Self-Orthogonality Module:一个即插即用的核正交化模块

作者丨苏剑林
单位丨追一科技
研究方向丨NLP,神经网络
个人主页丨kexue.fm
前些天刷 arXiv 看到新文章 Self-Orthogonality Module: A Network Architecture Plug-in for Learning Orthogonal Filters(下面简称“原论文”),看上去似乎有点意思,于是阅读了一番,读完确实有些收获,在此记录分享一下。
给全连接或者卷积模型的核加上带有正交化倾向的正则项,是不少模型的需求,比如大名鼎鼎的 BigGAN 就加入了类似的正则项。而这篇论文则引入了一个新的正则项,笔者认为整个分析过程颇为有趣,可以一读。


为什么希望正交?
在开始之前,我们先约定:本文所出现的所有一维向量都代表列向量。那么,现在假设有一个 d 维的输入样本 ,经过全连接或卷积层时,其核心运算就是:
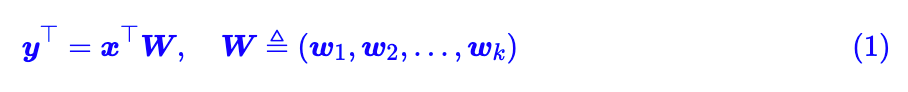
其中 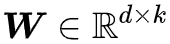
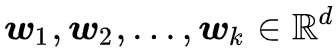

直观来看,可以认为 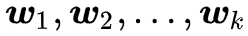
既然有 k 个视角,那么为了减少视角的冗余(更充分的利用所有视角的参数),我们自然是希望各个视角互不相关(举个极端的例子,如果有两个视角一模一样的话,那这两个视角取其一即可)。而对于线性空间中的向量来说,不相关其实就意味着正交,所以我们希望:

这便是正交化的来源。
常见的正交化方法
矩阵的正交化跟向量的归一化有点类似,但是难度很不一样。对于一个非零向量 w 来说,要将它归一化,只需要 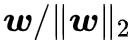
当然,一般来说我们也不是非得要严格的正交,所以通常的矩阵正交化的手段其实是添加正交化相关的正则项,比如对于正交矩阵来说我们有 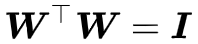

这里的范数 ||⋅|| 可以用矩阵 2 范数或矩阵 F 范数(关于矩阵范数的概念,可以参考深度学习中的Lipschitz约束:泛化与生成模型)。此外,上面这个正则项已经不仅是希望正交化了,而且同时还希望归一化(每个向量的模长为 1),如果只需要正交化,则可以把对角线部分给 mask 掉,即:

BigGAN 里边添加的就是这个正则项。
论文提出来的正则项
而原论文提出的也是一个新的正交正则项,里边包含一些有意思的讨论和推导,并做实验证明了它的有效性。
局部敏感哈希
原论文的出发点是如下的引理:
设 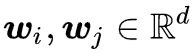
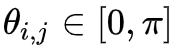
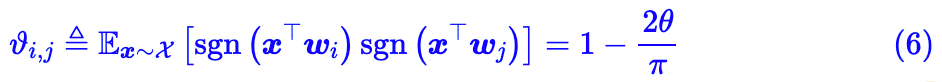
其中 sgn 是符号函数,即:
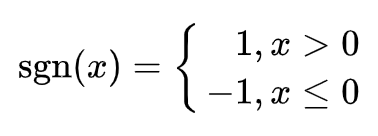
这个引理是关于余弦相似度的“局部敏感哈希”的直接推论,而局部敏感哈希(Locality Sensitive Hashing)则源自论文 Similarity Estimation Techniques from Rounding Algorithms,如果要追溯证明的话,可以沿着这条路线走。
乍看上去 (6) 就是一个普通的数学公式结论,但事实上它蕴含了更丰富的意义,它允许我们将两个实数连续向量的相似度(近似地)转化为两个二值向量(-1 和 1)的相似度。而转化为二值向量后,则相当于转化成为了一个“词-文档”矩阵,这允许我们建立索引来加速检索。换句话说,这能有效地提高实数连续向量的检索速度!
优化目标形式
直接看式 (6) 的定义,它的导数恒为 0,但我们可以得到它的某种光滑近似。假设我们已经得到了 ϑ 的某个光滑近似,那么我们就可以用它来构建正交正则项。原论文构建的正则项是:
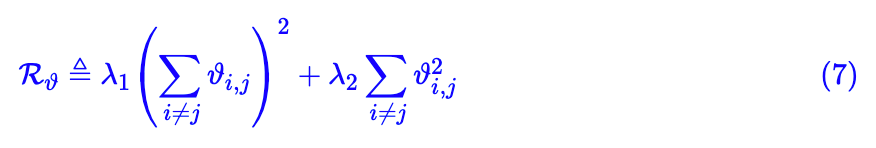
很明显,这个正则项希望 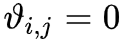
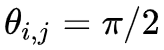
的均值为 0,而 λ2 则强硬一些,它希望所有的
都等于0。
考虑到实际问题可能比较复杂,我们不应当对模型进行过于强硬的约束,所以原论文让 λ1>λ2,具体值是 λ1=100, λ2=1。
插入到模型中
现在让我们来考虑 的实际估算问题。
首先,我们换一个角度来理解一下式 (6) 。假若我们采样 b 个样本 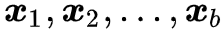
,就有:
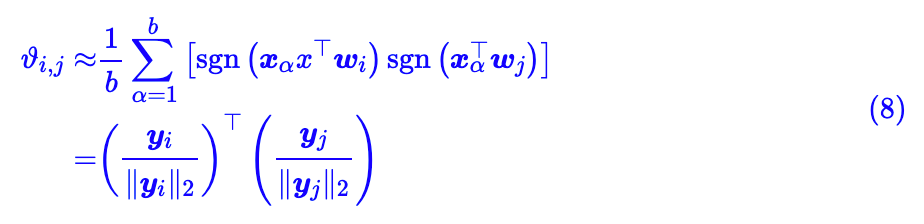
这里:
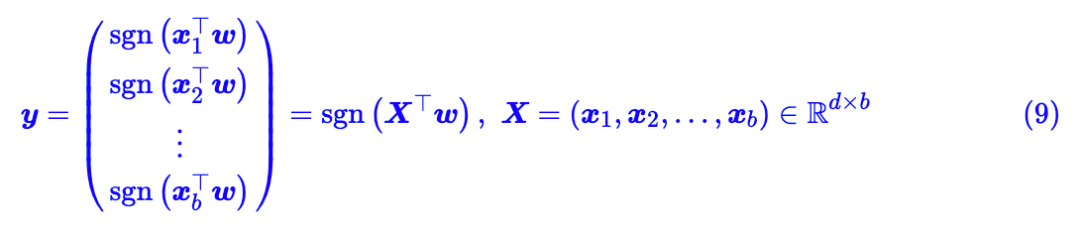
这个形式变换最巧的地方在于,由于 y 的元素不是 1 就是 -1,因此 y 的模长刚好就是 ,所以因子 1/b 刚好就等价于将
都归一化!
此外,值得提出的是,不管是(6)还是(8)其实都跟各 的模长没关系,因为 sgn(x)=sgn(|λ|x)。前面那个引理之所以要求在“单位超球面”上采样,只是为了强调采样方向(而不是模长)的均匀性。
理解到这里,我们就可以理清的 估计流程了:
估计流程:
1. 随机初始化一个 d×b 的矩阵(看成 b 个 d 维向量时,模长不限,方向尽量均匀);
2. 计算 ,得到两个 b 维向量,然后用 sgn 函数激活,然后各自做 l 2归一化,最后算内积;
3. 如果要求光滑近似的话,可以用 sgn(x)≈tanh(γx),原论文用了 γ=10。
X 怎么选好呢?原论文直接将它选择为当前 batch 的输入。回到 (1) ,一般来说,神经网络的输入就是一个 b×d 的矩阵,我们就可以把它当成 ,这时候 b 就是 batch size,而接下来神经网络会跟
