赛尔原创 | 文本摘要简述
作者:哈工大SCIR博士生冯夏冲
1. 简介
随着互联网产生的文本数据越来越多,文本信息过载问题日益严重,对各类文本进行一个“降 维”处理显得非常必要,文本摘要便是其中一个重要的手段。文本摘要旨在将文本或文本集合转换为包含关键信息的简短摘要。文本摘要按照输入类型可分为单文档摘要和多文档摘要。单文档摘要从给定的一个文档中生成摘要,多文档摘要从给定的一组主题相关的文档中生成摘要。按照输出类型可分为抽取式摘要和生成式摘要。抽取式摘要从源文档中抽取关键句和关键词组成摘要,摘要全部来源于原文。生成式摘要根据原文,允许生成新的词语、短语来组成摘要。按照有无监督数据可以分为有监督摘要和无监督摘要。本文主要关注单文档、有监督、抽取式、生成式摘要。
2. 抽取式摘要
2.1 传统方法
2.1.1 Lead-3
一般来说,作者常常会在标题和文章开始就表明主题,因此最简单的方法就是抽取文章中的前几句作为摘要。常用的方法为 Lead-3,即抽取文章的前三句作为文章的摘要。Lead-3 方法虽然简单直接,但却是非常有效的方法。
2.1.2 TextRank
TextRank 算法仿照 PageRank,将句子作为节点,使用句子间相似度,构造无向有权边。使用边上的权值迭代更新节点值,最后选取 N 个得分最高的节点,作为摘要。
2.1.3 聚类
将文章中的句子视为一个点,按照聚类的方式完成摘要。例如 Padmakumar and Saran [11] 将文章中的句子使用 Skip thought vectors 和 Paragram embeddings 两种方式进行编码,得到句子级别的向量表示,再使用 K 均值聚类和 Mean-Shift 聚类进行句子聚类,得到 N 个类别。最后从每个类别中,选择距离质心最近的句子,得到 N 个句子,作为最终摘要。
2.2 序列标注方式
抽取式摘要可以建模为序列标注任务进行处理,其核心想法是:为原文中的每一个句子打一个二分类标签(0 或 1),0 代表该句不属于摘要,1 代表该句属于摘要。最终摘要由所有标签为 1 的句子构成。
2.2.1 序列标注摘要基本框架
将文本摘要建模为序列标注任务的关键在于获得句子的表示,即将句子编码为一个向量,根据该向量进行二分类任务,例如 AAAI17 中,Nallapati 等人[10]的工作,使用双向 GRU 分别建模词语级别和句子级别的表示。其模型 SummaRuNNer 如图 1所示。蓝色部分为词语级别表示,红色部分为句子级别表示,对于每一个句子表示,有一个 0、1 标签输出,指示其是否是摘要。
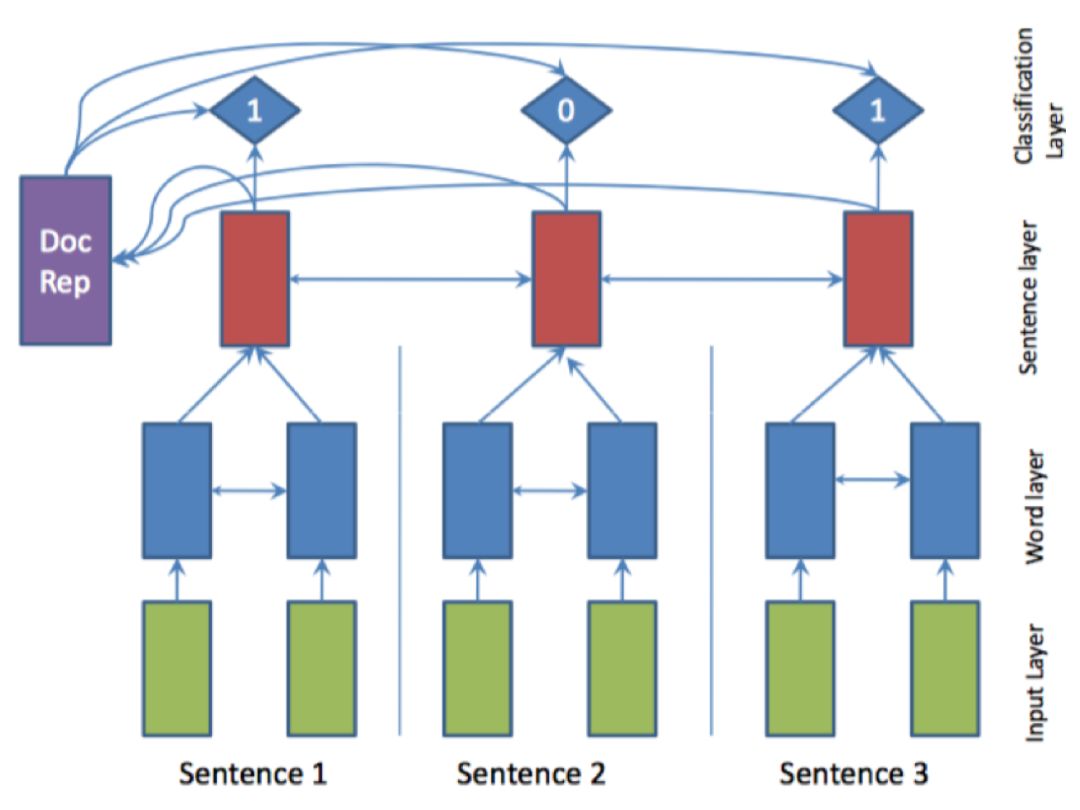
图1 SummaRuNNer 模型
该模型的训练需要监督数据,现有数据集往往没有对应的句子级别的标签,因此需要通过启发式规则进行获取。具体方法为:首先选取原文中与标准摘要计算 ROUGE 得分最高的一句话加入候选集合,接着继续从原文中进行选择,保证选出的摘要集合 ROUGE 得分增加,直至无法满足该条件。得到的候选摘要集合对应的句子设为 1 标签,其余为 0 标签。
