点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
作者丨葛艺潇@知乎,转自计算机视觉slam
来源丨https://zhuanlan.zhihu.com/p/169596514
本文介绍了一篇我们发表于ECCV 2020的论文《Self-supervising Fine-grained Region Similarities for Large-scale Image Localization》[1],很荣幸该论文被收录为spotlight presentation。
我们针对大规模图像定位中的弱监督问题提出有效的解决方法,旨在通过自监督学习的方法充分挖掘表征学习中的难样本,并进一步将图像级监督细粒化为区域级监督,以更好地建模图像与区域间的复杂关系。利用该算法训练的模型具有较强的鲁棒性和泛化性,在多个图像定位数据集上进行了验证,Recall@1准确度大幅超越最先进技术高达5.7%,代码和模型均已公开。
论文链接:https://arxiv.org/abs/2006.03926
代码链接:https://github.com/yxgeee/OpenIBL
项目主页:https://geyixiao.com/projects/sfrs
90s简要版视频介绍:https://www.bilibili.com/video/BV1Y54y1q7CL/
5min完整版视频介绍:https://www.bilibili.com/video/BV1Da4y1E79q(见下)
背景简介
1、图像定位
给定一张目标图像,图像定位(Image-based Localization)技术旨在不借助GPS等额外信息的情况下估计出图像所在的地理位置,该技术被广泛应用于SLAM、AR/VR、手机拍照定位等场景。目前针对图像定位的研究主要可以分为三个方向,分别为基于图像检索的、基于2D-3D匹配的和基于地理位置分类的算法。其中基于图像检索(Image Retrieval)的方案在大规模(Large-scale)的长期图像定位(Long-term Localization)上可行性更高,所以该工作针对基于图像检索的定位问题展开了研究。
