亿级订单数据的访问与储存,怎么实现与优化
今年以来,网络上时不时的就会传出“某某公司又裁员了,技术团队也被裁了”,其中不乏我们熟悉的一些大厂。
在这之后,市场上的“技术劳动力”又多了起来,而且这些“劳动力”中有相当一部分是有大型工程经验的,比如海量数据处理、高并发处理等经验。
对于求职者来说,竞争更加激烈了,在这个时刻,硬实力更显得尤为重要。
面试的时候,很可能会被问到海量数据的处理问题:
订单数据越来越多(亿级),查询越来越慢,如何处理?
分库分表会带来哪些副作用?可能的解决方式有哪些?
目前经常使用的关系型数据库如MySQL、SQL Server等,都是以“行”为单位进行存储,为了快速检索,也都采用了B树或其他索引技术。
从原理上来讲,表中的数据越多,索引树的范围越大,磁盘读取也越多,性能也就越低。
从实践角度来看,一般以百万到千万作为一个表的存储量级,超出该范围之后,性能就会下降,需要采用其他技术手段解决。
首先想到的就是能否将读和写分离,主数据库用于写入,读数据库(多个)用于对外提供查询,通过数据复制的方式将主数据库的数据同步到读库。该架构提升了数据库的读写能力,但对于主数据库的写入能力依然没法扩展。
其次,依据数据库分区的思路,可以将不同的数据分散到不同的库中,每个库存储的数据都不同,这样就可以将单一库的压力分散到多个库中,从而提升整个数据库的服务能力,这就是所说的分库分表技术。
若按照“字段(列)”分区,每个库/表存储不同的的字段,即schema不同,就是“垂直拆分”;
若按“数据记录(行)”分区,每个库/表的schema一致,但存储的数据不同,就是“水平拆分”。
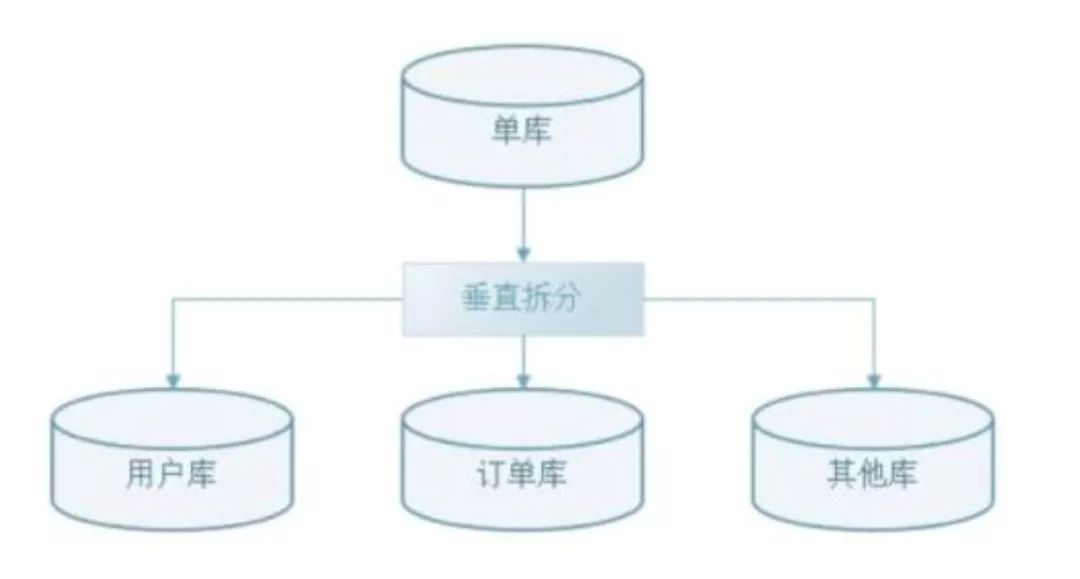
垂直拆分
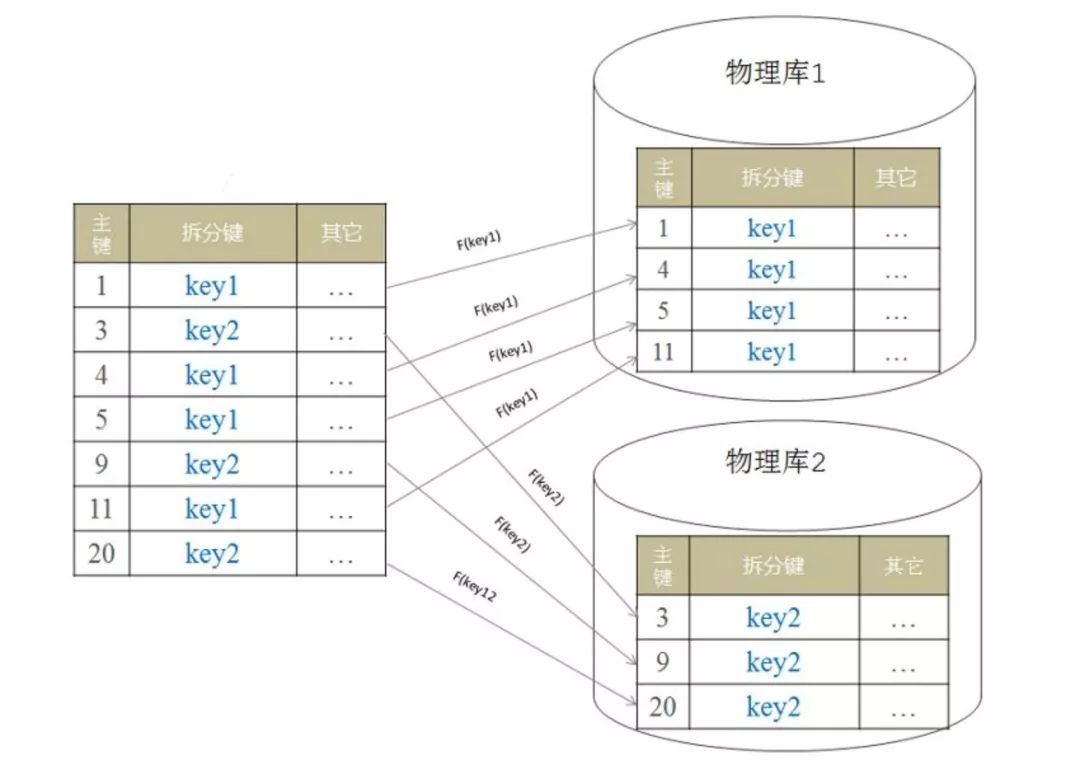
水平拆分
这样做的好处就是解决了数据存储容量的问题,但也带来了诸多弊端。这里以“水平拆分”为例来分析。
1.如何能做到数据的平均拆分,防止某一库压力过大?
系统开发者要结合业务特点来确定分库分表键,比如以userID为分库分表键,采用hash取模的方式将数据散列到不同的库中。
但并不是所有场景都适合用userID作为分库分表键的,若存在“大卖家”,则该userID可能有很多条记录,若简单的按照上述方法进行拆分,则可能打爆其中一个数据库。
