伦敦帝国理工学院 134页《深度学习数学基础笔记》(附下载)
【导读】本期分享为大家带来了来自伦敦帝国理工学院的《深度学习数学基础笔记》,希望大家喜欢。
介绍:
这些课堂讲稿来自于伦敦帝国理工学院的深度学习数学讲稿笔记,其目标在于为学生们提供基本的数学背景以及必要的技能,来理解、设计、实施现代的统计机器学习方法与推理机制,例如PCA(Principal Component Analysis)、Linear Discriminant Analysis、Bayesian Linear Regression 与 SVM(Support Vector Machines)。
掌握了深度学习中的数学基础后,同学们便可以逐步对深度学习模型进行探索,并随着领域的细分,逐步将研究方向聚焦于某个具体问题,正式进入研究阶段了。
笔记大纲:
线性回归
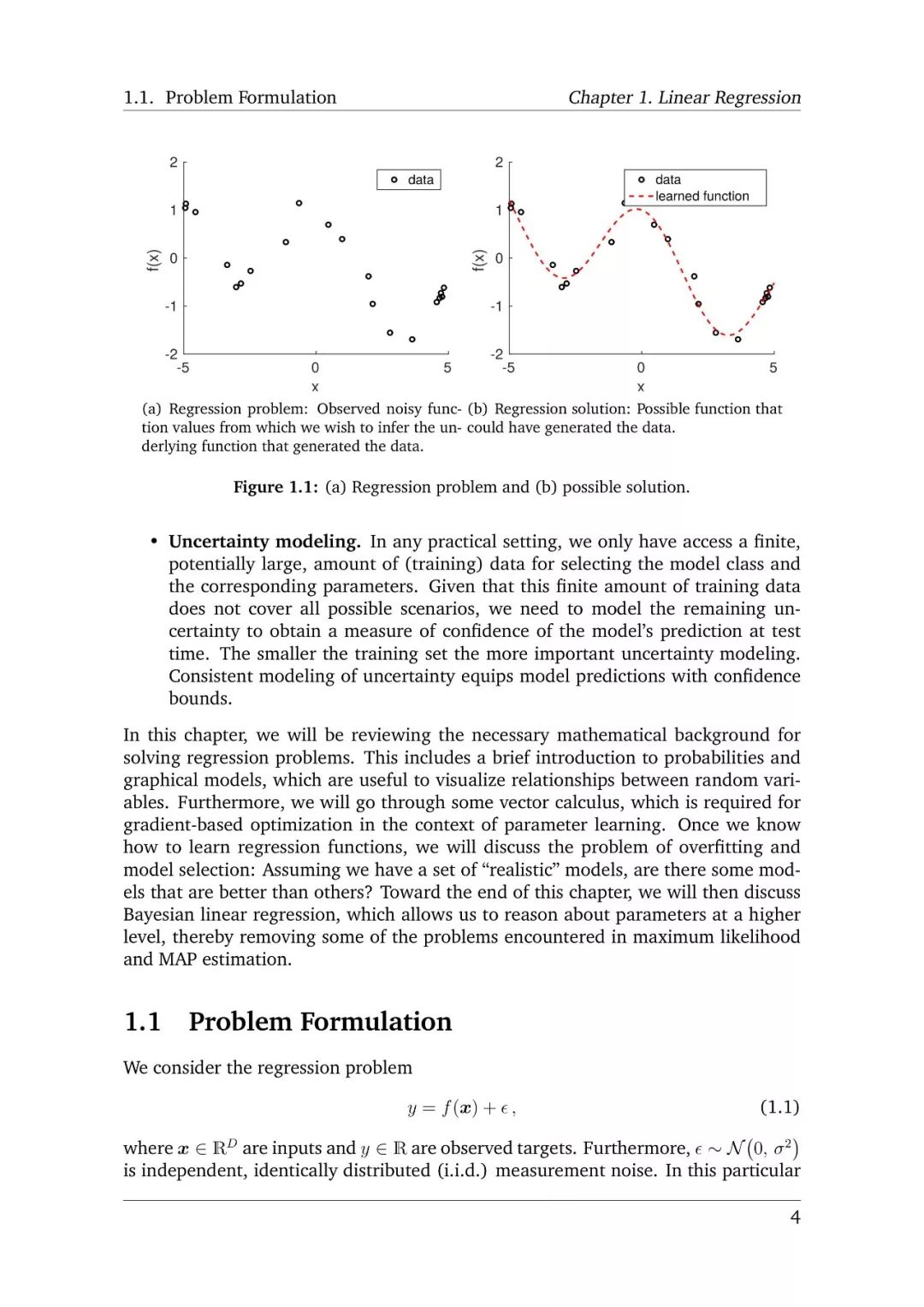
