不懂 NumPy 算什么 Python 程序员? | CSDN 博文精选




numpy 数组一旦创建,其元素数量就不能再改变了。增删 ndarray 元素的操作,意味着创建一个新数组并删除原来的数组。python 数组的元素则可以动态增减。
numpy 数组中的元素都需要具有相同的数据类型,因此在内存中的大小相同。python 数组则无此要求。
numpy 数组的方法涵盖了大量数学运算和复杂操作,许多方法在最外层的 numpy 命名空间中都有对应的映射函数。和 python 数组相比,numpy 数组的方法功能更强大,执行效率更高,代码更简洁。
c = list()
for i in
range(
len(a)):
c.
append(a[i]*b[i])
c = a*b
矢量化代码更简洁,更易于阅读;
更少的代码行通常意味着更少的错误;
代码更接近于标准的数学符号;
矢量化代码更 pythonic。

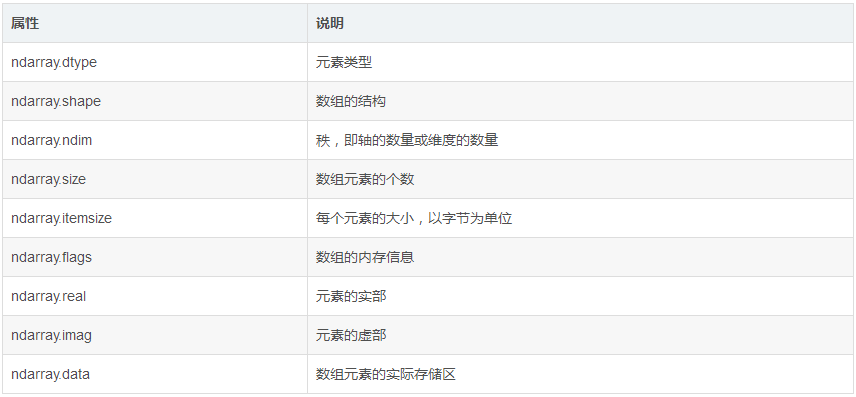
我们趟过的坑,几乎都是 dtype 挖的;
我们的迷茫,几乎都是因为 shape 和我们期望的不一样;
我们的工作,很多都是在改变 shape。

numpy.array(
object, dtype=None, copy=
True,
order=None, subok=
False, ndmin=
0)
numpy.empty(shape, dtype=float,
order=
'C')
numpy.zeros(shape, dtype=float,
order=
'C')
numpy.ones(shape, dtype=float,
order=
'C')
numpy.eye(N, M=None, k=
0, dtype=float,
order=
'C')
>>>
import
numpy
as
np
>>>>
np
.array(
[1, 2, 3])
array(
[1, 2, 3])
>>>
np
.empty((2, 3))
array(
[[2.12199579e-314, 6.36598737e-314, 1.06099790e-313],
[1.48539705e-313, 1.90979621e-313, 2.33419537e-313]])
>>>
np
.zeros(2)
array(
[0., 0.])
>>>
np
.ones(2)
array(
[1., 1.])
>>>
np
.eye(3)
array(
[[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
numpy.random.random(size=
None)
numpy.random.randint(low, high=
None, size=
None, dtype=
'l')
>>> np.
random.
random(
3)
array([
0.29334156,
0.45858765,
0.99297047])
>>> np.
random.randint(
2, size=
10)
array([
1,
0,
0,
0,
1,
1,
0,
0,
1,
0])
>>> np.
random.randint(
5, size=(
2,
4))
array(
[[4, 0, 2, 1],
[3, 2, 2, 0]])
>>> np.
random.randint(
3,
10,(
2,
4))
array(
[[4, 8, 9, 6],
[7, 7, 7, 9]])
numpy.arange(
start,
stop, step, dtype=
None)
numpy.linspace(
start,
stop,
num=
50, endpoint=
True, retstep=
False, dtype=
None)
numpy.logspace(
start,
stop,
num=
50, endpoint=
True, base=
10.0, dtype=
None)
>>> np.arange(
5)
array([
0,
1,
2,
3,
4])
>>> np.arange(
0,
5,
2)
array([
0,
2,
4])
>>> np.linspace(
0,
5,
5)
array([
0. ,
1.25,
2.5 ,
3.75,
5. ])
>>> np.linspace(
0,
5,
5, endpoint=False)
array([
0.,
1.,
2.,
3.,
4.])
