干货 :建立软件的经济学分析框架,浅议开源软件的经济学特性(附图解)
人类社会正在加速数字化。一个显而易见的事实是,人们生活、工作的方方面面都离不开各种各样的软件。不久以前,人们还不知道什么是软件;从今往后,软件正在吞噬整个世界[https://a16z.com/2016/08/20/why-software-is-eating-the-world/]。当我们仔细考察当今大多数软件的结构时,令人惊讶的是绝大多数软件都依赖开放源代码(简称“开放源码”,Open Source Code)。开放源码并不是人们通常想的那样,由类似微软、甲骨文等这样的专业软件公司开发和维护,并像其他商品那样销售。它们完全是由一些软件开发者和专业人士组织起来的社群来负责开发和维护,而且完全免费给用户使用。除此之外,开放源码完全是公开的,用户可以自由的更改和完善代码,并无限的拷贝和再发行。
鉴于开放源码的诸多好处[Why Open Source Software / Free Software (OSS/FS, FLOSS, or FOSS)? Look at the Numbers! ],越来越多的人和组织都在使用这些开放源码来构建各种软件,同样越来越多的公司也开始投入到开放源码的项目中来。在数字世界,“用的人多了,也就成了基础设施”。就像公路、铁路和桥梁等基础设施在物理世界所起的功能类似,开放源码构建了数字世界的基础设施(Digital Infrastructure)。
在数字世界,开放源码以非常独特的方式、低廉的成本创造出来一种全新的基础设施范式。开源也从一项运动逐渐演变为开源经济学(Open Source Ecnomics),它为数字基础设施建设的投融资提供了一种变革的方案。大数据、人工智能、云计算和区块链技术更成为加速器,使得这项变革会更持续、更持久的为人类社会的数字化和数字经济增长提供强劲的动力。
本文尝试将软件(software)作为一种特殊的商品,来建立一个针对软件的经济学分析框架,并运用这个框架来分析开源软件的经济学特性。
一、软件的经济学分析简化模型
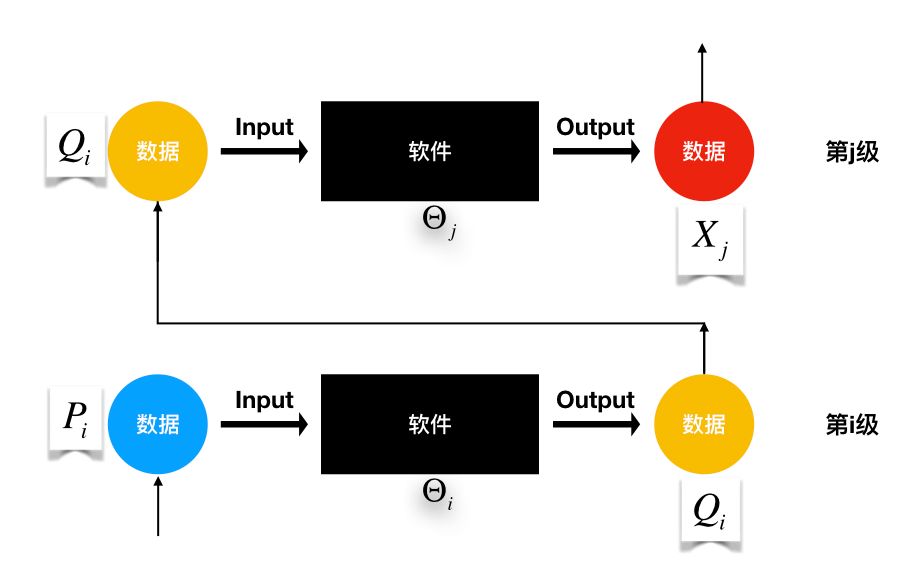
以经济学的视角,人们越来越倾向于将处理数据(Data Processing)的软件(Software)与数据(Data )分开来考察。这两者完全是不同属性、具有不同效用的商品。由此,可以基于经济学研究目的,来定义软件[The Economic Properties of Software,Sebastian von Engelhardt, 2008]和数据的概念。在数字经济中,软件和数据的关系示意图[基于DIKW体系以及数字经济价值链关系构建]如下。
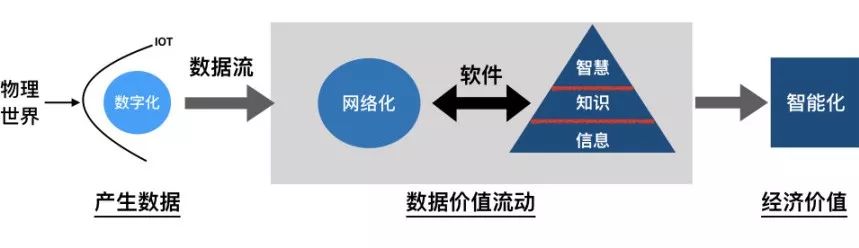
软件是为了处理数据的目的,而按照特定顺序组织/重组的指令和命令的集合。
数据是指所有能作为输入并被软件处理的符号的介质的总称;是作为输入,能够被软件进行处理,具有一定意义的数字、字母、符号和模拟量等的通称。
由于人们对数据安全和数据隐私的关切日益增长,数据权利和权益已经被独立的进行规范[https://gdpr-info.eu]。将数据与处理数据的软件进行分离,在技术层面上,也能很好的界定责任边界。
