Python 爬虫:Scrapy 实例(一)
一次性付费进群,长期免费索取教程,没有付费教程。
教程列表见微信公众号底部菜单
进微信群回复公众号:微信群;QQ群:460500587

微信公众号:计算机与网络安全
ID:Computer-network
1、创建Scrapy项目
cd
cd code/scrapy/
scrapy startproject todayMovie
tree todayMovie
执行结果如图1所示。

cd todayMovie
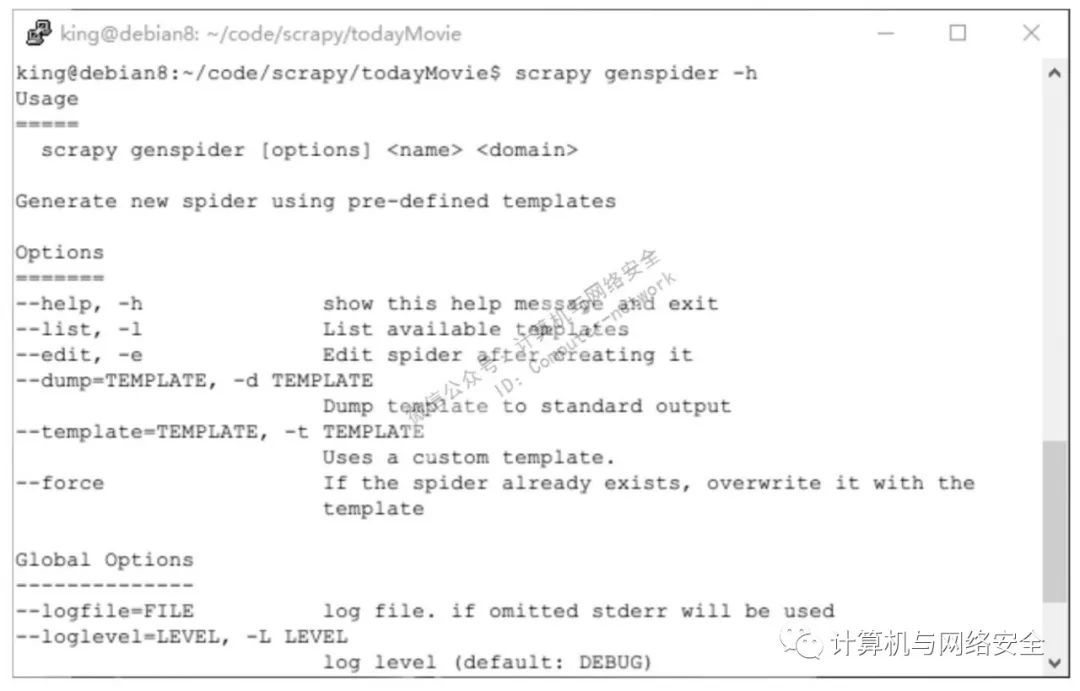
scrapy genspider wuHanMovieSpider mtime.com
执行结果如图2所示。

2、Scrapy文件介绍
1 # Automatically created by: scrapy startproject
2 #
3 # For more information about the [deploy] section see:
4 # http://doc.scrapy.org/en/latest/topics/scrapyd.html
5
6 [settings]
7 default = todayMovie.settings
8
9 [deploy]
10 #url = http://localhost:6800/
11 project = todayMovie
1 # -*- coding: utf-8 -*-
2
3 # Scrapy settings for todayMovie project
4 #
5 # For simplicity, this file contains only settings considered important or
6 # commonly used. You can find more settings consulting the documentation:
7 #
8 # https://doc.scrapy.org/en/latest/topics/settings.html
9 # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
10 # https://doc.scrapy.org/en/latest/topics/spider-middleware.html
11
12 BOT_NAME = 'todayMovie'
13
14 SPIDER_MODULES = ['todayMovie.spiders']
15 NEWSPIDER_MODULE = 'todayMovie.spiders'
16
17
18 # Crawl responsibly by identifying yourself (and your website) on the
user-agent
19 #USER_AGENT = 'todayMovie (+http://www.yourdomain.com)'
20
21 # Obey robots.txt rules
22 ROBOTSTXT_OBEY = True
items.py文件的作用是定义爬虫最终需要哪些项,items.py的内容如下:
1 # -*- coding: utf-8 -*-
2
3 # Define here the models for your scraped items
4 #
5 # See documentation in:
6 # http://doc.scrapy.org/en/latest/topics/items.html