先行回归出现在多个多样化的问题中,是一个基本问题,其中包括事件序列分析、控制和机器人学科、优化问题、深度学习应用中,为了寻找回归函数,需要以下几部分:参数选择、参数搜索、概率模型、过拟合与模型选择。

特征抽取
本章将重点讨论向量和矩阵的线性代数的使用,为了定义基本特征提取和降维方法,我们将研究特定的线性分解,如特征分解、对角化、QR分解、奇异值分解等,上述代数分解将用于制定流行的线性特征提取方法,如主成分分析和线性判别方法等。

支持向量机
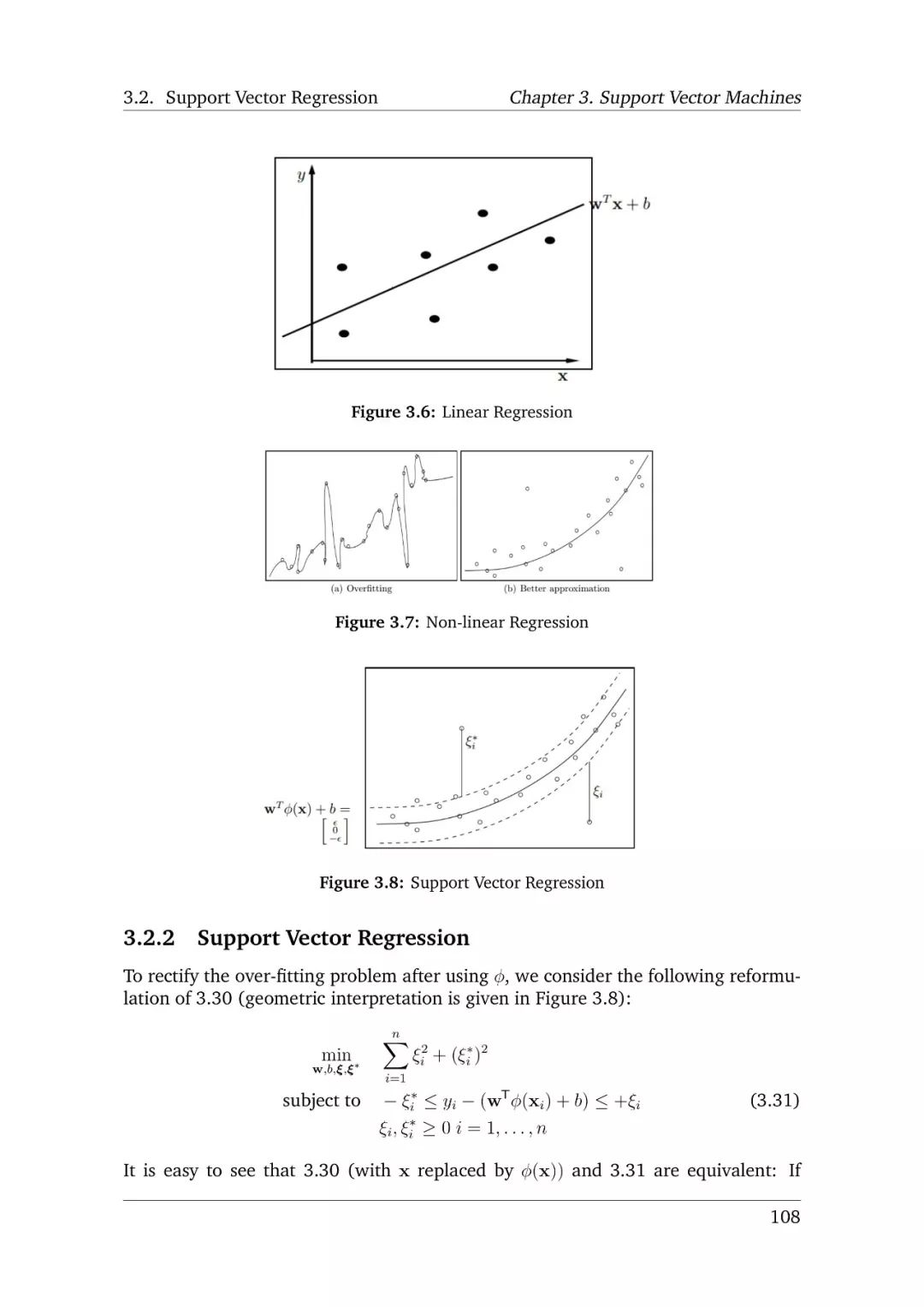
在本章中,我们将讨论有约束条件的二次优化问题,以便更详细的了解拉格朗日乘数的方法工作。此外,我们将研究如何建模dual optimisation problem问题,进而,研究SVM的分类和回归问题。

请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“LNMML” 就可以获取自监督学习指南的下载链接~
