人工智能很热,但它离我们的生活并没有那么近,这背后的原因是什么呢?| 陈云霁
本文经授权转载自《SELF格致论道讲坛》微信公众号
“我们也必须要看到一个很现实的问题,虽然大家都感觉人工智能很热门,但它离我们的生活并没有那么近。因为我们在日常生活中,并没有从这种最先进的人工智能算法中得益。那么,这背后的原因是什么呢?”
陈云霁
中科院计算所研究员
智能处理器研究中心主任
人工智能生活化存在现实问题
各位老师、各位朋友,我是来自中科院计算所的陈云霁,非常荣幸能在这里跟大家交流。大家可以看到,PPT的标题叫作“智能之芯”。是的,我们做的芯片是专门面向人工智能的芯片。

人工智能分别运用在人脸识别、语音识别、围棋游戏中
在人工智能领域,很多新的算法、新的应用层出不穷,一些应用已经开始接近甚至达到人类的水平。比如,在人脸识别领域,一些先进的深度学习程序,其识别人脸的能力甚至可以超过成人的肉眼。
在一个叫FW的人脸识别基准测试集中,人类的识别率大概可以做到97.5%,但是最先进的机器学习程序,其人脸识别的准确度甚至可以达到99%以上。在语音识别、AlphaGo这样的围棋游戏领域,人类都并不一定会比机器做得更好。
但是我们也必须要看到一个很现实的问题,虽然大家都感觉人工智能很热门,但它离我们的生活并没有那么近。因为我们在日常生活中,并没有从这种最先进的人工智能算法中得益。那么,这背后的原因是什么呢?
以AlphaGo为例。AlphaGo在跟李世石下棋的时候,它用了1000多个CPU和 200个GPU,所以它平均每盘棋消耗的电费就接近3000美元。因此有人开过一个玩笑,说AlphaGo跟李世石的比赛是一个不公平的比赛,为什么呢?

AlphaGo李世石对战
因为李世石的功耗就像我们一样,大概是20或者30瓦,但是AlphaGo却比他高上百倍。虽然是个笑话,但这也说明人工智能的确存在这种现实问题。现在的人工智能进行任务处理时候,芯片耗电量实在是太高了。
另外一个例子是2012年的一个谷歌大脑,当时谷歌用了大概1.6万个CPU核,组建了一个非常大的机器,科学家让这个机器去学什么事呢?去学怎么识别猫脸。1.6万个CPU跑了一个星期,最后学会了怎么去识别猫脸。
谷歌大脑识别猫脸
识别猫脸这个研究在人工智能领域是一个很重要的进展,因为它可以把猫脸识别的准确度提高很多。但是它从另外一个侧面也说明,现在的芯片在进行人工智能处理的时候,速度实在是太慢了。
试想一下,我们不是每个人都有钱去买1.6万个CPU核或买2000个GPU。即便你是个土豪,买这些东西没有问题,你能否在手机里面存储几千度的电,去使用像AlphaGo这样最先进的程序呢?很显然,都不可以。
因此,我们可以得出结论,现在整个人类社会并没有迈过智能时代的门槛。其实这里面非常核心的一个原因就是,智能时代的核心芯片——智能芯片还没有成熟。
我们要进入工业时代,但如果没有蒸汽机,没有发动机,怎么进入工业时代呢?显然这是不可能的。如果要进入信息时代,没有计算机怎么进入信息时代呢?这也是不可能的。
所以,如果要进入智能时代,那么智能的物质载体一定要成熟。也就是说,我们一定要有新的智能芯片,能够以非常快的速度,非常低的能耗去解决我们日常生活中可能碰到的智能问题。
非常幸运的是,我们中国科学院的计算技术研究所,在这个方向上有比较长期的积累,目前在国际上也走到了一个比较靠前的位置。
人工智能算法与芯片的碰撞
如果我们要去回顾这个故事的话,可能要回到20年前。我们这个团队最开始只有两个人,一个是我,我叫陈云霁,我还有一个弟弟叫陈天石。
我们俩在某种意义上,都是是年轻的“老”科学院人,在大约20年前,我们分别都来到了中国科大少年班读本科。所以,从那时候起我们就成了科学院的人。


陈云霁与陈天石的录取通知书
昨天主办会议的老师让我去准备PPT的时候,我正好看到电脑上有我和弟弟的大学录取通知书,我就把它给贴上来了。1997年跟2001年的科大录取通知书,好像还不太一样,但是“红专并进,勤奋学习”都在里面。
然后我和弟弟又分别到中国科学院的研究机构读研究生,我是在计算所跟着胡伟武老师做芯片方面的研究,陈天石当时在中国科大读研究生,导师是陈国梁、姚新两位老师,研究人工智能算法。

