有效捕捉目标级别语义信息,之江实验室&浙大提出再注意机制TRT
机器之心专栏
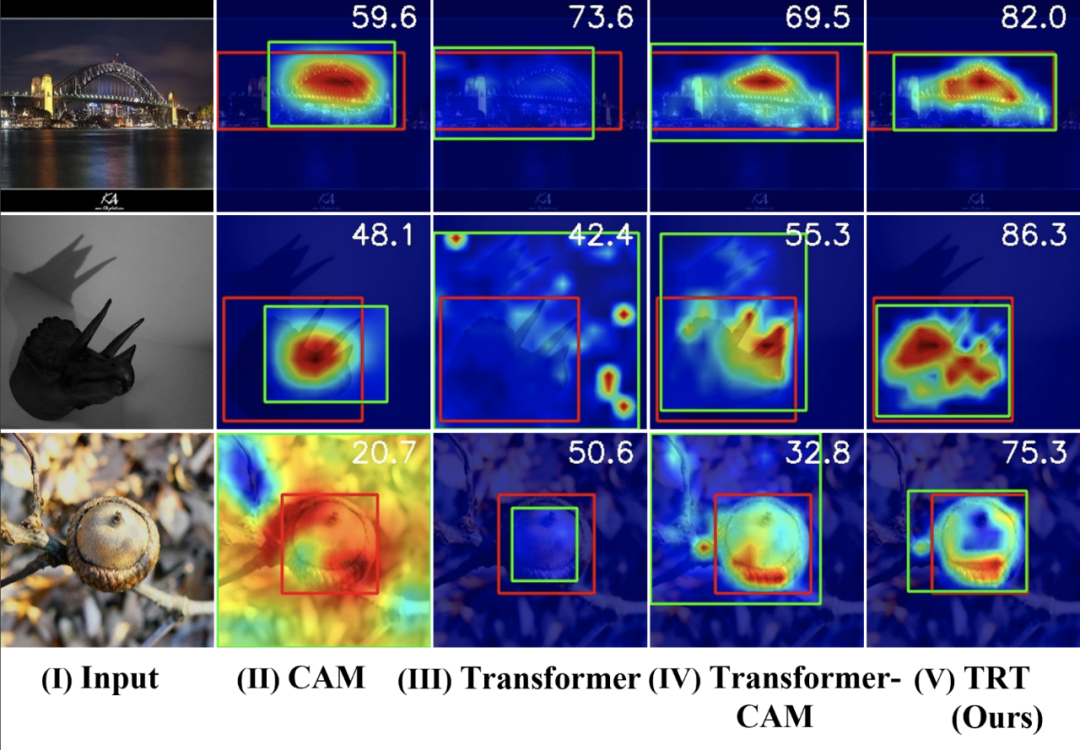
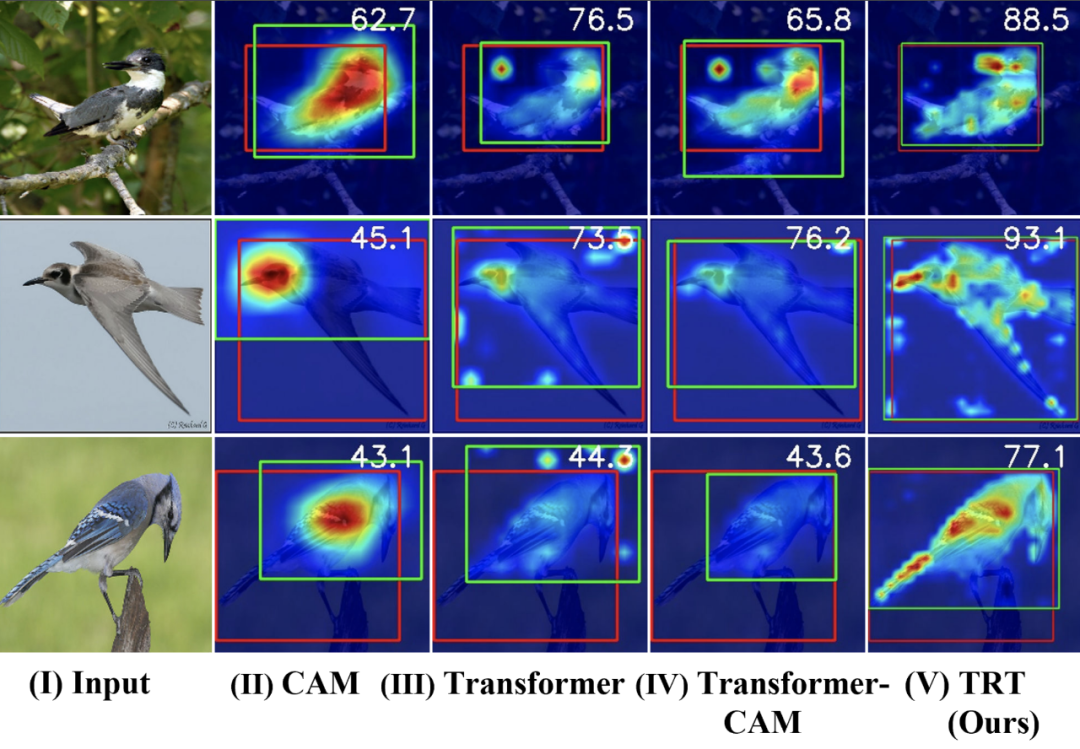
来自之江实验室和浙江大学的研究者提出了一种再注意机制,旨在更有效地捕捉目标级别的语义信息,抑制背景干扰,实现更准确的目标定位能力。
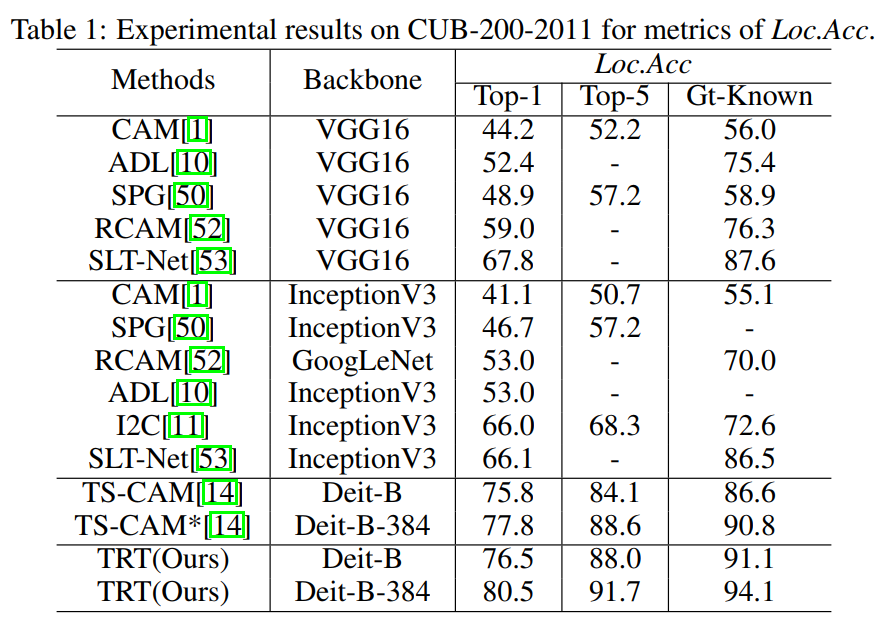
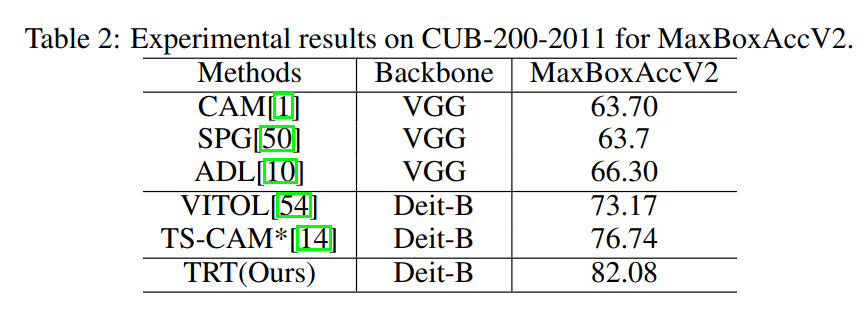
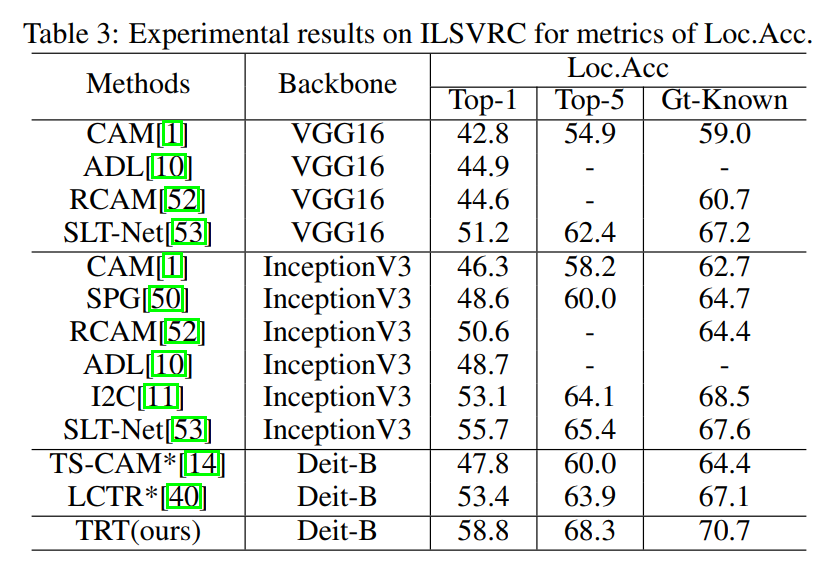
弱监督定位任务(Weakly supervised object localization, WSOL)仅利用图像级别的类别标签,就能实现目标级别的定位功能,因为其细粒度注释的最小化需求大大压缩了人工成本,于近年获得大量关注。


论文链接:https://arxiv.org/pdf/2208.01838.pdf
Github链接:https://github.com/su-hui-zz/ReAttentionTransformer
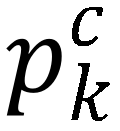 和