7
8 import scrapy
9
10
11 class TodaymovieItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 pass
1 # -*- coding: utf-8 -*-
2
3 # Define your item pipelines here
4 #
5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting
6 # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
7
8
9 class TodaymoviePipeline(object):
10 def process_item(self, item, spider):
11 return item
1 # -*- coding: utf-8 -*-
2 import scrapy
3
4
5 class WuhanmoviespiderSpider(scrapy.Spider):
6 name = "wuHanMovieSpider"
7 allowed_domains = ["mtime.com"]
8 start_urls = (
9 'http://www.mtime.com/',
10 )
11
12 def parse(self, response):
13 pass
3、Scrapy爬虫编写
(1)选择爬取的项目items.py
修改items.py文件如下:
1 # -*- coding: untf-8 -*-
2
3 # Define here the models for your scraped items
4 #
5 # See documentation in:
6 # http://doc.scrapy.org/en/latest/topics/items.html
7
8 import scrapy
9
10
11 class TodaymovieItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 #pass
15 movieTitleCn = scrapy.Field() #影片中文名
16 movieTitleEn = scrapy.Field() #影片英文名
17 director = scrapy.Field() #导演
18 runtime = scrapy.Field() #电影时长
(2)定义怎样爬取wuHanMovieSpider.py
修改spiders/wuHanMovieSpider.py,内容如下:
1 # -*- coding: utf-8 -*-
2 import scrapy
3 from todayMovie.items import TodaymovieItem
4 import re
5
6
7 class WuhanmoviespiderSpider(scrapy.Spider):
8 name = "wuHanMovieSpider"
9 allowed_domains = ["mtime.com"]
10 start_urls = [
11 'http://theater.mtime.com/China_Hubei_Province_Wuhan_Wuchang/4316/',
12 ] #这个是武汉汉街万达影院的主页
13
14
15 def parse(self, response):