将数据独立于软件之外的另一个好处是可以建立比较好的微观数字经济学分析框架。因为数据和软件是构建数字世界的原子级要素,因此,微观数字经济学的研究首先要从数据和软件开始。
一个软件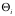
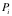
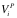
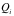
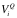
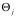
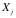
对于软件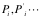
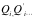
数据的价值我们可以表示为数据对其用户(
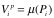
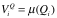
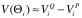
软件
我们将所有按照“输入数据规范[数据规范是数据按照某种方式表示的统称]”——记为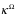
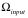
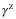
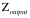
为了简便,假设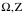
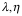
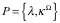
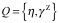
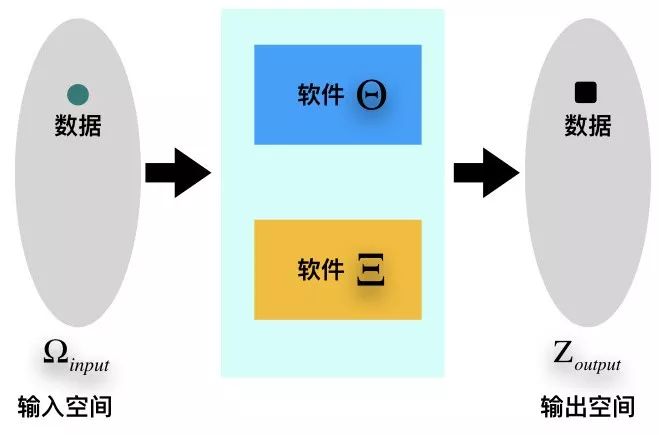
在数据科学领域,输入、输出空间是按照DIKW体系[https://en.wikipedia.org/wiki/DIKW_pyramid]进行设定的。DIKW模型是一个可以很好的理解数据(Data)、信息(Information)、知识(Knowledge)和智慧(Wisdom)之间的关系的模型,这个模型还向我们展现了数据是如何一步步转化为信息、知识、乃至智慧的方式。人们编写特定的代码(软件)来处理数据,其目的很自然的也是期望将数据转化为信息、知识或更高级的形式。这也是软件的价值所在。
因此,输入空间和输出空间的数据规范是与DIKW体系的层次递进关系相对应的:对软件的用户而言,输出空间的数据总是拥有比输入空间的数据更小的信息墒。如果用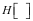
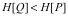
那么,回到经济学的视角,对于可以进行此种变换的全部软件集合而言,其中任意两个软件的价值差异将如何度量呢?
