顶会论文第二弹!AAAI 2020 + CVPR 2020
点击中国图象图形学报→主页右上角菜单栏→设为星标


图片来源网络
随着人工智能2.0的兴起,以及机器学习理论与技术的突破性发展,文档图像分析与识别领域的理论及应用难题得到了更多研究者的关注。
图图推荐来自AAAI2020与CVPR2020的9篇文档图像相关论文,方便图粉们速览学习。


1
All You Need Is Boundary: Toward Arbitrary-Shaped Text Spotting
来源会议:AAAI 2020
论文下载:

该论文提出了用边界点来表示任意形状文本的方法,解决了自然场景图像中任意形状文本的端到端识别问题。
如图1所示:现有方法用外接四边形框来表示文本边界(图1(a)),通过RoI-Align来提取四边形内的特征(图1(b)),这样会提取出大量的背景噪声,影响识别网络。利用边界点来表示任意形状文本有以下优势:
边界点能够描述精准的文本形状,消除背景噪声所带来的影响(图1(c));
通过边界点,可以将任意形状的文本矫正为水平文本,有利于识别网络(图1(d));
由于边界点的表示方法,识别分支通过反向传播来进一步优化边界点的检测。

Fig.1. Illustrations of two kinds of methods for text region representation.
具体方法细节如图2所示,主要包含3个部分:多方向矩形包围框检测器(the Oriented Rectangular Box Detector),边界点检测器(the Boundary Point Detection Network),以及识别网络(the Recognition Network)。
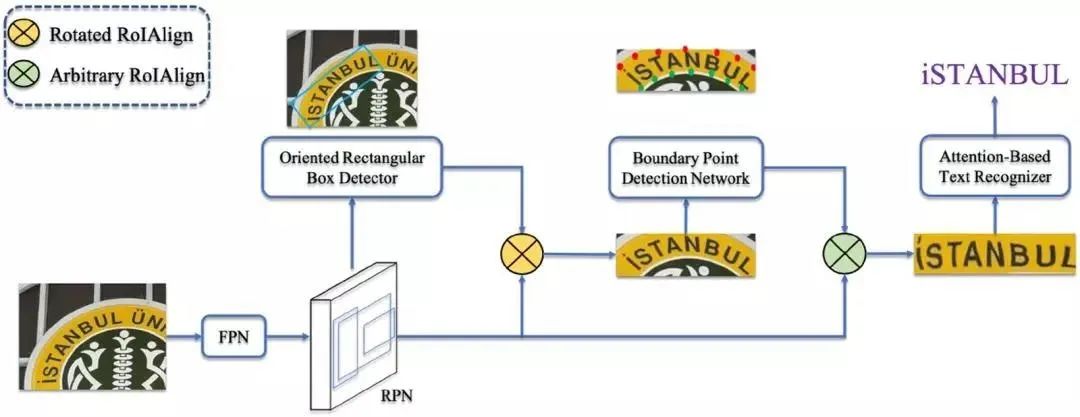
Fig.2. Overall architecture.
2
SynSig2Vec: Learning Representations from Synthetic Dynamic Signatures for Real-world Verification
来源会议:AAAI 2020
论文下载:

该论文针对联机签名认证任务中真实签名数据难以获取的难题,提出了一种基于书写运动学理论的签名合成方法,可以基于模板签名合成出不同形变程度的签名样本,并通过优化签名相似度排序的平均准确率(Average Precision,AP)指标进行特征学习,论文提出的SynSig2Vec方法在两个公开的联机签名认证数据集上比之前最好方法大幅度地降低了签名认证错误率。
该方法的一个主要亮点是无需任何随机仿冒或专业仿冒的真实负样本数据,也可训练一个高性能的笔迹鉴别模型。

图1 针对给定模板签名生成的不同形变程度的合成签名
3
Accurate Structured-Text Spotting for Arithmetical Exercise Correction
来源会议:AAAI 2020

