【论文推荐】结合KB和answer selection的相关论文推荐
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要11分钟
跟随小博主,每天进步一丢丢


来自 | 知乎
地址 | https://zhuanlan.zhihu.com/p/52057462
作者 | 是江晚晚呀
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
《Multi-Task Learning with Multi-View Attention for Answer Selection and Knowledge Base Question Answering》
来源:AAAI2019
链接:arxiv.org/pdf/1812.0235
MOTIVATION
1、KBQA和AS任务都可以看作是一个排序问题,一个在text-level,一个在knowledge-level。
2、AS可以整合来自KB的外部知识,KBQA可以通过在AS中学习到的上下文信息来改善。
3、为了实现联合学习这两项任务,本文考虑用多任务学习。现有的多任务学习框架一般把模型分为task-specific layers和shared layers。所有任务共享shared layers,对于每个任务,task-specific layers是独立的。这会忽略task-specific layers和shared layers的内部联系。
CONTRIBUTIONS
这篇文章提出了一种multi-task learning方案,从多个视角学习multi-view attention,使得KBQA和AS任务相互作用。具体来说:
1、通过组合来自task-specific层的attentive信息以在shared层学习更复杂的句子表示。
2、另外,multi-view attention机制通过结合word-level和knowledge-level信息增强句子表示学习。即:通过multi-view attention方案,word-level和konwledge-level的attentive信息在不同任务中共享和迁移。
最后在每个单任务上,这篇论文都实现了非常不错的效果。而且证明了多视角的注意力机制可以有效地从不同的表示视角上组合注意力信息。
MODEL
Multi-Task Question Answering Network
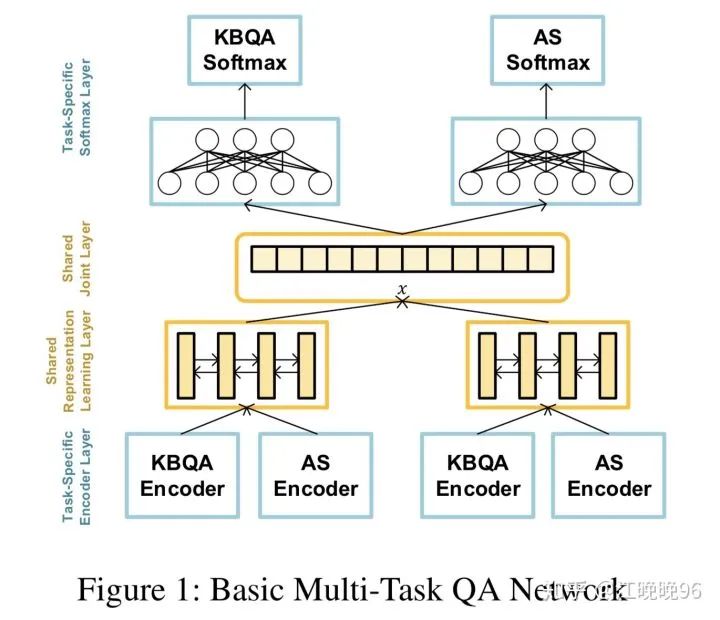

首先,AS任务和KBQA任务的多任务学习起始于实体链接结果。如表1所示,对于每个问题和每个候选答案,有单词序列 

1、Task-specific Encoder Layer
这里对于问题和答案都用了task-specific siamese encoder
(1)Word Encoder
输入词向量序列:
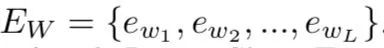
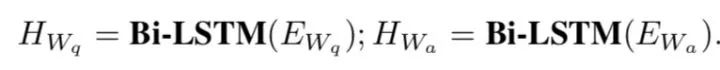
(2)Knowledge Encoder
输入知识嵌入序列:
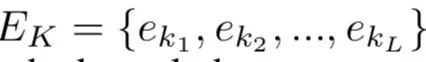
知识嵌入序列由一系列标记好的实体或者关系名称组成,而我们在后面的学习过程中需要更high-level的knowledge-based表示,所以将知识嵌入序列通过一个CNN,在知识嵌入矩阵上滑动,窗口大小为n,捕捉局部的n-gram特征。隐层向量计算如下:
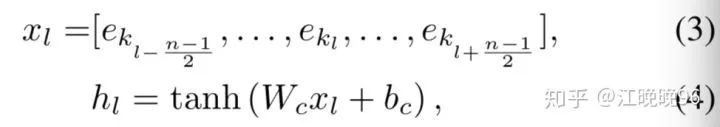
由于实体长度的不确定性,用了多种size的filters,得到不同的输出向量:
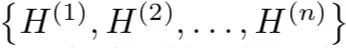
将这些输出向量通过一个全连接层以获得knowledge-based句子表示,L是句子长度,df是CNN的filter大小。
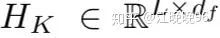
对于问题q和答案a,knowledge-based句子表示分别为:
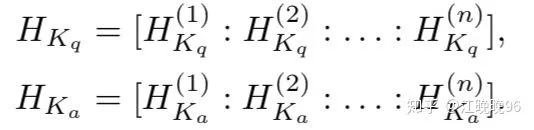
得到word-based句子表示和knowledge-based句子表示后,把它们连接起来:
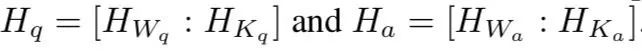
2、Shared Representation Learning Layer
用task-specific encoder把句子编码成向量表示后,通过一个共享表示学习层将不同任务的high-level信息进行共享。
整合两个任务的编码向量并通过一个high-level shared Siamese Bi-LSTM,生成最终的QA表示:
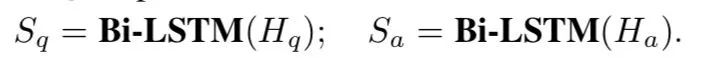
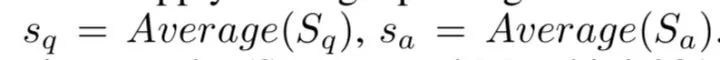
然后还整合了一些word overlap和knowledge overlap特征 
最后的特征空间是:
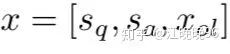
3、Task-specific Softmax Layer
给定question-answer pair q(t) and a(t)和它在第k个任务的的标签y(t),分类层:
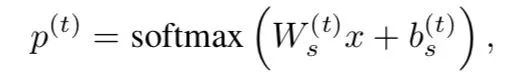
Multi-Task Model with Multi-View Attention
1、Multi-View Attention Scheme
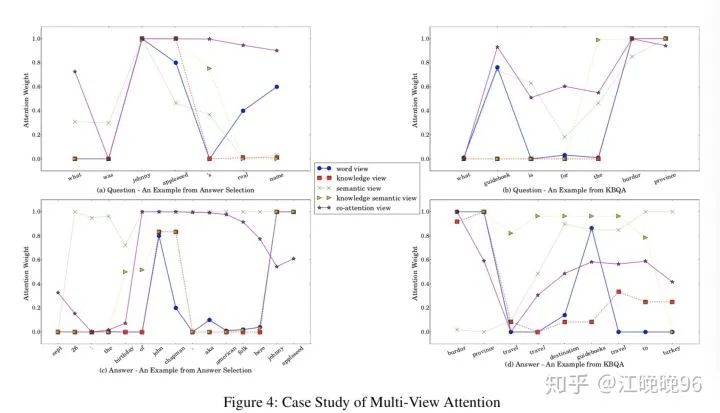
为了在表示空间增强不同任务之间的相互作用,提出一种multi-view注意力机制。首先,不仅仅利用task-specific层的attention,还结合了shared层的attention。其次,从word-level和knowledge-level这两个视角分别获得注意力信息。具体来说,有5个视角的attention:the views of word, knowledge, semantic, knowledge semantic and co-attention.
