图像配准的前世今生:从人工设计特征到深度学习
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作为计算机视觉的重要研究课题,图像配准经历了从传统方法走向深度学习的重要革命。本文将回顾图像配准技术的前世今生,为读者提供一个该领域的宏观视野。
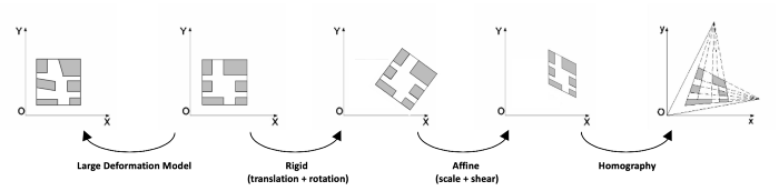
SIFT(Scale-invariant feature transform,尺度不变的特征变换)是用于关键点检测的原始算法,但是它并不能免费地被用于商业用途。SIFT 特征描述子对均衡的缩放,方向、亮度变化是保持不变的,对仿射形变也是部分不变的。
SURF(Speeded Up Robust Features,加速鲁棒特征)是受到 SIFT 深刻启发设计的检测器和描述子。与 SIFT 相比,它的运行速度要快好几倍。当然,它也是受专利保护的。
ORB(定向的 FAST 和旋转的 BRIEF)是基于 FAST(Features from Accelerated Segment Test)关键点检测器和 BRIEF(Binary robust independent elementary features)描述子的组合的快速二值描述子,具有旋转不变性和对噪声的鲁棒性。它是由 OpenCV Lab 开发的高效、免费的 SIFT 替代方案。
AKAZE(Accelerated-KAZE) 是 KAZE 的加速版本。它为非线性尺度空间提出了一种快速多尺度的特征检测和描述方法。它对于缩放和旋转也是具有不变性的,可以免费使用。
import numpy as npimport cv2 as cvimg = cv.imread('image.jpg')gray= cv.cvtColor(img, cv.COLOR_BGR2GRAY)akaze = cv.AKAZE_create()kp, descriptor = akaze.detectAndCompute(gray, None)img=cv.drawKeypoints(gray, kp, img)cv.imwrite('keypoints.jpg', img)

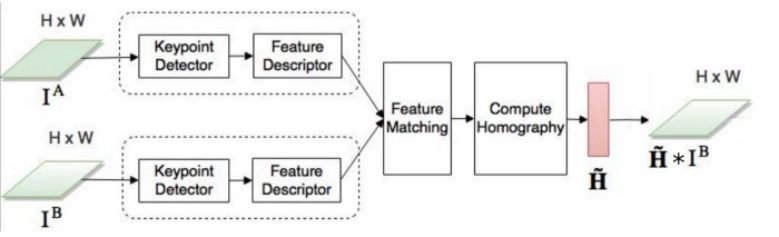
import numpy as npimport cv2 as cvimportmatplotlib.pyplot as pltimg1 = cv.imread('image1.jpg', cv.IMREAD_GRAYSCALE) # referenceImageimg2 = cv.imread('image2.jpg', cv.IMREAD_GRAYSCALE) # sensedImage# Initiate AKAZE detectorakaze = cv.AKAZE_create()# Find the keypoints and descriptors with SIFTkp1, des1 = akaze.detectAndCompute(img1, None)kp2, des2 = akaze.detectAndCompute(img2, None)# BFMatcher with default paramsbf = cv.BFMatcher()matches = bf.knnMatch(des1, des2, k=2)# Apply ratio testgood_matches = []for m,n in matches:if m.distance < 0.75*n.distance:good_matches.append([m])# Draw matchesimg3 = cv.drawMatchesKnn(img1,kp1,img2,kp2,good_matches,None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)cv.imwrite('matches.jpg', img3)

# Select good matched keypointsref_matched_kpts = np.float32([kp1[m[0].queryIdx].pt for m in good_matches]).reshape(-1,1,2)sensed_matched_kpts = np.float32([kp2[m[0].trainIdx].pt for m in good_matches]).reshape(-1,1,2)# Compute homographyH, status = cv.findHomography(ref_matched_kpts, sensed_matched_kpts, cv.RANSAC,5.0)# Warp imagewarped_image = cv.warpPerspective(img1, H, (img1.shape[1]+img2.shape[1], img1.shape[0]))cv.imwrite('warped.jpg', warped_image)

2014 年,Dosovitskiy 等人提出了通用特征学习方法「Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks」(https://arxiv.org/abs/1406.6909),仅使用无标签的数据来训练卷积神经网络。这些特征的泛化属性使得它们对变换是鲁棒的。这些特征(或称描述子),在匹配任务中要优于 SIFT 描述子。
2018 年,Yang 等人基于同样的思想研发了一种非刚性配准方法「Multi-temporal Remote Sensing Image Registration Using Deep Convolutional Features」(https://ieeexplore.ieee.org/document/8404075)。他们使用预训练的 VGG 网络层来生成能够同时保持卷积信息和定位能力的特征描述子。这些描述子似乎也要优于和 SIFT 类的描述子,尤其是在 SIFT 包含很多轮廓或者不能匹配到足够数目的特征点的情况下。