2.2.2 序列标注结合Seq2Seq
抽取式摘要还可以在序列标注的基础上结合 Seq2Seq 和强化学习完成。ACL18 中,Zhang等人[14]在序列标注的基础上,使用 Seq2Seq 学习一个句子压缩模型,使用该模型来衡量选择句子的好坏,并结合强化学习完成模型训练。其模型 Latent 如图 2所示。
该方法的核心关注点是:摘要数据集往往没有对应的句子级别的标签,需要通过启发式规则获取,然而仅仅利用这些标签训练模型会丢失很多标准摘要中重要的信息。因此 Latent 模型不采用序列标注方法计算标签级别的损失来训练模型,而是将序列标注作为中间的步骤。在得到序列标注的概率分布之后,从中采样候选摘要集合,与标准摘要对比计算损失,可以更好地利用标准摘要中的信息。
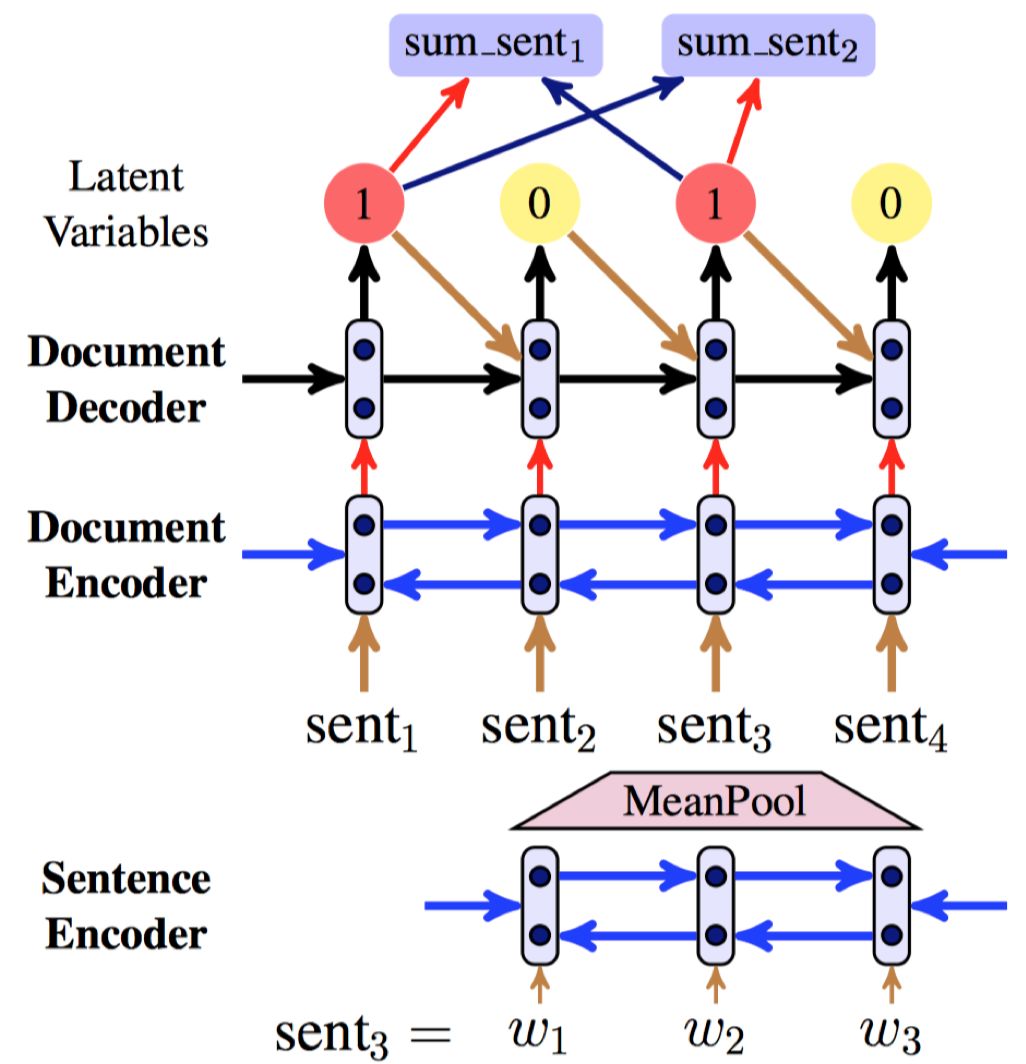
图2 Latent 模型
2.3 Seq2Seq方式
之前的抽取式摘要往往建模句子级别的表示,忽略了关键词的作用。ACL18 中,Jadhav and Rajan等人[5]直接使用 Seq2Seq 模型来交替生成词语和句子的索引序列来完成抽取式摘要任务。其模型 SWAP-NET 在解码的每一步,计算一个 Switch 概率指示生成词语或者句子。最后解码出的是词语和句子的混合序列。最终摘要由产生的句子集合选出。除了考虑生成句子本身的概率之外,还需要考虑该句是否包含了生成的词语,如果包含,则得分高,最终选择 top k 句作为摘要。
2.4 句子排序方式
抽取式摘要还可以建模为句子排序任务完成,与序列标注任务的不同点在于,序列标注对于每一个句子表示打一个 0、1 标签,而句子排序任务则是针对每个句子输出其是否是摘要句的概率,最终依据概率,选取 top k 个句子作为最终摘要。虽然任务建模方式(最终选取摘要方式)不同,但是其核心关注点都是对于句子表示的建模。
2.4.1 句子排序结合新的打分方式
之前的模型都是在得到句子的表示以后对于句子进行打分,这就造成了打分与选择是分离的,先打分,后根据得分进行选择。没有利用到句子之间的关系。在 ACL18 中,Zhou 等人[15]提出了一种新的打分方式,使用句子受益作为打分方式,考虑到了句子之间的相互关系。其模型 NeuSUM 如图 3所示。
句子编码部分与之前基本相同。打分和抽取部分使用单向 GRU 和双层 MLP 完成。单向 GRU 用于记录过去抽取句子的情况,双层 MLP 用于打分。打分如下公式所示。
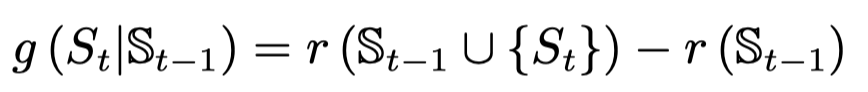
其中 r 代表 ROUGE 评价指标,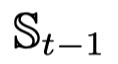