>>> np.logspace(
1,
3,
3)
array([
10.,
100.,
1000.])
>>> np.logspace(
1,
3,
3, endpoint=False)
array([
10. ,
46.41588834,
215.443469 ])
numpy.asarray(a, dtype=
None, order=
None)
numpy.empty_like(a, dtype=
None, order=
'K', subok=
True)
numpy.zeros_like(a, dtype=
None, order=
'K', subok=
True)
numpy.ones_like(a, dtype=
None, order=
'K', subok=
True)[source]
>>>
np
.asarray(
[1,2,3])
array(
[1, 2, 3])
>>>
np
.empty_like(
np
.asarray(
[1,2,3]))
array(
[0, 0, 0])
>>>
np
.zeros_like(
np
.asarray(
[1,2,3]))
array(
[0, 0, 0])
>>>
np
.ones_like(
np
.asarray(
[1,2,3]))
array(
[1, 1, 1])
>>> a = np.arange(
3)
>>> a
array([
0,
1,
2])
>>> np.tile(a,
2)
array([
0,
1,
2,
0,
1,
2])
>>> np.tile(a, (
2,
3))
array([[
0,
1,
2,
0,
1,
2,
0,
1,
2],
[
0,
1,
2,
0,
1,
2,
0,
1,
2]])
>>> a = np.arange(
3)
>>> a
array([
0,
1,
2])
>>> a.repeat(
2)
array([
0,
0,
1,
1,
2,
2])
>>> lon = np.arange(
30,
120,
10)
>>> lon
array([
30,
40,
50,
60,
70,
80,
90,
100,
110])
>>> lat = np.arange(
10,
50,
10)
>>> lat
array([
10,
20,
30,
40])
>>> lons, lats = np.meshgrid(lon, lat)
>>> lons
array([[
30,
40,
50,
60,
70,
80,
90,
100,
110],
[
30,
40,
50,
60,
70,
80,
90,
100,
110],
[
30,
40,
50,
60,
70,
80,
90,
100,
110],
[
30,
40,
50,
60,
70,
80,
90,
100,
110]])
>>> lats
array([[
10,
10,
10,
10,
10,
10,
10,
10,
10],
[
20,
20,
20,
20,
20,
20,
20,
20,
20],
[
30,
30,
30,
30,
30,
30,
30,
30,
30],
[
40,
40,
40,
40,
40,
40,
40,
40,
40]])
>>> lats, lons= np.mgrid[
10:
50:
10,
30:
120:
10]
>>> lats
array(
[[10, 10, 10, 10, 10, 10, 10, 10, 10],
[20, 20, 20, 20, 20, 20, 20, 20, 20],
[30, 30, 30, 30, 30, 30, 30, 30, 30],
[40, 40, 40, 40, 40, 40, 40, 40, 40]])
>>> lons
array(
[[ 30, 40, 50, 60, 70, 80, 90, 100, 110],
[ 30, 40, 50, 60, 70, 80, 90, 100, 110],
[ 30, 40, 50, 60, 70, 80, 90, 100, 110],
[ 30, 40, 50, 60, 70, 80, 90, 100, 110]])
>>> lats, lons = np.mgrid[
10:
50:
5j,
30:
120:
10j]
>>> lats
array(
[[10., 10., 10., 10., 10., 10., 10., 10., 10., 10.],
[20., 20., 20., 20., 20., 20., 20., 20., 20., 20.],
[30., 30., 30., 30., 30., 30., 30., 30., 30., 30.],
[40., 40., 40., 40., 40., 40., 40., 40., 40., 40.],
[50., 50., 50., 50., 50., 50., 50., 50., 50., 50.]])
>>> lons
array(
[[ 30., 40., 50., 60., 70., 80., 90., 100., 110., 120.],
[ 30., 40., 50., 60., 70., 80., 90., 100., 110., 120.],
[ 30., 40., 50., 60., 70., 80., 90., 100., 110., 120.],
[ 30., 40., 50., 60., 70., 80., 90., 100., 110., 120.],
[ 30., 40., 50., 60., 70., 80., 90., 100., 110., 120.]])