2、基于图像检索的图像定位
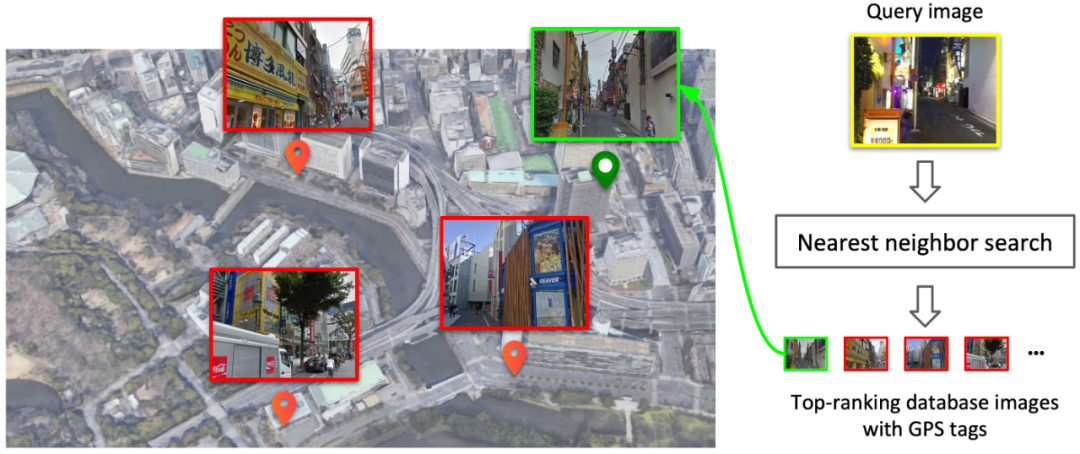
基于检索的图像定位问题旨在通过从城市级规模的数据库中识别出与目标图像最相似的参考图像,从而通过参考图像的地理位置(GPS)来估计目标图像的地理位置。基于检索的图像定位问题也被称为地点识别(Place Recognition)。
挑战 #1
1、问题
图像定位的数据集目前主要主要分为两种,一种是直接从街景地图(谷歌街景图、百度街景图等)中对图像和相应的GPS标签进行爬取,这种类型的数据集无需人为标注,零成本,易于收集和进行规模提升;另一种是具有6DoF相机位姿的数据集,该类数据集通常通过自动驾驶车进行收集,收集成本较高。该工作以前者为基准开展研究,即在仅有GPS标签的情况下进行基于检索的图像定位算法研究。
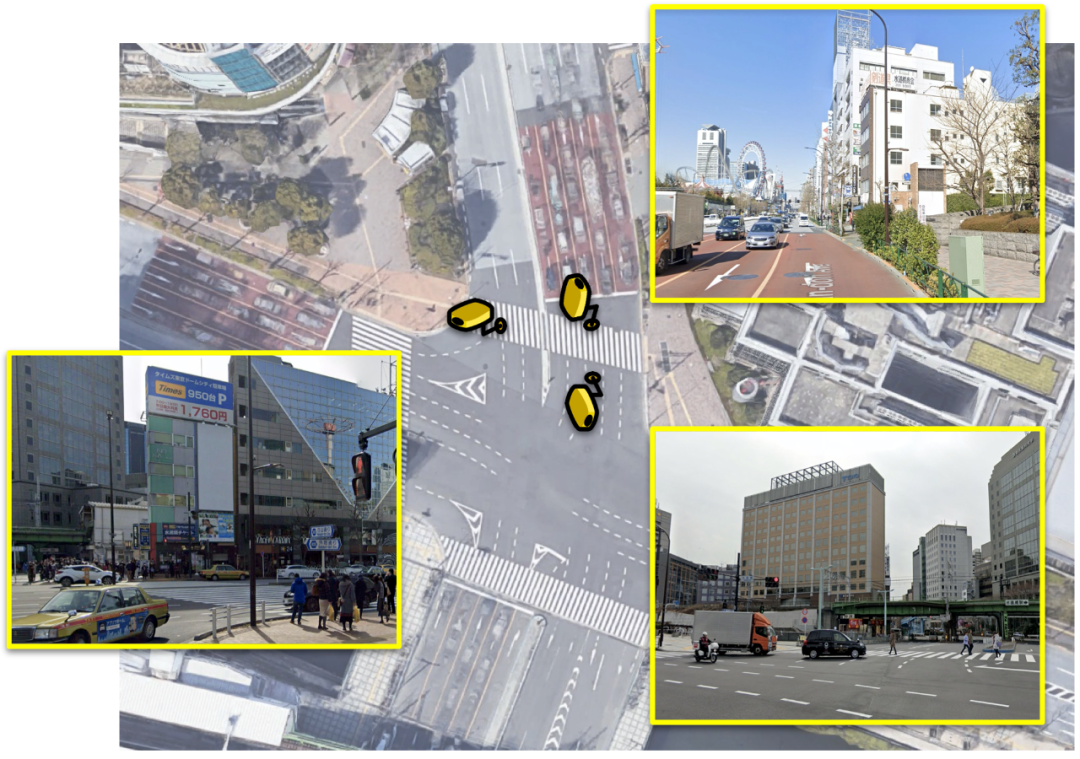
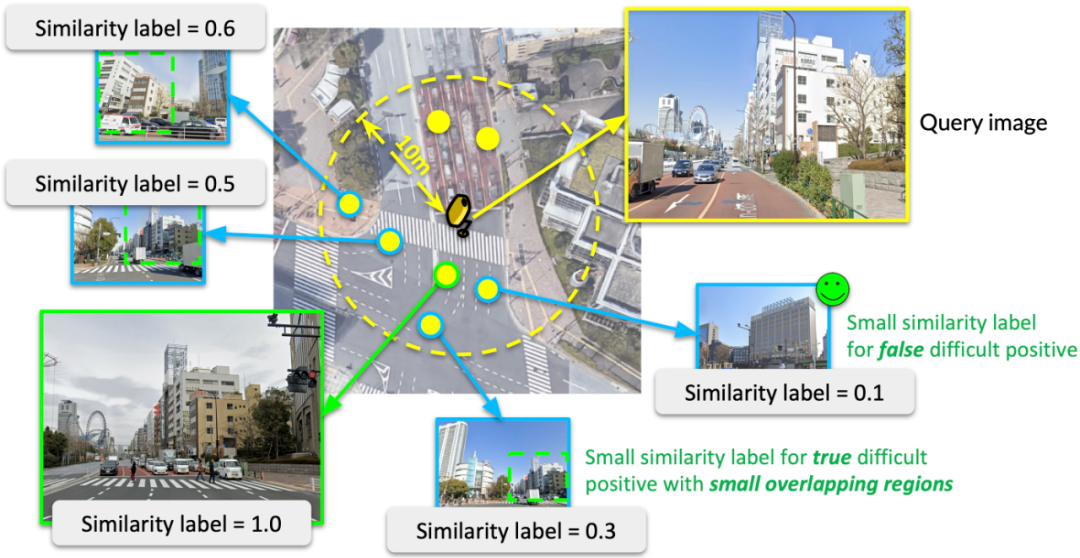
图像检索的关键在于如何学习到具有辨别性的图像特征,而在模型的训练中往往都需要有正样本和负样本。具体来说,模型需要学习让目标图像的特征靠近正样本而远离负样本。在仅有GPS的图像定位数据集中,我们可以首先通过GPS进行筛选,比如GPS相距10m以内的图像为潜在正样本(Potential Positives)。但是,如下图所示,当地理位置上较近(GPS较近)的图像在面向不同方向时,并不会拍摄到同样的场景,所以仅靠GPS进行过滤的潜在正样本中仍然具有很多假性正样本(False Positives)。所以在模型训练中,这被定义为一个弱监督学习问题。