和
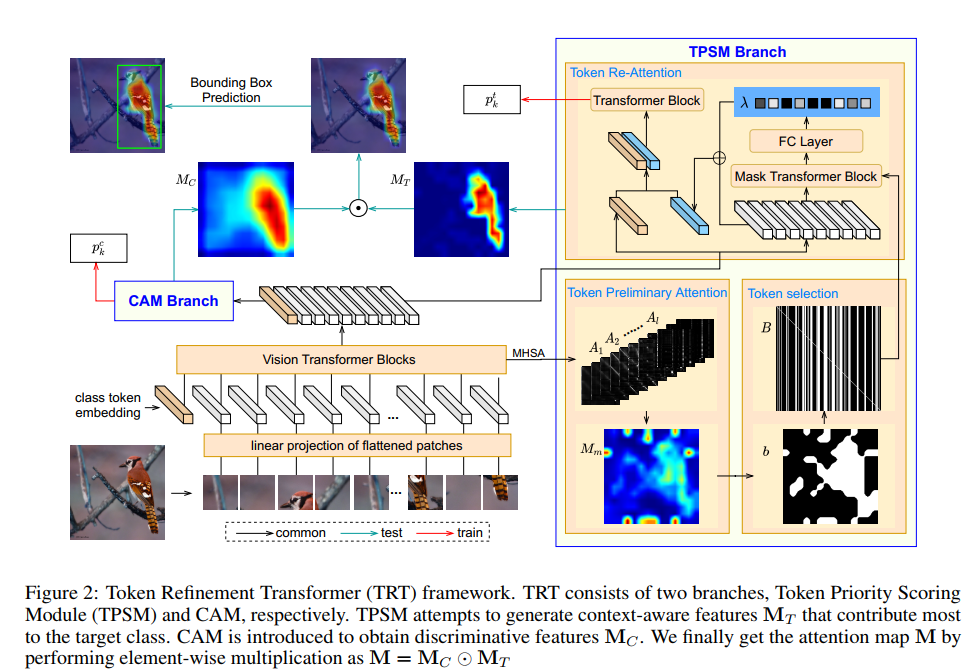
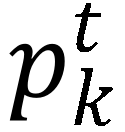 ,与类别标签构建交叉熵损失函数,实现分类训练,如下公式(2)所示。
,与类别标签构建交叉熵损失函数,实现分类训练,如下公式(2)所示。
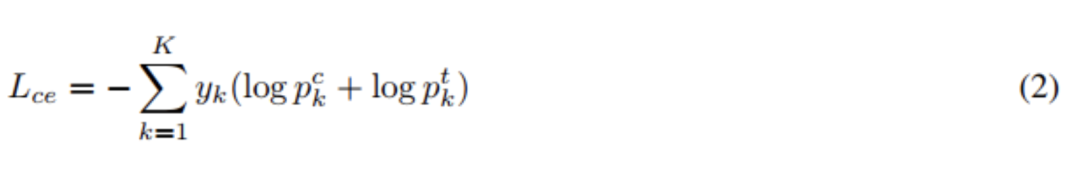
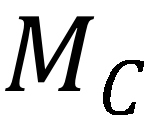 与 TPSM 分支输出的特征
与 TPSM 分支输出的特征
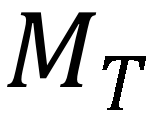 点乘,生成最终的注意力图M。
点乘,生成最终的注意力图M。

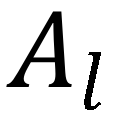 的第一行为 class token 的注意力向量,展示了 class token 和所有 patch token 之间的关联关系。将所有层 transformer 层 class token 的注意力向量进行均值融合,得到初步注意力结果 m。
