SDM 2022 | GNN预训练中的自适应图表示 —— 图匹配任务
© 作者|侯宇蓬
机构|中国人民大学
研究方向|图机器学习和推荐系统
今天要介绍的论文是我们小组和蚂蚁集团合作,发表在 SDM 2022 的一篇论文。我们提出了一系列基于图匹配的图神经网络(GNN)预训练方法,使 GNN 在预训练阶段生成自适应的图表示,在单一任务中同时训练节点与图级别的信息。我们基于通用的可学习的图匹配层,为自监督和粗粒度监督预训练这两个场景设计了对应的预训练任务,并针对图匹配网络复杂度高的问题进行效率优化。我们在两个场景的公开的 benchmark 上与已有方法进行了比较,验证了提出的 GNN 预训练算法 GMPT 的效果。文章也同步发布在AI Box知乎专栏(知乎搜索 AI Box专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!

论文题目:Neural Graph Matching for Pre-training Graph Neural Networks
论文下载地址:https://arxiv.org/pdf/2203.01597.pdf
论文开源代码:https://github.com/RUCAIBox/GMPT
一. 背景
近些年来,图神经网络(GNN)发展火热,迅速席卷各类图表示学习任务。然而,GNN 在应用于下游任务时,需要充足的带标注的图数据用于训练。现实中,任务相关的图数据又往往难以标注,使 GNN 模型难以达到很好的效果。为了缓解数据稀疏的问题,这两年来研究人员开始探索预训练+微调的范式,先在大规模无标注(或粗粒度标注)的图数据上预训练 GNN,再将预训练模型迁移至下游任务数据上微调。
已有的图网络预训练的工作着重于设计预训练任务。已有的预训练任务主要分为两类:(1)图级别(graph-level)一般是学习整个图的表示,用于图级别标签预测或图对比学习;和(2)节点级别(node-level)一般是学习节点的表示,用于特征或者局部图信息的预测。
关于图对比学习及 GNN 预训练的详细介绍也可以参考《顶会论文看图对比学习研究趋势》和《图神经网络上的预训练和自监督学习》两篇博客。
二. 动机
