机器如何猜你所想?阿里小蜜预测平台揭秘

阿里妹导读:阿里小蜜是2015年阿里发布的一款智能客服机器人。2017年双11期间,阿里小蜜的服务量达到643万,其中智能解决率达到95%,占整体服务量的95%。经过近几年的发展,能否更进一步解决智能客服机器人的压力成为当前我们思考的问题。今天,小蜜机器人实验室的市丸带领大家一起思考。
一、背景介绍
真实的服务链路中,阿里小蜜系列智能客服已经很大程度上减轻了人工客服的压力,但是能否更进一步解决智能客服机器人的压力成为当前我们思考的问题。因此我们启动了预测平台项目,通过人工智能技术在用户与机器人交互前对用户意图进行预测,并以主动或被动服务的方式帮助用户解决当前遇到问题。
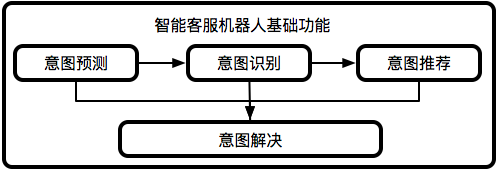
目前预测平台核心围绕两个能力建设,订单预测&问题预测。
订单预测:预测用户哪笔订单遇到了问题
阿里小蜜约70%的服务咨询都是与订单相关。
体验问题,不管是在线服务的订单选择器,还是热线服务让用户手动输入订单编号,体验都不太友善。
都不知道用户哪笔订单有问题,更何谈预测用户遇到了什么问题。
问题预测:预测用户遇到了什么样的问题
预测平台服务类预测的终极目标。
除此之外,我们还做了场景预测(预测用户是哪类问题,比如账户、物流、权益等等)、先验知识预测(正负向的一些pattern以及ranking)、用户预测(预测来电的号码是哪个淘宝id)等等。
二、落地产品介绍
预测平台经过半年多的发展,我们已经覆盖了阿里小蜜、店小蜜、热线小蜜、XSpace、万象等CCO的各个服务端产品,下面我们就举例看下几个已经落地的产品形态以及他们的效果。
阿里小蜜:
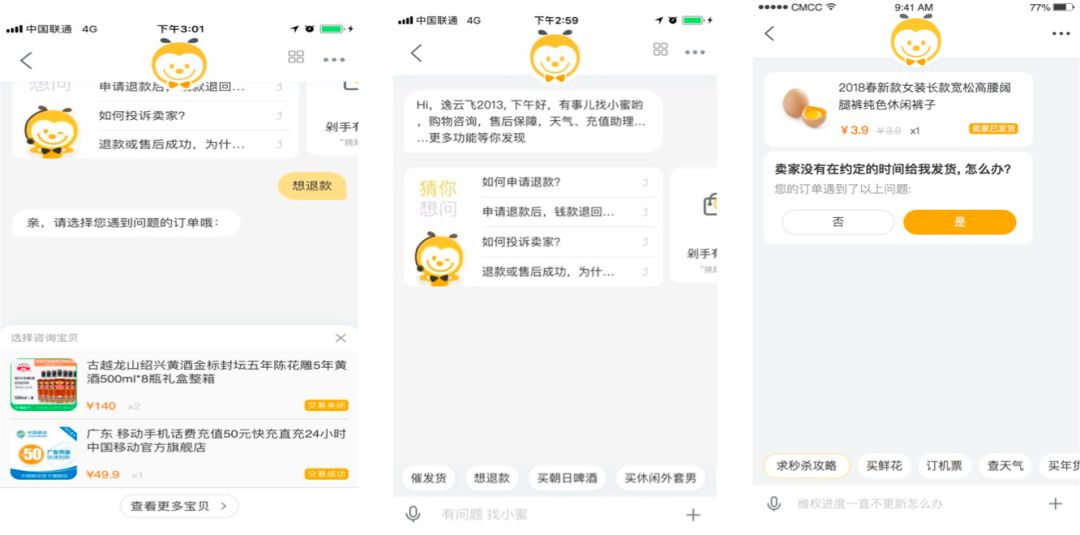
上图是阿里小蜜的落地场景,分别是订单预测,问题预测猜你想问形态和问题预测bot形态。