的第一行为 class token 的注意力向量,展示了 class token 和所有 patch token 之间的关联关系。将所有层 transformer 层 class token 的注意力向量进行均值融合,得到初步注意力结果 m。

利用累积分布采样方法构建自适应阈值,具体操作为:对初步注意力结果 m 进行排序并构建积分图,针对积分图结果确定固定阈值,则针对 m 生成了自适应阈值。
操作原理如下式(5)所示,其中 F 为 m 的累积分布函数,严格单调转换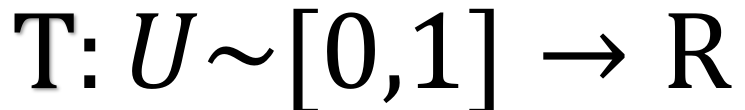
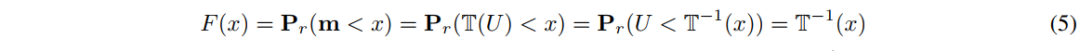
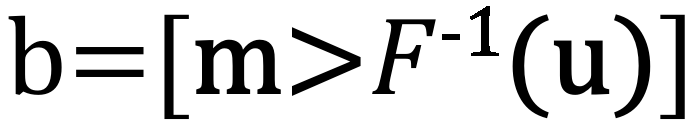 ,b 中值为 1 的位置表示被筛选的 patch token 的位置。
,b 中值为 1 的位置表示被筛选的 patch token 的位置。
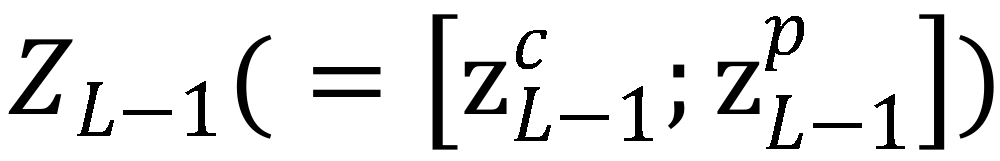 中 patch token 部分
中 patch token 部分
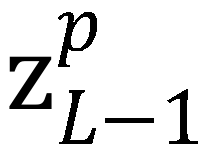 执行掩码自注意力操作,对操作结果进行全连接和掩码 softmax 操作,生成重要性权重 λ。
执行掩码自注意力操作,对操作结果进行全连接和掩码 softmax 操作,生成重要性权重 λ。
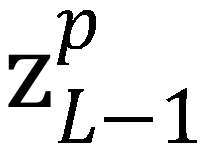 进行加权融合,将
进行加权融合,将
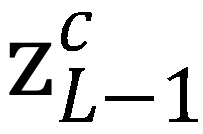 与融合结果送入最后一个 transformer 层。利用最后一个 transformer 层输出的 class token 生成分类概率
与融合结果送入最后一个 transformer 层。利用最后一个 transformer 层输出的 class token 生成分类概率
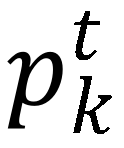 。
。
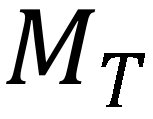 ,如式(10)所示,m' 为的向量形式。
,如式(10)所示,m' 为的向量形式。

掌握「声纹识别技术」:前20小时交给我,后9980小时……
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年11月28日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月28日