陈云霁与陈天石兄弟二人合影
10多年前,大概在2008年的时候,我们产生了一个想法:我们能不能合起来做一些研究呢?我是做芯片的,他是做人工智能算法的,我们很自然地就会想到,可以一起合作研究人工智能芯片。
这是一个巧合——我们专业背景的巧合,使得我们在同行关注到这个事情很多年以前,就会去做人工智能芯片。另外,2012年到2014年,我们团队还有一位很好的一个国际上合作者叫Oliver Temam,他是“千人计划”的一个教授,在计算所跟我们一起做了一些研究。
我们做的芯片叫“寒武纪”,为什么我们会起这个名字呢?因为寒武纪在地质时代里是一个很原始的时代,但是它也孕育着很多的希望。很多物种都是在寒武纪出现的,甚至很多都出现了爆发性的增长。
我们也希望在当今社会,人工智能和我们的智能芯片也遇到一个爆发性的增长。所以,我们就给这个研究项目起名“寒武纪”。
我们研究这样一个深度学习的处理器芯片背后,有什么样的科学问题呢?研究过程中,我们碰到最大的问题是:怎么去做一个芯片,才能够把各种各样的人工智能或者深度学习算法支撑得非常好?
因为深度学习是一个非常大的“筐”,什么样的东西都可以往里面“装”。比如在深度学习领域,有做语音识别的、有做图像识别的、有做视频理解的,甚至还有做广告推荐或者下围棋的,各种各样的不同程序都属于深度学习范畴。全世界还有几十万个在做这方面研究的算法科学家,这些科学家每天不干别的,就在那改算法。
所以,这里存在一个很大的挑战,我们怎么去做一个芯片,能够把各种各样的深度学习的算法,甚至是我们从来没有见过的深度学习算法,都能够支撑得非常的好,能够比CPU或者 GPU要高很多数量级。
研究路上的“拦路虎”
以下就是我们研究过程中碰到的三个主要的矛盾。
第一个是有限规模的硬件,怎么去支撑任意规模的算法?深度学习芯片核心的计算都是通过硬件的神经元和硬件突触来完成的。可硬件是个铁疙瘩,它出厂的时候里面有多少个神经元,有多少突触是固定不变的;但是算法上有多少个神经元,有多少个突触,程序员自己想定义成什么样,就是什么样,所以这是一个矛盾。
第二个矛盾是我们怎么让结构固定的硬件,去应对千变万化的、不断演进的算法?深度学习算法,有图像、语音、自然语言理解等很多种。但是硬件,它电路的构造在芯片研制出来这一刻,就已经固定下来了。那么,这里面也存在矛盾。
第三个矛盾就是在日常生活中应用人工智能芯片,它有非常严苛的能耗限制。如果我们希望它用在手机里面,那么它的功耗不能超过1瓦,如果用在服务器上它不能超过300瓦。
但是做算法研究的科学家,可能并不会去考虑这么多。比如,当你想去设计一个像AlphaGo这样的算法的时候,你会想我怎么让他下棋下得更好,并不会去考虑他用了多少电。
所以这种越来越聪明的算法,跟只有一点点功耗的硬件之间,也存在一个矛盾。我们怎么去解决这个矛盾呢?我们过去的研究主要就解决这三个主要的科学矛盾。
第一个矛盾是怎么用有限规模的硬件,去把任意规模的算法实现出来。针对这个矛盾我们提出了一种思路,叫硬件神经元的虚拟化。对于做计算机研究的人来说会比较了解“虚拟化”这个概念,但对于信息领域以外的朋友可能接触较少。
硬件神经元虚拟化
所谓的虚拟化就是说,让我们的硬件在某一个时刻装扮成算法上的这一块,下一个时刻我又装扮成另外一块,这就是虚拟化的作用。我在不同的时刻,以时分复用的方式去解决算法中的不同部分。
通过这种硬件神经元虚拟化技术,就可以让有限规模的硬件去解决任意大规模的算法。我们只需要这个硬件第一个时钟周期虚拟成这一块,下一个周期再换一块。这样的话,不管你算法有多大,我们一定能够把它虚拟出来。
对于第二个矛盾,我们的解决方案叫做智能的指令集。结构固定的硬件,怎么去高效地支撑千变万化的算法?针对这个矛盾,我们就提出了国际上第一个智能的指令集。指令集是什么意思呢?
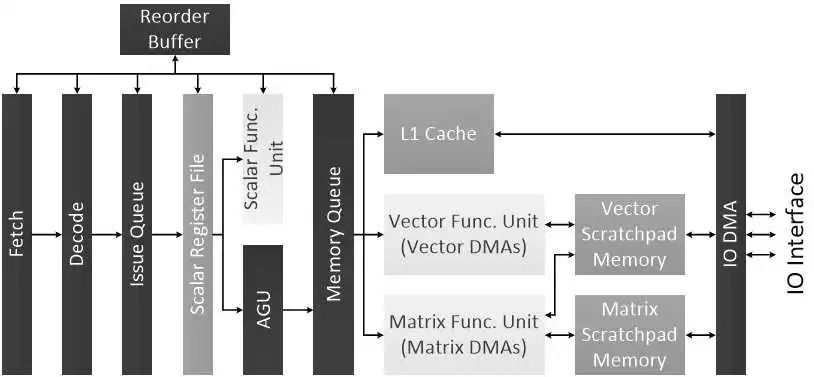
智能指令集
我们把要解决的问题,拆分成一些最基本的小颗粒。然后,如果来了一个我们从没见过的新应用、新算法,并不用担心,只要用这些颗粒去把它拼出来就行了。打个比方,就像是我们买玩具的时候,你可能会买一个坦克玩具,或者一个飞机玩具。
但是还有一种玩具就叫乐高积木,乐高积木就有很多基本的小颗粒,有了这些小颗粒之后,你愿意拼一个飞机也可以拼,你愿意拼一个坦克也可以拼,愿意去拼一个宇宙飞船也可以拼。实际上,我们智能的指令集,就相当于一个智能的乐高积木,有了这样的积木,就可以把所有的智能算法都高效地拼出来。
解决第三个矛盾的方法是稀疏化的处理。我们的主要目标是用很低的能耗去把非常复杂、高能耗的算法实现出来。在大规模神经网络中有很多硬件神经元突触,它们的绝对值可能很接近于零,那么我们就把它约等于零。用机器很高效地去把这些等于零的东西跳过去,大致就是这样一个思路。
解决了三个问题之后,我们研制了一系列专门为深度学习和人工智能服务的芯片。
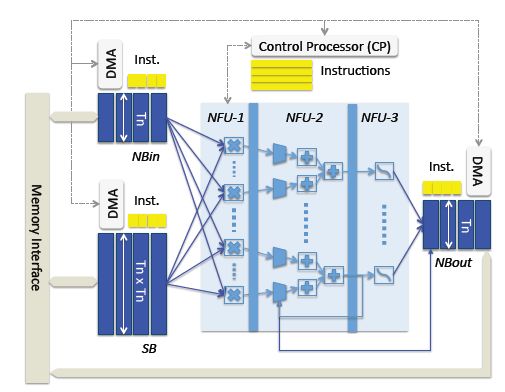
这是我们在2013年做的工作,这是国际上第一个深度学习专用处理器的架构。
“DianNao”国际首个深度学习处理器
当时我们给它起了一个英文代号叫作“DianNao”,其实最开始我们想叫它Electric brain,是电子大脑的意思。但是我们的外籍合作者Oliver Temam教授说:“别,千万别。你还是起一个中国的名字比较好。”
大家都觉得外国的东西很有意思,很先进,对吧?所以起个中国名字,对于外国人来说,也会觉得很先进。所以,就有了这样一个名字。
后来,这项工作在国际会议ASPLOS上拿到了最佳论文奖,这是整个亚洲地区第一次在计算机体系结构的国际会议上拿奖。那么有了“电脑”之后,我们又做了国际上第一个多核的深度学习处理器,它很大,所以它叫作“大电脑”。
到后来我们又做了一个名为“普电脑”的芯片,因为“电脑”跟“大电脑”只能做深度学习,还有很多其他的人工智能算法怎么支持呢?我们就做了“普电脑”,这是一个比较普适的芯片。

