为这些修改很少对实际应用有改进,甚至有时会造成损害。
受近期机器学习自动搜索方法取得成功的启发,我们提出一种自动生成反向传播方程的方法。
为此,我们提出一种领域特定语言(domain specific language),以将这些数学公式描述为原始函数列表,并使用一种基于进化(evolution-based)的方法来发现新的传播规则。在经过几个epoch的训练后,搜索条件是使 generalization 最大化。我们找到了和标准反向传播效果同样好的几个变体方程。此外,在较短的训练时间内,这几种变体可以提高准确率。这可以用来改进 Hyperband 之类的算法,在训练过程中做出基于准确性的决策。
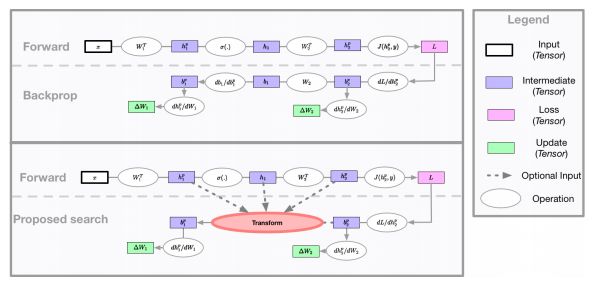
图1:神经网络可以看作是一些计算图。前向图(forward graph)由网络设计者定义,而反向传播算法隐式地为参数更新定义了一个计算图。本研究的主要贡献是探索如何利用evolution来找到一个比标准反向传播更有效的参数更新计算图。

其中,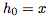
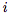
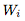
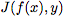
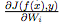
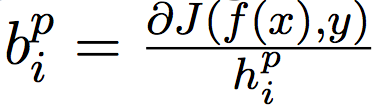
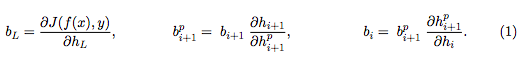
一旦计算出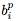
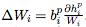
如图1所示,神经网络可以表示为前向和后向的计算图。给定一个由网络设计者定义的前向计算图,反向传播算法定义了一个用于更新参数的反向计算图。但是,有可能找到一个改进的反向计算图,从而得到更好的泛化。
最近,用于机器学习的自动搜索方法已经在各种任务上取得了很好的结果,这些方法涉及修改前向计算图,依靠反向传播来定义适当的反向图。与之不同,在这项工作中,我们关注的是修改反向计算图,并使用搜索方法为
为了找到改进的更新规则,我们使用进化算法来搜索可能的更新方程(update equation)的空间。在每次迭代中,进化控制器将一批突变的更新方程发送给workers池进行评估。每个worker使用其接收到的变异方程来训练一个固定的神经网络结构,并将获得的验证精度报告给控制器。
搜索空间
受到Bello et al. (2017) 的启发,我们使用领域特定语言(domain-specific language,DSL)来描述用于计算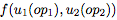
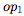
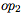
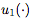
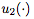
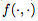
操作数(Operands):W(当前层的权重矩阵),
(高斯矩阵),
(从
到
的高斯随机矩阵映射),
(前向传播的隐藏激活),
(反向传播的值)。
一元函数
二元函数
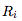
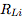
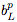
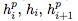
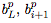
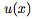
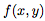
其中,
结果得到的量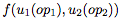
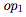
进化控制器(evolutionary controller)维护一组已发现的方程。在每次迭代中,控制器执行以下操作之一:1)概率为p的情况下,控制器在搜索期间找到的N个最优竞争力的方程中随机选择一个方程,2)概率为1 - p时,控制器从population的其他方程中随机选择一个方程。
控制器随后将k个突变(mutation)应用于所选方程,其中k是从分类分布中提取的。这k个突变中的每一个只是简单地选择一个随机一致的方程组件(例如,一个操作数,一个一元函数,或者一个二元函数),然后将它与另一个随机选择的同类组件交换。某些突变会导致数学上不可行的方程,在这种情况下,控制器会重新启动突变过程,直到成功。N、p和k的分类分布是算法的超参数。
为了创建初始 population,我们简单地从搜索空间中随机抽样N个方程。此外,在我们的一些实验中,我们从一小部分预定义的方程开始(通常是正常的反向传播方程或其反馈对齐方程变体)。从现有方程出发的能力是基于强化学习的进化方法具有的优势。
在该方法中,用于评估每个新方程的模型的选择是一个重要的设置。规模更大、更深的网络会更真实,但需要更长的时间来训练,而较小的模型训练更快,但可能导致更新网络无法推广。我们通过使用Wide ResNets (WRN) 来平衡这两个标准,其中WRN有16层,宽度multiplier为2,并且在CIFAR-10数据集中进行训练。
基线搜索和泛化
在第一次搜索中,控制器提出新方程训练WRN 16-2网络20个epoch,并且分别在有或没有动量的情况下用SGD训练。根据验证准确性收集前100个新方程,然后在不同场景下进行测试:
(A1)使用20个epoch训练WRN 16-2 ,复制搜索设置;
(A2)使用20个epoch训练WRN 28-10 ,将其推广到更大的模型(WRN 28- 10的参数是WRN 16-2的10倍);
(A3)使用100个epoch训练WRN 16-2 ,测试推广到更长的训练机制。
实验结果如表1所示:
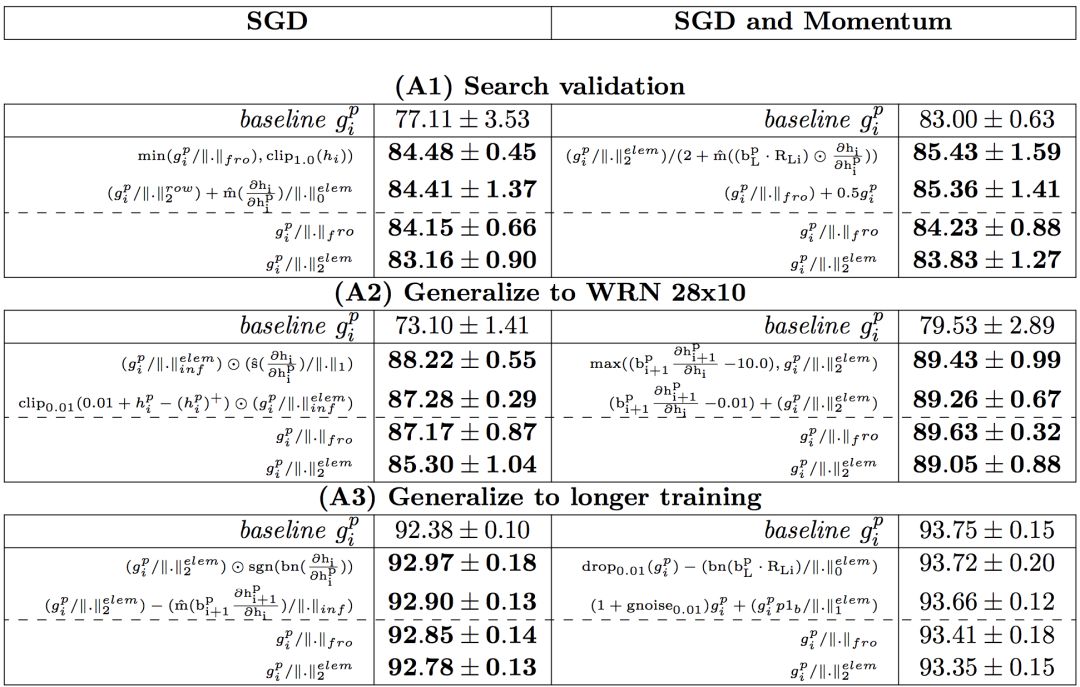

