RetinaMask:人脸口罩检测新网络
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:AI算法修炼营 | 论文已上传,文末附下载方式
该视频来自于B站《Richard日常读paper:一款口罩检测应用 (RetinaMask)》地址:https://b23.tv/TkxJRt
已获得作者授权,未经许可,严禁转载。

论文地址:https://arxiv.org/pdf/2005.03950.pdf
2019年冠状病毒疾病已严重影响世界,对人类有效的保护方法之一是在公共场所戴口罩。此外,许多公共服务提供商要求客户仅在正确佩戴口罩的情况下才能使用该服务。然而,关于面罩检测的研究很少。
为了促进人类的公共医疗保健,我们提出RetinaMask,这是一种高精度,高效的口罩检测器。提出的RetinaMask是一种单阶段检测器,由一个将高级语义信息与多个特征图融合的特征金字塔网络和一个专注于检测面罩的新型上下文关注模块组成。
此外,我们还提出了一种新颖的跨类对象去除算法,以拒绝具有低置信度和较高并集的交集的预测。实验结果表明,RetinaMask在公共面罩数据集上获得了最先进的结果,其面部和面罩检测精度分别比基线结果高2.3%和1.5%,分别高出11.0%和5.9%比召回基准。此外,我们还探讨了使用轻量级神经网络MobileNet为嵌入式或移动设备实现RetinaMask的可能性。
在深度学习时代之前,人脸检测一般采用传统的、基于手动设计特征的方法,其中最知名的莫过于Viola-Jones算法,至今部分手机和数码相机内置的人脸检测算法,仍旧采用Viola-Jones算法。然而,随着深度学习技术的蓬勃发展,基于深度学习的人脸检测算法逐步取代了传统的计算机视觉算法。
在人脸检测最常用的数据集——WIDER Face数据集的评估结果上来看,使用深度学习的模型在准确率和召回率上极大的超过了传统算法。下图的青线是Viola-Jones的Precision-Recall图。

下图是众多基于深度学习的人脸检测算法的性能评估PR曲线。可以看到基于深度学习的人脸检测算法的性能,大幅超过了VJ算法(曲线越靠右越好)。近两年来,人脸检测算法在WIDER Face的简单测试集(easy 部分)上可以达到95%召回率下,准确率也高达90%,作为对比,VJ算法在40%召回率下,准确率只有75%左右。

其实,基于深度学习的人脸检测算法,多数都是基于深度学习目标检测算法进行的改进,或者说是把通用的目标检测模型,为适应人脸检测任务而进行的特定配置。而众多的目标检测模型(Faster RCNN、SSD、YOLO)中,人脸检测算法最常用的是SSD算法,例如知名的SSH模型、S3FD模型、RetinaFace算法,都是受SSD算法的启发,或者基于SSD进行的任务定制化改进, 例如将定位层提到更靠前的位置,Anchor大小调整、Anchor标签分配规则的调整,在SSD基础上加入FPN等。

所提出的RetinaMask的体系结构如图2所示。为了设计有效的面部口罩检测网络,采用了mmdetection中提出的目标检测器框架,该框架提出了一种具有骨架,颈部和头部的检测网络。
骨干是指由卷积神经网络组成的通用特征提取器,用于将图像中的信息提取到特征图。在RetinaMask中,我们采用ResNet作为标准骨干网,但也包括MobileNet作为骨干网络,以便在计算资源有限的部署方案中进行比较并减少计算量和模型大小。
就颈部而言,它是骨架和头部之间的中间组件,它可以增强或改进原始特征图。在RetinaMask中,FPN用作接连部分,它可以提取高级语义信息,然后通过增加系数来将这些信息融合到先前图层的特征图中。
最后,代表能够实现网络最终目标的分类器,预测器,估计器等。在RetinaMask中,我们采用与SSD类似的多尺度检测策略,通过多个FPN特征图进行预测,因为它可以具有不同的接受场来检测各种大小的对象。特别是,RetinaMask利用三个特征图,并将每个特征图馈入检测头。在每个检测头内部,我们进一步添加了上下文关注模块来调整接收字段的大小并专注于特定区域,这类似于单级无头(SSH),但具有关注机制。
检测头的输出通过完全卷积网络而不是完全连接的网络,以进一步减少网络中的参数数量。将检测器命名为RetinaMask,因为它遵循RetinaNet的体系结构,该体系结构由SSD和FPN组成,并且还能够检测小型口罩。(RetinaNet相关细节可以参考文章:目标检测经典工作:RetinaNet和它背后的Focal Loss)

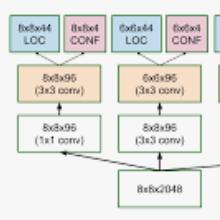
为了提高口罩的检测性能,RetinaMask提出了一种新颖的情境关注模块作为其检测头(图3)。与SSH中的上下文模块类似,我们利用不同大小的内核来形成类似Inception的块。它能够从同一要素图获得不同大小的感受野,因此它将能够通过级联操作并入更多不同大小的对象。
但是,原始上下文模块不会考虑面部或口罩,因此我们只需在原始上下文模块之后层叠一个关注模块CBAM,即可让RetinaMask专注于面部和遮罩功能。上下文感知部分具有三个子分支,每个分支中分别包含一个3×3,两个3×3和三个3×3内核。然后,通过通道注意将串联的特征图馈送到CBAM中,以通过多层感知器选择有用的通道,然后通过无空间关注将重点放在重要区域上。
Convolutional Block Attention Module(CBAM)
论文地址:http://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf
在该论文中,作者研究了网络架构中的注意力,注意力不仅要告诉我们重点关注哪里,还要提高关注点的表示。目标是通过使用注意机制来增加表现力,关注重要特征并抑制不必要的特征。为了强调空间和通道这两个维度上的有意义特征,作者依次应用通道和空间注意模块,来分别在通道和空间维度上学习关注什么、在哪里关注。此外,通过了解要强调或抑制的信息也有助于网络内的信息流动。

