熵与其它信息量估计—国科大UCAS胡包钢教授《信息论与机器学习》课程第四讲
【导读】在信息论或机器学习教学中,通常不包含熵估计内容。由于现代通讯应用中是数字通讯,对于离散随机变量,熵估计方法成熟,因此不是问题。而在机器学习或大数据处理中,大量数据是以连续随机变量方式出现(如图像、语音等)。而对连续随机变量及其混合随机变量,目前熵估计仍然处于方法研究发展阶段。机器学习传统教学中会包括分布估计,而不包括熵估计内容。我们知道熵估计类似于随机变量分布估计,需求大量且在低维数据中方可获得较好的近似解。熵估计或分布估计均属于“生成式(discriminative)学习”,一般会比“判别式(generative)学习”更难于处理,且预测结果误差更大。熵估计可以被认为是信息论与机器学习“综合”中的最大障碍。而这些障碍有些是本质性的,比如高维数据情况下的维数灾难(Curse of Dimensionality)问题。当估计结果很差时,基于信息论机器学习方法将不可能有效。比如对同样一组数据,应用不同估计方法或不同内部参数会有很大不同结果。因此可以认为基于信息论机器学习中,熵与其它信息量估计是关键性的基础问题。因此本教学中,增加该章为独立内容。我们认为对抗网络(GAN)中的“生成式”方法结合“判别式”方法是赋予智能机器进化功能中的重要学习方式,其中信息论会扮演重要角色(想想为什么)。该章是讲解熵与其它信息量估计这样基础问题与必要知识,由此也可理解为什么近年来这个主题研究开始活跃起来。

第17-22页: 在第一章中我们介绍了美国佛罗里达大学Principe教授是国际上首次提出“信息论机器学习(ITL)”理论框架的学者。基于此框架他们团队发展了许多基础性的原创工作。这里主要是他们关于二次Renyi熵中的部分贡献。其中从物理视角提出信息势、信息势场、信息力的定义(第19页),并与二次Renyi熵建立关联的学术思想十分重要并具启迪性。本人理解这是对机器学习从信息论角度提供解释性的重要基础。其中给我的启迪是未来研究要打通机器学习、信息论、物理原理之间的关联。第22页中的要点也可以理解为熵估计方法中期望的性质。