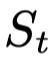
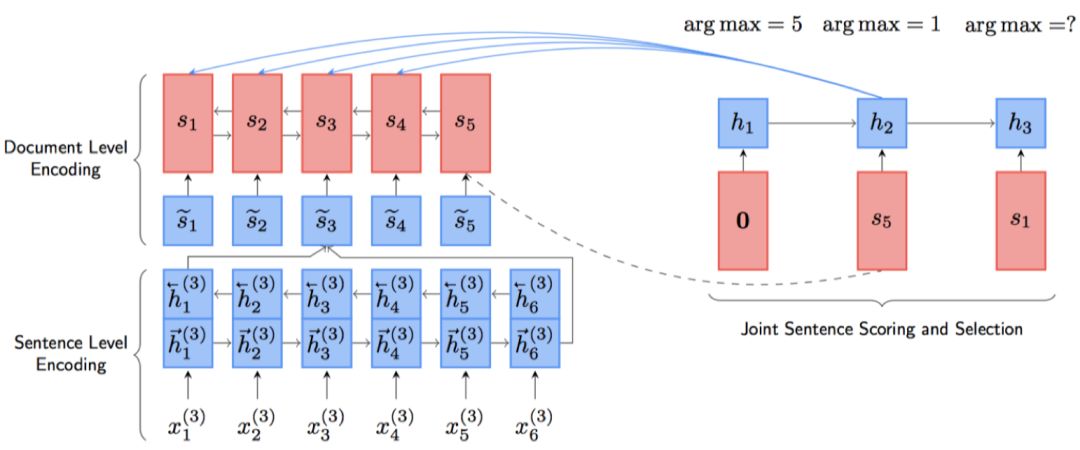
图3 NeuSUM 模型
因此在打分和选择部分,逐步选择使得 g 最高的句子,直到无法满足该条件或者达到停止条件为止。集合 S 为最终摘要。
3. 生成式摘要
抽取式摘要在语法、句法上有一定的保证,但是也面临了一定的问题,例如:内容选择错误、连贯性差、灵活性差等问题。生成式摘要允许摘要中包含新的词语或短语,灵活性高,随着近几年神经网络模型的发展,序列到序列(Seq2Seq)模型被广泛的用于生成式摘要任务,并取得一定的成果。
仅使用 Seq2Seq 来完成生成式摘要存在如下问题:(1)未登录词问题(OOV),(2)生成重复。现在被广泛应用于生成式摘要的框架由 See 等人[13]在 ACL17 中提出,在基于注意力机制的 Seq2Seq 基础上增加了 Copy 和 Coverage 机制,有效的缓解了上述问题。其模型 pointer-generator 网络如图 4所示。
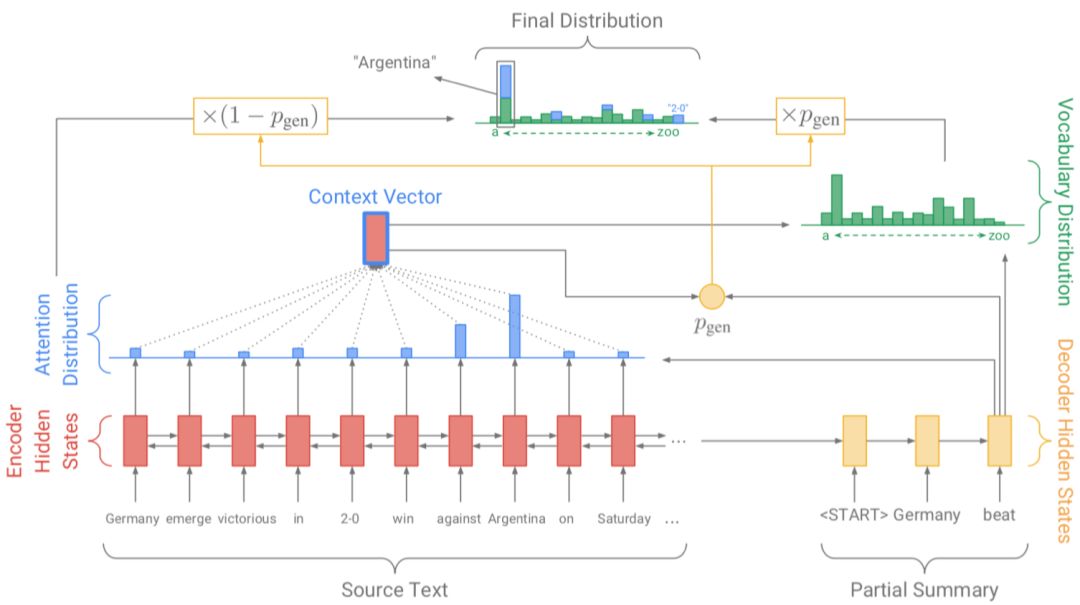
图4 Pointer-Generator 模型
其模型基本部分为基于注意力机制的 Seq2Seq 模型,使用每一步解码的隐层状态与编码器的隐层状态计算权重,最终得到 context 向量,利用 context 向量和解码器隐层状态计算输出概率。
利用 Copy 机制,需要在解码的每一步计算拷贝或生成的概率,因为词表是固定的,该机制可以选择从原文中拷贝词语到摘要中,有效的缓解了未登录词(OOV)的问题。
利用 Coverage 机制,需要在解码的每一步考虑之前步的 attention 权重,结合 coverage 损失, 避免继续考虑已经获得高权重的部分。该机制可以有效缓解生成重复的问题。
基于该框架可以做出一些改进,在 ICLR18 中,Paulus 等人[12],在该框架的基础上又使用解码器注意力机制结合强化学习来完成生成式摘要。
基于上述 Coverage 机制,在 EMNLP18 中,Li 等人[8]基于句子级别的注意力机制,使用句子级别的 Coverage 来使得不同的摘要句可以关注不同的原文,缓解了生成信息重复的问题。
3.1 利用外部信息
除上述问题以外,基于 Seq2Seq 的模型往往对长文本生成不友好,对于摘要来说,更像是一种句子压缩,而不是一种摘要。因此在 ACL18 中,Cao 等人[1],使用真实摘要来指导文本摘要的生成。其核心想法在于:相似句子的摘要也具有一定相似度,将这些摘要作为软模板,作为外部知识进行辅助。其模型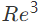