“普电脑”
最后很有意思的是,2016年,有个加州大学伯克利分校的教授,是一个洋人,我从来没有见过他,之前也不认识他。他在我们这个领域非常重要的一个期刊《Communications of the ACM》上专门写了一篇文章,去专门介绍我们过去写的论文里面,这些汉语拼音到底都是什么意思?他也没有问过我,估计他是查了谷歌翻译。没想到我们的论文居然间接地弘扬了一下中国文化。
从学术研究到实现商用
今天,我们的工作已经不仅仅限于在学术界产生影响力。现在每年已经有数千万的手机或者摄像头,在使用我们研制的这种专门深度学习的处理器。像这个例子里面大家看到的华为Mate10手机,当然除了它之外还有很多,比如华为P20、荣耀等各系列的手机,也包括联想、曙光、阿里的服务器,都在使用我们的寒武纪深度学习处理。
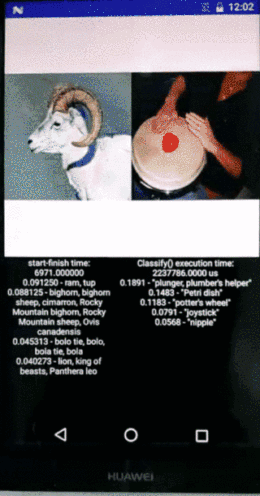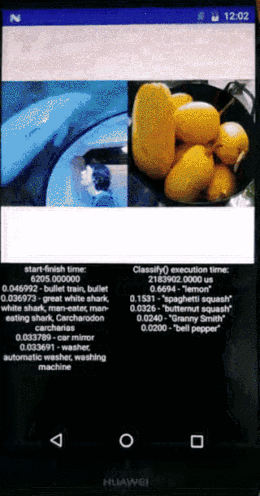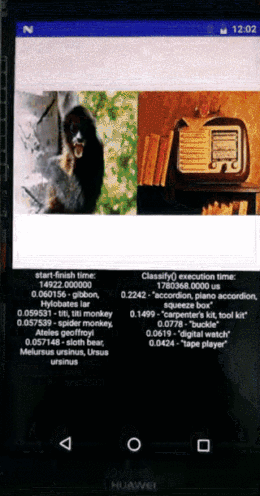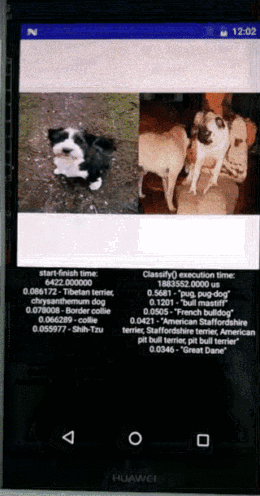
上图展示的是图像识别的速度,一边是在手机上面用CPU做图像识别,另外一边是寒武纪做图像识别,识别速度有非常显著的差异,性能甚至达到1~2个数量级的提升。
有了寒武纪这样的芯片,我们在手机上就可以完成很多复杂任务,比如图像识别、语音识别。我们的人工智能芯片还有很多是用在服务器上的,这个是我们2018年4月份的一项工作——MLU100。这是同期国际上峰值性能最高的智能芯片,已经在阿里、联想、曙光、讯飞等很多企业里面做商用。