该论文提出了一个端到端的算术习题批改系统,包括检测、识别和评估三个模型。根据算术习题的三个特性,论文提出了基于现有模型的改进方法,取得了超越先前方法的结果。论文还发布了AEC-5k数据集,涵盖40种常见算术习题,共5300张图片。
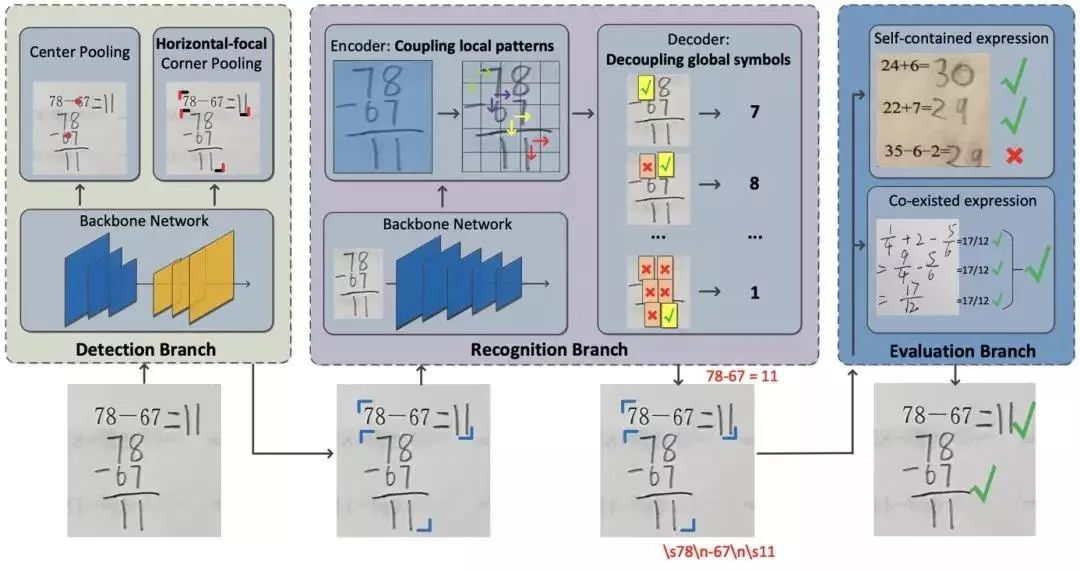
图1 算术习题批改系统模型概览
4
GTC: Guided Training of CTC Towards Efficient and Accurate Scene Text Recognition
来源会议:AAAI 2020
论文下载:

该论文针对场景文本识别,将CTC和Attention结合起来,提出了GTC(Guided Training of CTC)。同时,该工作还提出了一种图卷积网络(GCN)来学习特征的局部相关性。实验证明,该方法能有效提升CTC的识别性能,不仅达到了State-of-the-art的效果,而且相对基于Attention的方法有6倍的加速。
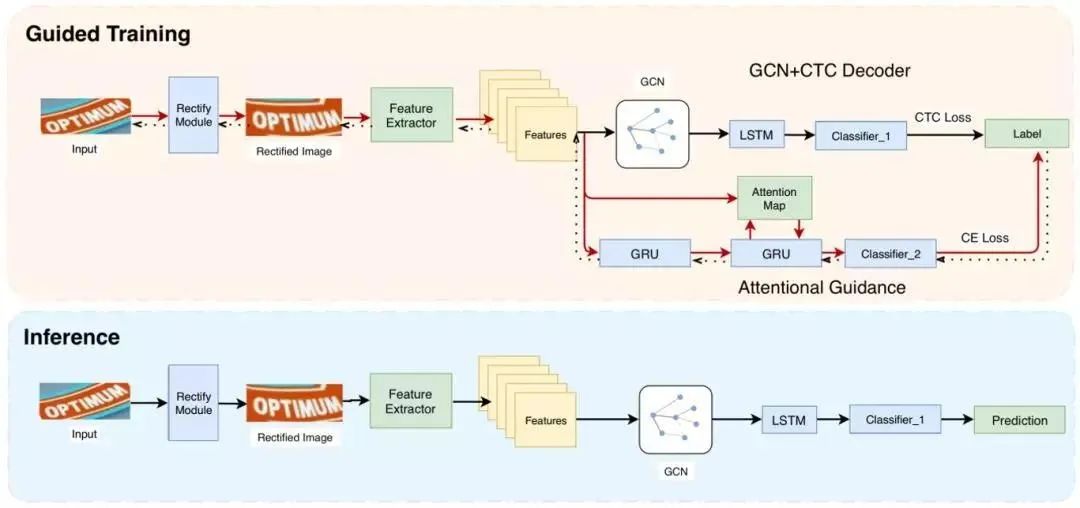
图1 GTC方法的整体结构
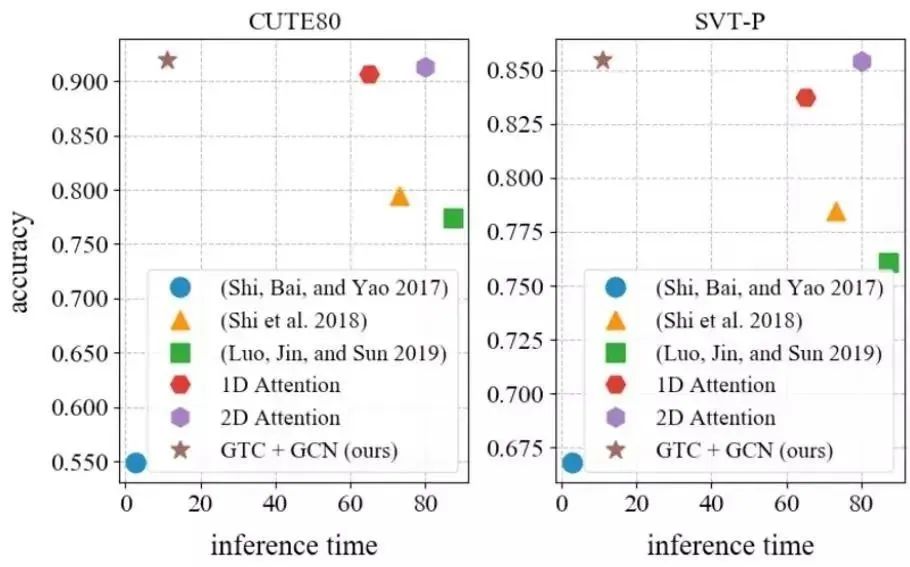
图2 不同方法在准确率和速度指标上的对比
5
Decoupled Attention Network for Text Recognition
来源会议:AAAI 2020
论文下载:

注意力机制是当前文本识别最先进的方法之一,其在场景文本识别任务上取得了尤为出色的效果。然而,当前注意力机制的对齐操作依赖于上一步的解码信息,这就导致了一旦上一步解码出错或具有迷惑性,注意力机制的对齐将产生错误,且此错误会累积传播。这一问题在较长的手写文本上体现得较为明显,如下图所示。

为了解决这种情况,论文提出了一种去耦注意力网络(DAN),该网络将注意力的对齐阶段从解码器中解耦出来,即进行对齐时不再依赖于上一步的解码信息。实验表明,DAN有效缓解了注意力机制的对齐错误问题,并在手写和场景两种文本识别场景上取得了SOTA或相当的效果。
DAN由3个模块组成:特征提取器(FE)、卷积对齐模块(CAM)、去耦解码器(DTD),如下图所示。FE对输入图片提取多个尺度的特征图;CAM接收特征提取器中的多尺度特征,采用全卷积结构,输出与特征图等尺寸的attention map;最后DTD解码出识别结果。
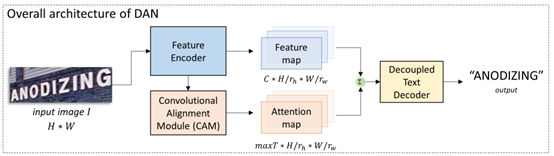

6
Deep Relational Reasoning Graph Network for Arbitrary Shape Text Detection
来源会议:CVPR 2020
论文下载:
http://arxiv.org/pdf/2003.07493
代码链接:

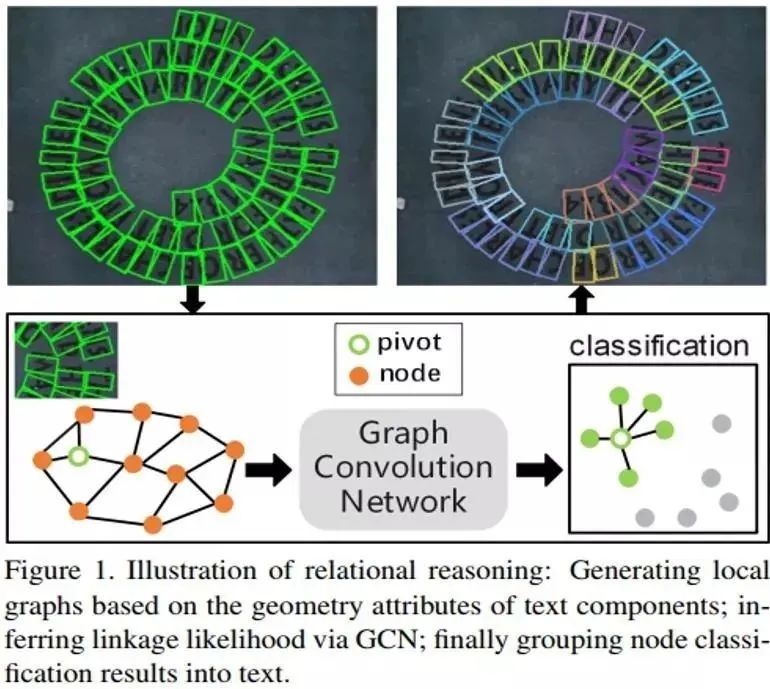
论文提出了一种基于文字/文本组件连接的检测任意形状的方法,利用图卷积神经网络来进行组件之间的深度关系推理,有效地解决了复杂情况下文本组件的连接问题(如图1所示)。
该方法将每个文本实例表示成许多个矩形的文本组件,然后把每个文本组件视为一个节点,通过该论文提出的局部子图(Local Graph)将同一张图中的文本组件节点划分成多个子图,每个子图包含一个中心节点和其二阶以内的邻居节点,最后通过一个图卷积神经网络模型进行学习和推理中心节点与其邻居节点的关系。同时,在局部子图的桥接下,文本组件预测模型(CNN)和关系推理模型(GCN)组合成了一个端到端可训练的任意形状文本检测系统。
实验证明,该方法在多个场景文本检测数据集上达到了State-of-the-art的效果。
具体方法细节如图2所示,主要包含五个部分:共享卷积层(Shared Convolutions)、文本组件预测网络(Text Component Prediction)、局部子图(Local Graphs)、关系推理模型(Relational Reasoning)和组件的归并过程(Link Merging)。
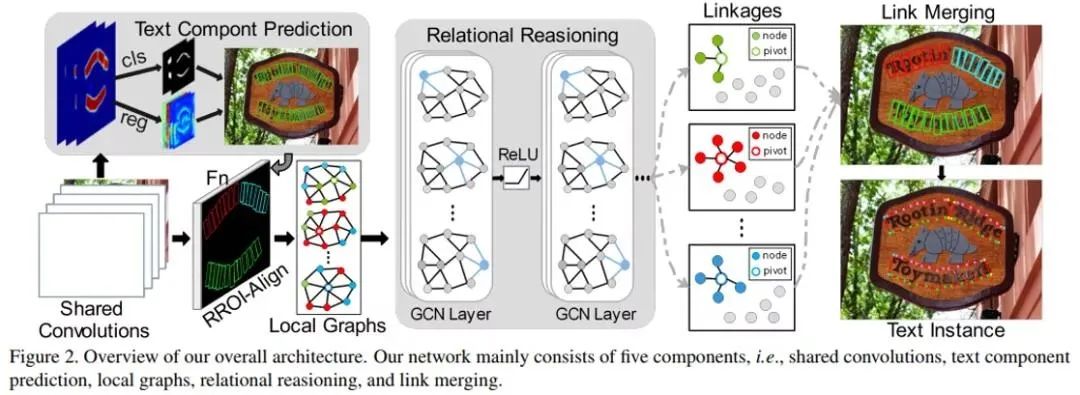
7
SwapText: Image Based Texts Transfer in Scenes
来源会议:CVPR 2020
论文下载:
https://arxiv.org/pdf/2003.08152
深度阅读:论文推荐|[CVPR2020] SwapText: Image Based Texts Transfer in Scenes

论文提出了一种用于自然场景文本替换任务的端到端网络,它可以在保持场景文本图像原有风格的同时,替换其中的文字内容,并与原图片达到一致的可视化效果。实现这一功能主要分为3个步骤:
1.Text Swapping Network:提取待替换图像的前景文字的几何形状和风格特征,并将其转换到输入文本图像上;
2.Background Completion Network:擦除风格图片中的文字并用合适的纹理修复,得到背景图像,并把Decoder中的权值共享给Fusion Network;
3.Fusion Network:将被转换的文本与已擦除的背景合并。

