TransRec: 基于混合模态反馈的可迁移推荐系统
归根到底,推荐系统算法过度依赖用户ID与物品ID信息,基于ID的推荐算法虽使得推荐系统脱离复杂的内容建模,在神经网络的加持下,性能也是经历了一段提升期,甚至逐渐主导了推荐系统领域,然而“成也ID,败也ID”,ID本身的不可共享性也导致了推荐系统故步自封,无法更好的拥抱NLP与CV领域的最新进展,使得基于ID的推荐系统性能出现严重瓶颈,甚至已经十分逼近ID本身的天花板;与此同时,ID的不可迁移性与难以共享性严重的拖了推荐系统大模型的后腿。本文将简要介绍一种最新的可迁移推荐算法,致力于探索可迁移推荐模型,实现更大范围的通用推荐系统。

一. 动机与目的
计算机视觉(CV)和自然语言处理(NLP)领域出现了许多大模型,形成了预训练大模型+微调的迁移学习范式。然而,对于推荐系统(RS)来说,还没有一个公认的学习范式来构建推荐系统的通用模型(general-purpose recommender systems:gpRS)。阻碍这一点的一个关键问题是,现有的RS模型主要由基于ID的协同过滤(CF)方法主导,其中用户/物品由推荐平台分配的唯一ID来表示,这些数据在不同平台间是不可共享的。因此,即便在一个平台经过充分训练的RS模型也只能用于服务当前的系统。即使在一些特殊情况下,两个平台的用户ID或物品ID 可以共享,仍然不容易实现预期的迁移,因为平台间较少的用户和物品重叠会带来有限的迁移效果。PeterRec[1],Conure[2]和 STAR[3]等模型就属于有限制的可迁移模型。
为了实现真正的通用推荐(无用户和物品重叠),论文探索基于模态内容的推荐,其中物品由模态编码器(如BERT和ResNet)而不是ID信息来表示。