Retrieve 部分主要检索相似句子,获得候选摘要。Rerank 部分用于排序候选模板,在训练集中,计算候选与真实摘要的 ROUGE 得分作为排序依据,在开发集与测试集中,使用神经网络计算得分作为排序依据。训练过程中,使得预测得分尽可能与真实得分一致。Rewrite 部分,结合候选模板与原文生成摘要。
3.2 多任务学习
除了将本身数据集的信息作为一种外部知识以外,在 ACL18 中,Guo 等人[3]将摘要生成作为主任务,问题生成、蕴含生成作为辅助任务进行多任务学习。问题生成任务需要根据给定的文本和答案生成问题,要求模型具有选择重要信息的能力,蕴含生成任务要求根据给定文本,有逻辑地推出输出文本,要求模型具有逻辑推理能力。在文本摘要中,定位原文中的关键信息是核心问题,根据原文生成摘要又要求模型具有一定的逻辑推理能力,使得生成的摘要与原文不违背,无矛盾。
3.3 生成对抗方式
在 AAAI18 中,Liu 等人[9]利用 SeqGAN[14] 的思想,利用生成模型 G 来生成摘要,利用判别模型 D 来区分真实摘要与生成摘要。使用强化学习的方法,更新参数。
4. 抽取生成式摘要
抽取式、生成式摘要各有优点,为了结合两者的优点,一些方法也同时使用抽取结合生成的方法来完成摘要任务。
在生成式摘要中,生成过程往往缺少关键信息的控制和指导,例如 pointer-generator 网络在 copy 的过程中,无法很好地定位关键词语,因此一些方法首先提取关键内容,再进行摘要生成。
从直觉上来讲,摘要任务可以大致分为两步,首先选择重要内容,其次进行内容改写。在 EMNLP18 中,Gehrmann 等人[2]基于这种想法,提出了“Bottom Up”方式的摘要, 首先使用“content selector”选择关键信息,其次使用 pointer-generator 网络生成摘要。
内容选择部分建模为词语级别序列标注任务,该部分的训练数据通过将摘要对齐到文档,得到词语级别的标签。摘要生成部分使用 pointer-generator 网络,使用内容选择部分计算的概率修改原本 attention 概率,使得解码器仅关注选择的内容。
除了上述以序列标注方式来选择关键词的方法以外,在 NAACL18 中,Li 等人[6]使用 TextRank 算法获得关键词,之后使用神经网络获得关键词语的表示,并将该表示结合 pointergenerator 网络生成摘要。
上述方法从原文中选择重要的部分用来指导摘要的生成,显式地利用了文本级别的信息,在 EMNLP18 中,Li 等人[7],使用门控机制,从编码得到的向量表示中选择有用的信息用于之后的摘要生成,属于一种 Soft 方式。在使用层次化 encoder 得到句子级别的向量表示之后,使用门控机制,得到新的句子级别向量,表示从中选择有用信息。其模型 InfoSelection 如图 5所示。
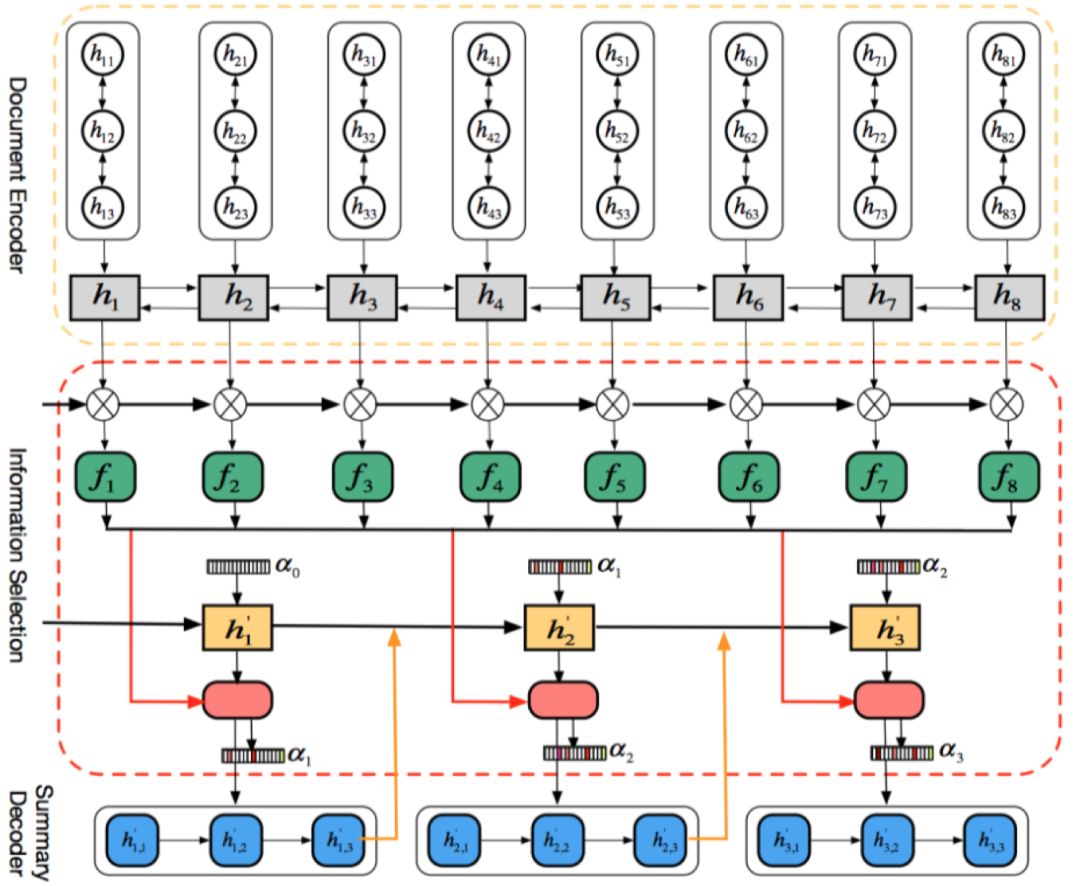
图 5 InfoSelection 模型