对于任意两个软件
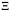
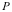
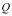
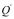
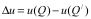

区别于其他商品交付后即无法持续改进或升级,软件的特点是“交付-持续改进/升级-再交付”,每次性能或功能的改进/升级都以版本号的改变作为标志。除非,生产软件的组织消亡,否则理论上软件版本的迭代是可以持续进行的。驱动软件版本迭代的动力在需求确定的情况下(假设I),主要是寻求最优解的过程。
由【引理1】,我们可以得出一个推论:【推论】如果在输出空间中存在一个效用最大的输出数据点,记为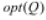
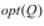
事实上,上述结论只是分析软件内蕴的价值。Katz&Shapiro指出,软件价值有很强的外部性,网络效应(Network Effects)是其中对价值影响最大的因素。由此。上述软件
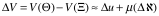
其中,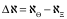
由此,得出一个重要的结论:【引理2】在满足假设I的前提下,软件是一种网络化的商品,其价值由其内蕴因素和网络效应决定。这里的网络效应简单的说,就是当用户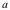
二、开源软件的起源和发展
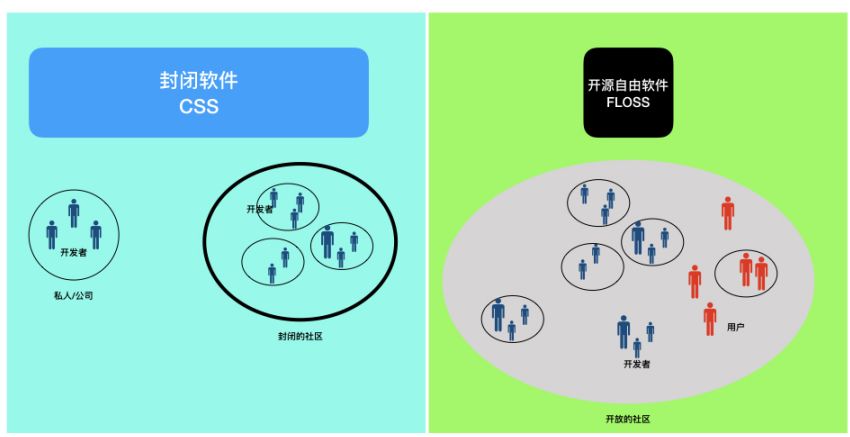
任何软件都以两种基本的形式存在:源代码(Source Code)和机器可读的二进制代码(Binary Code)。按照软件的源代码的权利属性,可以将软件划分为两大类:开源软件(FLOSS:Free/Libre Open Source Software)和封闭软件(CSS:Close Source Software)。按照软件在用户和机器之间的层次,可以将其划分为系统软件(Operating System)和应用软件(Application Software)两大类。(示意图如下左)
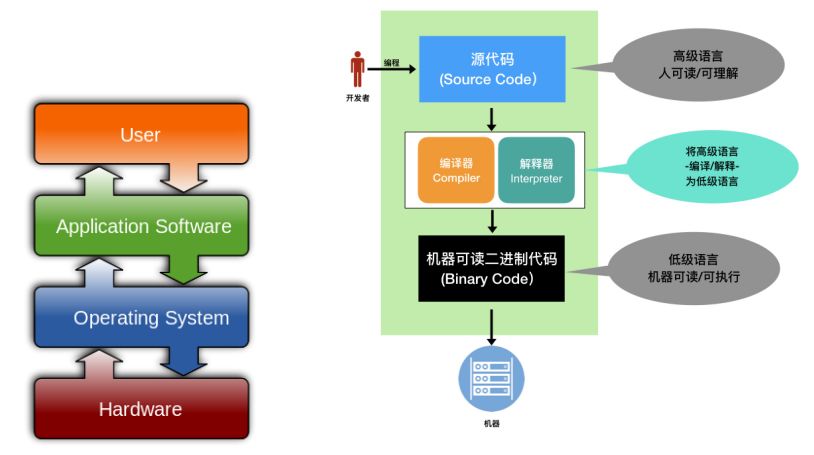
源代码相对机器语言而言,是一种高级语言(如C、Python、Java等),主要是便于人们编写、阅读和理解。机器语言是机器可读/可执行的语言。任何软件要能够工作(runtime),必须由编译器或解释器将源代码转换为二进制代码。转换为二进制代码后才能在机器/虚拟机(VM)上运行。(示意图如上右)
1998年,开放源码促进会(Open Source Initiative)给予了开放源码一个官方的、正式的定义,简称为—OSD[https://opensource.org/osd-annotated]:该定义指出,开源并不只是意味着对源代码的存取访问,而且还要遵守十条准则。这就是说,只有遵守OSD的源代码可公开访问的软件才能被称作开放源码软件。