订单预测主要在各个订单选择器的入口,比如输入框旁边的“+”键、问题预测或者对话系统NLU识别到用户意图后部分需要用户先提供订单等场景,算法对用户订单列表做reranking。目前,无意图场景和有意图场景对比上线前点击率提升均约16%-20%浮动,点击部分满意度提升3.2%。
问题预测猜你想问形态,在用户各个渠道进入阿里小蜜后都会出现,目前部分场景优先做全覆盖策略,部分场景优先做高准确策略,前者点击率较上线前提高约2-3倍,后者点击率高于上线前近10倍。
问题预测bot形态,我们模型判断非常高准确部分以上图第三种形态呈现给用户,告诉用户是否XX订单有XX问题。目前这部分的有效率高于阿里小蜜整体有效率35个百分点,满意度也高3个点,但是覆盖率相对较低,仅3%。
除了阿里小蜜外,我们还覆盖了下面几个场景:
热线小蜜(热线智能客服机器人):用户进线优先反问用户是否遇到了“XXX问题”,如果是则播报解决方案,否的话走热线流程;当对话判断到意图后则会反问用户是否“XXX订单遇到了问题”,如果是则走SOP逻辑,否则请用户提供订单编号。目前订单预测已经全场景上线,90%的用户反馈正确,满意度提升7%。“问题预测”目前还在开发中,期待今年双十一给用户带来惊喜。
店小蜜(店铺智能客服机器人):产品形态类似阿里小蜜的猜你想问,近期刚完成全行售后知识预测的上线,售后部分点击率提升4%,解决率提升4%。
Xspace热线工作台(热线人工)。过往的热线人工服务,大部分小二都会需要用户手动在手机端输入订单号码,体验有点糟糕。目前通过订单预测,避免用户手动的输入,对大盘att降低6%+,覆盖部分ATT降低10%+,服务团队每天可多接千级电话服务,全年节省成本百万级。
万象(面向商家咨询的智能客服机器人)。产品形态也类似猜你想问。覆盖消保和交易场景,点击率提升4%,解决率提升4%。
三、算法技术介绍
目前算法部分的核心能力,如下图,不同的业务场景我们会组装不同的算法能力,比如热线的订单预测(用户识别+订单定位),在线小蜜的问题预测(意图分流+订单定位+召回预测+目标预测),每个子模块这里就不做过多的描述,本章节主要介绍其中的算法逻辑,具体落地方式参考第四章节。