高性能通用智能芯片MLU100
2018年2月份的时候,《Science》杂志对我们进行了专门的报道,称我们的工作是一个颠覆性的进展,是这个方向的引领者和先驱。我们非常自豪地看到,从我们做第一个深度学习处理器到今天,只过去了4~5年的时间。我们的这个方向已经成为国际芯片领域最热门的方向,我们的工作也进入了教科书。

《Science》杂志对该项目的评价
现在国际上有上百个研究机构,包括哈佛、斯坦福、MIT、伯克利、UCSB、USLA、IBM、英特尔、惠普、谷歌等,有几十个美国的科学院院士或者ACM Fellow引用跟踪我们的论文,去从事这种深度学习专用处理器的研究。从10年前,我们是孤独的研究者,到今天有这么多同行者,我们非常欣慰也非常高兴。
2018年5月份的时候,习近平总书记在院士大会的重要讲话里,专门提到自主研发的人工智能深度学习芯片要实现商业化的应用。两天之后,《人民日报》的头版也对我们的工作进行专门报道,宣传贯彻习近平总书记的讲话内容。

《人民日报》头版报道
但这是我们过去做的一些工作,未来我们还有更远大的梦想,我们希望能够把代表性智能算法的处理速度和能效提升1万倍。为什么是1万倍呢?
谷歌大脑是用了1.6万个CUP核,如果提升1万倍,就意味着我们可以把过去的超级计算机才能做的任务塞到我们的手机里面,我们每个手机都会成为一个智能超级计算机,能够不断地去学习,不断跟着我们一起提高。
全世界有几十亿台手机,如果能连在一起,那么每天它都可以从手机用户得到很多的输入和指导。也许有一天,手机可以萌发出一些我们意想不到的智能。
我刚刚讲的这些研究工作,只是中科院计算所人千千万万工作中很小的一部分。60年前我们研究所刚成立的时候,美国和苏联对我们进行了技术封锁。
当时中国没有计算机,计算所就研制了我们国家第一台电子计算机,在“两弹一星”的研制过程中完成了大量计算任务,为我们国家打破封锁起到了很大作用。
40年前我们迎来了改革开放的春天,就是这盛放的40年,我们所又创办了很多的企业,像联想、曙光这样的企业使得我们国家计算机产业建立起来,打破垄断。
今天,作为新一代的科学院人,我们中科院计算所更多的使命是要改变过去。改变过去总是处于引用、跟踪国际同行的状态,现在我们要做一些新的东西,去做能引领国际学术前沿发展的东西,这是我们新科学院人的使命。我就说这些,谢谢各位。