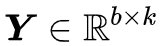
估计流程”中 k 个核向量
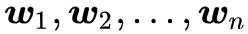
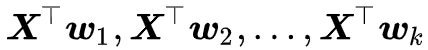
估计流程中的大部分计算量都省掉了,直接根据模型当前层的输出就可以估算了。
注:如果读者去看原论文,会发现原论文这部分的描述跟博客的描述不大一样(主要是原论文第三节 Experiments 上方两个段落),根据我对文章整体思路的理解,笔者认为原论文该段落的描述是错误的(主要是 D、d 的含义搞乱了),而博客中的写法才是正确的。
总的来说,最终估算 的方案是:
1. 当前层的输入 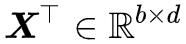
2. 对
3. 计算 ,得到 k × k 的矩阵,这就是所有的
。
4. 有了 之后,就可以代入式 (7) 算正则项了,由于正则项是利用模型自身的输出来构建的,所以称之为“自正交化正则项”。
跟BN的联系
另外,原论文中作者猜测,“在 b 的那一维(即 batch size 那一维)做 l2 归一化”这个操作跟 BN 有点类似,所以加了自正交化正则项后,模型或许可以不用加BN了。
个人认为这个猜测有点勉强,因为这个操作仅仅是在计算正则项时用到,并不影响模型正常的前向传播过程,因此不能排除 BN 的必要性。
此外,在本身的“ 估计流程”中,我们要求 X 各个向量的方向尽量均匀,但后面我们直接选取当前层的输入(的转置)作为 X ,无法有效地保证方向均匀,而加入 BN 后,理论上有助于让输入的各个向量方向更加均匀些,所以就更不能排除 BN 了。事实上,原论文的实验也并不完全支持作者这个猜测。
实验与个人分析
写了这么长,推导了一堆公式,总算把原论文中的正则项给推导出来了。接下来作者的确做了不少实验验证了这个正则项的有效性,总的结论就是确实能让核矩阵的向量夹角的分布更接近两两正交,此外还能带来一定的(微弱的)提升,而不是像已有的正交正则项那样只能保证正交却通常会掉点。
具体的实验结果请读者自己看原论文好了,放到这里也没有什么意思。此外尽管作者做了不少实验,但我还是觉得实验不够完善,因为作者大部分的实验做的都只是点云(point cloud)的实验,常规的分类实验就只做了 cifar-10,过于简略。
最后,那为什么这个正交正则项(似乎)会更有效呢?个人认为可能是新的正则项相对来说更柔和的结果,不管是 (4) 还是 (5) ,它们都是对单个内积(夹角)的惩罚,而原论文的 (7) 则是更倾向于从角度的分布这么一个整体视角来实现正交惩罚。此外,新的正则项涉及到了 tanh ,它存在饱和区,也就是意味着像 hinge loss 一样它会对惩罚做了一个截断,进一步使得惩罚更为柔和。
文章小结
本文主要简单介绍了一下最近 arXiv 上的一篇论文,论文指出已有正交正则项都并不能提高模型的准确率,所以作者引入了一个新的正交正则项,并且做了相应的评估,结论了自己的正则项不仅能促进正交,而且能带来一定的结果提升。
最后,由于笔者之前并没有了解过相关内容(尤其是前面的“局部敏感哈希”相关部分),只是偶然在 arXiv 上读到这篇论文,觉得颇有意思,遂来分享一翻,如有任何不当错漏之处,敬请读者理解并不吝指正。

点击以下标题查看作者其他文章:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客