通过对模态特征进行建模,推荐模型才有可能在更广泛的意义上实现对应模态的跨域迁移,即不再依赖共享的ID信息,从基于ID回到基于内容的推荐,本文中通用推荐的实现是基于一个常见的推荐场景,即用户的物品交互行为由混合模态(MoM: Mixture-of-modality)的物品组成,例如信息流推荐场景,今日头条等用户在一个session内可能点击新闻也可能点击视频或者图。
如图1,在源域中,用户交互的物品可以是文本(text)形式,视觉(vision)(图像/视频等)形式,或两种模态形式都存在。这样的场景在许多实际的推荐系统中很流行,比如说feeds流推荐,其中推荐的物品可以是一篇新闻、一张图片或一段微视频。基于混合模态反馈(feedback with MoM)的推荐模型是实现可迁移和通用推荐的重要途径,可以迁移到属于任何源领域模态组合的目标域,扩展了模型的通用性。值得注意的是,于近日公开发表的UniSRec[4]和ZESREC[5]基于物品的文本信息进行跨域推荐,聚焦于一种单文本模态。很显然,只包含一种模态的交互要求目标域必须和只能具备该模态信息,限制了通用范围。
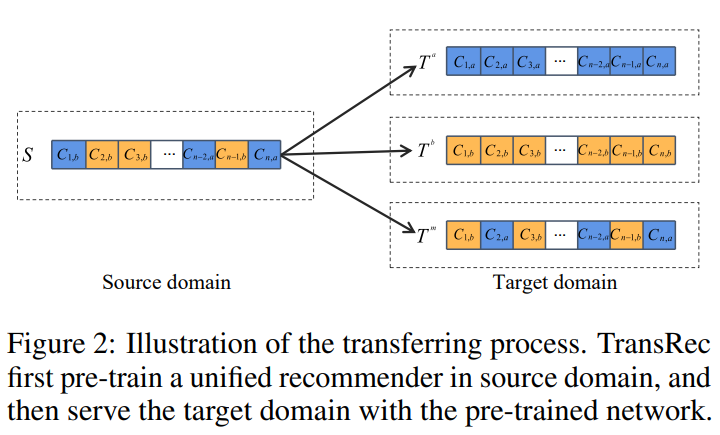
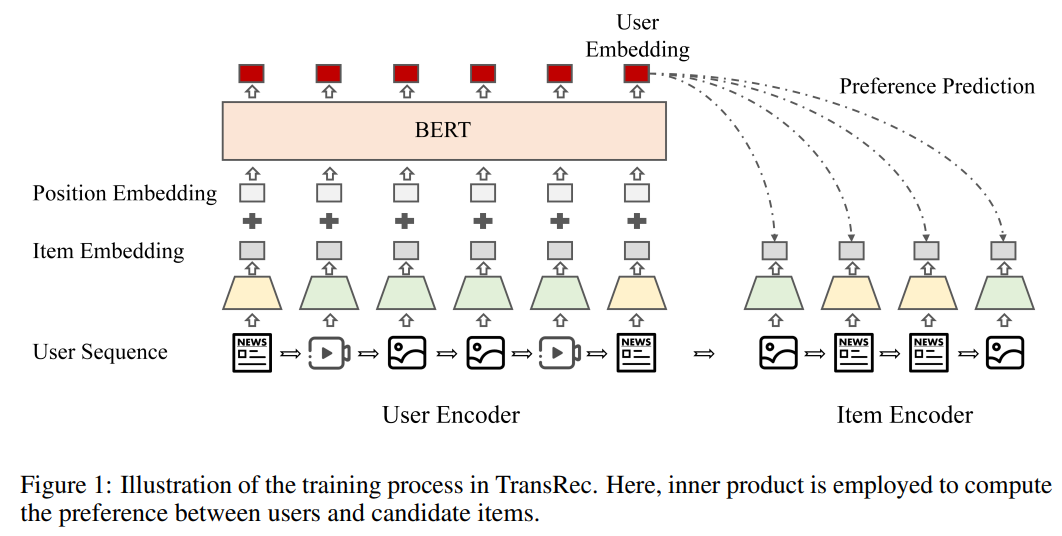
论文设计了TransRec,如图2所示,一个简单而有代表性的双塔推荐框架,用于对混合模态的用户反馈进行建模。TransRec是对最经典的基于ID的双塔DSSM的直接改编应用。其中一端是item encoder,物品通过模态编码器获得item embedding;一端是user encoder,用户则由他的物品交互序列来表示,通过Bert对用户交互序列进行建模获得用户embedding。最后通过计算用户和物品的相似度预测。论文没有设计复杂的推荐模型,相反,采用最常见最简单的模型,只需要将ID直接替换成模态encoder,就能实现很好的通用性和可迁移性。