图1 论文方法效果图
论文方法在主观视觉真实性和客观定量评分方面取得了优异的结果。同时,该网络还具有跨语言替换的能力,论文还通过全面的Ablation Study验证了提出网络的有效性。
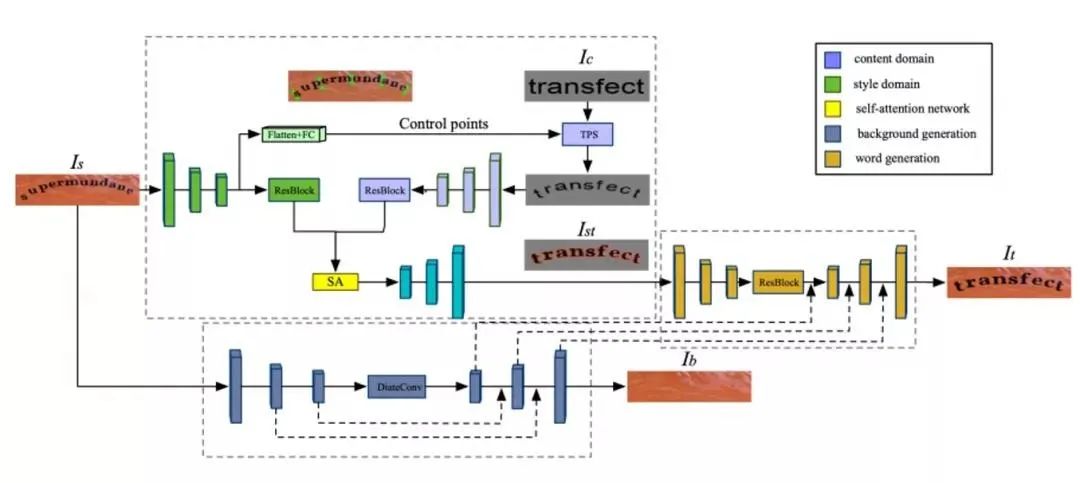
图2 网络整体框架图
8
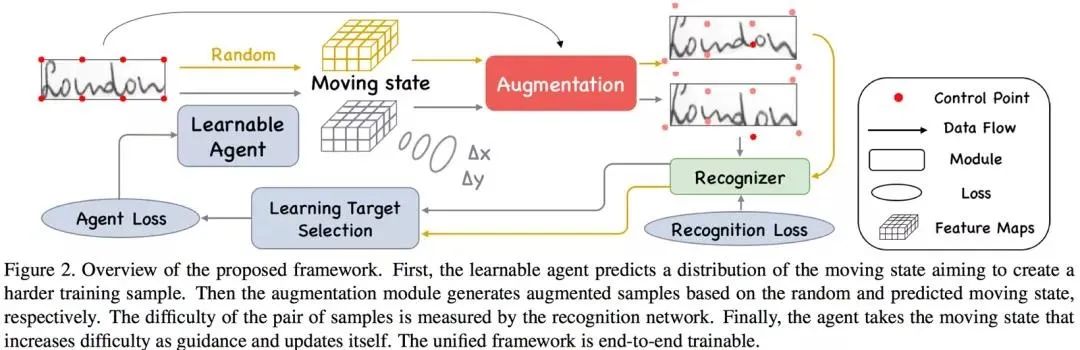
Learn to Augment: Joint DataAugmentation and Network Optimization for Text Recognition
来源会议:CVPR 2020
论文下载:

针对训练数据的几何多样性不足的问题,论文提出了一种面向文本行图像的几何增广方法,和简单的几何变换不同,这种方法可以丰富各个字符的几何多样性。论文进一步提出一种可学习的增广方式,联合识别器端到端训练,以提高识别器的泛化性能。这是针对文本行图像增广的初步探索,该问题仍然有很大的研究空间。
9
Towards Accurate Scene Text Recognition with Semantic Reasoning Networks
来源会议:CVPR 2020
论文下载:

论文围绕自然场景文本识别,针对语义信息利用受限、解码效率低等问题,提出了语义推理模块Global Semantic Resoning Module (GSRM)用于实现全局语义信息推理,并在此基础上,提出了端到端的语义推理网络Semantic Reasoning Networks (SRN),可以融合视觉特征与语义特征。
SRN在英文规则文本行、不规则文本行和中文长文本行数据集上都取得SOTA的效果。另外,SRN在训练和推断阶段,字符与字符之间是并行的,相比于Attention based方法有2倍的加速。