>>> complex(
2,
5)
(
2+
5j)

a = np.arange(
9)
>>> a[-
1]
# 最后一个元素
8
>>> a[
2:5]
# 返回第2到第5个元素
array([
2,
3,
4])
>>> a[
:7:3]
# 返回第0到第7个元素,步长为3
array([
0,
3,
6])
>>> a[
::-1]
# 返回逆序的数组
array([
8,
7,
6,
5,
4,
3,
2,
1,
0])
>>> a = np.arange(
24).reshape(
2,
3,
4)
# 2层3行4列
>>> a
array([[[
0,
1,
2,
3],
[
4,
5,
6,
7],
[
8,
9,
10,
11]],
[[
12,
13,
14,
15],
[
16,
17,
18,
19],
[
20,
21,
22,
23]]])
>>> a[
1][
2][
3]
# 虽然可以这样
23
>>> a[
1,
2,
3]
# 但这才是规范的用法
23
>>> a[
:,
0,
0]
# 所有楼层的第1排第1列
array([
0,
12])
>>> a[
0,
:,
:]
# 1楼的所有房间,等价与a[0]或a[0,...]
array([[
0,
1,
2,
3],
[
4,
5,
6,
7],
[
8,
9,
10,
11]])
>>> a[
:,
:,
1:3]
# 所有楼层所有排的第2到4列
array([[[
1,
2],
[
5,
6],
[
9,
10]],
[[
13,
14],
[
17,
18],
[
21,
22]]])
>>> a[
1,
:,-
1]
# 2层每一排的最后一个房间
array([
15,
19,
23])
>>> a = np.array(
[[1,2,3],[4,5,6]])
>>> a.shape # 查看数组维度
(
2,
3)
>>> a.reshape(
3,
2) # 返回
3行
2列的数组
array(
[[1, 2],
[3, 4],
[5, 6]])
>>> a.ravel() # 返回一维数组
array([
1,
2,
3,
4,
5,
6])
>>> a.transpose() # 行变列(类似于矩阵转置)
array(
[[1, 4],
[2, 5],
[3, 6]])
>>> a.resize((
3,
2)) # 类似于reshape,但会改变所操作的数组
>>> a
array(
[[1, 2],
[3, 4],
[5, 6]])
numpy.rollaxis(a, axis,
start=
0)
a:数组;
axis:要改变的轴,其他轴的相对顺序保持不变;
start:要改变的轴滚动至此位置之前,默认值为0。
>>> a = np.ones((
3,
4,
5,
6))
>>> np.rollaxis(a,
3,
1).shape
(
3,
6,
4,
5)
>>> np.rollaxis(a,
2).shape
(
5,
3,
4,
6)
>>> np.rollaxis(a,
1,
4).shape
(
3,
5,
6,
4)
>>> np.append([
1,
2,
3],
[[4, 5, 6], [7, 8, 9]])
array([
1,
2,
3,
4,
5,
6,
7,
8,
9])
>>> np.append(
[[1, 2, 3]],
[[4, 5, 6]], axis=
0)
array(
[[1, 2, 3],
[4, 5, 6]])
>>> np.append(np.array(
[[1, 2, 3]]), np.array(
[[4, 5, 6]]), axis=
1)
array(
[[1, 2, 3, 4, 5, 6]])
>>> a = np.array(
[[1, 2], [3, 4]])
>>> b = np.array(
[[5, 6]])
>>> np.concatenate((a, b), axis=
0)
array(
[[1, 2],
[3, 4],
[5, 6]])
>>> np.concatenate((a, b.T), axis=
1)
array(
[[1, 2, 5],
[3, 4, 6]])
>>> np.concatenate((a, b), axis=None)
array([
1,
2,
3,
4,
5,
6])
>>> a = np.arange(
9).reshape(
3,
3)
>>> b = np.arange(
9,
18).reshape(
3,
3)
>>> a
array(
[[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> b
array(
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]])
>>> np.hstack((a,b)) # 水平合并
array(
[[ 0, 1, 2, 9, 10, 11],
[ 3, 4, 5, 12, 13, 14],
[ 6, 7, 8, 15, 16, 17]])
>>> np.vstack((a,b)) # 垂直合并
array(
[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]])
>>> np.dstack((a,b)) # 深度合并
array(
[[[ 0, 9],
[ 1, 10],
[ 2, 11]],
[[ 3, 12],
[ 4, 13],
[ 5, 14]],
[[ 6, 15],
[ 7, 16],
[ 8, 17]]])
>>> a = np.arange(
60).reshape(
3,
4,
5)
>>> b = np.arange(
60).reshape(
3,
4,
5)
>>> a.shape, b.shape
((
3,
4,
5), (
3,
4,
5))