开源OSD来源于最早的自由软件Debian社群契约[https://lists.debian.org/debian-announce/1997/msg00017.html](Debian Social Contract)。它的具体内容是Bruce Perens[Open Sources: Voices from the Open Source Revolution ]借鉴该契约中的自由软件指南(DFSG:Debian Free Software Guidelines)的部分作为基础,编撰而成。Debian是一个致力于创建一个自由操作系统「名为Debian」的社群组织。其特色在于除了系统内核(Kernel)外,全部使用自由软件来构建。Debian是最早的自由软件项目,为了组织社群来实施这个项目,就拟订了Debian社群契约[https://www.debian.org/intro/about]。
开源软件主要由程序员、计算机工程师及其它软件用户推动的一项运动。它是自由软件(Free/Libre Software)倡议的一个分支。自由软件倡议是基于哲学思想(有时被称为所谓骇客文化)的理想主义所驱动,而开放源码运动则主要注重程序本身的质量提升。从技术中性的角度看,这两种软件并没有太大的区别[https://www.gnu.org/philosophy/floss-and-foss.en.html]。如今,人们将这两大阵营的软件统称为FLOSS(Free/Libre and Open Souce Software)。为了简便,本文将FLOSS统称为“开源软件”。
单单从技术上讲,我们可以简单的遍历一下当前的开源软件:改变软件交付方式的容器技术实现 Docker 是开源软件;基于容器技术实现编排的 Kubernetes 是开源;大数据软件生态圈中的Hadoop、Spark、Kafka、Hive、Hue……都是开源软件;当前最火热的人工智能,亦是由开源所驱动,如 TensorFlow、MXNet等等。更早的开源软件Linux占据全球超算前500名,90%的云计算的操作系统使用的都是Linux;还要数不清的智能手机和设备使用的是开源软件Android。
就在10年前,人们都很难想象,Linux这样一个世界级的操作系统是用互联网连接起来的、分布在全球的几千个开发人员用业余时间构建的。现在,很多世界级的软件系统(Docker,Kubernets等)都是采用这样的方式构建的。
即便像微软、甲骨文、谷歌等这样的巨头公司,也很难想象能够招募到、负担起那几千个为linux出过力的软件工程师。在解决问题方面,没有任何公司可以与linux的“社区头脑库”相匹敌!在回顾linux社区为什么取得如此巨大的成就时,Linux基金会创始人linux Torvalds认为,FLOSS软件是一种文化,这种文化胜利的原因,不是因为群体协作在道德上是正确的,或软件“囤积居奇”在道德上是错误的,而仅仅是因为开源社区可以把更大更好的开发资源放在解决问题上。
开源软件界的知名人物 Eric S.Raymond 在其天才作品《大教堂与集市》 中指出,“95%的软件生产出来是来使用的,而不应是销售的,因此,软件是可以且应该是开源的。”
开源软件追求的是开源,而不是免费。开源软件用户拥有四项基本权利[GUN.org]:
自由运行软件;
自由学习和修改软件源代码;
自由再发布软件拷贝;
自由发布修改后的软件版本。
为了保持软件自由,社群认为,必须按照著作权的规定,通过构建一些特殊许可证来实现。虽然任何人都可以写出自定义的许可证,但要写出一个真正想表达其要求、而且在法庭上有效的许可证是一件很麻烦的事。由此,社群开发了一些标准的、规范的许可证解决了这个问题。目前有三种最常使用的开源软件著作权许可证:
GNU General Public License (GPL),这是世界上最通用的自由软件许可证。
Artistic License (艺术家的许可证)。
BSD License。
由此,开源软件就是按照OSD或自由软件的规则,来进行软件的开发、维护,并按照对应的软件著作权许可证,发布和使用的软件。
目前开源的不仅有软件的源代码,还有一些编译器/解释器也开源了其源代码。
相比封闭软件,开源软件在哪些方面具有优势呢?