-
论文验证了一个重要的事实,即学习用户的混合模态反馈(MoM feedback)具备极大的潜力实现通用推荐系统。 -
论文设计了简单而有效的TransRec, 第一个可以实现跨模态和跨域推荐的双塔结构模型,同时可以根据需求集合用户/物品特征进行迁移学习。 -
论文在包括四种推荐场景的目标域下对预训练TransRec的可迁移性做了测评和验证,目标域均与源域无用户和物品重叠。 -
论文通过缩小/扩大源/目标域数据规模,验证了数据集大小对迁移性能的影响。
-
新的源混合模态场景和数据集
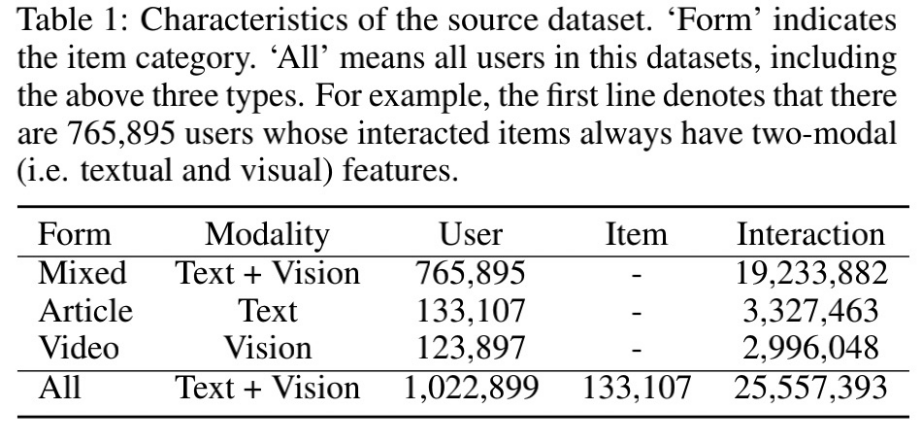
源域来自新闻推荐场景,包含文章和视频。用户交互的item为文本和视觉两种混合模态,交互分布根据模态共包括三种(单一文本,单一视觉和文本视觉混合)情况。包括超过一百万用户的混合模态交互行为,具体分布如图3。
2.预训练方法
TransRec采用2阶段式的训练方式,第一阶段先对user encoder进行预训练,采用下一个item预测这种方式进行单向Bert的训练。第二阶段则是双塔模型的端到端训练,采用CPC训练方式,预测用户行为序列,采取随机负采样。过程如图4所示。具体地:
第 1 阶段:user encoder预训练。以自监督的方式对user encoder进行预训练。具体来说,作者采用从左到右的生成预训练来预测用户交互序列中的下一个item,即预训练单向Bert,因为单向预训练收敛速度更快,但不会损失精度。使用 softmax 交叉熵损失作为目标函数,损失函数如下图4所示:
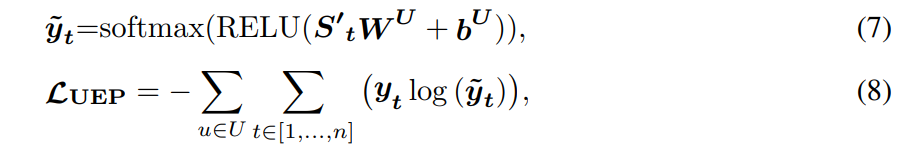