>>> np.stack((a,b), axis=
0).shape
(
2,
3,
4,
5)
>>> np.stack((a,b), axis=
1).shape
(
3,
2,
4,
5)
>>> np.stack((a,b), axis=
2).shape
(
3,
4,
2,
5)
>>> np.stack((a,b), axis=
3).shape
(
3,
4,
5,
2)
>>> a = np.arange(
4).reshape(
2,
2)
>>> a
array(
[[0, 1],
[2, 3]])
>>> x, y = np.hsplit(a,
2) # 水平拆分,返回list
>>> x
array(
[[0],
[2]])
>>> y
array(
[[1],
[3]])
>>> x, y = np.vsplit(a,
2) # 垂直拆分,返回list
>>> x
array(
[[0, 1]])
>>> y
array(
[[2, 3]])
>>> a = np.arange(
8).reshape(
2,
2,
2)
>>> a
array(
[[[0, 1],
[2, 3]],
[[4, 5],
[6, 7]]])
>>> x,y = np.dsplit(a,
2) # 深度拆分,返回list
>>> x
array(
[[[0],
[2]],
[[4],
[6]]])
>>> y
array(
[[[1],
[3]],
[[5],
[7]]])
numpy.sort(a, axis=
-1, kind=
'quicksort', order=
None)
a:要排序的数组;
axis:沿着它排序数组的轴,如果没有,数组会被展开,沿着最后的轴排序;
kind:排序方法,默认为’quicksort’(快速排序),其他选项还有 ‘mergesort’(归并排序)和 ‘heapsort’(堆排序);
order:如果数组包含字段,则是要排序的字段。
>>> a = np.array([
3,
1,
2])
>>> np.sort(a)
array([
1,
2,
3])
>>> dt = np.dtype([(
'name',
'S10'),(
'age', int)])
>>> a = np.array([(
"raju",
21),(
"anil",
25),(
"ravi",
17), (
"amar",
27)], dtype = dt)
>>> a
array([(b
'raju',
21), (b
'anil',
25), (b
'ravi',
17), (b
'amar',
27)],
dtype=[(
'name',
'S10'), (
'age',
'<i4')])
>>> np.sort(a, order=
'name')
array([(b
'amar',
27), (b
'anil',
25), (b
'raju',
21), (b
'ravi',
17)],
dtype=[(
'name',
'S10'), (
'age',
'<i4')])
numpy.argsort(a, axis=
-1, kind=
'quicksort', order=
None)
a:要排序的数组;
axis:沿着它排序数组的轴,如果没有,数组会被展开,沿着最后的轴排序;
kind:排序方法,默认为’quicksort’(快速排序),其他选项还有 ‘mergesort’(归并排序)和 ‘heapsort’(堆排序);
order:如果数组包含字段,则是要排序的字段。
>>> a = np.array([
3,
1,
2])
>>> np.argsort(a)
array([
1,
2,
0], dtype=int64)
numpy.argmax(a, axis=
None, out=
None)
numpy.argmin(a, axis=
None, out=
None)
numpy
.nonzero(
a)
numpy
.where(
condition
[, x, y])
>>> a = np.arange(
10)
>>> a
array([
0,
1,
2,
3,
4,
5,
6,
7,
8,
9])
>>> np.where(a <
5)
(array([
0,
1,
2,
3,
4], dtype=int64),)
>>> a = a.reshape((
2, -
1))
>>> a
array([[
0,
1,
2,
3,
4],
[
5,
6,
7,
8,
9]])
>>> np.where(a <
5)
(array([
0,
0,
0,
0,
0], dtype=int64), array([
0,
1,
2,
3,
4], dtype=int64))
>>> np.where(a <
5, a,
10*a)
array([[
0,
1,
2,
3,
4],
[
50,
60,
70,
80,
90]])
numpy
.extract(
condition,
arr)
>>> a = np.arange(
12).reshape((
3,
4))
>>> a
array([[
0,
1,
2,
3],
[
4,
5,
6,
7],
[
8,
9,
10,
11]])
>>> condition = np.mod(a,
3)==
0
>>> condition
array([[
True,
False,
False,
True],
[
False,
False,
True,
False],
[
False,
True,
False,
False]])
>>> np.extract(condition, a)
array([
0,
3,
6,
9])
numpy.insert(arr, obj,
values, axis=None)
>>> a = np.array(
[[1, 1], [2, 2], [3, 3]])
>>> a
array(
[[1, 1],
[2, 2],
[3, 3]])
>>> np.
