FastText:自然语言处理的利器——一个快速文本表示和分类库
【导读】FastText是Facebook人工智能研究实验室(FAIR)开源的一个文本处理库,他是一个专门用于文本分类和外文本表示的库,致力于提高文本表示和分类的效率。本文是Kirti Bakshi与1月16日写的一篇关于FastText介绍的博文,主要介绍了FastText的基础理解、核心思想和应用价值。是理解FastText这个开源项目的一篇不错的的文章。
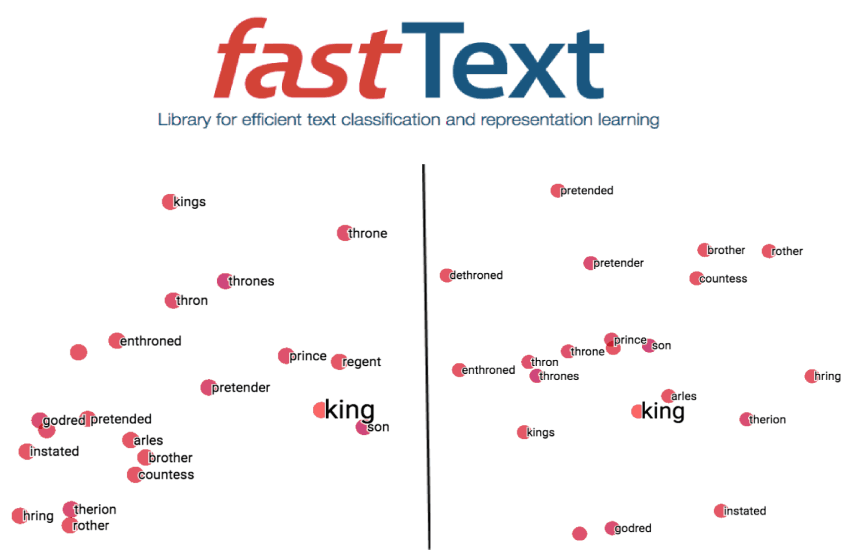
FastText:用于快速文本表示和分类的库(Facebook AI Research)
人工智能研究人员面临的最大的技术挑战之一就是再翻阅帖子内容的时候,如何理解其内在含义。这里有一个基本要求。在我们日常的交互中,文本自动处理是计算机的一个关键部分。自动文本处理是从网络搜索和内容排序甚至垃圾邮件过滤的等任务的重要组成部分,当它运行良好和有序时,它变得完全不可见,你完全感觉不到它的存在。随着在线数据量的增加,现在需要更灵活的工具来更好地理解超大数据集的内容,并且提供更准确的分类结果。
▌FastText
为了研究这个重要的需求,Facebook人工智能研究实验室(FAIR)开放了一个库,该开源库旨在帮助人们构建可扩展的文本表示,以及称为fastText分类的解决方案。他们不断致力于开源社区分享和写作,并认为这比仅仅提供代码更有意义。他们认为,为了推动这个领域进步,分享学习是很重要的,所以现在他们发表的关于fastText的研究是开源的。
▌什么是FastText?
FastText是由Facebook AI Research实验室(FAIR)实验室开发的一个开源工具,它是一个专用于文本可伸缩表示和分类文本的库,与其他任何可用的工具相比,它具有更快和更好的性能。该库是用C ++编写的,但也有其他语言如Python和Node.js的接口。
▌为什么现在要使用FastText?
根据Facebook的说法,“我们可以在不到一分钟的时间内对312K个类别中的50万个句子进行分类,并在不到10分钟的时间内使用标准的多核CPU在超过10亿字上训练fastText”。使用任何其他机器学习工具时,这种使用多核CPU分类实际上要需要几个小时才能实现。深度学习工具在小数据集上使用时表现良好,但在大数据集的情况下会非常缓慢,这限制了它们在生产环境中的使用。
fastText的核心是使用“词袋”的方式,不管文字的顺序。 而且,它不是线性的,而是使用分层分类器来将时间复杂度降低到对数级别,并且在具有更高分类数量的大数据集上更高效。
深度神经网络最近在文本处理中变得非常流行。虽然这些模型在实验室实践中取得了非常好的表现,但是它们的训练和测试往往很慢,这限制了它们在非常大的数据集上的使用。
fastText有助于解决这个问题。它使用分层分类器而非扁平式架构,用树结构组织不同类别,所以这种方法在多类别数据集上非常有效。因此,就类别数量而言,将训练和测试文本分类器的时间复杂度从线性级别降低到对数级别。FastText还通过使用霍夫曼算法来构建树结构,以解决类的不平衡问题。
▌fastText 专用工具:
文本分类在商业中非常重要。有一些工具针对一般分类问题而设计的模型,比如Vowpal Wabbit或者libSVM,但是它们只用于文本分类。 这使得它可以在非常大的数据集上快速训练。 已有模型的结果如下:使用标准的多核CPU,在不到10分钟的时间里训练超过10亿字。 fastText可以在不到五分钟的时间内实现对三十多万个类别中的五百万个句子进行分类。
因此希望fastText的引入有助于更好地构建解决可扩展文本表示和分类问题。 由于它是作为开源库提供的,人们相信fastText对于研究和工程界来说都是非常有价值的,它可以帮助人们设计更好的应用程序,并进一步提高语言理解能力。
更多信息见GitHub
https://github.com/facebookresearch/fastText
原文链接:
https://www.techleer.com/articles/462-fasttext-library-for-fast-text-representation-and-classification-facebook-ai-research/
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!