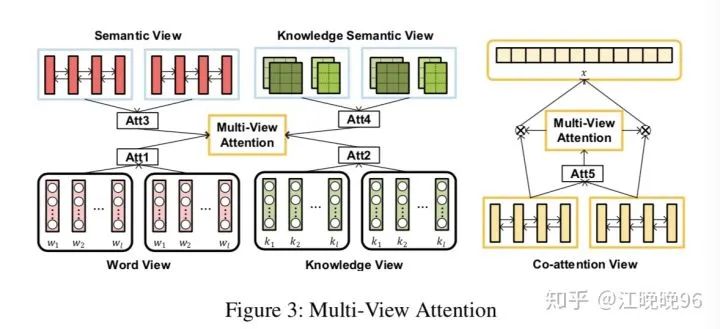
2、Word View & Knowledge View
这里用了双向注意力机制来得到word view和knowledge view的注意力权重。
首先计算两个注意力矩阵:
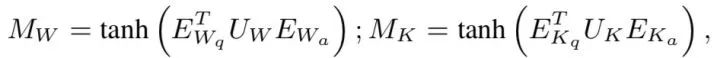
然后分别对行和列做max pooling,分别得到word view和knowledge view的问题和答案的注意力权重:
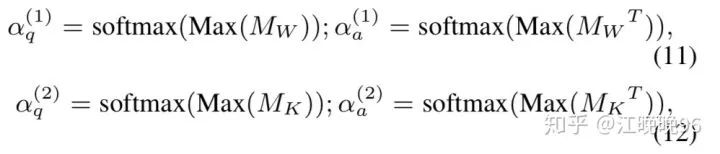
3、Semantic View & Knowledge Semantic View
对task-specific编码层的输出进行max/mean pooling以获得一个句子的整体语义信息,通过实验,下面这种pooling方法表现最好:
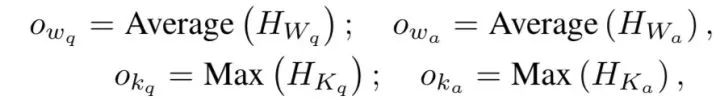
semantic view:
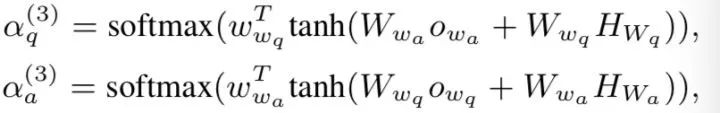
knowledge semantic view:
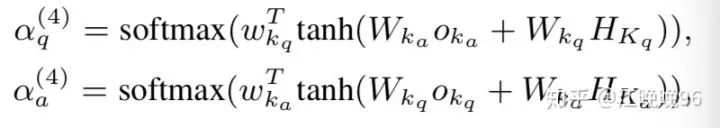
4、Co-attention View
这里也用了双向attention机制,以生成最终问题和答案表示之间的co-attention:
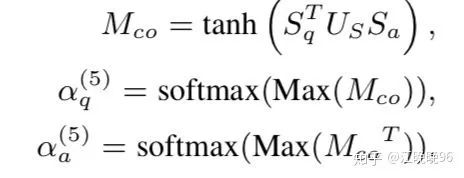
5、Multi-View Attentive Representation
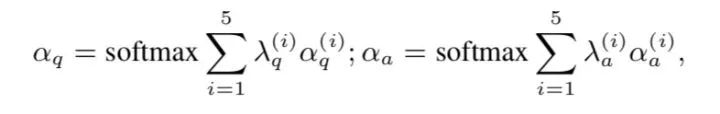
最后的attentive QA表示如下:
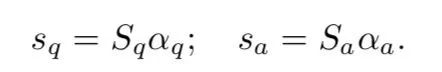
Multi-View Attention Sharing