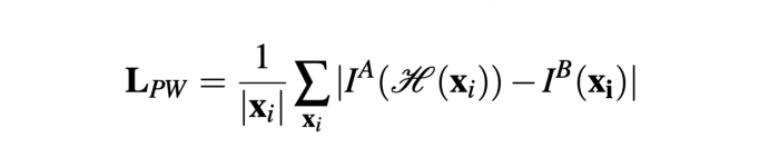
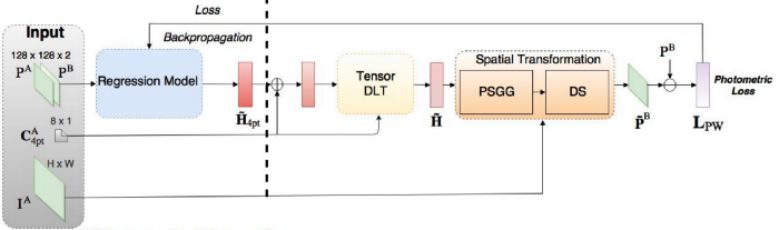
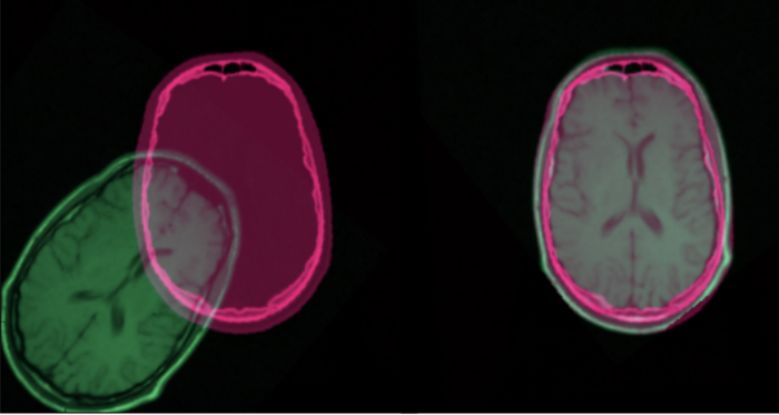
2016 年,Liao 等人首次在图像配准中使用强化学习。他们的方法(https://arxiv.org/pdf/1611.10336.pdf)是以用于端到端训练的贪婪监督算法为基础的。其目标是通过找到最佳的动作序列来对齐图像。虽然这种方法优于一些目前最先进的模型,但是它仅仅被用于刚性变换。
强化学习也被用在更加复杂的变换中。在论文「Robust non-rigid registration through agent-based action learning」(https://hal.inria.fr/hal-01569447/document)中,Krebs 等人使用了人工智能体来优化形变模型的参数。这个方法在前列腺核磁共振图像的受试者间配准上进行了测试,在 2D 和 3D 图像上都展现出了良好的效果。

第一个例子就是上文提及的 Krebs 等人的强化学习方法。
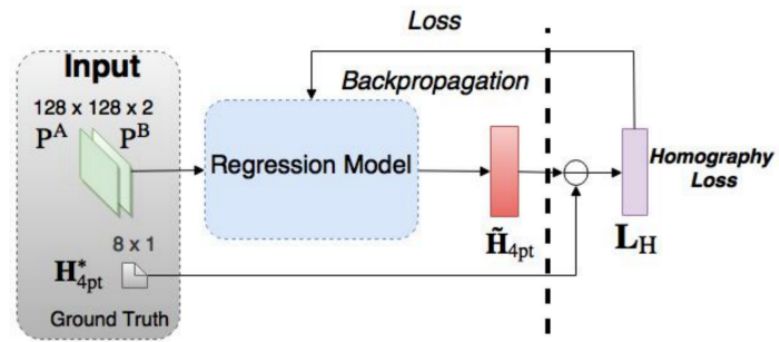
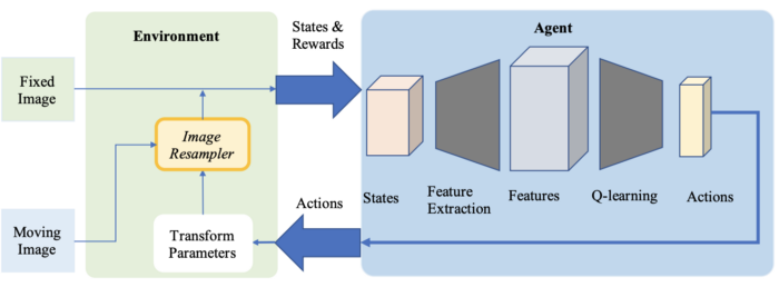
2017 年,De Vos 等人提出了 DIRNet。这是一个使用 CNN 来预测控制点的网格的神经网络,这些控制点能够被用来生成根据参考图像来对待配准图像进行变形的位移矢量场。
重磅!CVer学术交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!