上图为整个CBAM的示意图,先是通过注意力机制模块,然后是空间注意力模块,对于两个模块先后顺序对模型性能的影响,本文作者也给出了实验的数据对比,先通道再空间要比先空间再通道以及通道和空间注意力模块并行的方式效果要略胜一筹。
那么这个通道注意力模块和空间注意力模块又是如何实现的呢?
通道注意力模块
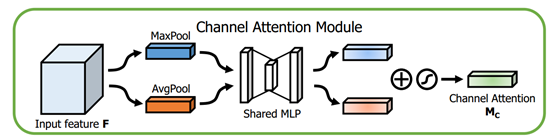
这个部分大体上和SENet的注意力模块相同,主要的区别是CBAM在S步采取了全局平均池化以及全局最大池化,两种不同的池化意味着提取的高层次特征更加丰富。接着在E步同样通过两个全连接层和相应的激活函数建模通道之间的相关性,合并两个输出得到各个特征通道的权重。最后,得到特征通道的权重之后,通过乘法逐通道加权到原来的特征上,完成在通道维度上的原始特征重标定。
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)空间注意力模块
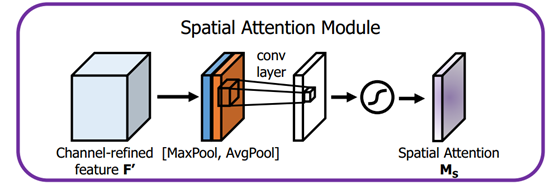
首先输入的是经过通道注意力模块的特征,同样利用了全局平均池化和全局最大池化,不同的是,这里是在通道这个维度上进行的操作,也就是说把所有输入通道池化成2个实数,由(h*w*c)形状的输入得到两个(h*w*1)的特征图。接着使用一个 7*7 的卷积核,卷积后形成新的(h*w*1)的特征图。最后也是相同的Scale操作,注意力模块特征与得到的新特征图相乘得到经过双重注意力调整的特征图。
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x)网络整体代码:
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out # 广播机制
out = self.sa(out) * out # 广播机制
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out对于每个输入图像,RetinaMask产生两个输出,分别是定位偏移量预测和类别预测。

OHEM:在线难例挖掘
OHEM算法(online hard example miniing,发表于2016年的CVPR)主要是针对训练过程中的困难样本自动选择,其核心思想是根据输入样本的损失进行筛选,筛选出困难样本(即对分类和检测影响较大的样本),然后将筛选得到的这些样本应用在随机梯度下降中训练。
传统的Fast RCNN系列算法在正负样本选择的时候采用当前RoI与真实物体的IoU阈值比较的方法,这样容易忽略一些较为重要的难负样本,并且固定了正、负样本的比例与最大数量,显然不是最优的选择。以此为出发点,OHEM将交替训练与SGD优化方法进行了结合,在每张图片的RoI中选择了较难的样本,实现了在线的难样本挖掘。

OHEM实现在线难样本挖掘的网络如上图所示。图中包含了两个相同的RCNN网络,上半部的a部分是只可读的网络,只进行前向运算;下半部的b网络即可读也可写,需要完成前向计算与反向传播。
在一个batch的训练中,基于Fast RCNN的OHEM算法可以分为以下5步:
(1)按照原始Fast RCNN算法,经过卷积提取网络与RoI Pooling得到了每一张图像的RoI。
(2)上半部的a网络对所有的RoI进行前向计算,得到每一个RoI的损失。
(3)对RoI的损失进行排序,进行一步NMS操作,以去除掉重叠严重的RoI,并在筛选后的RoI中选择出固定数量损失较大的部分,作为难样本。
(4)将筛选出的难样本输入到可读写的b网络中,进行前向计算,得到损失。
(5)利用b网络得到的反向传播更新网络,并将更新后的参数与上半部的a网络同步,完成一次迭代。
当然,为了实现方便,OHEM的简单实现可以是:在原有的Fast-RCNN里的loss layer里面对所有的props计算其loss,根据loss对其进行排序,选出K个hard examples,反向传播时,只对这K个props的梯度/残差回传,而其他的props的梯度/残差设为0。
但是,由于其特殊的损失计算方式,把简单的样本都舍弃了,导致模型无法提升对于简单样本的检测精度,这也是OHEM方法的一个弊端。
优点:1) 对于数据的类别不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强;2) 随着数据集的增大,算法的提升更加明显;
缺点:只保留loss较高的样本,完全忽略简单的样本,这本质上是改变了训练时的输入分布(仅包含困难样本),这会导致模型在学习的时候失去对简单样本的判别能力。

baseline资料:
数据下载地址
开源代码和模型链接
https://github.com/AIZOOTech/FaceMaskDetection
在线体验链接
https://aizoo.com/face-mask-detection.html

参考资料:
《AIZOO开源人脸口罩检测数据+模型+代码+在线网页体验,通通都开源了》
论文下载
在CVer公众号后台回复:RetinaMask,即可下载本论文
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集3900人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加群
▲长按关注我们
请给CVer一个在看!