PaddlePaddle首次曝光全景图和中文名“飞桨”,发布11项重大更新

除此之外,百度深度学习技术平台部总监马艳军还发布了 PaddlePaddle 新版本的 11 项重大功能更新,包括开发、训练、预测等环节,并宣布“1 亿元”AI Studio 算力支持计划,为开发者提供价值一亿元的免费算力。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
2016 年,百度深度学习框架 PaddlePaddle 正式开源,成为中国首个也是目前国内唯一开源开放的端到端深度学习平台。据马艳军透露,PaddlePaddle 现已覆盖 10 万开发者,主要为企业用户。
PaddlePaddle 最新版本 GitHub 地址:
https://github.com/PaddlePaddle/Paddle/blob/develop/README_cn.md
发布会上,PaddlePaddle 首次对外公布全景图:

(PaddlePaddle 全景图)
此外,PaddlePaddle 今后将有一个中文名——飞桨,意为快速划动的桨,寓意期望这个平台能够实现快速成长。
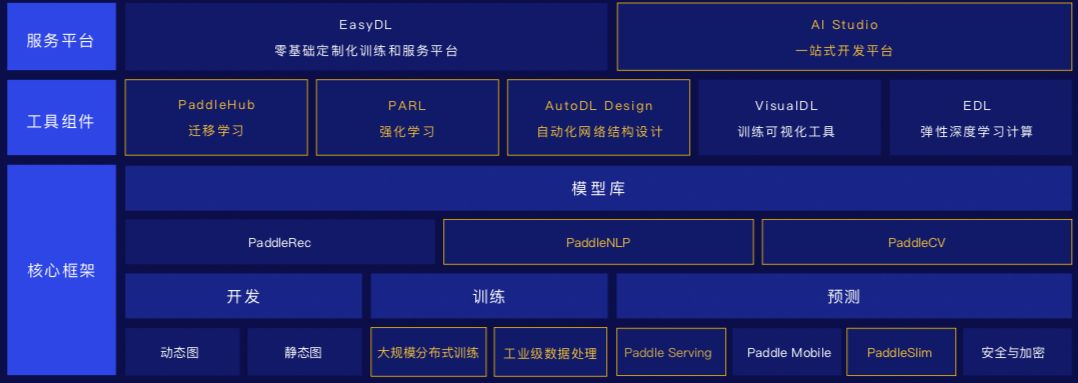
上图中,黄色框为此次更新涵盖的模块,服务平台包括 AI Studio 一站式开发平台,工具组件包括 PaddleHub 迁移学习、PARL 强化学习、AutoDL Design 自动化网络结构设计,核心框架中的模型库 PaddleNLP、PaddleCV,训练模块中的大规模分布式训练和工业级数据处理,预测模块的 Paddle Serving 和 PaddleSlim 都有了更新,以下为具体细节:
PaddleNLP 工具集
PaddleNLP 面向工业级应用,将自然语言处理领域的多种模型用一套共享骨架代码实现,可减少开发者在开发过程中的重复工作,拥有业内领先的语义表示模型 ERNIE(Enhenced Representation through Knowledge IntEgration)。Benchmark 显示,ERNIE 在自然语言推断、语义匹配、命名实体识别、检索式问答任务中超过谷歌提出的 BERT。