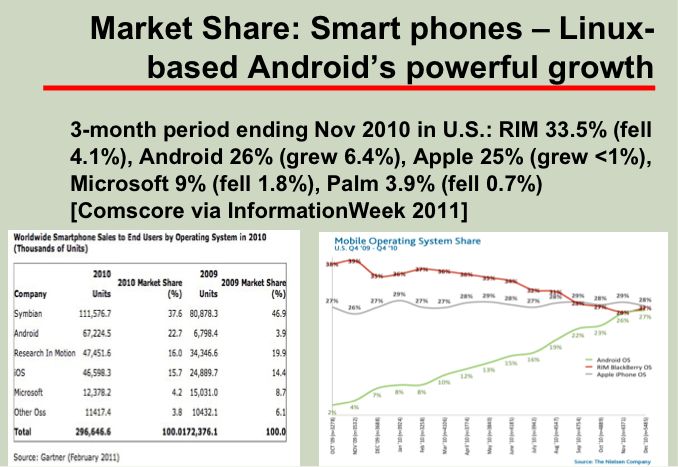
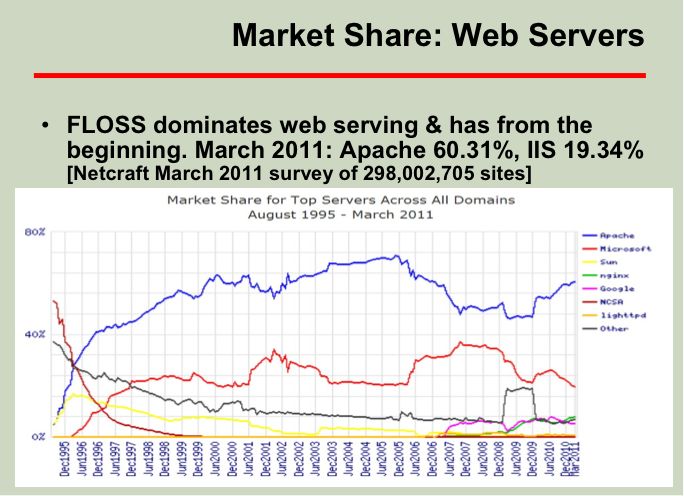
David. Wheeler构建了一套指标体系,用来说明开源软件的独特优势。用非常翔实的数据,分析指出,开源软件在各个领域的市场上都拥有较大的市场占有率、更可靠稳定的性能、更高的安全性以及规模效应。(例子:下图为web server以及智能手机操作系统的比较)
开源软件更为详细的研究[https://web.archive.org/web/20160920231938/https://www.whitehouse.gov/sites/default/files/omb/memoranda/2016/m_16_21.pdf]指出,无论政府、军队还是企业,都可以从开源软件中获益。其中最关键的三个因素是:透明度(Transparency)、成熟度(Maturity)、可持续性(Sustainability)和人力资源储备(Talent Reserve)。研究还指出,超过一半的用户会使用第三方的技术提供商来应用开源软件。例如,虽然linux是开源软件,但很多用户还是会付钱给linux的技术提供商(比如Redhat)来获得技术支持。
软件在中国已经成为一个巨大的产业。预计到2020年,中国的软件收入将达到1.2万亿美元,在2016年,使用开源软件所占的比重就超过了83%,计划中要用开源软件的比例为10%,只有约7%的软件采用专有技术[Survey report from China Academy of Telecommunication Research, 2017]。华为公司是中国开源软件领先的开发者、技术服务商,它不仅参与开源项目的开发,贡献代码,而且也分发很多开源项目软件,并提供技术服务。
虽然开源软件的源代码是免费的,但很多公司都可以从提供多样化的服务实现盈利。这些服务包括为用户优化、扩展开源代码;提供开源软件相关的技术支持;构建围绕开源软件的生态体系等。
三、开源软件社区
根据【推论1】,从给定的输入空间到输出空间变换的所有软件集合中,存在最优软件。但这个推论并没有告诉我们实现最优的路径。
开源软件最早是作为一种软件工程方法引入社区的。这种方法是建立一个软件开发者和软件用户的社区。软件的源代码可以被社区中的任何人查看、修改和贡献新的代码。因为,任何人都可以提出质疑,建议和解决方案,软件的每一行代码都被置于“阳光下”,类似大集市的寻优机制就发挥起作用。社区内,人们可以相互学习,知识得到广泛的传播,各种观点可以得到充分的讨论和审视…。Eric S.Raymond 很早就洞察到,这种开放式的软件工程方法有很多优点。很自然的,当社区内部的人才和规模达到一个临界点后,就实现了一种自组织形式:软件被自主的得到不断的优化,以最有效率的方式,逼近最优。
以开源软件linux为例,数据和事实证明,linux系统的稳定性、可靠性和可扩展性等诸多评估软件性能的指标都超过其他同类软件,它被公认为是服务器操作系统的最优软件。
目前的软件工程学还无法告诉人们,针对特定的输入空间和输出空间,怎么开发出一个最优软件。从上面的讨论,可以看出,开源软件无疑成为一种实证最有效,经济最可行的方法。