因为多视角的attention是用在共享表示层的隐层状态上的,所以计算注意力的参数应该在多个任务上共享。同时,由于多视角attention聚集task-specific层和shared层的信息,多个任务是通过多视角attention联系的。
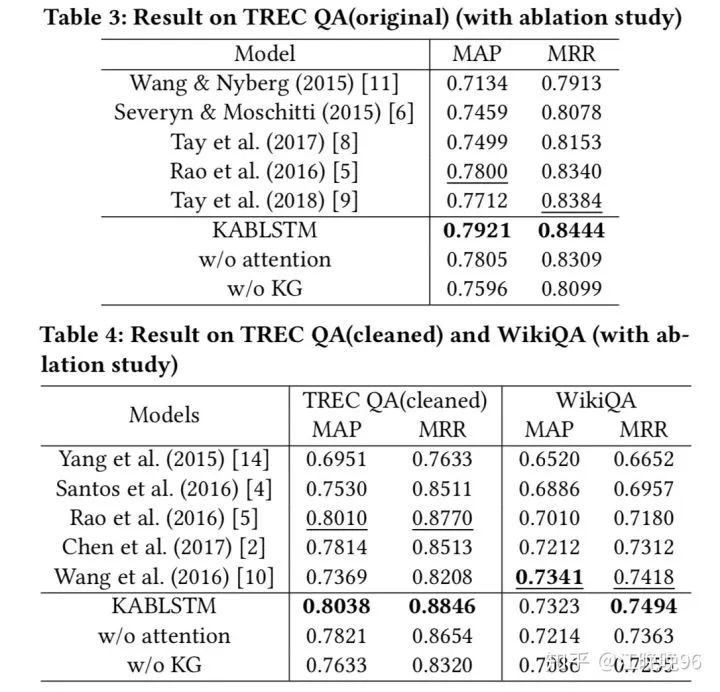
EXPERIMENTS
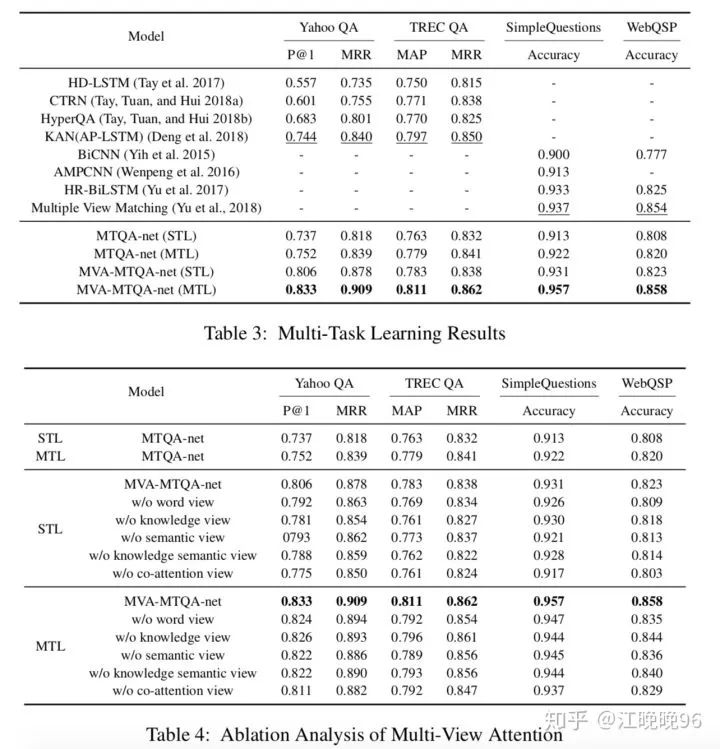
《Knowledge-aware Attentive Neural Network for Ranking Question Answer Pairs》
来源:SIGIR 2018
链接:delivery.acm.org/10.114
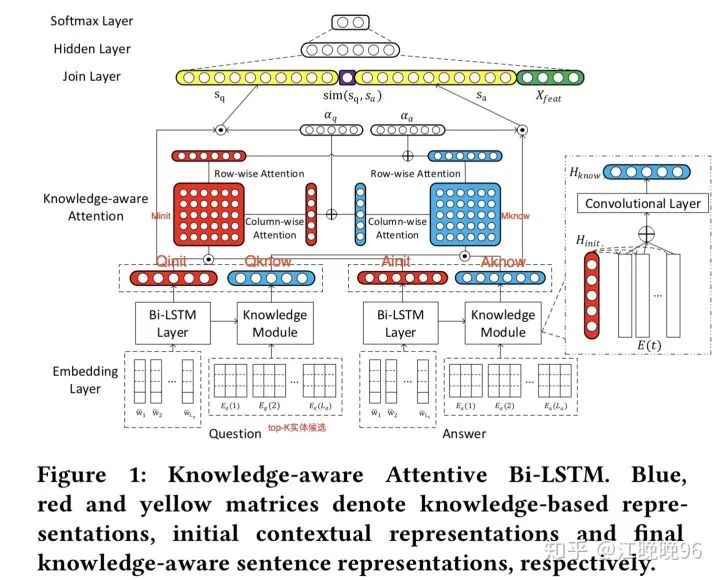
本文的主要亮点在于交互地学习knowledge-based and context-based句子表示。具体如下:
1、用knowledge embedding方法预训练来自KB的知识向量。
2、设计了一个context-guided注意力CNN,从KG中的离散候选实体中学习knowledge-based的句子表示。
3、用knowledge-aware的注意力机制学习问题和答案的knowledge-aware句子表示,这个可以根据上下文和背景知识适应性地决定问题和答案的重要信息。
MODEL
1、Basic Model
生成问题和答案的初始contextual句子表示:
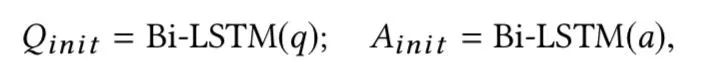
2、Knowledge Module: Knowledge-based Sentence Representation Learning