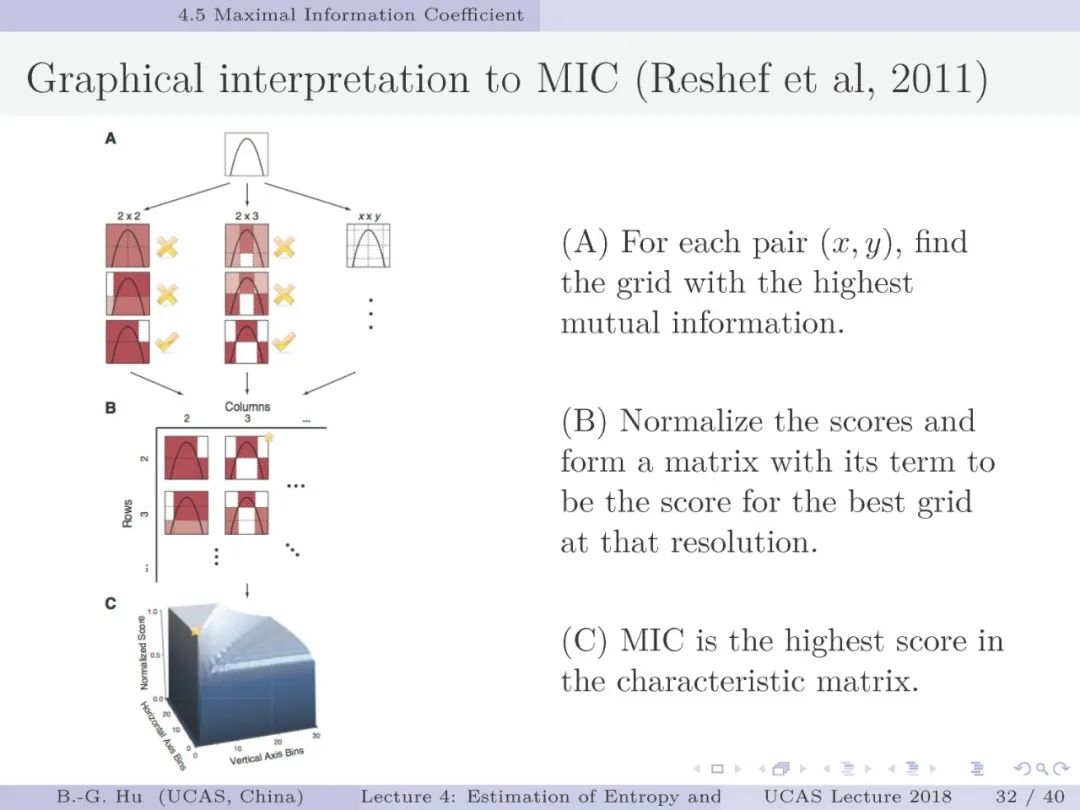
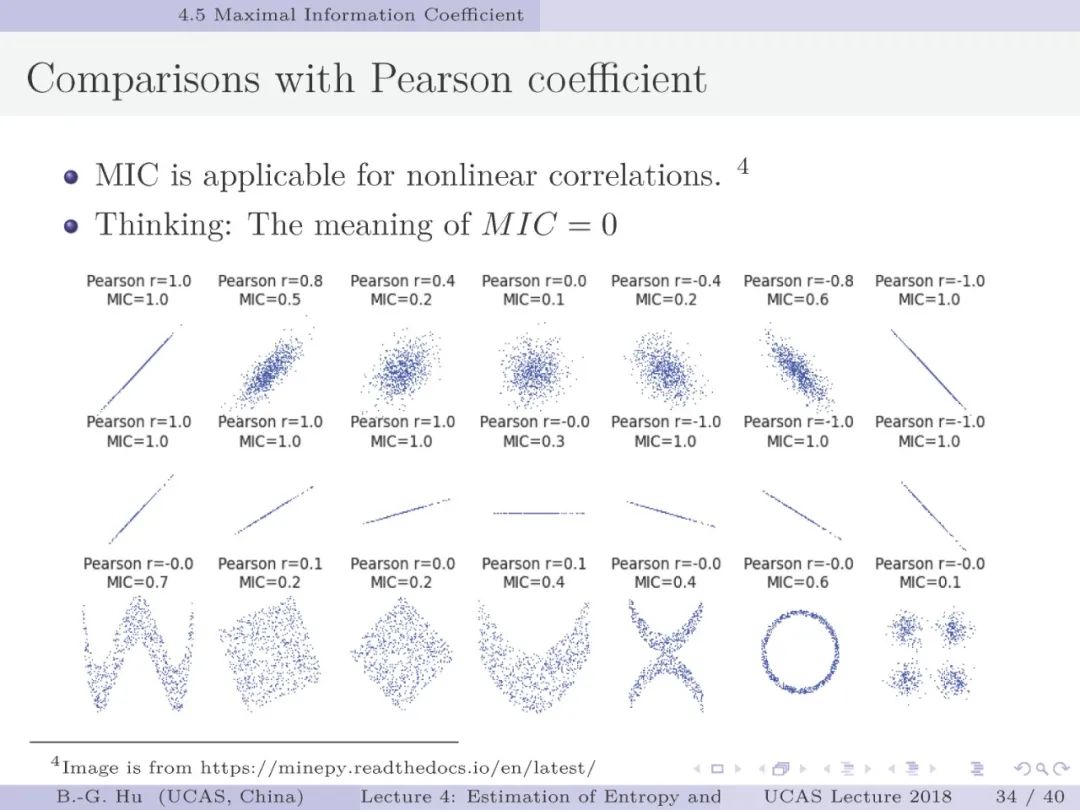
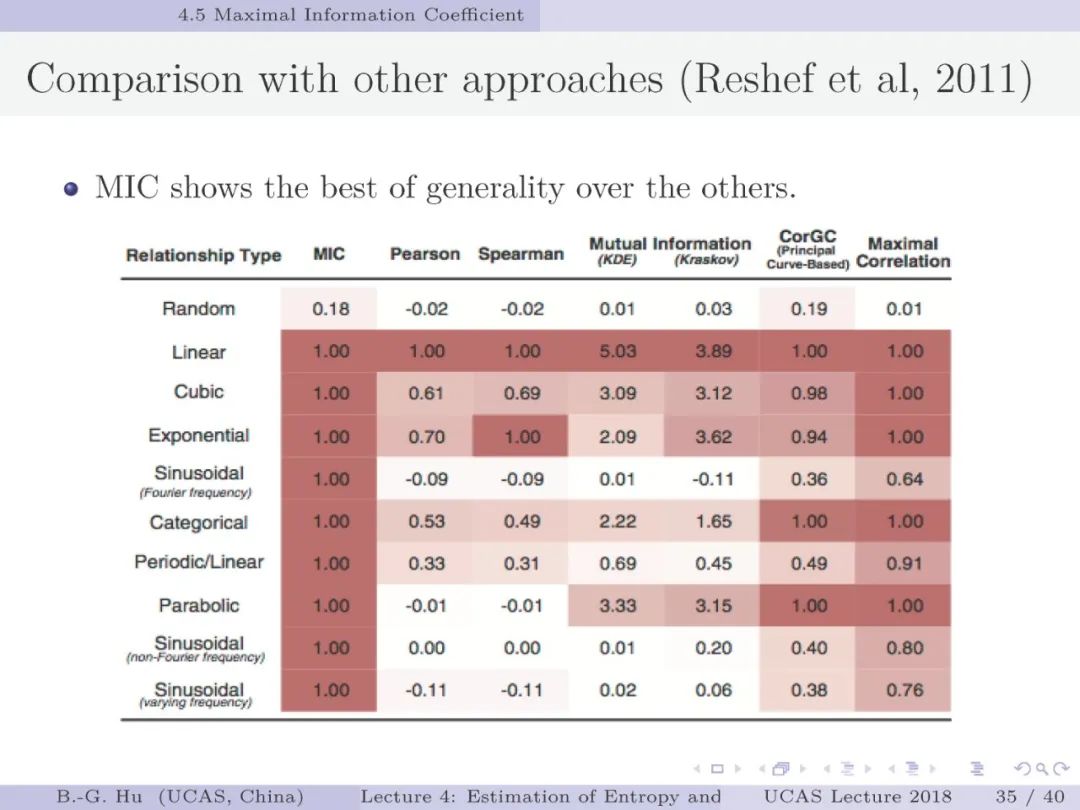
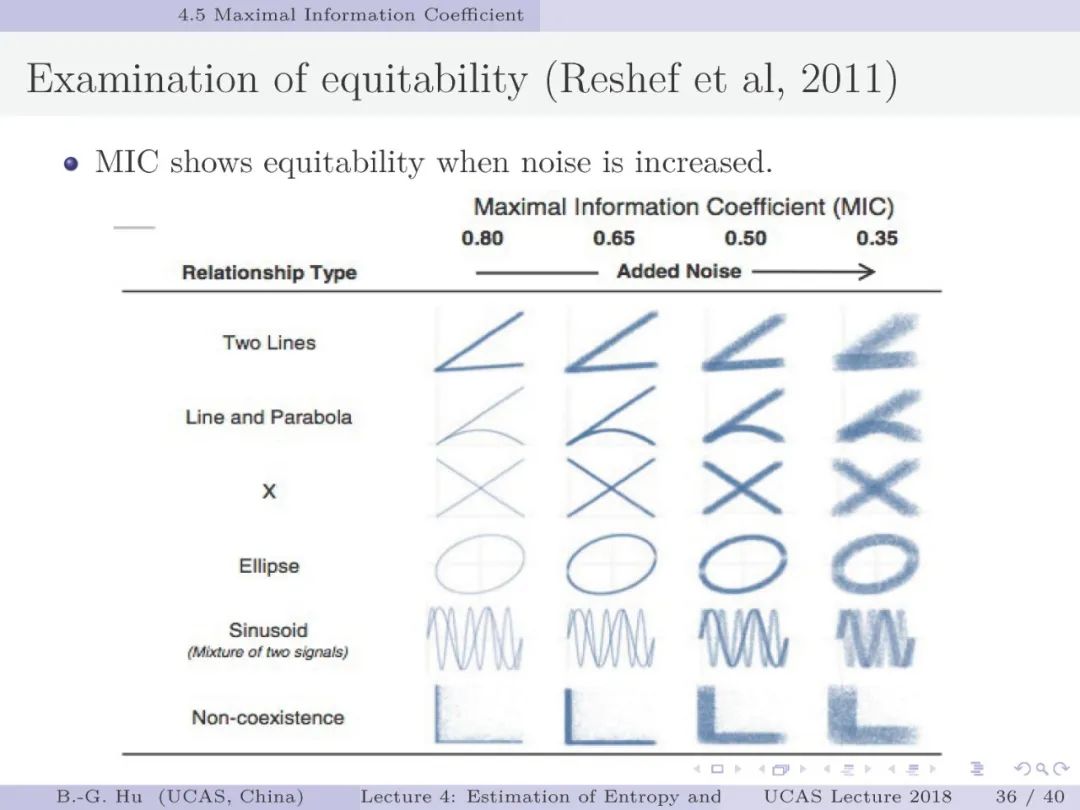
第30-37页: 我认为MIC方法给出了信息论中互信息定义扩展应用与估计方法创新的典型样例。他们首先发现现有指标应用中的问题,然后提出基于信息论为基础思想的指标,再后对这个指标提出需求满足两个启发式属性。这是一种顶层的先验知识。我们将其称为“元准则”,即关于准则之上的准则。最后是发展了具体MIC方法并从数据实验中表明该方法是基本符合两个启发式属性。希望读者能够从从这个研究样例中“悟”出一种个人总结的方法论?