预测/推荐,通常的算法技术主要通过分类问题或排序问题来解,之前我们也尝试了相对较基础的特征工程+RF的方式以及W&D的模型,另外上图的不同能力模块中,我们也尝试了label-lda/xgboost等算法,因为整个预测平台算法技术模块划分相对较多,今天我们的分享主要围绕问题预测进行,本章节我们核心介绍近几个月在问题预测方面的一些进展,具体当前线上的问题预测模型可以参考下面的表格(MV-DSSM正在对比中)。
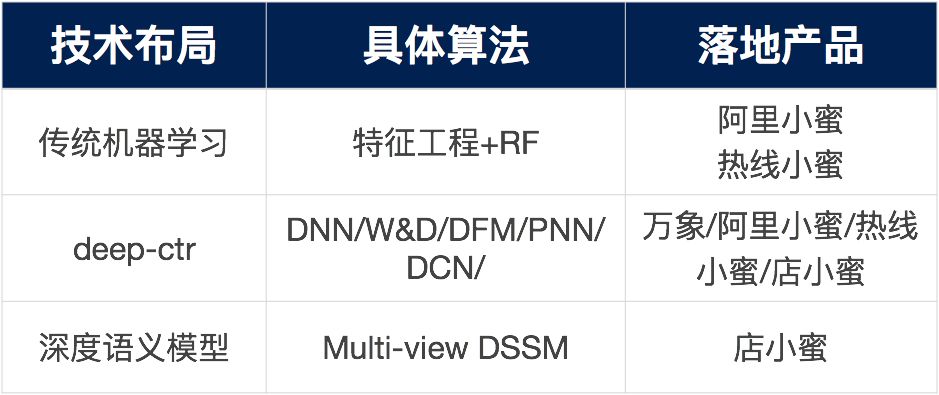
3.1 问题预测的base 模型
近几个月,我们核心围绕deep-ctr的方式支撑业务,具体在不同的业务中对比或上线了DeepFM、PNN(IPNN)、DCN三个模型。以DCN为例,作为对Wide & Deep的扩展,DCN模型可以有效学习大规模的稀疏和稠密特征,能够以较低的计算开销(参数较少),有效抓住特征间的交叉关系。下图为文献中网络结构图:
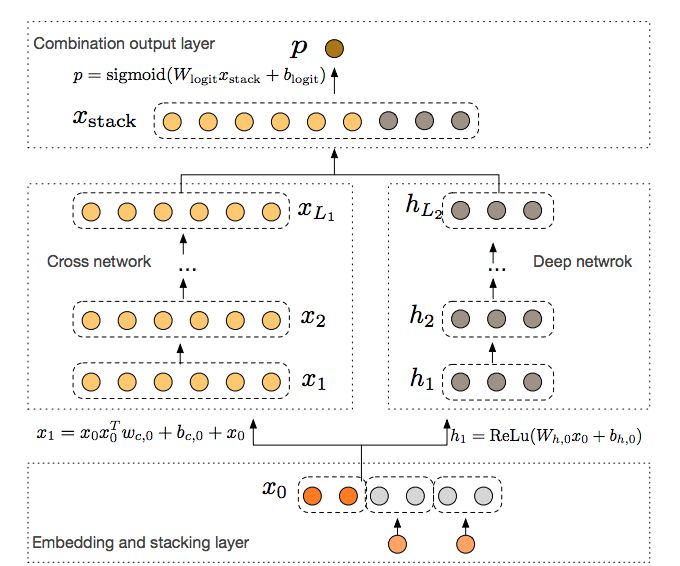
图片来源《Deep & Cross Network for Ad Click Predictions》Ruoxi Wang,2017。交叉网络结构形式中,每一层都是学习一个特征交叉映射f:ℝd→ℝd ,来拟合xl+1−xl 的残差。一方面,每一层学习的映射f 都是一个对交叉特征的非线性映射,然后通过拟合残差的方式,提高权重的敏感度,更适合稀疏的输入,同时另一方面,方便网络整体的反向传播,提高网络训练效率。右侧是一般的全连接层,是对原始输入特征的非线性映射,最后连接层是softmax。
此外,我们对DeepCTR系列算法做了一些改进。为了使DeepCTR模型更具通用性,我们参考了Kaggle竞赛:Mercari Price Suggesion中4th方案的做法,具体包括:
input层同时支持One-hot + Multi-hot特征;
使用2vect算法独立训练词向量;
加入文本embedding层;
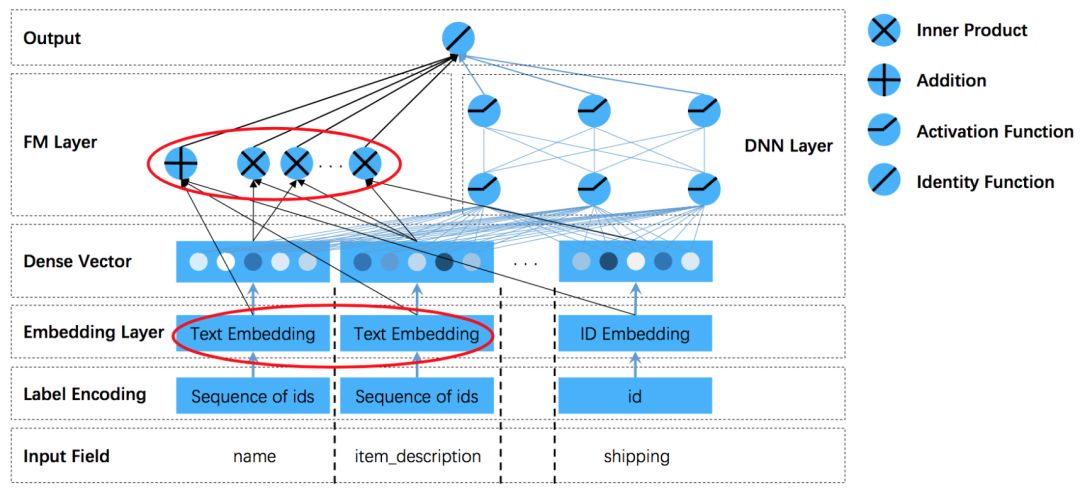
图片来自
ChenglongChen/tensorflow-XNN, https://github.com/ChenglongChen/tensorflow-XNN
3.2 强化学习
近期我们正在和计算平台的团队合作,基于deep-ctr的base模型(特征空间较大,但是训练时间较长更新较慢),结合drl做reranking(根据ctr-score以及实时线上的一些反馈数据,通过构建sequential的排序方式进行episode建模),强化点击率/解决率/满意率等目标。
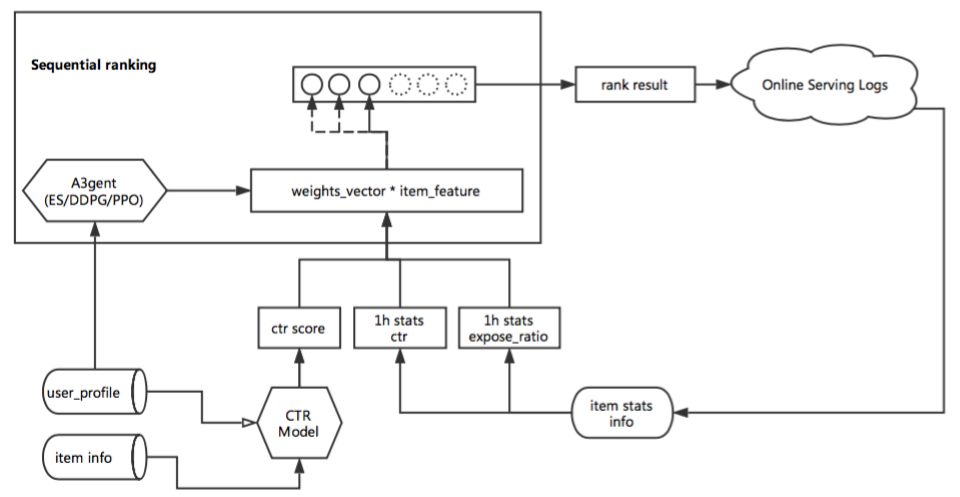
3.3 流计算
既然我们有了问题预测的能力,很容易联想到为什么我们要等用户进入我们的服务渠道我们才预测呢?为什么我们不在用户使用淘宝的时候实时监控用户日志,主动预测用户的问题并第一时间发送消息触达到用户,提醒用户来阿里小蜜我们可以帮助解决他的问题。这就需要借助流计算的能力。
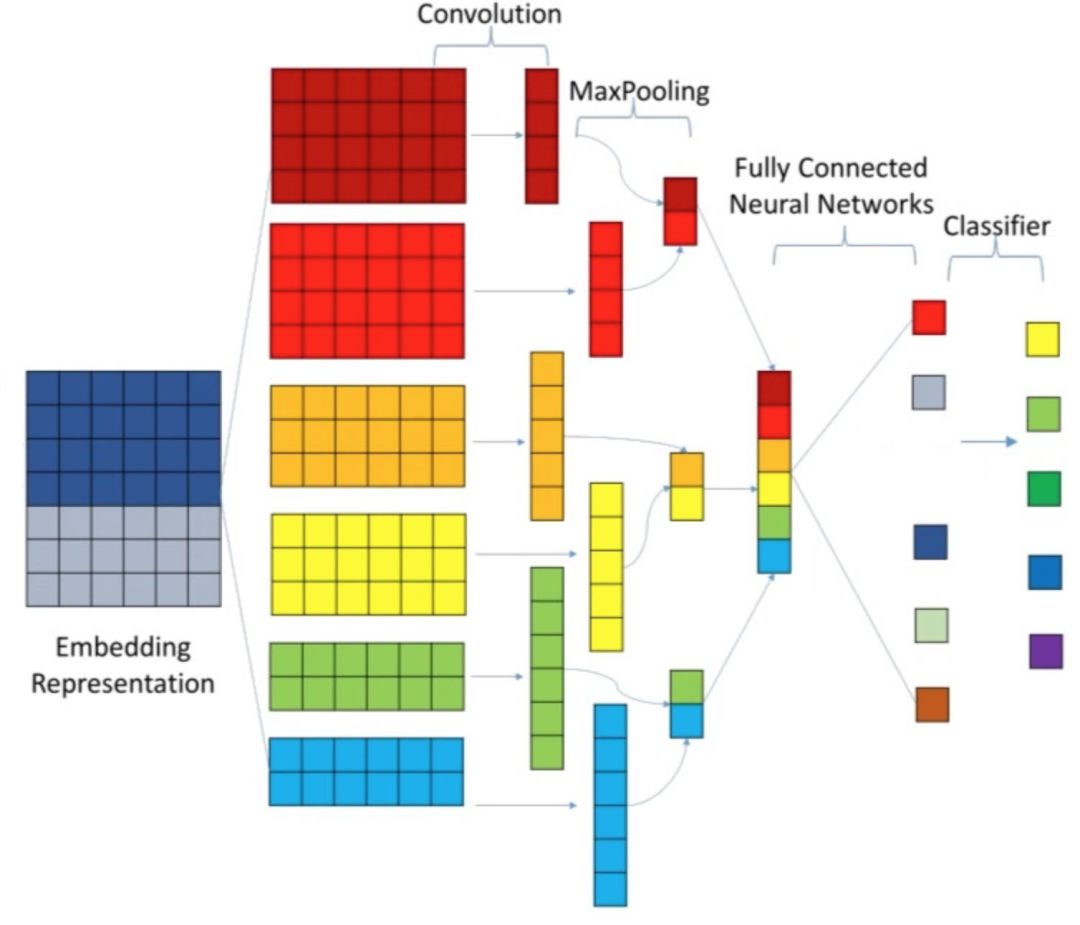
该模型目前对召回用户达到86.42%精确率;模拟全量用户实时计算主动服务场景,覆盖率为0.1%。TextCNN方法最先由《Convolutional Neural Networks for Sentence Classification》,Kim Yoon提出以解决文本情感分类问题。在工程领域普遍认为是LSTM等复杂序列化模型的替代。
根据我们提出的touch2vect的编码并结合改进的TextCNN序列数据做分类。首先基于海量用户的页面浏览路径,以及随之遇到的问题,无监督的挖掘背后的“语义信息”并保存为编码模型。在Embedding representation阶段,系统通过接入(手淘、天猫)实时浏览日志,将用户的序列化页面浏览路径(页面1>页面2>…>页面N)编码为二维向量作为输入,通过CNN提取序列化的隐含模式,最后让模型所激活的Top“问题/知识”作为预测结果。