16 selector = response.xpath('/html/body/script[3]/text()')[0].extract()
17 moviesStr = re.search('"movies":\[.*?\]', selector).group()
18 moviesList = re.findall('{.*?}', moviesStr)
19 items = []
20 for movie in moviesList:
21 mDic = eval(movie)
22 item = TodaymovieItem()
23 item['movieTitleCn'] = mDic.get('movieTitleCn')
24 item['movieTitleEn'] = mDic.get('movieTitleEn')
25 item['director'] = mDic.get('director')
26 item['runtime'] = mDic.get('runtime')
27 items.append(item)
28 return items
打开Chrome浏览器,在地址栏输入爬取网页的地址,打开网页。
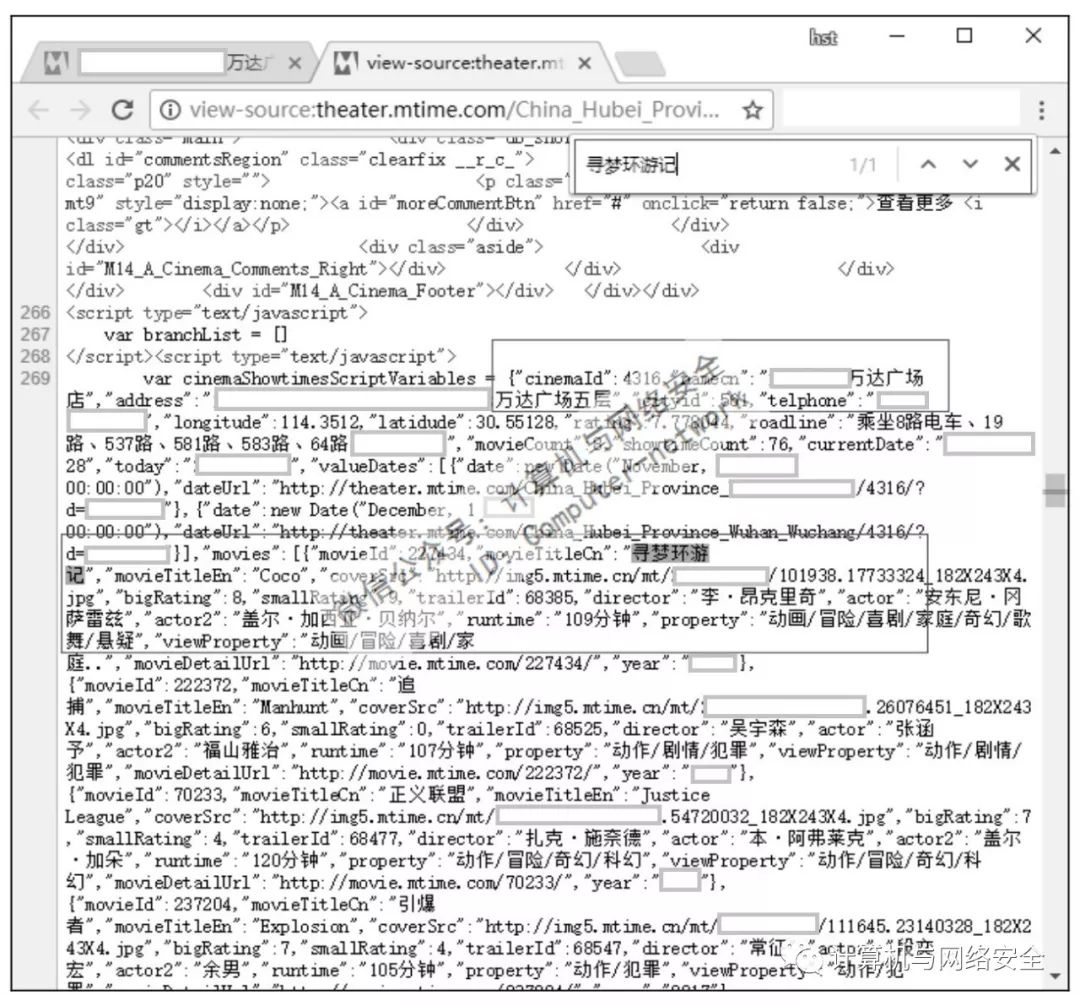
16 selector = response.xpath('/html/body/script[3]/text()')[0].extract( )
scrapy shell
http://theater.mtime.com/China_Hubei_Province_Wuhan_Wuchang/4316/
执行结果如图5所示。
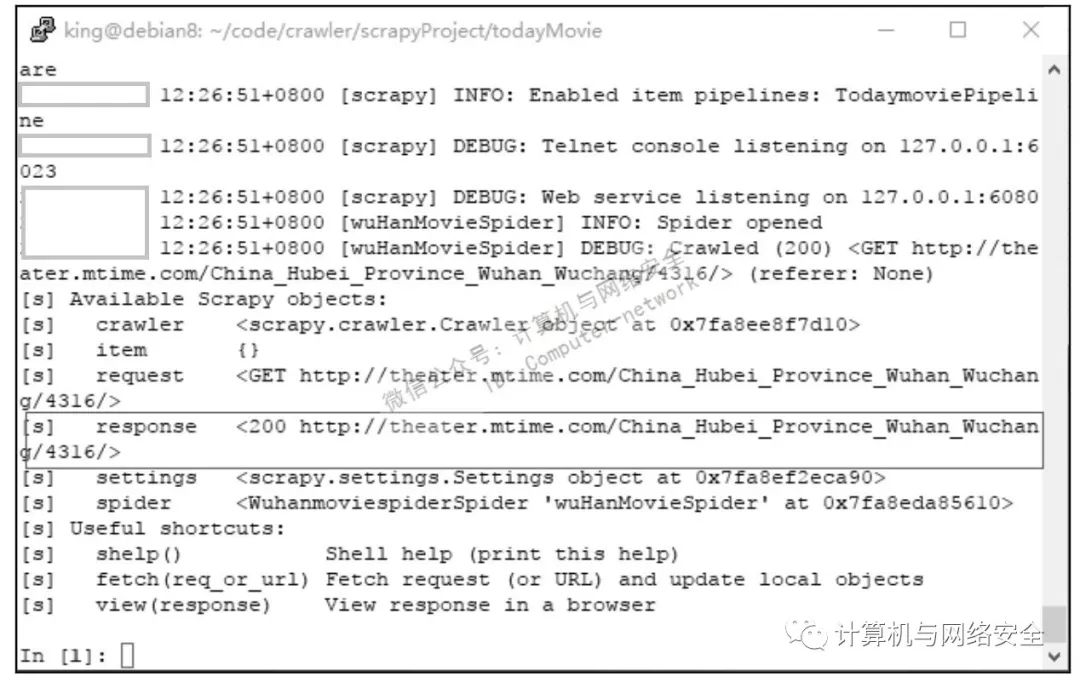
selector =
response.xpath('/html/body/script[3]/text()')
[0].extract()
print(selector)
执行结果如图6所示。

(3)保存爬取的结果pipelines.py
修改pipelines.py,内容如下:
1 # -*- coding: utf-8 -*-
2
3 # Define your item pipelines here
4 #
5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting
6 # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
7
8 import codecs
9 import time
10
11 class TodaymoviePipeline(object):
12 def process_item(self, item, spider):
13 today = time.strftime('%Y-%m-%d', time.localtime())
14 fileName = '武汉汉街万达广场店' + today + '.txt'
15 with codecs.open(fileName, 'a+', 'utf-8') as fp:
16 fp.write('%s %s %s %s \r\n'
17 %(item['movieTitleCn'],
18 item['movieTitleEn'],
19 item['director'],
20 item['runtime']))
21 # return item
scrapy crawl wuHanMovieSpider
结果却什么都没有?为什么呢?