Figure 1. SRN的识别结果,证实了语义模块GSRM的有效性。在(a)中图像右侧顶部文本行是纯视觉的识别结果,图像右侧底部文本行是SRN识别结果。在(b)中图像下方靠左的文本行是纯视觉的识别结果,图像下方靠右的文本行是SRN识别结果。
论文提出的端到端可训练的SRN由4部分组成:基础网络Backbone、并行的视觉特征提取模块(PVAM)、全局语义推理模块(GSRM) 和视觉语义融合的解码器(VSFD)。
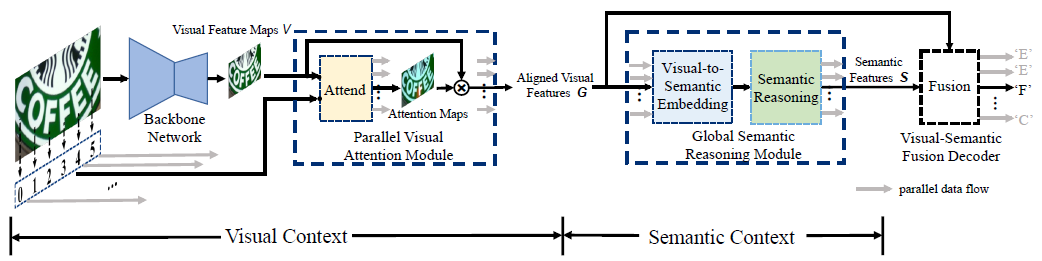
Figure 2. SRN的结构图。灰色表示并行的数据流

以上论文内容解读主要由以下公众号
中国图象图形学学会CSIG
CSIG文档图像分析与识别专委会
提供,中国图象图形学报微信公众号汇编推出。
前沿进展 | 多媒体信号处理的数学理论
中国卫星遥感回首与展望
单目深度估计方法:现状与前瞻
目标跟踪40年,什么才是未来?
10篇CV综述速览计算机视觉新进展
算法集锦 | 深度学习在遥感图像处理中的六大应用
封面故事 | 从传统到深度:火灾烟雾识别综述
封面故事 | 光场数据压缩综述
学者观点 | 结合深度学习和半监督学习的遥感影像分类
编辑推荐 | 视频 + 地图!四维信息助力实景中国
深度学习+图像降噪,如何解决“卡脖子”问题?
专家推荐|高维数据表示:由稀疏先验到深度模型
专家报告 | AI与影像“术”——医学影像在新冠肺炎中的应用
专家推荐|真假难辨还是虚幻迷离,参与介质图形绘制让人惊叹!
学者推荐 | 深度学习与高光谱图像分类【内含PPT 福利】
专家报告|深度学习+图像多模态融合
专家报告 | 类脑智能与类脑计算
100页PPT!道尽Pansharpening 的数学建模机理
实战例题!200+PPT带你看懂监督学习
118页PPT!机器学习模型参数与优化那些事儿~
专家开讲 | 机器学习究竟是什么?
Hinton,吴恩达,李飞飞 !大师深度学习课程集锦
羡慕别人中了顶会?做到这些你也可以!
如何阅读一篇文献?
共享 | SAR图像船舶切片数据集
资源分享| 不知道如何获取最新的算法资讯?快来这里看一看
资源分享|热门IT资讯号推荐
《中国图象图形学报》2020年第2期目次
《中国图象图形学报》2020年第1期目次
《中国图象图形学报》2019年第12期目次
《中国图象图形学报》2019年第11期目次
《中国图象图形学报》2019年第10期目次
本文内容仅供学习交流
版权属于原作者
欢迎大家关注转发!
编辑:秀 秀
指导:梧桐君
审校:夏薇薇
总编辑:肖 亮
声 明
欢迎转发本号原创内容,任何形式的媒体或机构未经授权,不得转载和摘编。授权请在后台留言“机构名称+文章标题+转载/转发”联系本号。转载需标注原作者和信息来源为《中国图象图形学报》。本号转载信息旨在传播交流,内容为作者观点,不代表本号立场。未经允许,请勿二次转载。如涉及文字、图片等内容、版权和其他问题,请于文章发出20日内联系本号,我们将第一时间处理。《中国图象图形学报》拥有最终解释权。
与你同在
前沿 | 观点 | 资讯 | 独家
电话:010-58887030/7035/7418
网站:www.cjig.cn