视频识别工具集

(飞桨视频识别工具集)
大规模分布式训练
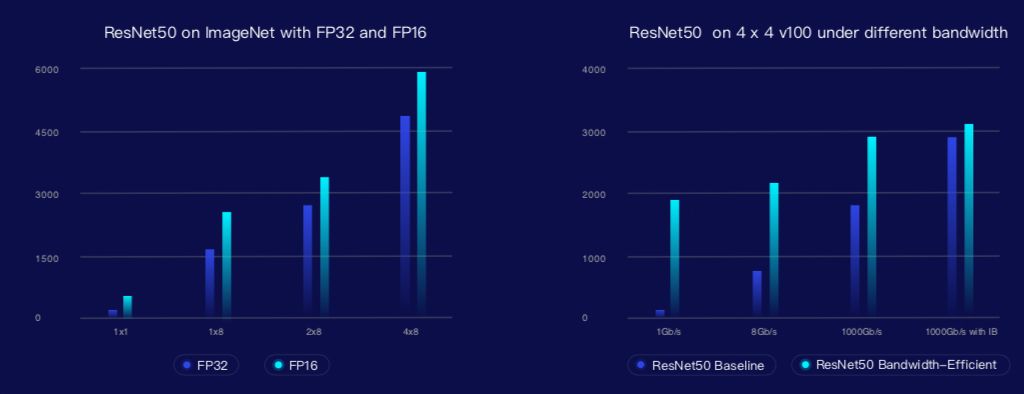
(分布式训练 Benchmark)
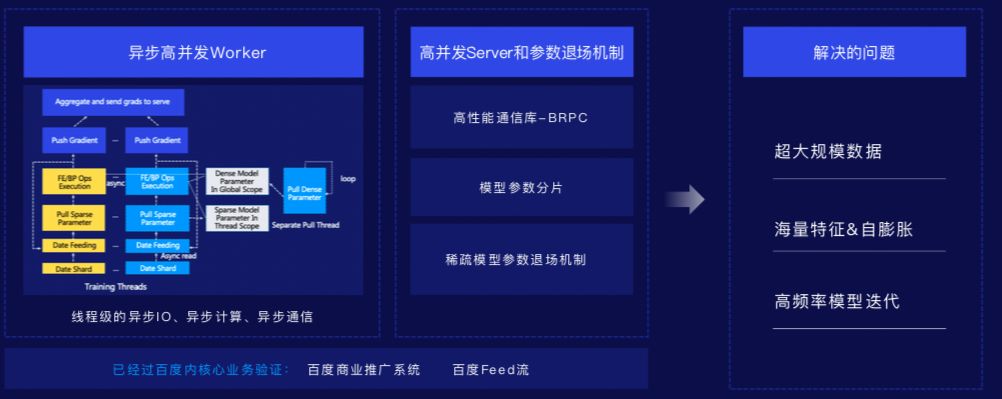
(大规模系数参数服务器)
2. 工业级数据处理
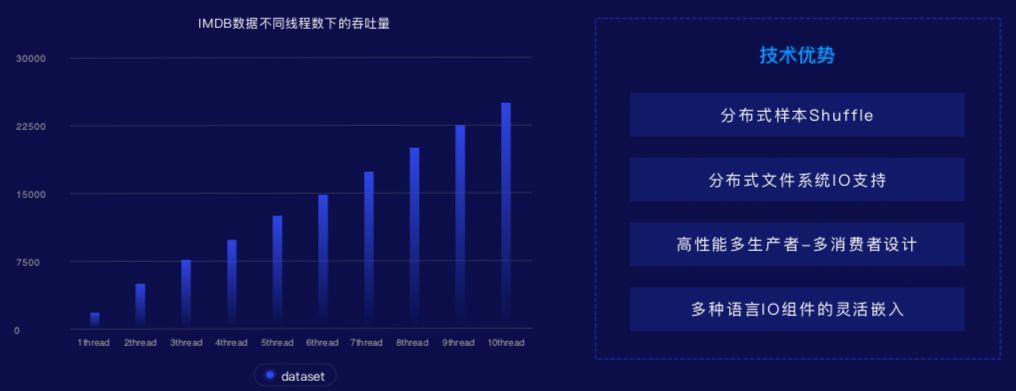
数据处理方面,优化分布式 IO,增加远程文件系统流式读取能力。GPU 多机多卡同步训练通过增加稀疏通信能力提升带宽不敏感训练能力,在低配网络带宽网络环境下,例如 10G 网络下,同步训练可提速 10 倍。
开发和训练后,将模型部署到各种应用场景下是非常关键的一个步骤。部署环节需要高速的推理引擎,在此基础上,为了部署在更多的硬件上往往需要做模型压缩,在真正使用时,还需要软硬一体能力的支持。基于此,PaddlePaddle 准备了完整的端到端的全流程部署方案,并将持续扩展对各类硬件的支持。基于多硬件的支持,PaddlePaddle 提供底层加速库和推理引擎,全新发布 Paddle Serving 支持服务器端的快速部署。
不仅如此,飞桨还发布了模型体积压缩库 PaddleSlim,用两行 Python 代码即可调用自动化模型压缩,经过减枝、量化、蒸馏处理,针对体积已经很小的 MobileNet 模型,它仍能在模型效果不损失的前提下实现 70% 以上的体积压缩。