已有经验表明,在预训练 GNN 时有必要同时结合两个级别的优化目标。现有方法或采用两阶段训练模式依次优化;或采用多任务学习的模式。然而每个单独的预训练任务都无法同时知晓图和节点级别的信息,可能会导致另一个级别的表示没有得到充分的优化。我们能否设计一种预训练任务,使 GNN 在单一任务预训练下能够同时学习节点和图级别的语义?
三. 思路
因此我们提出基于图匹配(graph matching)的 GNN 预训练任务。给定一对儿图,我们将评估它们结构上和语义上的相似性。
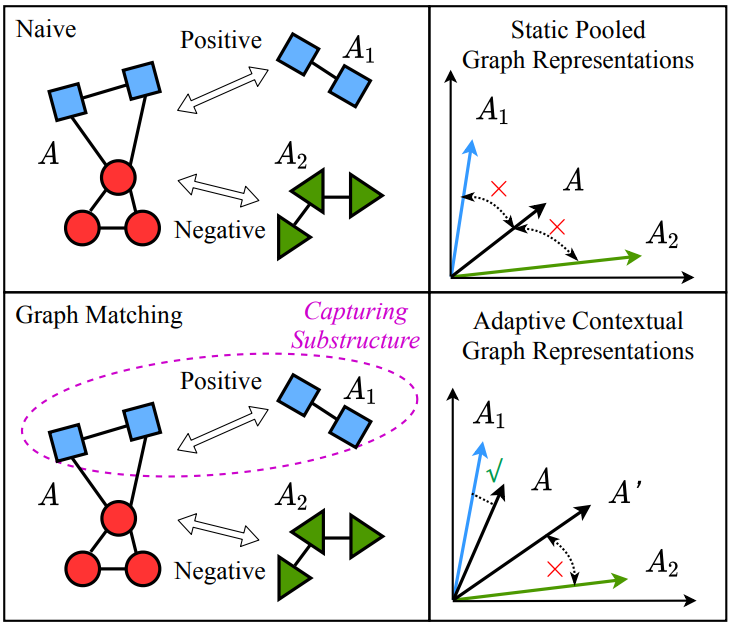
图和节点级别信息的融合。在图匹配的过程中,会同时关注于节点级别的关联(比如两个节点特征是否相似)和图级别的性质(比如两个图是否相似、是否含有共同子结构等)。
自适应的图表示。经由可学习的图匹配网络编码,在面对不同的图时,一个特定的图会自适应地产生不同的图表示。如上图例所示,当仅使用 GNN 进行静态图编码时,三个图的表示可能都不甚相似。而借由图匹配网络进行自适应编码时,由于A 和 A1 含有共同的子结构,在面对 A1 时,A 的表示与 A1 的表示靠近,在面对 A2 时则远离。
四. 方法
具体地,我们提出 GMPT(Graph Matching based GNN Pre-Training),针对针对(1)自监督和(2)粗粒度监督两种预训练场景分别设计了具体的基于图匹配的 GNN 预训练任务。
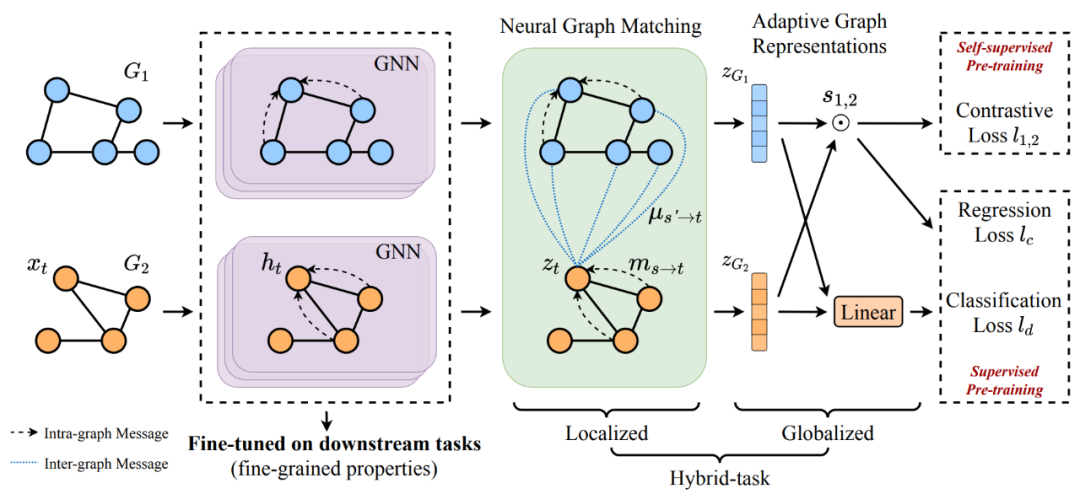
4.1 通过图匹配自适应学习图表示
在进入具体任务前,我们首先介绍基于图匹配网络,学习自适应图表示的方法。给定图 1 和 2,我们首先用待预训练的 GNN 为其学习节点表示。在拿到经过 GNN 编码的节点表示后,我们再进一步使用图匹配网络编码得到各自的自适应图表示。
具体而言,图匹配网络依然遵从 GNN 中经典的消息传递机制,只不过在更新目标节点 t 的表示时,传递而来的消息不仅来自图内某节点(图内消息,intra-graph messages)也来自于待匹配的图的某个节点(图间消息,inter-graph messages)。
对于图内消息,我们可以使用和待预训练的 GNN 相同的形式;对于图间消息,我们可以采用注意力机制进行计算。
经过与待匹配图充分的消息传递,我们可以得到增强后节点表示。
这些匹配增强后的节点表示经过池化等操作即可得到自适应的图表示。