目前这个子项目正在进行中,离线评测效果为召回1.5%的前提下,准确率86.3%。不使用rnn based的模型,一是因为rnn性能相对糟糕,况且在日志高QPS的前提下更加麻烦;二是因为目前第一版模型,以相对简单探索为主,避免模型太复杂影响调研结论,当然目前也已经开始打算尝试一些序列化的模型。
四、平台化方案介绍
随着早期快速的业务支撑落地拿结果,逐渐发现了以下一些瓶颈:
代码重复建设,阿里小蜜 、店小蜜、热线小蜜中代码重复开发,逻辑分散,业务无法快速响应。
模型评测逻辑分散,各算法工程师各自维护,重复开发,评测效率低。
算法服务管理分散,各算法工程师独立维护,无法统一管理和维护所有算法服务。
模型更新后,算法服务无法自动化更新,模型迭代效率不高。
因此,今年我们启动了整个平台化的进程。整体功能包含算法流式引擎、取数、特征工程、模型训练、算法灰度、在线评测、自动降级以及自动上线等,提供各类预测服务的一体化平台。当前阶段的重点工作主要在算法能力模块化(通过可串联、可编排的算法流式引擎,实现算法能力复用,快速响应业务,快速验证算法效果)、统一数据源及特征工程(可使算法同学专注算法实现,验证算法效果)、统一算法服务管理及模型评测(避免算法评测代码重复开发)、算法服务自动化更新(提升模型发布效率,保证模型的时效性)、线上推荐点击数据自动回流(通过线上数据反哺模型,提升模型效果)。
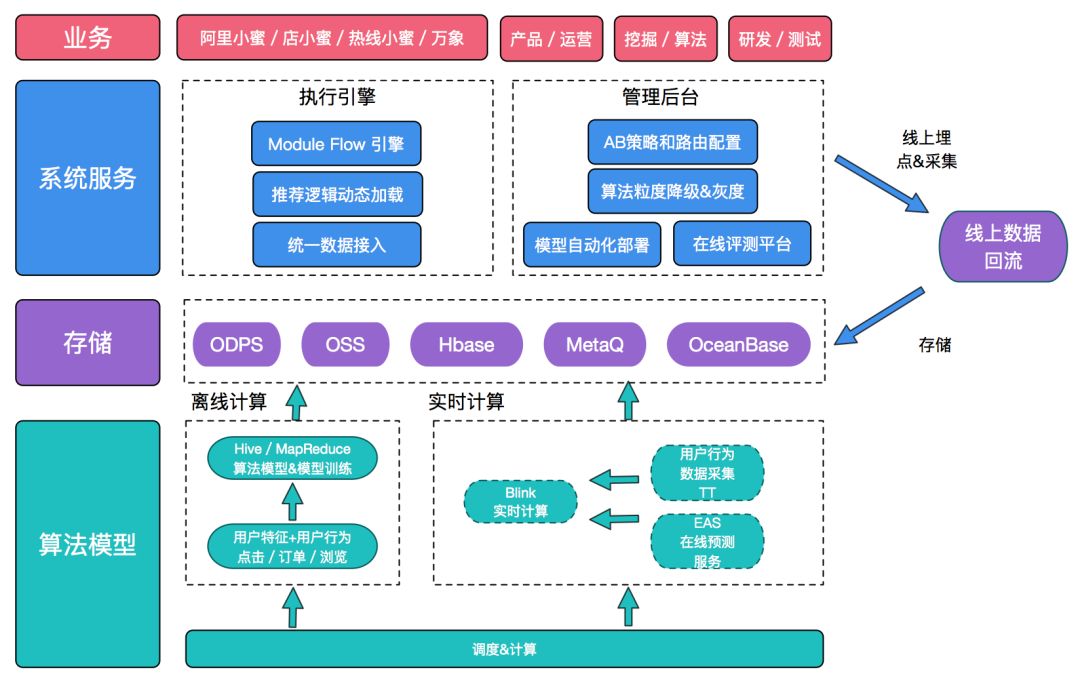
具体方案如上图,核心分为如下四个部分:
1.执行引擎串联预测流程,提供预测能力,通过组件化改造预测流程使系统有更好的扩展性,业务场景覆盖从之前的代码开发,改造为通过配置化支持。