一般来说,会将一段时间以前的数据归档(比如某个userID三个月之前的数据),存放到类似HBase这种非关系型数据库中,以此来解决上述问题。
2.分库分表之后就要求每个查询的where子句中必须携带分库分表键,但并非每个查询都能携带分库分表键的。
比如订单库按照订单号hash取模之后存储,此时分库分表键为订单号,那么想查询某位买家所有的订单,查询时就没有了分库分表键,就会出现“全表扫描”的情况。
一般在实践中解决这种问题的方法是建立“异构索引表”,即采用异步机制将原表内的每次一创建或更新,都换一个维度保存一份完整的数据表或索引表,拿空间换时间。
在上面说到,订单库按照订单号hash取模之后存储,同时也按照userID维度进行hash取模,再存储一份数据,那么想要获取某一userID的全部订单时,就将userID作为分库分表键传进去即可,避免了全表扫描。
上面这些是在海量数据处理过程中出现问题的解决思路,技术的突破需要依赖业务场景的需求和自身刻意的规划学习,二者缺一不可。但前者是机会,往往不是自己能完全把控的,如果在工作中没有实践场景,最好的办法就是系统的学习与梳理,待机会来临时才能一展身手。如果你对这些感兴趣,网易云课堂的两大福利就很适合你:
扫描网易小姐姐二维码领取

福利1
《网易云课堂Java进阶免费直播课》
适听人群:Java初、中级开发工程师
▼
1. 4月22日 20:00
网易框架封装之高并发缓存组件开发
2. 4月23日 20:00
华为内部分享 - 变量可见性&线程安全根因解密
3. 4月24日 20:00
网易云背后的技术 - 支撑10亿/秒请求背后的负载均衡体系
4. 4月25日 20:00
从0开始,一小时打造属于你的Spring框架
5. 4月26日 20:00
让你的系统无懈可击-Shiro企业级安全框架应用&原理源码解读
6. 4月27日 20:00
这些分布式ID生成策略,够你去BAT用了
7. 4月28日 20:00
网易单点登录SSO原理解密
福利2
Java开发进阶资料包
包含「Java开发参考书籍」「Java开发学习图谱」「大数据容器数据库架构技术文档」等
扫描下方二维码
即可免费参与Java直播进阶课程
并领取Java开发进阶资料包
全方位扩充你的知识体系
微信号:weizhuanye50
免费课程,名额有限,先到先得~~