附笔记全文:












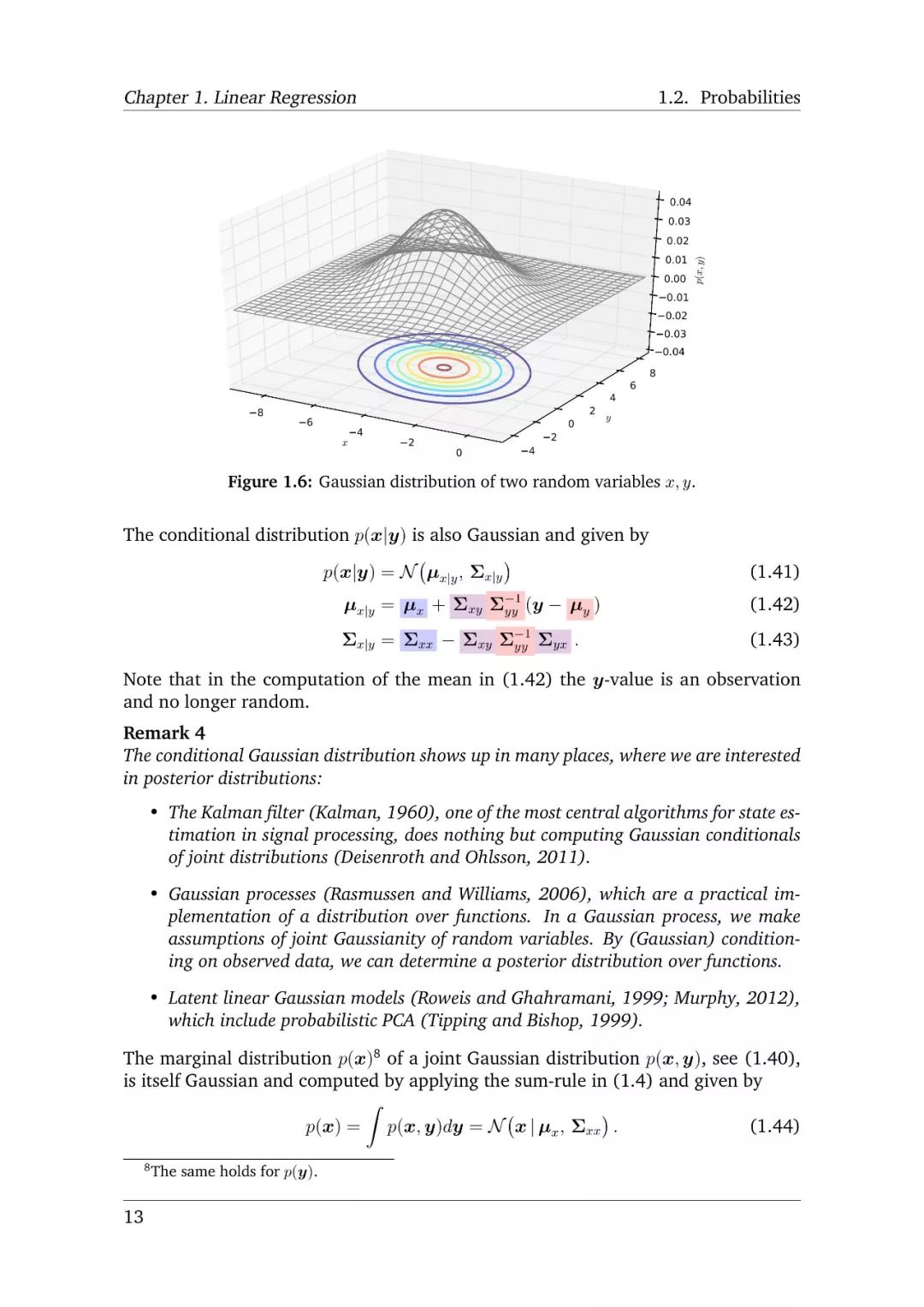
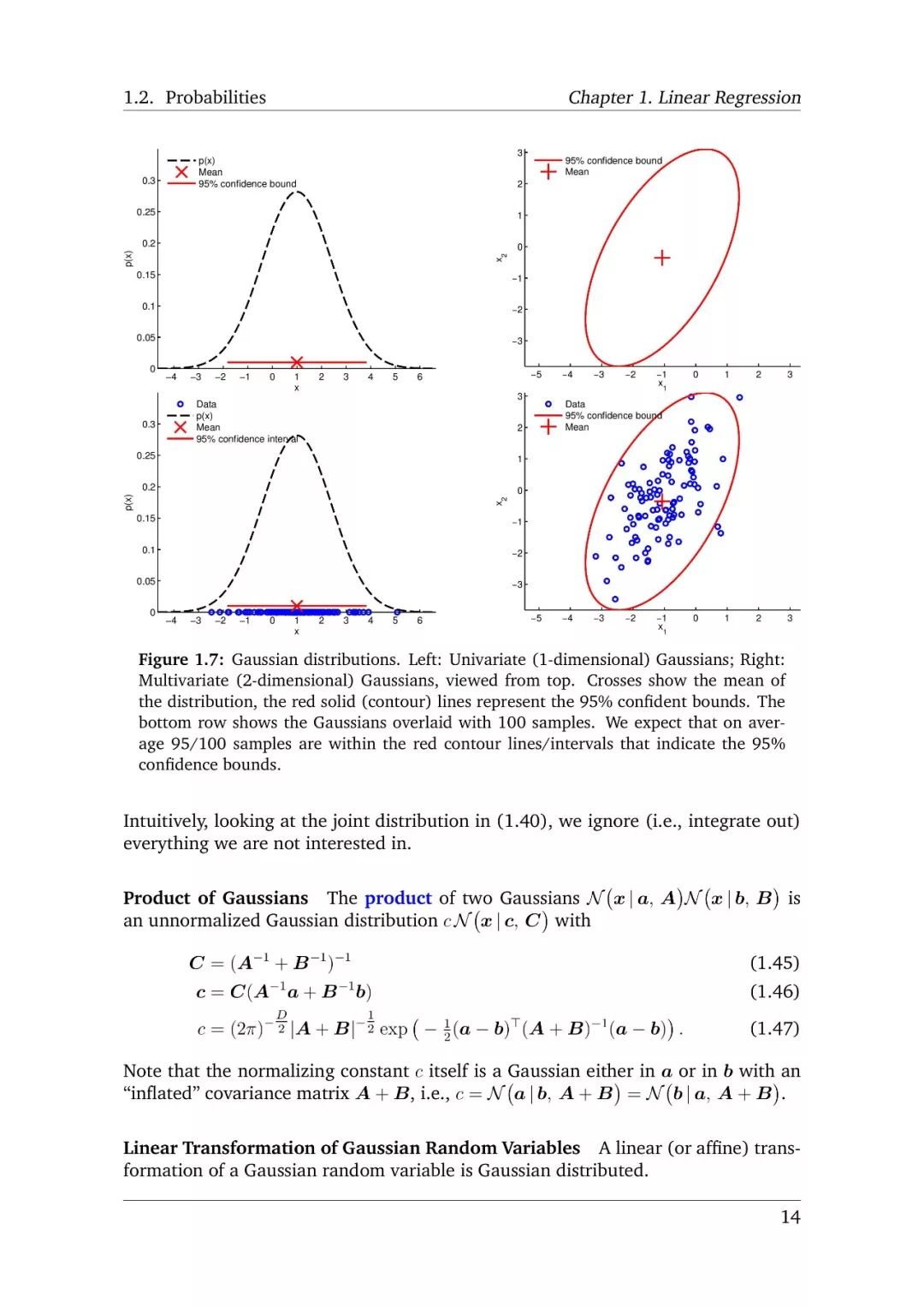
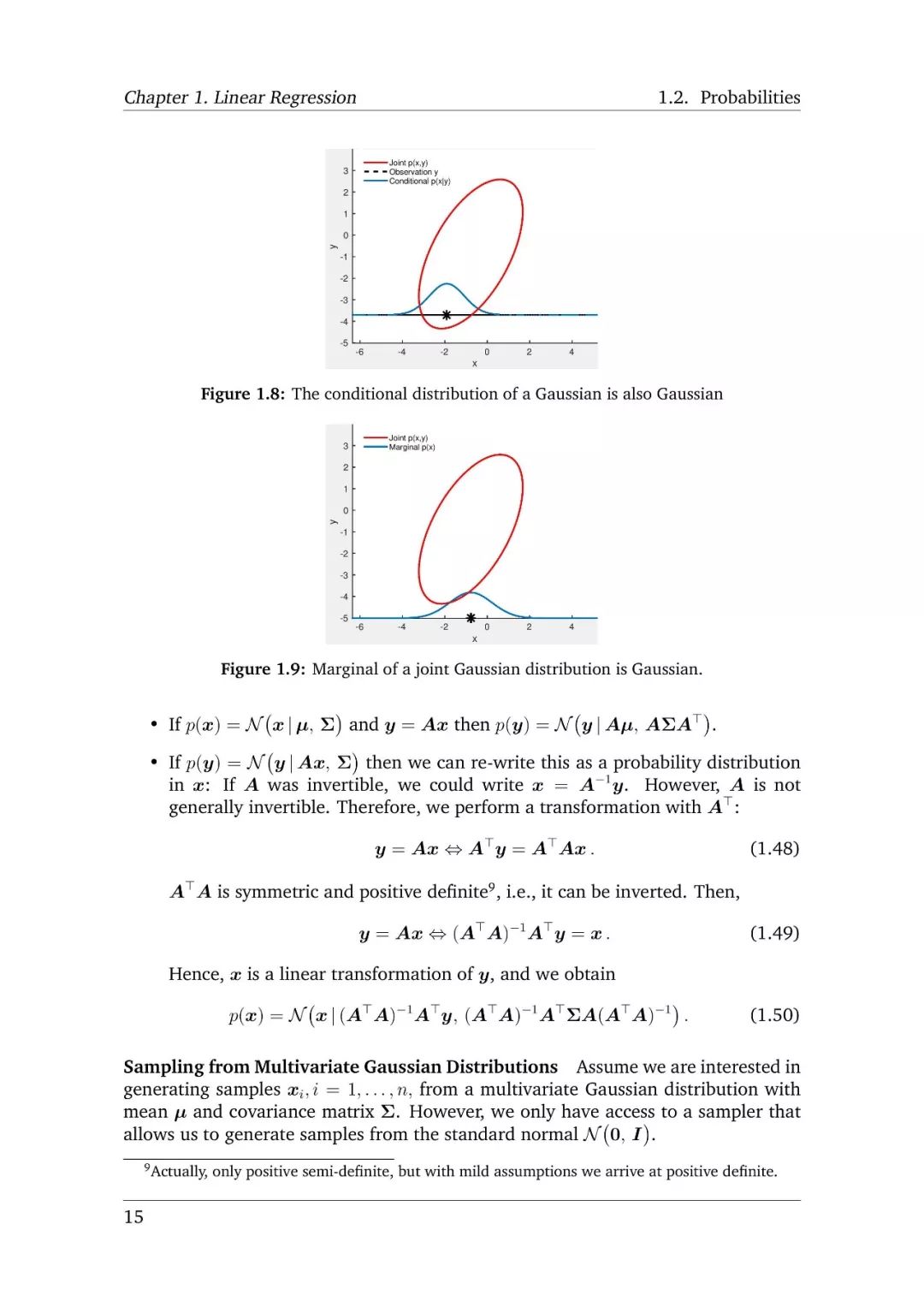
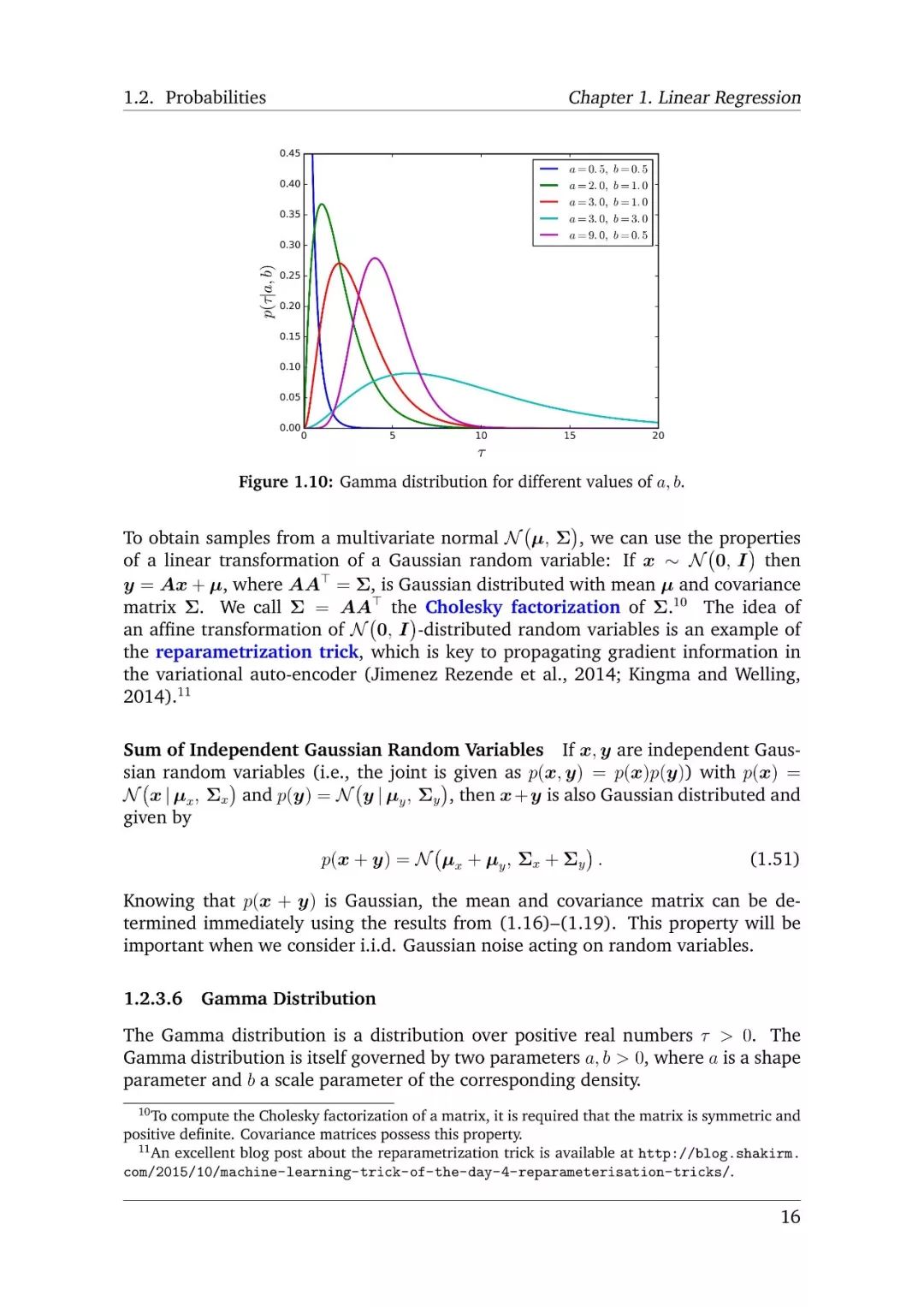





































































































-END-
专 · 知
人工智能领域26个主题知识资料全集获取,关注专知公众号,后台回复关键词如NLP、CV等获取更多专业资料。
加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