由于开源软件能够最有效率的逼近最优的软件。对用户而言,其效用相比封闭软件就大。越来越多的用户就会很自然的选择使用它。与此同时,由于开发者可以自由使用开源代码构建新的软件,开源软件就可以作为部件被“装入”越来越多的新软件中。由于这些新软件中都有共同的开源代码,这些新软件之间就形成了某种联系,这就形成了生态圈,开源软件的用户也就会增长。
由此,我们可以得出一个推论:【推论2】开源软件社区的属性决定了它的价值。这是因为,开源软件的每一行代码都是由其社区生产的;开源软件的网络效应也是源自社区的。代码质量和性能是由社区的人力资源和知识决定的。网络效应则是由社区成员行为决定的。
目前已经形成一套对开源软件项目的评估体系:通过采集开源软件托管平台(如GitHub)上的数据,来评估该开源软件项目。这些数据包括:社区的主要开发者以及其水平;托管平台的代码提交/修改/更新频率;代码下载数量;代码贡献活跃度,以及其他数据。通过这些社区数据的分析,能够对该开源软件的发展趋势做出一定的预测。
以经济学的视角,更近一步的研究是将开源软件社区,作为一个开放的虚拟组织(Open Virtual Organization)来研究[Hambley, Virtual Team Leadership:the effects of leadership style and communication medium team interaction styles and outcomes.] [Curseu P L, Emergent States in Virtual teams: a complex adaptive systems perspective.]。这样就可以比较其与公司、NGO等组织形式的差异。这个视角指出,开源软件社区区别于其他组织的显著的特性是经济可持续的大规模群体协作(Mass Collaboration)和网络效应[http://www.congo-education.net/wealth-of-networks/index.htm](Yochai Benkler)。
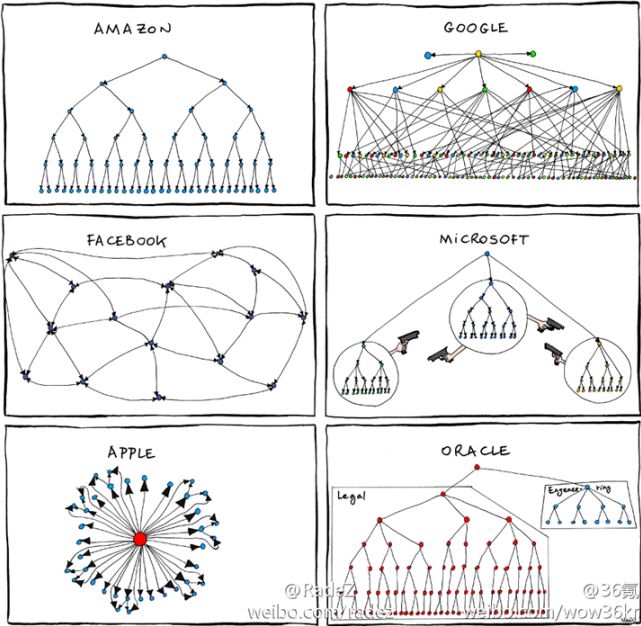
既然开源软件具有这么多的优势,那么采用开源软件社区这种组织架构来生产软件是不是唯一的最佳选择呢?康威定律(Conway Law)[https://en.wikipedia.org/wiki/Conway%27s_law]对这个问题给出了答案。他指出,“一个产品或系统的架构受到其生产组织自身交流沟通结构的制约。” 换句话说,每个组织架构的特性都会被“镜像”[Alan MacCormack, Exploring the Duality between Product and Organizational Architectures: A Test of the “Mirroring” Hypothesis ]到其生产的产品或系统中。以软件为例,也就是说,组织架构与软件架构之间存在“镜像”关系——这个后来被称为“镜像假说(Mirroring Hypothesis)”。因此,并不是所有的软件都适合用开源社区这种组织架构来生产,采用什么样的组织架构最佳,事实上取决于用户的需求。用户的需求决定软件的架构,而按照“镜像假说”,软件的架构最好与生产它所采取的组织架构相匹配。(见左图)
