FACEGOOD 推出10万点人脸关键点跟踪,重新定义工业级人脸3D重建
作者:FACEGOOD
目前无论是学术界还是工业界对人脸的研究有两个方向,其一民用级,通过技术泛化为用户提供低精的产品,这些技术在工业级高精度上是无法满足需要的,主要因为算法泛化丢失了人脸的高频信息。其二工业级,从人脸生物力学仿真层面,持续提高精度,FACEGOOD 走在这个方向,在技术适当泛化的基础上,其将人脸关键点跟踪推向了极致,目前已将精度推到 10 万级,该技术可用于工业级换脸、表情捕捉等场合。


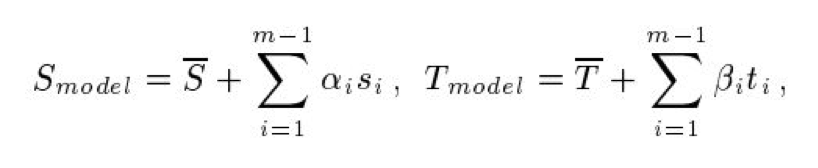

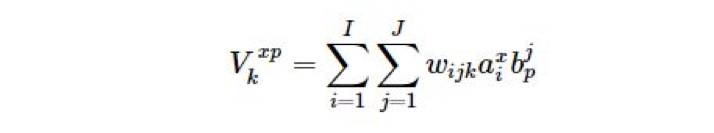
这个双线性公式在公式 1 的思路上增加了一个系数 a,表示不同表情,b 表示不同的个体,w 是人脸数据库,到此 3DMM 在算法流程上完整了,为日后 Facewarehouse 等应用奠定了基础,后面的故事大家都知道了 Facewarehouse 推出了自己的数据库及应用思路,讲到这里我们对前面这些研究做个总结。
3DMM 缺点是很明显的,在技术泛化这条路上一路狂奔,忽略了人脸非常多的细节,尤其是高频低幅度的表情细节,在个体上体现非常明显,造成这个局面的原因有两个,基于统计的回归并不精确,是一个模糊解,3D 数据库模型的采集多数用成本低廉的设备生成,精度不高,两者加起来,3DMM 在高精应用场景可以说完全无法满足需求,更不可能达到工业级超高精度需要。


为了更精确的计算人脸的 3D 信息,并能适用于工业级业务场景,FACEGOOD 团队采用相机阵列方式采集了 100 个不同个体的 3D 模型,每个人有 43 个不同的表情,以及他们对应的高精度皮肤材质数据,至于这些数据建立了 FACEGOOD 3DMM 模型。
目前开源的数据库主要有 BFM 跟 SFM 两个,同时还有一个 Facewarehouse 仅供学术研究使用,对比这些数据库,FACEGOOD 3DMM 主要体现在精度上,抛弃 kinect 这类民用级扫描技术,使用相机阵列的方式,可以完全重建人脸的所有肖像特征,如上图所示,图示 2 是 FACEGOOD 数据,图示 1 是 SFM 数据,后者在细节上损失很大,基本上只保留了人脸的大概特征。
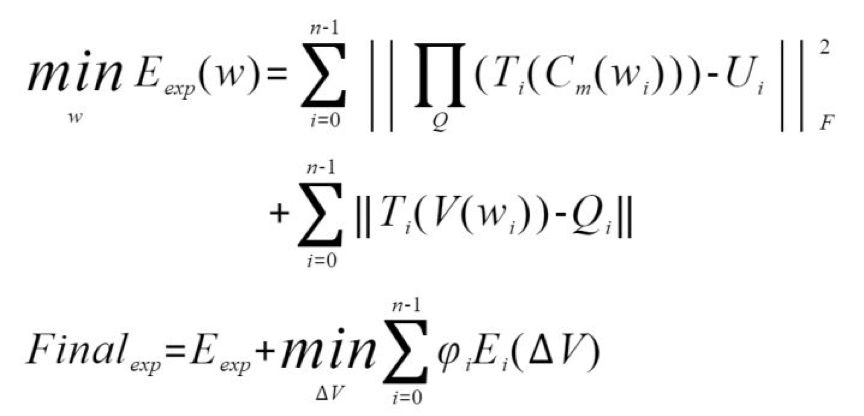
如上图公式 3 所示,基本思想是:同样基于人脸可由基础脸线性组合得出这样一个假设,FACEGOOD 团队研发了这样一套算法,Cm 是 FACEGOOD 3DMM 模型,第一步使用高精算法(图示 3)跟踪人脸的 2D 特征点,随后在此基础上拟合出人脸高精度 3D 模型,再通过 V(wi) 进一步优化 3D 模型,这一步的结果基本贴合到人脸。然后继续优化,在得出带有表情的基本 Eexp 之后,加上一个 detaV,使得 3D 模型完全对齐到人脸,到此就得到了一个完整的高精度的 3D 人脸,包括了在眼轮匝肌、口轮匝肌周围细微的高频的微表情信息。
最终,得出精确的 3D 人脸之后,通过肌肉仿真算法,将表情参数重定向到虚拟人物,就跑完了全流程。
· 微表情在戏剧表演中对艺术真实塑造的作用,曹娜,衡阳师范学校音乐系,2016
· T.F. Cootes and C.J. Taylor and D.H. Cooper and J. Graham (1995). "Active shape models - their training and application". Computer Vision and Image Understanding
· Cootes, T. F.; Edwards, G. J.; Taylor, C. J. (1998). "Active appearance models". Computer Vision — ECCV'98. Lecture Notes in Computer Science.
· Bilinear Model for 3D Face and Facial Expression Recognition,Iordanis Mpiperis,Fellow,IEEE,2008.
· Ekman and W. Friesen. Facial Action Coding System: A Technique for the Measurement of Facial Movement. Consulting Psychologists Press, Palo Alto, 1978.
· BRADLEY, D., HEIDRICH, W., POPA, T., AND SHEFFER, A. 2010. High resolution passive facial performance capture. ACM Trans. Graph. 29, 4 (July), 41:1–41:10.
· PIGHIN, F. H., SZELISKI, R., AND SALESIN, D. 1999. Resynthesizing Facial Animation through 3D Model-based Tracking. In Proc. 7th International Conference on Computer Vision, Kerkyra, Greece, 143–150.
· WEISE, T., BOUAZIZ, S., LI, H., AND PAULY, M. 2011. Realtime performance-based facial animation. ACM Transactions on Graphics (Proceedings SIGGRAPH 2011) 30, 4 (July).LIU, X., MAO, T., XIA, S., YU, Y., AND WANG, Z. 2008. Facial animation by optimized blendshapes from motion capture data. Computer Animation and Virtual Worlds 19, 3–4, 235–245.
· LI, H., ADAMS, B., GUIBAS, L. J., AND PAULY, M. 2009. Robust single-view geometry and motion reconstruction. ACM Transactions on Graphics (Proceedings SIGGRAPH Asia 2009) 28, 5.
· BALTRUSAITIS, T., ROBINSON, P., AND MORENCY, L.-P. 2012. 3D constrained local model for rigid and non-rigid facial tracking. In Computer Vision and Pattern Recognition (CVPR 2012).
· CHUANG, E., AND BREGLER, C. 2002. Performance driven facial animation using blendshape interpolation. Tech. rep., Stanford University.