4.2 自适应图表示下的对比学习预训练 GMPT-CL
在自监督场景中,我们可以获得大量无标注的图数据。一个常用的预训练目标是图对比学习,一般是通过随机数据增强给 batch 中每个图产生不同的视图,并设定同一个 graph 生成的不同视图之间为正例,其他视图之间为负例。在这里,我们采用同样的流程预训练 GNN。
其中
同时我们注意到,引入图匹配网络不可避免地会带来更大的时空复杂度。因此我们设计了近似对比训练(Approximate Contrastive Training)策略,来减少时空消耗。具体来说,对于 n 个图的 batch,传统的方法需要进行 次匹配,我们则均匀采样 q 个视图与其他同 batch 视图进行 次匹配。同时我们采用梯度累加策略,仅保留 次匹配所需的计算图,单次计算后累计梯度,待一个 batch 计算完整后统一更新。通过此操作我们可以大大减少时空复杂度。同时我们对此策略下的优化目标给出了理论分析,具体的推导可以参考原论文。
4.3 粗粒度有监督预训练 GMPT-Sup 和 GMPT-Sup++
除了在大规模无标注图数据上进行自监督预训练,有时我们可以获取到经过粗粒度标注的图样本。与精细标注的标签不同,粗粒度标签与下游任务有相对很弱的关联,但是标注的获取是相对容易的。
当粗粒度标签是连续的实值时,标签可以被视为实数空间中的向量。我们这里假设,相似的图对应的标签向量也是相似的。因此我们提出 GMPT-Sup,优化图相似性分数和标签相似性分数之间的差距,并使用 MSE 损失进行优化。
当粗粒度标签是离散的 token 时,我们无法对一对儿图的标签进行显示地比较。因此给定一对儿随机采样的图,我们联合预测它们的粗粒度标签,并使用 BCE (Binary cross-entropy) 损失优化。
注意到,尽管两个图的损失是分别计算的,但它们的表示是由图匹配网络学习得到的自适应图表示。
五. 实验
我们在公开的 benchmark 上与若干 GNN 预训练的基线方法进行比较,每组结果均为 10 个标准随机种子取平均得到的。具体的代码和预训练模型已经开源:https://github.com/RUCAIBox/GMPT。
5.1 自监督预训练
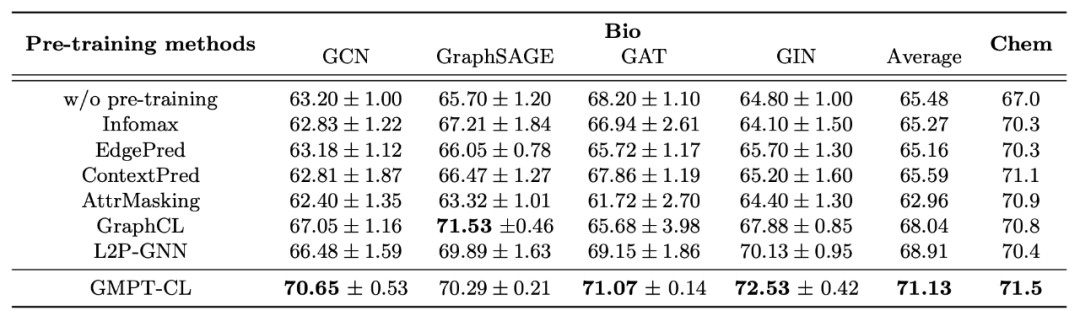
可以看到,我们提出的 GMPT-CL,对不同的 GNN 进行自监督预训练,都可以达到不错的效果。