镜像假说更严格的数学描述就是“同构(isomorphism)[https://en.wikipedia.org/wiki/Isomorphism]”。同构是指两个系统在所有本质方面都相同。在软件领域,这个本质方面主要包括任务、过程和关系这三个方面[Ayoko, Managing conflict and emotions for performance in virtual teams.]。
随着开源项目的日益增长,很多问题也逐渐暴露出来。例如,与头部开源项目异常火爆相比,大多数开源项目都吸引不到足够多的开发人才和活跃度。很多开源项目随着时间的增长,很多人都离开社区,而去了更吸引他的其他项目中,社区留下来很少的人,完全凭着一种精神在维护和维持代码。社区内部的冲突也开始变的复杂和难以协调… 数据显示,虽然开源软件占据了非常重要的地位,但大部分开源软件项目都难以为继。人们也在质疑,依托自由精神的开源软件社区是否可以持续?
事实上,开源软件社区的组织形式也在不断演进,特别显著的就是基于区块链的DAO和AI的应用。
随着区块链技术的发展,最近几年出现的去中心化的组织(DAO)发展迅速。DAO全称是Decentralized Autonomous Organization,也称作Decentralized Autonomous Corporation。这种形式的组织的运行完全通过计算机程序,这类程序称作智能合约。 而一个DAO组织通过ICO来进行融资支撑其运营开支,其财务记录以及运行规则都是放在区块链上。这种完全由计算机代码控制运作的类似公司的实体,旨在彻底根除影响公司效率的人为因素,被认为是对于现行的公司体制的一个潜在的变革。
已经有一些软件项目采用DAO的组织形式来生产。这些软件项目大多数是开源的。与传统的开源软件社区不同的是,DAO的成员可以根据其贡献或提供的劳务,获得此DAO发行的代币(Token)。这些代币上市后,可以在交易所进行买卖。购买代币的主要来源被设想是使用这个DAO提供的产品或服务需要支付代币。代币被作为一种激励机制,吸引更多的资源来实现这个DAO的目的。随着代币市场近期表现的暴跌,DAO这种组织形式,赖以生存的根基就显得很脆弱。但DAO仍然被认为是一种潜力很大的组织形式。但它到底适合什么样软件,或许还需要一段时间才能给出答案。
四、开源软件经济学
事实上,开源软件社区已经积累了大量的“可重复使用”的代码库,这些代码库就如同乐高积木块一样已经存在并在持续的被开发出新的积木块。生产新的软件,就变成如何用这些积木块搭建出一个有意义的“乐高玩具”的问题。由人去设计一个蓝图是一个途径;训练机器去实现也是一个可行的途径;人-机混合编程,更是一条潜力巨大的途径。
AI技术的发展,将软件开发推向新的高度。就像训练AlphaGo类似,人们尝试训练可以编写程序的AI Programmer。一项研究报告[Jay,Will humans even write code in 2040 and what would that mean for extreme heterogeneity in computing?]更预计,2040年AI将可以自主编程,人-机混和软件开发模式将成为主流,大多数代码都将是由AI程序员编写的。这些AI也会按照软件工程的分工,更细致的分类为诸如AI架构师、AI数据库以及AI前端等“工种”。
一旦训练出来,由于低廉的成本,可以想象,几万、几十万甚至更多的AI程序员可以组成一个庞大的AI军团来开发某个软件。软件的生产效率、速度会实现几何级数的提高。这样的软件生产组织体系可大幅度降低成本,用户按需定制自己需要的“专用软件”也就成为可能。 在这种情况下,生产出来的软件代码的重要性显著的降低了,选择什么样的AI程序员来生产软件就显得更重要些。