表1:实验结果
从A1到A3,在每个设置中展示了两个性能最好的方程,以及两个在所有设置中都表现良好的方程。在B1中展示了4个性能最好的方程,所有结果均为5次以上的平均测试准确率。基线是梯度反向传播。比基线性能优于0.1%的结果都用粗体表示。我们用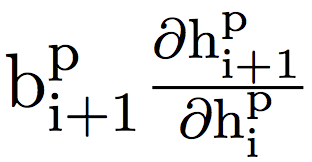
增加训练次数的搜索
之前的搜索实验发现新方程在训练开始时运行良好,但在收敛时不优于反向传播。后一种结果可能是由于搜索和测试机制之间的不匹配,因为搜索使用20个epoch来训练子模型,而测试机制使用100个epoch。
一个后续方案是匹配这两个机制。 在第二次搜索实验中,使用100个epoch训练每个子模型。 为了补偿由于使用较多的epoch进行训练而导致的实验时间增加,使用较小的网络(WRN 10-1)作为子模型。 使用较小的模型是可以接受的,因为新方程倾向于推广到更大,更真实的模型,如(A2)。
实验结果在表1中的(B1),与(A3)较为相似,即,可以找到对SGD表现较好的更新规则,但是对有动量的SGD的结果与基线相当。(A3)和(B1)结果的相似性表明,训练时间的差异可能不是误差的主要来源。 此外,具有动量的SGD对于不同的新方程是几乎不变的。
在这项工作中,提出了一种自动查找可以取代标准反向传播的方程的方法。使用了一种进化控制器(在方程分量空间中工作),并试图最大化训练网络的泛化。探索性研究的结果表明,对于特定的场景,有一些方程的泛化性能比基线更好,但要找到一个在一般场景中表现更好的方程还需要做更多的工作。
注:投稿请电邮至124239956@qq.com ,合作 或 加入未来产业促进会请加:www13923462501 微信号或者扫描下面二维码:

文章版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将删除内容或协商版权问题!联系QQ:124239956