insert(a,
1,
5)
array([
1,
5,
1,
2,
2,
3,
3])
>>> np.
insert(a,
1,
5, axis=
0)
array(
[[1, 1],
[5, 5],
[2, 2],
[3, 3]])
>>> np.
insert(a,
1, [
5,
7], axis=
0)
array(
[[1, 1],
[5, 7],
[2, 2],
[3, 3]])
>>> np.
insert(a,
1,
5, axis=
1)
array(
[[1, 5, 1],
[2, 5, 2],
[3, 5, 3]])
numpy.
delete(arr, obj, axis=None)
>>> a = np.array(
[[1, 2], [3, 4], [5, 6]])
>>> a
array(
[[1, 2],
[3, 4],
[5, 6]])
>>> np.delete(a,
1)
array([
1,
3,
4,
5,
6])
>>> np.delete(a,
1, axis=
0)
array(
[[1, 2],
[5, 6]])
>>> np.delete(a,
1, axis=
1)
array(
[[1],
[3],
[5]])
numpy.unique(ar, return_index=
False, return_inverse=
False, return_counts=
False, axis=
None)
arr:输入数组,如果不是一维数组则会展开;
return_index:如果为true,返回新列表元素在旧列表中的位置(下标),并以列表形式储;
return_inverse:如果为true,返回旧列表元素在新列表中的位置(下标),并以列表形式储;
return_counts:如果为true,返回去重数组中的元素在原数组中的出现次数。
>>> a = np.array([[
1,
0,
0], [
1,
0,
0], [
2,
3,
4]])
>>> np.unique(a)
array([
0,
1,
2,
3,
4])
>>> np.unique(a, axis=
0)
array([[
1,
0,
0],
[
2,
3,
4]])
>>> u, indices = np.unique(a, return_index=True)
>>> u
array([
0,
1,
2,
3,
4])
>>> indices
array([
1,
0,
6,
7,
8], dtype=int64)
>>> u, indices = np.unique(a, return_inverse=True)
>>> u
array([
0,
1,
2,
3,
4])
>>> indices
array([
1,
0,
0,
1,
0,
0,
2,
3,
4], dtype=int64)
>>> u, num = np.unique(a, return_counts=True)
>>> u
array([
0,
1,
2,
3,
4])
>>> num
array([
4,
2,
1,
1,
1], dtype=int64)
numpy.save(file, arr, allow_pickle=
True, fix_imports=
True)
file:要保存的文件,扩展名为 .npy,如果文件路径末尾没有扩展名 .npy,该扩展名会被自动加上;
arr:要保存的数组;
allow_pickle:可选,布尔值,允许使用 python pickles 保存对象数组,python 中的 pickle 用于在保存到磁盘文件或从磁盘文件读取之前,对对象进行序列化和反序列化;
fix_imports:可选,为了方便 pyhton2 读取 python3 保存的数据。
numpy
.savez(
file, *
args, **
kwds)
file:要保存的文件,扩展名为 .npz,如果文件路径末尾没有扩展名 .npz,该扩展名会被自动加上;
args:要保存的数组,可以使用关键字参数为数组起一个名字,非关键字参数传递的数组会自动起名为 arr_0, arr_1…
kwds:要保存的数组使用关键字名称。
numpy.load(file, mmap_mode=
None, allow_pickle=
True, fix_imports=
True, encoding=
'ASCII')
file:类文件对象(支持 seek() 和 read()方法)或者要读取的文件路径;
arr:打开方式,None | ‘r+’ | ‘r’ | ‘w+’ | ‘c’;
allow_pickle:可选,布尔值,允许使用 python pickles 保存对象数组,python 中的 pickle 用于在保存到磁盘文件或从磁盘文件读取之前,对对象进行序列化和反序列化;
fix_imports:可选,为了方便 pyhton2 读取 python3 保存的数据;
encoding:编码格式,‘latin1’ | ‘ASCII’ | ‘bytes’。
a = np.array([[1,2,3],[4,5,6]])
b = np.arange(0, 1.0, 0.1)
c = np.sin(b)
# c 使用了关键字参数 sin_array
np.savez(
"runoob.npz", a, b, sin_array = c)
r = np.load(
"runoob.npz")
print(r.files)
# 查看各个数组名称
print(r[
"arr_0"])
# 数组 a
print(r[
"arr_1"])
# 数组 b
print(r[
"sin_array"])
# 数组 c
a = np.array([1,2,3,4,5])
np.savetxt('out.txt',a)
b = np.loadtxt('out.txt')
print(b)

numpy.around(a, decimals=
0,
out=None)
>>> np.around([-
0.