第 2 阶段:端到端双塔推荐预训练。TransRec 通过微调user encoder和item encoder的参数以端到端的方式进行训练。这与许多在训练模型之前预先提取模态特征的多模态推荐任务有很大不同。端到端训练可以更好地适应当前推荐领域的文本和视觉特征。具体来说,论文使用 Contrastive Predictive Coding(CPC) 学习方法。给定一个用户交互序列 ,将序列划分为子序列 和 来编码和预测它们之间的关系,采取二元交叉熵损失函数,如下图5所示:
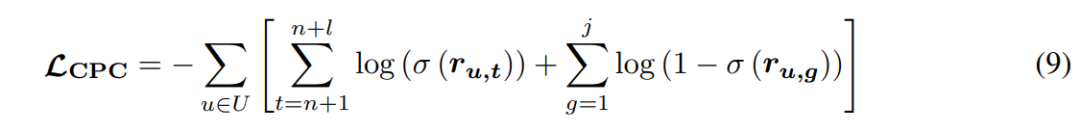
特别地,针对item encoder,论文将一种物品的模态对应一种模态编码器,具体利用经过预训练的ResNet和BERT分别编码视觉物品和文本物品。针对视觉信息,作者采用视频的首页图作为内容,文本则使用新闻的标题。
三. 实验结果
-
源域结果
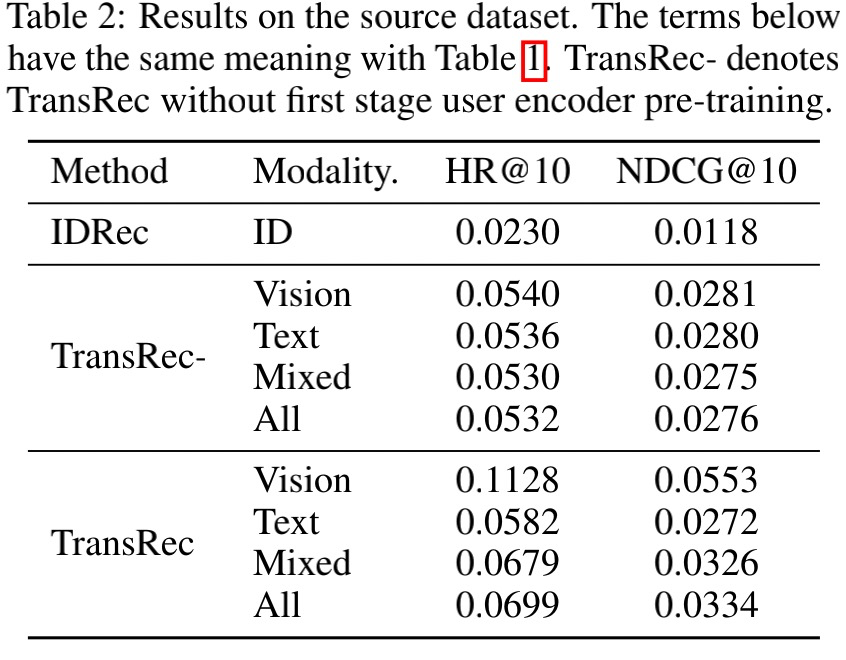
作者首先在预训练的源域数据上测试了结果。首先TransRec的性能大大超过在相同的网络结构下基于ID的模型。其次,论文还证实了第1阶段user encoder预训练的作用,通过与直接训练双塔模型比较,2阶段式的模型性能更强。具体数据分布的结果如下图6所示:
-
目标域结果
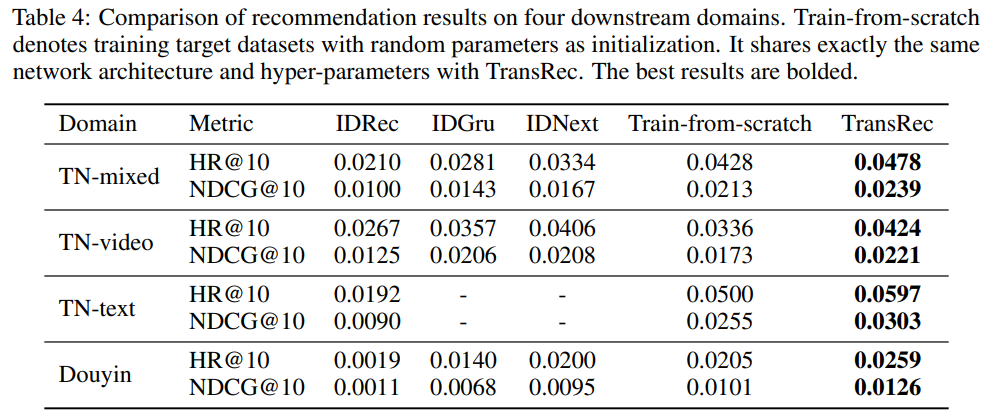
目标域包括源域模态能覆盖到的所有情况,即单一文本模态,单一视觉模态,以及混合文本和视觉模态的三种情况下的4个推荐场景数据集,这些目标域均与源域不存在重叠信息。作者将预训练好的模型直接迁移到目标域进行finetune。首先与基于ID的3个序列推荐模型进行结果比较,经过finetune的TransRec可以有效提升推荐结果。结果对比如图7所示。其次,经过finetune的TransRec性能仍旧超过该模型的trian-from-scratch方式,证实了在大数据上预训练的TransRec推荐模型有效的学习了用户和物品的关系,并且可以迁移到下游推进任务,实现通用推荐。结果对比如图7所示:
此外,论文还与线下提取item模态feature后进行推荐的方法进行了比较,进一步证实了端到端的训练方式使性能获得了极大的提升。作者还对模型的灵活性进行了探索,TransRec在迁移到下游具有额外特征的推荐场景,即双塔的模型可以分别在item encoder 和 user encoder端集成物品和用户的特征。
-
Ablation study
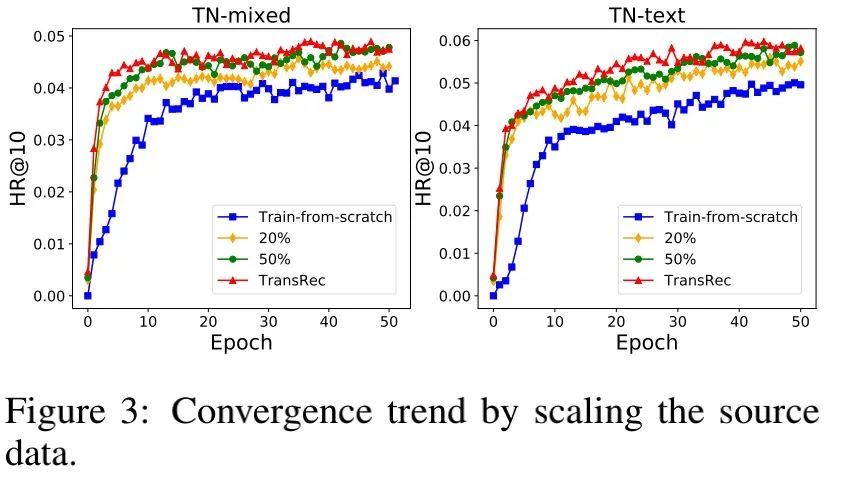
作者还做了大量的scaling实验,分别对源数据集和目标数据集进行scaling。对源数据集进行缩小规模重新进行完整的TransRec预训练,再迁移到目标域上,结果证实随着源数据集的增大,目标域提升的性能也逐渐增大,如图8所示。这表明,TransRec可以通过扩大数据集实现更强的推荐性能,工业界往往具备不断扩充数据的能力,TransRec可以有效应用于公司。
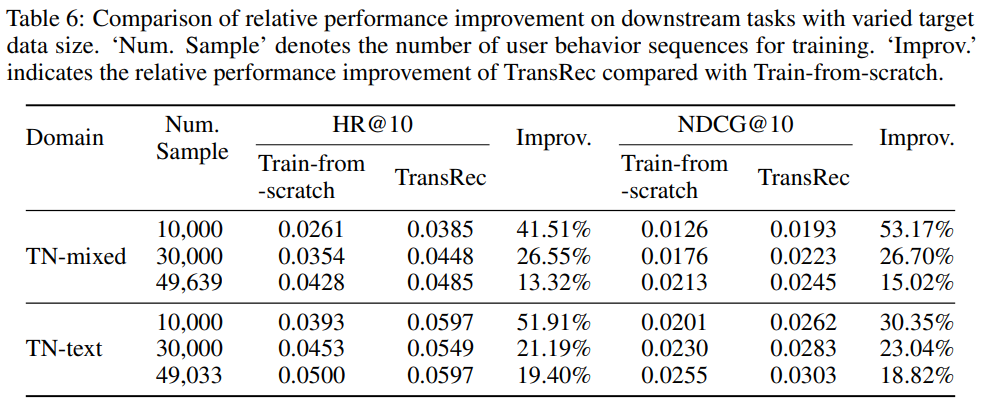
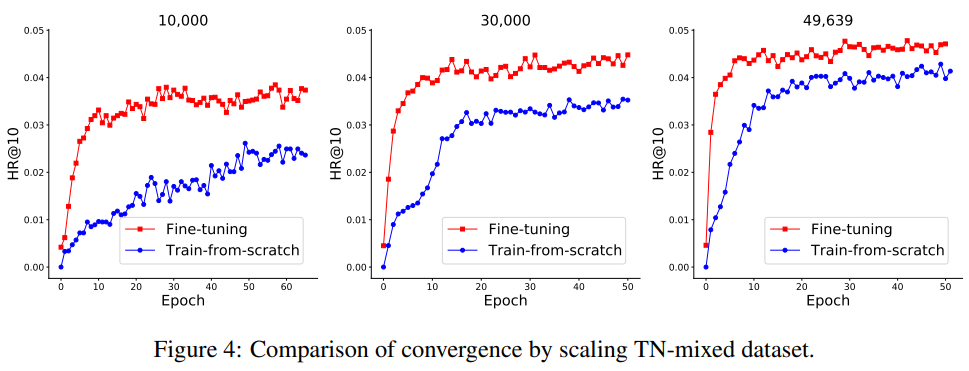
作者又对目标数据集缩小规模进行迁移比较,如图9与图10所示。结果表明随着目标数据集的减小,TransRec对于性能的提升逐渐增大,对收敛速度的提升也更多,这意味着在训练数据集过小时,预训练的TransRec可以通过巨大的源数据集学习的关系弥补因目标数据集过小而损失的用户-物品关系。
参考文献
[5] Ding, Hao, et al. Zero-shot recommender systems. arXiv, 2021.
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。