在工具组件模块,PaddlePaddle 还 开源了 AutoDL Design、升级 PARL,在算法的覆盖、高性能通讯以及并行的训练方面做了支持和扩展,10 分钟可以训练一个 Atari 智能体。
此外,飞桨还 全新发布了预训练一站式管理工具 PaddleHub。
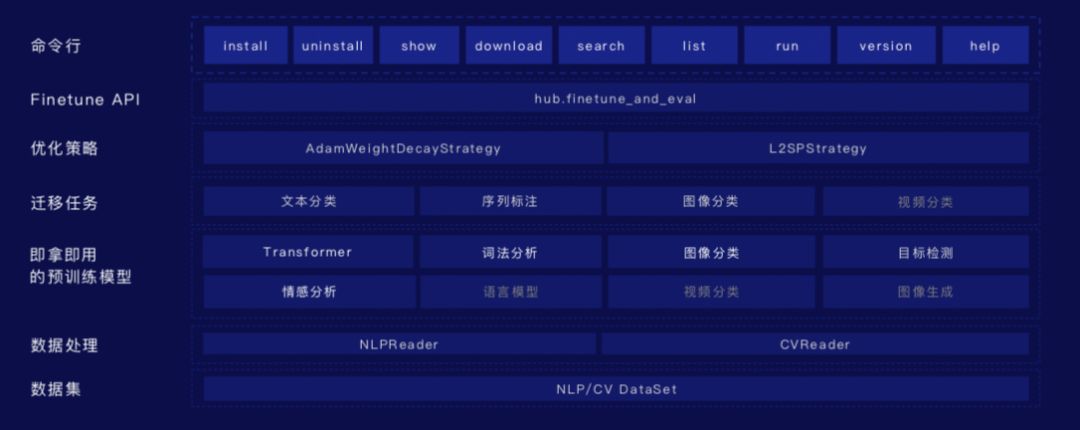
预训练模型管理工具 PaddleHub 提供包括预训练模型管理、命令行一键式使用和迁移学习三大功能,10 行代码即可让开发者完成模型迁移。