(4)分派任务的settings.py
1 # -*- coding: utf-8 -*-
2
3 # Scrapy settings for todayMovie project
4 #
5 # For simplicity, this file contains only the most important settings by
6 # default. All the other settings are documented here:
7 #
8 # http://doc.scrapy.org/en/latest/topics/settings.html
9 #
10
11 BOT_NAME = 'todayMovie'
12
13 SPIDER_MODULES = ['todayMovie.spiders']
14 NEWSPIDER_MODULE = 'todayMovie.spiders'
15
16 # Crawl responsibly by identifying yourself (and your website) on the user-a gent
17 #USER_AGENT = 'todayMovie (+http://www.yourdomain.com)'
18
19 ### user define
20 ITEM_PIPELINES = {'todayMovie.pipelines.TodaymoviePipeline':300}
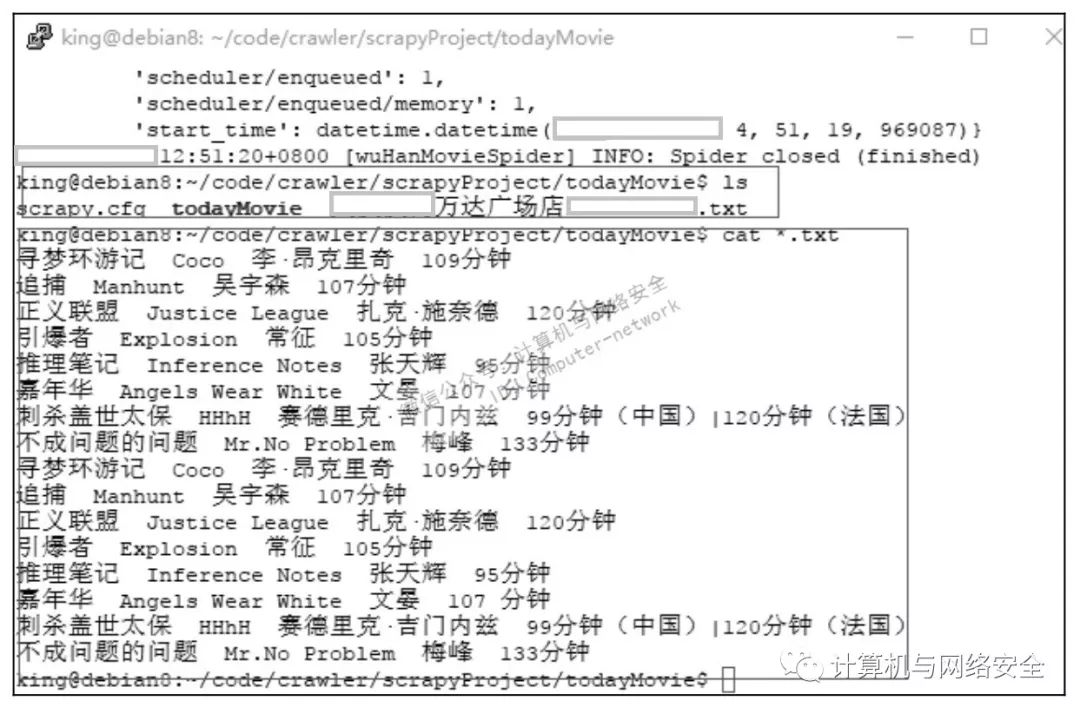
现在可以测试这个Scrapy爬虫了,还是执行命令:
scrapy crawl wuHanMovieSpider
ls
cat *.txt
执行结果如图7所示。
这个最简单的爬虫就到这里了。从这个项目可以看出,Scrapy爬虫只需要顺着思路照章填空就可以了。如果需要的项比较多,获取内容的网页源比较复杂或者不规范,可能会稍微麻烦点,但处理起来基本上都是大同小异的。与re爬虫相比,越复杂的爬虫就越能体现Scrapy的优势。
微信公众号:计算机与网络安全
ID:Computer-network