5.2 粗粒度监督预训练
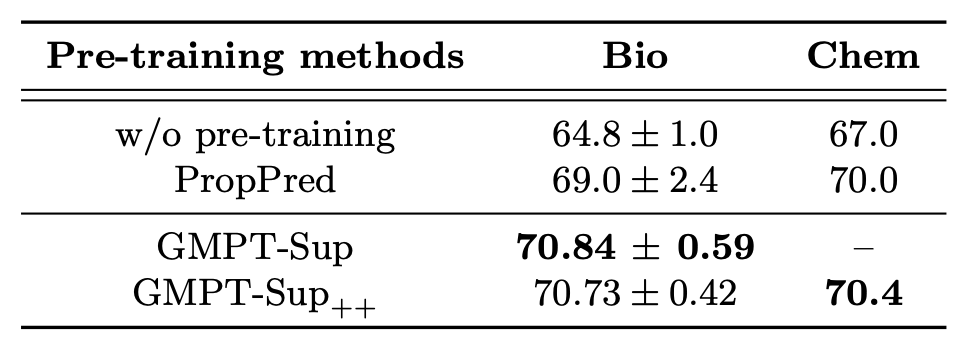
粗粒度监督的基线方法较少,我们提出的基于图匹配的标签相似性预测(GMPT-Sup)和联合标签预测(GMPT-Sup++)方法在两组数据集上均达到了最优。注意 Chem 数据集上,粗粒度标签存在较多缺失值,此时使用适配范围更广的 GMPT-Sup++ 是更合适的。
5.3 近似对比训练策略
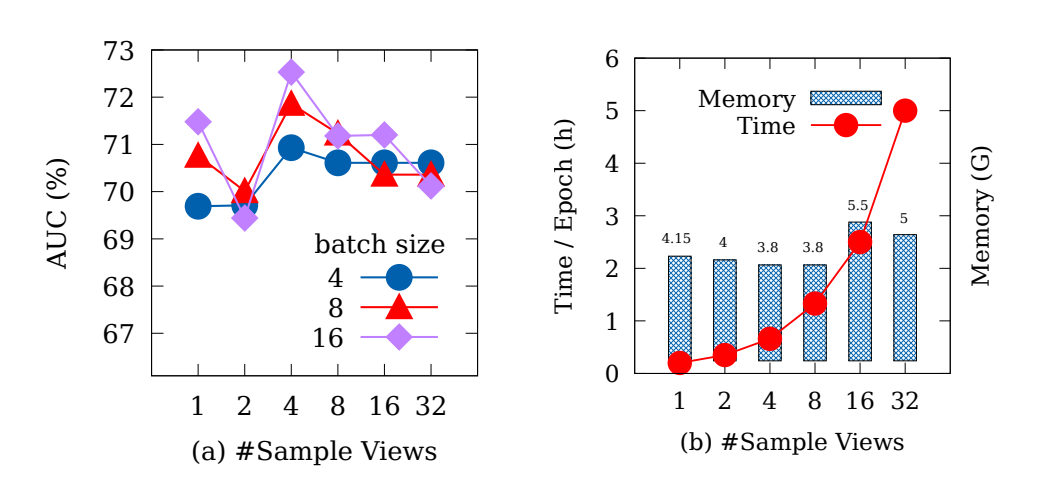
我们对提出的近似对比策略也进行了分析。可以看出,在对比学习的 pair 中采样并没有对迁移效果产生显著影响,反而当采样个数合适时,会提升迁移性。同时,在效率方面,训练时间随采样个数线性增长,而所需的显存则无明显变化。
5.4 迁移性分析
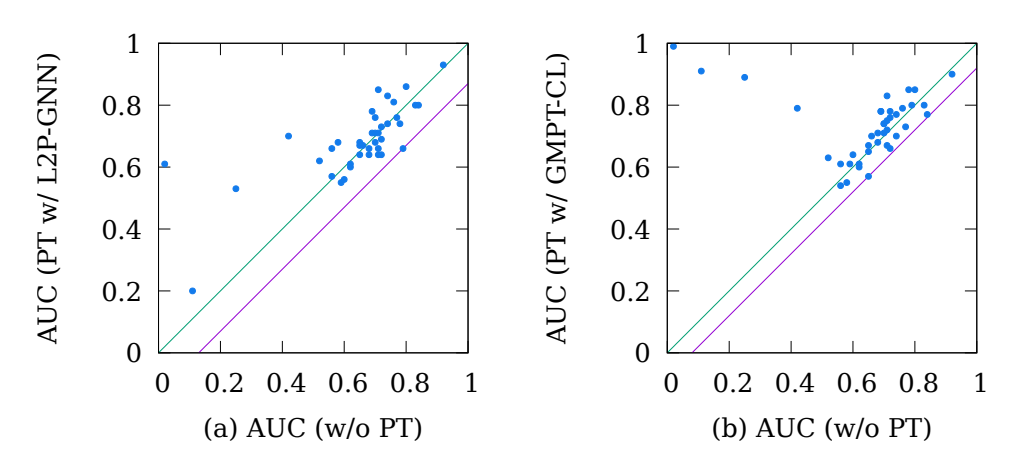
这里,我们分析提出的方法的迁移性。横轴代表不经过预训练时,Bio 数据集各个子任务的效果;纵轴代表基线方法和我们提出的 GMPT-CL 预训练后,子任务的效果。其中绿线左上方的点代表预训练提升了子任务的效果,反之代表下降,即负迁移(negative transfer)。而紫线则代表不同方法中,负迁移水平的极值。绿线和紫线之间的距离越近,代表负迁移越不明显。由图可见,我们提出的方法可以较大程度缓解负迁移现象的产生。在 Bio 数据集上,我们的方法使 GNN 在预训练后,各个子任务都训练到了一个相对较优的水平(AUC > 0.5)。
六. 总结
我们提出了一系列基于图匹配的 GNN 预训练任务 GMPT。它能在单一任务中同时鼓励 GNN 捕捉节点和图级别信息,并产生自适应的图表示以更好地表达图之间的相似性。同时我们提出了近似对比训练策略,可以有效缓解图匹配预训练中额外增加的时空开销。我们在自监督和粗粒度监督两个场景下设计了具体的优化目标,在公开 benchmark 上的实验也验证了提出方法的效果。
欢迎大家通过邮箱(houyupeng@ruc.edu.cn)或 GitHub 的 issue 区与笔者进行交流~
更多推荐
WSDM 2022 | C2-CRS:用于对话推荐系统的由粗粒度到细粒度的对比学习预训练

WWW 2022 弯道超车:基于纯MLP架构的序列推荐模型