2、以前的方法
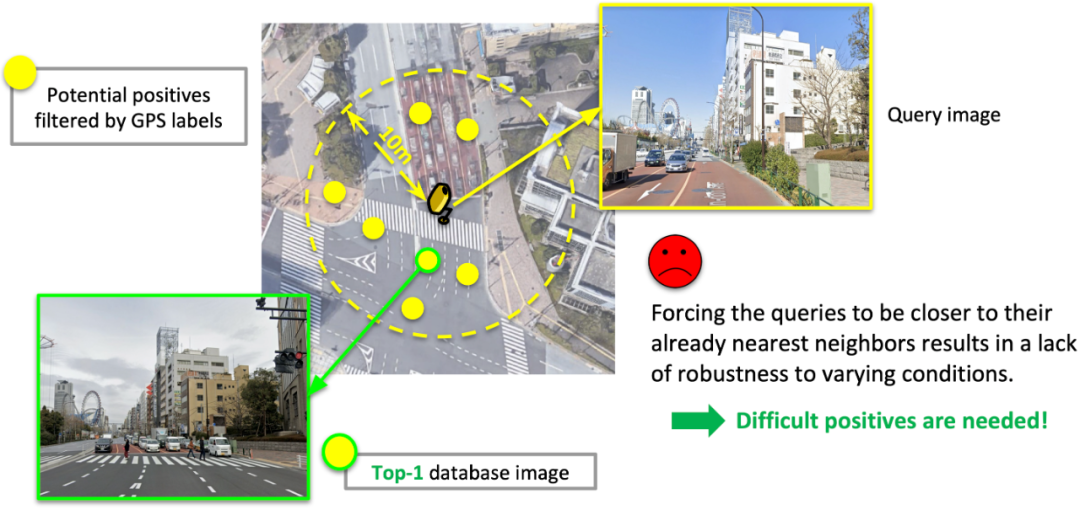
如果在训练中让目标图像靠近假的正样本,会导致严重的误差放大,乃至模型崩溃。所以,如下图所示,现有的训练算法[2, 3]让目标图像靠近潜在正样本中特征距离最近的图像,也被称为top-1/最相似图像。虽然这样的方法可以有效减少假性正样本出现的概率,但是,让模型学习靠近已经是最相似(也就是最简单)的正样本,会使得训练的模型缺乏适应多种条件(光照、角度等等)的能力,降低模型的鲁棒性。
3、动机
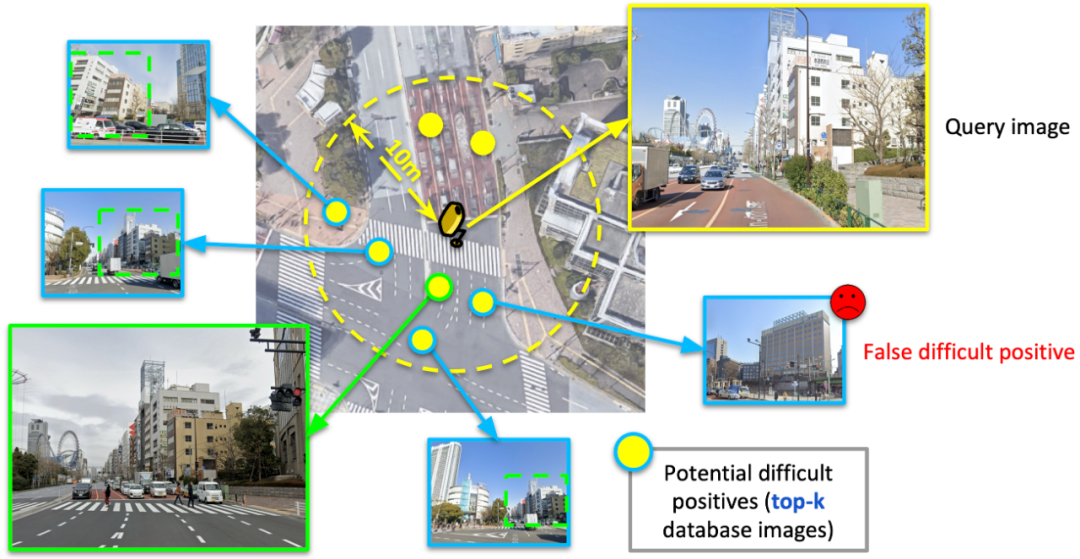
我们认为,困难的正样本(Difficult Positives)在表征学习中不可缺少。但是,简单地使用top-k图像(这里top-k指的是利用特征距离进行排序后的top-k数据库图像)作为正样本进行学习具有较大的噪声。如下图所示,top-k的图像中无法避免地包含一些假性正样本,在对比实验中我们也发现,简单地采用top-k图像进行训练,结果还不如上述只学习top-1的现有方法。所以,问题的关键在于,如何合理地使用top-k图像,在挖掘困难正样本的同时,减轻假性正样本对模型训练带来的干扰。
4、解决方法
我们提出利用目标图像与数据库图像之间的相似性作为软标签对模型训练进行监督。具体来说,对于假性正样本,或具有较小重叠区域的正样本,我们希望设置较小的相似性标签;而针对与目标图像重叠区域较大的正样本,我们希望设置较大的相似性标签。这样的话,在相似性标签的监督下,模型可以模拟出目标图像与不同匹配图像之间距离关系,从而有针对性地进行表征学习。
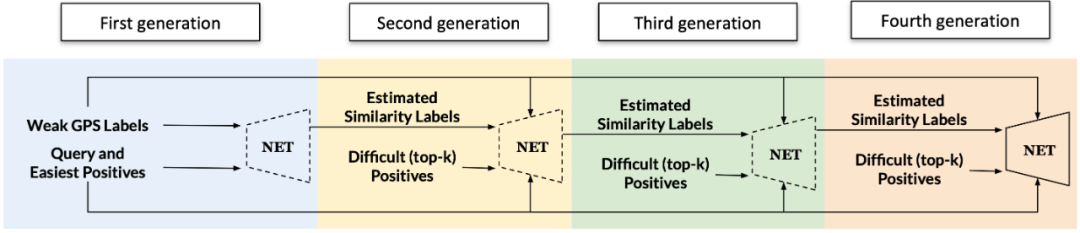
那么,如何获得相似性标签呢?直接通过当前模型的数据进行预测是不可行的,这就类似于自己站在自己的脚上,既没有够到更高的区域,反而会站不稳(导致误差放大)。所以,我们提出,通过