(1)通过n-gram matching进行实体论述检测,对于句子中每个实体论述都提供一个来自KG的top-K实体候选E(t) 。KG中的实体嵌入用TransE进行预训练。

(2)然后通过聚合KG中对应的候选实体,设计了一个context-guided attention机制来学习句子中每个实体论述的知识表示。
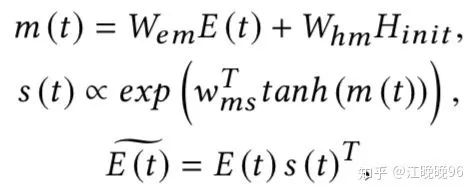
(3)为句子中每个实体论述都生成一个context-guided表示 
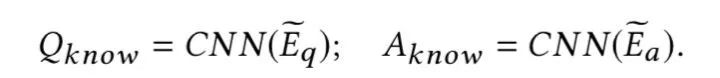
3、 Knowledge-aware Attention: Context-based Sentence Representation Learning
首先计算context-based句子表示和knowledge-based句子表示的注意力矩阵 

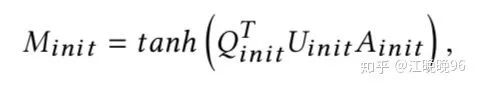
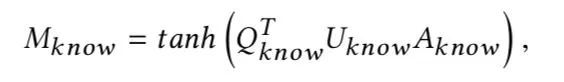
对
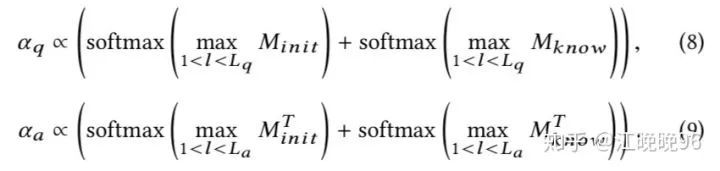
最后得到问题和答案的knowledge-aware attention句子表示:
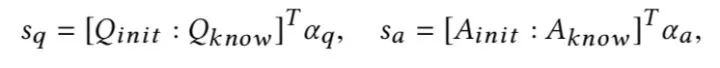
4、Hidden Layer and Softmax Layer
添加了两个额外特征:
(1)问题和答案向量的双线性相似度分数
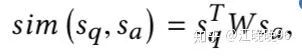
(2)wordoverlap特征 
所以隐藏层的输入为:
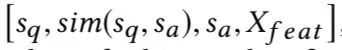
然后输出通过一个softmax层进行二元分类,损失函数为:
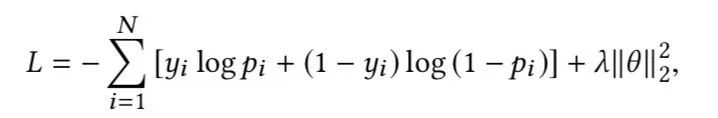
EXPERIMENTS