作业:
1. 个人编程或应用开放工具箱(如[1]) 进行数值计算来理解KL(p|q), KL(q|p) and JS(p|q)。根据给定分布采样。如p(x)=0.5*N(0,1)+0.5*N(8,2),Case 1: q(x)=N(0,1), Case 2: q(x)=N(4,4)。考察:I. 三个信息指标之间的差异。II. 关于估计方法中自由参数与估计结果的讨论。III. 估计结果与采样样本个数的关系。
2. 从机器学习四个基本问题中考察,熵与其它信息量的估计属于哪个基本问题?学习目标选择是否应该考虑估计情况?
附录:
鉴于目前人工智能研发更多是在Linux操作系统下实施,因此推荐读者学习托瓦兹(L.B. Torvalds)开创Linux内核的历史[2]。托瓦兹是1991年21岁身为大学生期间成功地开发了操作系统Linux内核。如果说前面斯托曼绘制了一个新世界愿景,那么托瓦兹则创造了一个新世界,且最初的动机“只是为了好玩(Just for fun)”。推荐读者阅读《只是为了好玩: Linux之父林纳斯自传》一书(人民邮电出版社,2014年)。可以看到他还逐步悟出了人生,创造出了Linux法则(Law of Linux)。这样“为了好玩”见解真是值得我们在学习与科研中去体悟。希望读者学习本课件会有“为了好玩”的心态,最后能够获得“不亦说乎”的感受。托瓦兹受斯托曼影响,还为Linux给出吉祥物标志为企鹅[3]。我把它看成“阳光小男孩”。本人2002年创作的一个作品正是受到托瓦兹的影响。很喜欢他的一个故事是用以下立场回复质疑者:“我对许可权协议的看法是‘写代码的人有权选择其软件的许可权协议形式,其他人没有权力对此指责’。任何指责许可权协议的人都是怨妇。反对 KDE 的人可以自由地编写他们自己的代码,但是他们在道义上没有权力指责别人编写其它代码。我对于这些报怨的人持蔑视态度,我不想卷入这场争论。”(《天才莱纳斯,Linux 传奇》,朱正茂 译,机械工业出版社,2002.)。这里表达了对创新工作(如开源软件)中的人生观:人生要追求成为建设者(而非怨妇),并用你的创新作品说话。你了解托瓦兹事迹后会悟出什么个人新见解?
1. https://github.com/gregversteeg/NPEET
2. https://baike.baidu.com/item/linux/27050?fr=aladdin
3. https://baike.baidu.com/item/Tux/9557378?fr=aladdin
前期课程链接:
第一讲:
国科大UCAS《信息论与机器学习》课程,中国科学院自动化研究所胡包钢研究员
第二讲:
国科大UCAS胡包钢教授《信息论与机器学习》课程第二讲:信息论基础一
第三讲:
国科大UCAS胡包钢教授《信息论与机器学习》课程第三讲:信息论基础二
课件文件:
































附录文件:
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ITML2020” 就可以获取《国科大UCAS《信息论与机器学习》课件》专知下载链接