迭代训练(Training in Generations)的方案,将第一代模型的输出作为第二代模型的监督,以此类推
。请注意,这里的“代”指的是一个模型从初始化训练到收敛的整个过程。如下图所示,第一代模型通过与现有算法一致的方案进行训练,训练收敛后,建立并初始化第二代模型,并使用固定的第一代模型进行相似度标签的估计,用以训练第二代模型。预测的相似度标签准确性和模型的辨别性随着训练的迭代不断更新和提升,从而形成自监督的过程。
迭代训练的思路与自蒸馏(Self-distillation)的算法[4, 5]比较相关,不同的是,自蒸馏的算法主要针对分类问题,对具有固定类别数目的分类预测值进行蒸馏,而我们成功地将迭代训练的思路应用于图像检索问题,在表征学习的过程中利用我们提出的相似性标签进行信息迭代。具体公式在这里就不做展示了,感兴趣的同学可以查阅原论文。
挑战 #2
1、问题与动机
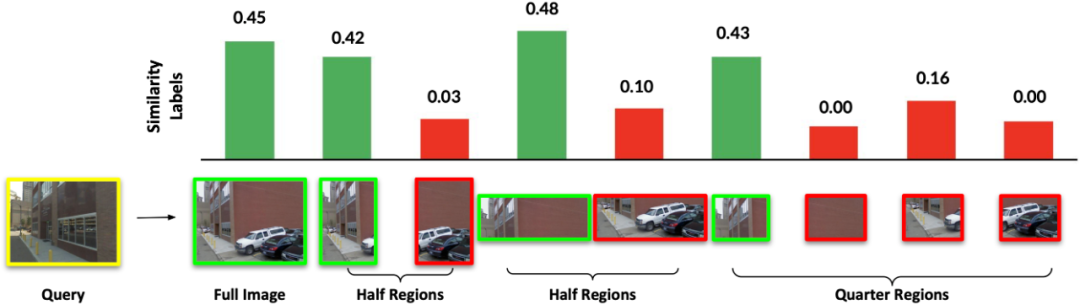
上文,我们讨论了如何合理地挖掘困难正样本,并减轻假性正样本对训练造成的干扰。但是,我们发现,即使是真的正样本,与目标图像之间仍然存在不重叠的区域,该区域在困难正样本中尤为显著。如下图左边所示,只使用图像级的监督会使得目标图像与正样本图像的所有局部特征都趋向于相似,这样的监督会损害局部特征的辨别性学习。所以,我们提出,理想的监督应当为区域级的监督,如下图右边所示,让正样本中的正区域(Positive Regions)靠近目标图像,而负区域(Negative Regions)远离目标图像。
2、解决方法
为了实现区域级的监督,我们将匹配的正样本分解为4个二分之一区域和4个四分之一区域,并将图像-图像间的相似性监督细粒化为图像-区域间的相似性监督,以上文中所述迭代训练的方式进行学习。具体来说,第一代模型所预测的图像-区域的相似性标签用于监督第二代模型的图像-区域学习。
实验结果