42, -
1.68,
0.
37,
1.64])
array([-
0., -
2.,
0.,
2.])
>>> np.around([-
0.
42, -
1.68,
0.
37,
1.64], decimals=
1)
array([-
0.
4, -
1.7,
0.
4,
1.6])
>>> np.around([.
5,
1.5,
2.5,
3.5,
4.5])
# rounds to nearest even value
array([
0.,
2.,
2.,
4.,
4.])
numpy.
floor(a)
numpy.
ceil(a)
>>>
np
.floor(
[-0.42, -1.68, 0.37, 1.64])
array(
[-1., -2., 0., 1.])
>>>
np
.ceil(
[-0.42, -1.68, 0.37, 1.64])
array(
[-0., -1., 1., 2.])
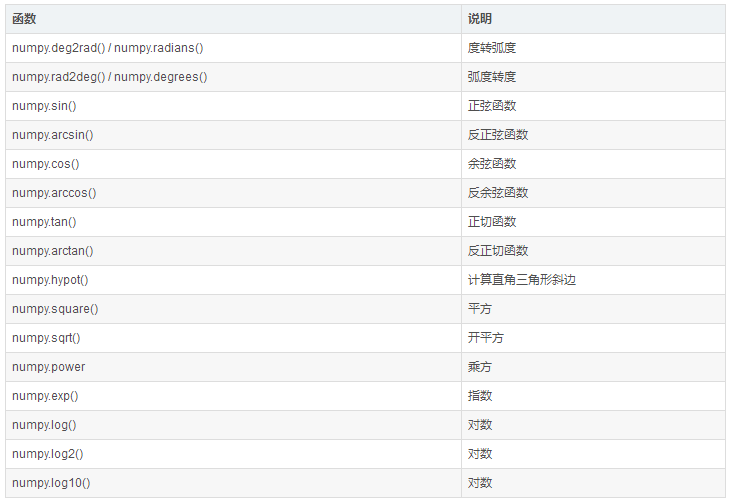
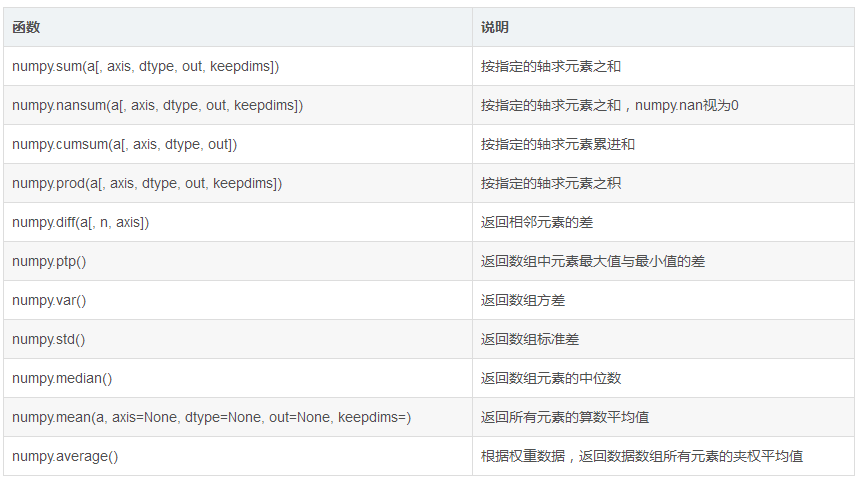

import
math
vertices =
[[3,4,5], [7,8,9], [4,9,3]]
p = [
2,
7,
4]
d = list()
for v
in vertices:
d.append(
math.
sqrt(
math.
pow(v[
0]-p[
0],
2)+
math.
pow(v[
1]-p[
1],
2)+
math.
pow(v[
2]-p[
2],
2)))
print(vertices[d.index(
min(d))],
min(d))
import numpy as np
vertices = np.array(
[[3,4,5], [7,8,9], [4,9,3]])
p = np.array([
2,
7,
4])
d = np.
sqrt(np.sum(np.square((vertices-p)), axis=
1))
print(vertices[d.argmin()], d.
min())