会议接近尾声,马艳军还宣布了 AI Studio 即将推出的亿元算力支持计划,即飞桨将为开发者提供价值一亿元的免费算力。
据介绍,免费算力主要以两种模式提供,第一种是 一人一卡模式,V100 的训练卡包括 16G 的显存,最高 2T 的存储空间。另外一种是 远程集群模式 ,PaddlePaddle 提供高性能集群,供开发者免费使用,获取前者需要使用邀请码,后者现在登录 AI Studio 即可使用。
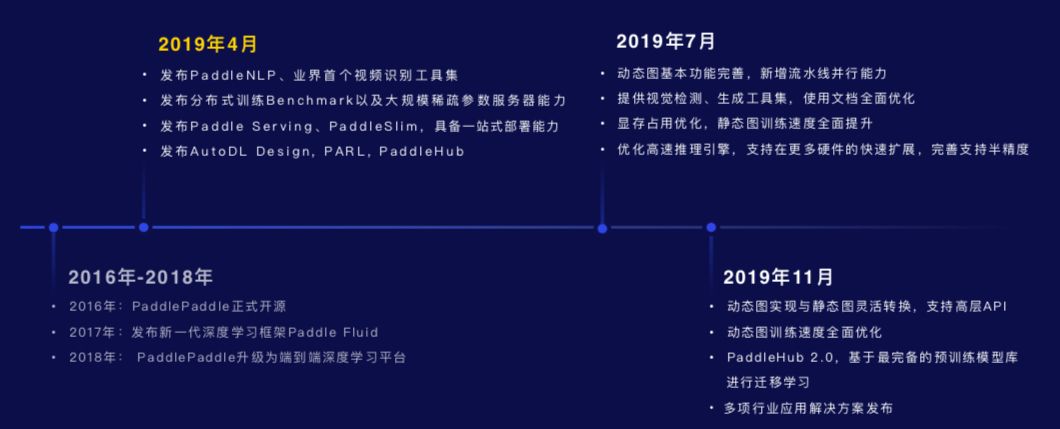
最后,马艳军展示了飞桨从 2016 年建立到今年的路线图,其中值得关注的是其在动态图方面的计划。路线图显示,到今年 11 月,飞桨将实现动态图和静态图的灵活转换,支持高层 API,且训练速度全面优化,还将发布 PaddleHub 2.0 以及多项行业应用解决方案。
马艳军表示,飞桨今后的目标是让核心框架易用性和性能的持续提升,虽然目前 PaddlePaddle 的实现比较简洁,所以在易学易用方面有自己的优势,但飞桨还将持续降低它的使用门槛,让开发者觉得它越来越好用。另外,飞桨将更关注模型和工具在真实场景中的实用性,一方面变得更好用,另一方面满足产业实践的要求。
会后,马艳军在采访中进一步详解飞桨深度学习平台,并表达了他对深度学习的看法。
Q:ONNX 使得不同的深度学习框架可以采用相同格式存储模型数据并交互,阿里巴巴的 XDL 支持任意开源深度学习框架,采用的是桥接的理念,两种产品虽然不同但总体思路,都是用一种产品支持所有深度学习框架,这样的思路您怎么看?
马艳军:ONNX 现在确实有几个框架在支持。ONNX 更多的是在底层的算子实现层做标准,实现统一。各个框架要想兼容这种格式其实有不小的开发成本,是因为深度学习模型是在不断增加、不断被研发出来的,在使用了某个深度学习框架以后,就会按照这个框架的要求不断往里面加算子,可以实现这些模型。因此,现有的框架转换为采用 ONNX 标准都有不小的成本。目前应该说还没有一个很明朗的趋势,表明大家都会用统一的一套算子或标准,不一定最后会实现统一的框架,而是可能多个框架都在用。
Q:Paddle 和 Pytorch、TF 相比差别主要在哪里?
马艳军: 第一,PaddlePaddle 是在我们的产业实践中持续研发和完善起来的,我们的 slogan 也是“源自产业实践的开源深度学习平台”。因此 PaddlePaddle 贴合实际应用场景,真正满足工业场景的应用需求。PaddlePaddle 也开放了深度学习产业应用中的最佳实践。如官方支持面向真实场景应用、达到工业级应用效果的模型,针对大规模数据场景的分布式训练能力、支持多种异构硬件的高速推理引擎,训练所支持的数据规模、训练速度、推理支持的硬件全面性、推理速度更优。
第二,PaddlePaddle 不仅包含深度学习框架,而是提供一整套紧密关联、灵活组合的完整工具组件和服务平台,更加有利于深度学习技术的应用落地。目前 PaddlePaddle 完整具备了端到端的平台能力。去年我们就将 PaddlePaddle 定位为深度学习平台,我们布局也是很早的。所以,我们出的各种相应的配套工作都做得非常完善,开发者能在实打实的应用里体验到,在这个方面 PaddlePaddle 和其他框架相比形成了自己的特色。
Q:PaddleNLP 以前包含很多官方模型,前期预处理数据或文本数据处理比较麻烦,这次会不会包括在内?
马艳军: 自然语言处理和视觉技术确实不太一样, 对于很多 NLP 的任务,端到端的深度学习还不能直接解决问题。在 NLP 包里我们提供了针对一系列任务的处理工具,包括预处理和后处理,这是 PaddleNLP 里的一些功能,并且这块功能也是我们持续完善的点。之所以叫它工具集,就是希望在这些任务场景里包含这些能力,这样用户真正在用的时候,就觉得都能跑得通,跑得顺,不需要前后准备很多工作。
Q:今天发布的新模型都是用一套骨架、相同的 API?
马艳军:NLP 里的模型比较多,针对不同的网络结构,针对不同的任务可以选择使用这些网络结构,也可以基于这些网络结构做出新网络。之前是针对每一个任务都要从头到尾把这一套都跑一遍,写针对各种任务的工具,最后工具之间互相没有关系。PaddleNLP 做了一些任务的抽象,最后放出来的是一套工具,只要修改配置都可以在上面跑了,避免任何工具都要重新写一遍,提升效率。
Q:您认为引领下一波机器学习进步浪潮的将是哪个 / 哪些技术?有人说是迁移学习,您怎么看?
马艳军: 深度学习本身的能力,不管是它灵活建模的能力还是强大的表示能力,这些内在的潜力还可以继续挖掘,并由可能产生新的突破;另一方面,它和一些其他方法的结合,比如说它和知识图谱结合,和强化学习结合,都有可能在一个特定的领域产生一些突破。深度学习和迁移学习也有很多好的结合点,比如深度学习的预训练模型做 Fine-tuning 就能应用到很多场景,这也是个趋势。当然,这点也是发挥了深度学习本身的技术优势,基于深度学习的预训练模型,我们可以把它迁移到很多场景发挥作用。
关于深度学习数据的问题,也有很多解法,比如通过自监督的方法可以解决数据少的问题,这里还有很多可挖掘的点。所以,深度学习领域还在持续出现有影响力的成果,未来还会有更多。

你也「在看」吗?👇