如何让AI程序员公平对待每一个用户,不仅仅是技术问题,还涉及AI的伦理道德。可以设想,如果一个隐藏了某种“偏好”的AI程序员可以对特定的一个或一类用户采用特殊的代码,就会导致这样的问题。现在人们熟悉的Bug、病毒,本质就是将不适当的代码提供给用户。相比Bug可以通过持续的反馈——改进流程来排除,病毒就麻烦很多。为软件用户建立一套类似人体的免疫系统的思路,会成为软件和计算机体系架构变革的主要驱动力。
与此同时,很多第三方技术服务商帮助用户在使用开源软件时做到“量体裁衣”。例如,不是每个用户都需要将庞大的linux装进自己的系统,需要哪些代码,不仅仅是优化问题,更多是适当性的考量。
金融科技外包服务,在过去很长一段时间,由第三方给银行提供硬件以及IT方面的采购、外包服务。而现在,则涉及由软件驱动的功能(如客服、获客)、信息和知识(如算法和模型)等多个维度的服务。科技公司用软件“肢解”了金融的每一个流程,并部分或全部承担了这些流程。那么到底“谁在做金融?” 以往监管并不涉及金融科技公司。但现在越来越多的监管机构开始将金融科技公司纳入监管视野,监管溯源的原则很自然的最终就是对软件源代码的监管。
无人驾驶系统已经发生的一些意外事故,引发一些思考:当一辆无人驾驶汽车面临是撞击一个老人和一个小孩的两难选择的时候,算法到底怎么决定?“谁在驾驶?”的溯源也最终落在软件源代码上。
开源软件社区演进的主要方向是:AI自治的社区(AAC:AI Autoamous Community)和人机混合社区(HAC:Hyper—AI Community)。他们都将面临比现在更为复杂的挑战:如何将“适当的代码”提供给用户。将每一行代码暴露在阳光下,接受最大限度的监督和审查,是过去开源软件取得成功的关键。当软件成为每个人生活、工作的不可或缺时,将适当的代码提供给用户尤其显得重要。
【作者简介】:张家林;
1995年-1997年创办期货经纪公司,北京商品交易所会员,从事商品期货经纪业务。
1995年-2003年涉足证券投资与股权投资。
2006年-2009年在国外从事结构化金融衍生品交易,包括CDO,CDS等。
2009年6月创建私募证券投资管理公司,负责决定公司的投资计划、投资策略、投资原则、投资目标、资产分配及投资组合的总体规划。
2014年初创建金融科技公司,从事人工智能投顾、监管科技的业务。
发表过有金融人工智能、数字货币、网络空间贸易与投资、区块链等二十余篇文章,政策建议。著有《证券投资人工智能》等专著。参与多项央行、证监会的多项优秀课题研究。2017、2018年证券业协会的优秀课题。2015年开始涉足区块链的应用和技术研究。是Hyperledger中国区首家会员,开发多项区块链的应用研究和跨链技术。
「完」
转自:数据派THU ;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
关联阅读
原创系列文章:
数据运营 关联文章阅读:
数据分析、数据产品 关联文章阅读:
80%的运营注定了打杂?因为你没有搭建出一套有效的用户运营体系
合作请加qq:365242293
更多相关知识请回复:“ 月光宝盒 ”;
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。