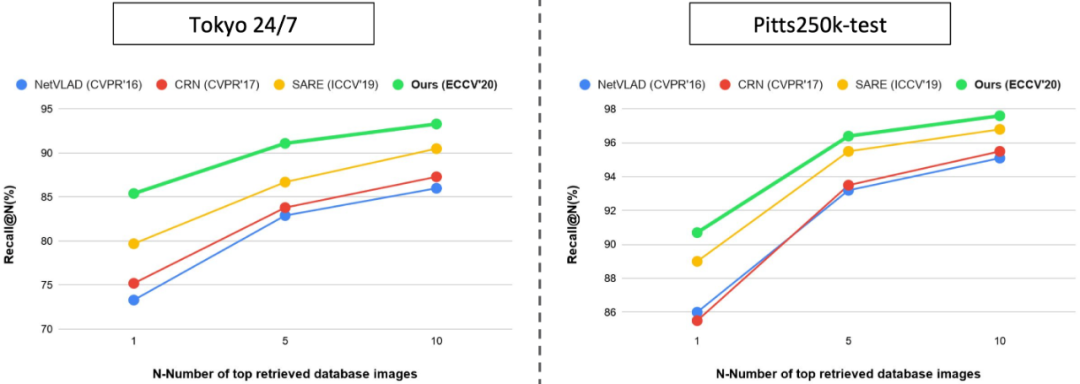
下图是实验结果,我们的模型只在一个数据集(Pitts30k-train)上进行了训练,可以很好地泛化到不同的测试集上,例如在Tokyo 24/7和Pitts250k-test上均取得了最先进的精度。其中,Tokyo 24/7数据集难度最大,因为图像的光照、角度、拍摄装置等条件都具有很强的多样性,我们在Recall@1准确度上超出此前最先进的SARE算法(发表于ICCV’19)5.7%个点。
https://github.com/yxgeee/OpenIBL
同时,我们还开源了基于PyTorch的NetVLAD [2] 和SARE [3] 复现(官方代码基于MatConvNet),方便大家后续的研究与开发。
[1] Y. Ge, et al. Self-supervising Fine-grained Region Similarities for Large-scale Image Localization. ECCV, 2020.
[2] R. Arandjelovic, et al. NetVLAD: CNN architecture for weakly supervised place recognition. CVPR, 2016.
[3] L. Liu, et al. Stochastic Attraction-Repulsion Embedding for Large Scale Image Localization. ICCV, 2019.
[4] T. Furlanello, et al. Born Again Neural Networks. ICML, 2018.
[5] Q. Xie, et al. Self-training with noisy student improves imagenet classification. CVPR, 2020.