2.离线计算部分,数据源主要来源于三部分,odps的离线+TT日志+TC等在线接口,一部分用于规则部分的计算,另一部分输出到odps用作离线训练和实时算法的输入数据。
3.实时计算部分,数据源主要来自于用户线上的实时日志数据,通过Blink和EAS服务进行实时计算,输出预测结果,一部分直接推送给终端用户,另一部分和用户进线后的预测结果进行整合。
4.预测平台管理后台,主要用于预测服务的运维光立,提供算法服务管理,预测流程Flow管理,支持算法自动上线,灰度调控,算法服务降级等。
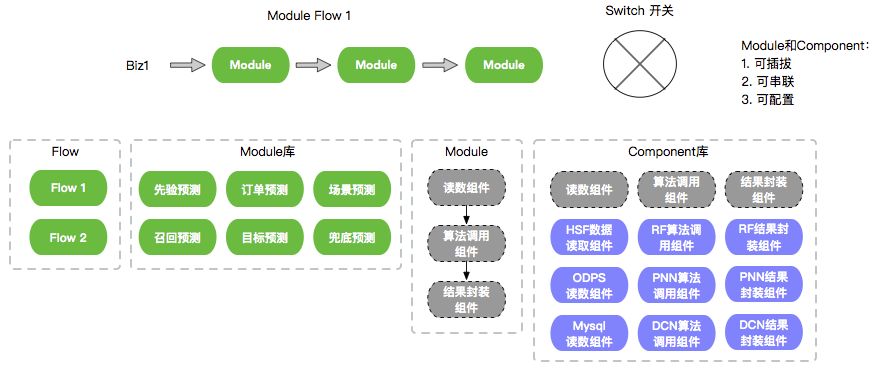
算法流式引擎方案如上图
Component:(调算法,取数,自定义处理)组件。开发者编码实现最多的地方。
Module:模块,一组Component的可选实现的顺序组合(串行)。
Switch:开关,条件、顺序、并发、重复、终止等逻辑判断和流程操作的执行器和调度者,用于连接各个上下游Module。开发者须在此做具体实现,支持N路开关(n in, m out)。
Flow:工作流,一组实现完整预测功能的Module和Switch的DAG组合。一个Module可以被多个flow共享(一次请求只执行一次)。
biz:业务,由多个可配置的工作流组成,支持一项问题预测业务的问题预测client的调用。client调用方只关心biz-id。
五、总结
作为一个平台化支持阿里小蜜家族的项目,目前已经落地了不少CCO touch服务的端,并且还在不断的努力中,真心感觉这一路大家亲密无间的并肩作战以及大家的付出。
最后打下招聘广告,阿里小蜜团队招聘NLP、推荐/预测相关算法同学,有意向欢迎邮件至:shiwan.ch@alibaba-inc.com

阿里巴巴数学大赛赛题、官方参考答案现已公布。
长按识别以下二维码,关注“阿里巴巴机器智能”公众号,回复“数学大赛”,即可下载哦。

↑ 翘首以盼等你关注

你可能还喜欢
点击下方图片即可阅读




关注「阿里技术」
把握前沿技术脉搏