在 ACL18 中,Hsu 等人[4]将抽取式模型的输出概率作为句子级别的 attention 权重, 用该权重来调整生成式模型中的词语级别的 attention 权重,如图 6所示,其核心想法为:当词语级别的 attention 权重高时,句子级别的 attention 权重也高。基于此想法提出了 Inconsistency 损失函数,使得模型输出的句子级别的权重和词语级别的权重尽量一致。在最终训练时,首先分别预训练抽取式和生成式模型,之后有两种方式来结合两个模型,Hard 方式:将抽取式模型抽出的关键句直接作为生成式模型的输入;Soft 方式:将抽取式模型的的输出概率用来调整词语级别的权重。
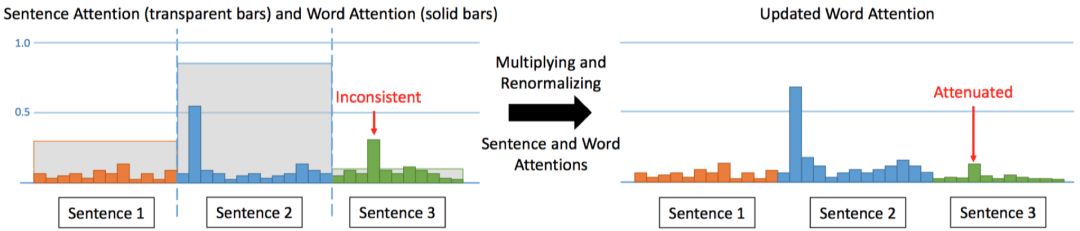
图6 权重调整过程
5. 数据集
常用的文本摘要数据集有 DUC 数据集、New York Times 数据集、CNN/Daily Mail 数据集、 Gigaword 数据集、LCSTS 数据集。
由于 DUC 数据集规模较小,因此神经网络模型往往在其他数据集上进行训练,再在 DUC 数据集上进行测试。
NYT 数据集包含了发表于 1996 至 2007 年期间的文章,摘要由专家编写而成。该数据集的摘要有时候不是完整的句子,并且长度较短,大约平均 40 个词语。
目前广泛使用的是 CNN/Daily Mail 数据集,属于多句摘要数据集,常用于训练“生成式”摘要系统。该数据集一共有两个版本,匿名(Anonymized)版本和未匿名(Non-anonymized)版本,未匿名版本包括了真实的实体名(Entity names),匿名版本将实体使用特定的索引进行替换。
Gigaword 数据集摘要由文章第一句话和题目结合启发式规则构成。
LCSTS 为中文短文本摘要数据集,由新浪微博构建得到。
6. 总结
参考文献
[1] Ziqiang Cao, Wenjie Li, Sujian Li, and Furu Wei. Retrieve, rerank and rewrite: Soft template based neural summarization. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pages 152–161, 2018.
[2] Sebastian Gehrmann, Yuntian Deng, and Alexander M Rush. Bottom-Up Abstractive Summarization. EMNLP, 2018.
[3] Han Guo, Ramakanth Pasunuru, and Mohit Bansal. Soft layer-specific multi-task summarization with entailment and question generation. arXiv preprint arXiv:1805.11004, 2018.
[4] Wan-Ting Hsu, Chieh-Kai Lin, Ming-Ying Lee, Kerui Min, Jing Tang, and Min Sun. A unified model for extractive and abstractive summarization using inconsistency loss. arXiv preprint arXiv:1805.06266, 2018.
[5] Aishwarya Jadhav and Vaibhav Rajan. Extractive summarization with swap-net: Sentences and words from alternating pointer networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pages 142–151, 2018.
[6] Chenliang Li, Weiran Xu, Si Li, and Sheng Gao. Guiding generation for abstractive text summarization based on key information guide network. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), volume 2, pages 55–60, 2018a.
[7] Wei Li, Xinyan Xiao, Yajuan Lyu, and Yuanzhuo Wang. Improving neural abstractive document summarization with explicit information selection modeling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1787–1796, 2018b.
[8] Wei Li, Xinyan Xiao, Yajuan Lyu, and Yuanzhuo Wang. Improving neural abstractive document summarization with structural regularization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4078–4087, 2018c.
[9] Linqing Liu, Yao Lu, Min Yang, Qiang Qu, Jia Zhu, and Hongyan Li. Generative adversarial network for abstractive text summarization. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[10] Ramesh Nallapati, Feifei Zhai, and Bowen Zhou. Summarunner: A recurrent neural network based sequence model for extractive summarization of documents. In Thirty-First AAAI Conference on Artificial Intelligence, 2017.
[11] Aishwarya Padmakumar and Akanksha Saran. Unsupervised text summarization using sentence embeddings.
[12] Romain Paulus, Caiming Xiong, and Richard Socher. A Deep Reinforced Model for Abstractive Summarization. CoRR, 2017.
[13] Abigail See, Peter J Liu, and Christopher D Manning. Get to the point: Summarization with pointer-generator networks. arXiv preprint arXiv:1704.04368, 2017.
[14] Lantao Yu, Weinan Zhang, Jun Wang, and Yong Yu. Seqgan: Sequence generative adversarial nets with policy gradient. In Thirty-First AAAI Conference on Artificial Intelligence, 2017. Xingxing Zhang, Mirella Lapata, Furu Wei, and Ming Zhou. Neural latent extractive document summarization. arXiv preprint arXiv:1808.07187, 2018.
[15] Qingyu Zhou, Nan Yang, Furu Wei, Shaohan Huang, Ming Zhou, and Tiejun Zhao. Neural document summarization by jointly learning to score and select sentences. arXiv preprint arXiv:1807.02305, 2018.
本期责任编辑:张伟男
本期编辑:赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。



