赛尔原创 | 基于转移的语义依存图分析
论文作者:王宇轩,车万翔,郭江,刘挺
引言
本文介绍的工作来源于我实验室录用于AAAI2018的论文《A Neural Transition-Based Approach for Semantic Dependency Graph Parsing》。
语义依存图是近年来提出的对树结构句法或语义表示的扩展,它与树结构的主要区别是允许一些词拥有多个父节点,从而使其成为有向无环图(direct edacyclic graph,DAG)。(我实验室在SemEval-2012上组织了世界上最早的语义依存(树)分析技术评测,并随后将其扩展到语义依存图,在SemEval-2016上组织了相关评测。图1和图2分别给出同一句话的句法依存树和语义依存图的例子,更多有关中文语义依存图的信息可以参考http://mp.weixin.qq.com/s/bvm6sISUsUEhOpTOV-NxSg)因此要获得句子的语义依存图,就需要对这种DAG进行分析。然而目前大多数工作集中于研究依存树结构,少有人研究如何对DAG进行分析。本文提出一种基于转移的分析器,使用list-based arc-eager算法的变体对依存图进行分析,并提出了两种有效的神经网络模块,分别用于获得转移系统中缓存和子图更好的表示。该系统在中英数据集上都取得了很好的结果,并且还能通过简单的模型融合方法进一步提高性能。
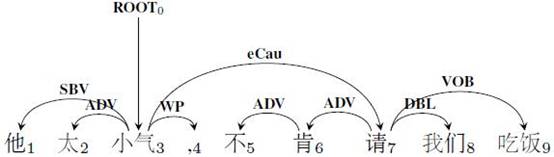
图1 句法依存树
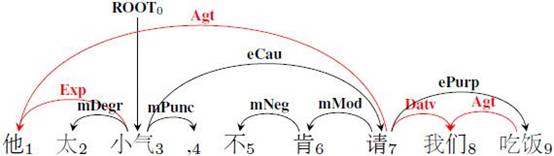
图2 语义依存图
1. 基于转移的依存图分析框架
目前依存树分析领域两大主流方法分别是基于转移(Transition-based)和基于图(Graph-based)的依存分析。基于图的算法将依存分析建模为在有向完全图中求解最大生成树的问题。基于转移的依存分析算法将句子的解码过程建模为一个有限自动机问题(类比编译器中的句法分析组件)。
本文中,我们选择了基于转移的依存分析方法。这种方法从起始转移状态开始,不断地执行转移动作从一个状态进入另一个状态,最终达到终结状态,并将终结状态对应的树(或图)作为分析结果。转移状态包括一个保存正在处理中的词的栈(Stack),一个保存待处理词的缓存(Buffer),和一个记录已经生成的依存弧的存储器。转移动作通常包括如移进、规约并生成依存弧等。数据驱动的基于转移依存句法分析的目标是训练一个分类器。这个分类器对给定转移状态预测下一步要执行的转移动作。
如图2所示,依存图与依存树有两种主要区别。第一,依存图中存在交叉弧。传统转移算法需要通过添加缓存机制来解决交叉弧的问题。Choi等人2013年提出的List-based Arc-eager算法[1]就是这样一思路的代表。List-based Arc-eager算法在前文介绍的转移系统基础上,增加了一个双向队列(Deque)用于保存暂时跳过的词,来生成交叉弧。第二,依存图中的词可能存在多个父节点。导致传统转移算法无法产生依存图的主要原因是:这些算法为了保证了最终生成的是一棵依存树,往往规定一旦找到了一个词的父节点,这个词就应立即被规约。为了使我们的转移算法能够产生依存图结构,我们在Choi等人的基础上修改了转移动作的执行条件,使得找到父节点的词缓存在双向队列中而不被规约,这为接下来的转移动作找到该词的其它父节点提供了可能,从而生成语义依存图。图3给出用修改后的算法生成语义依存图的具体流程。
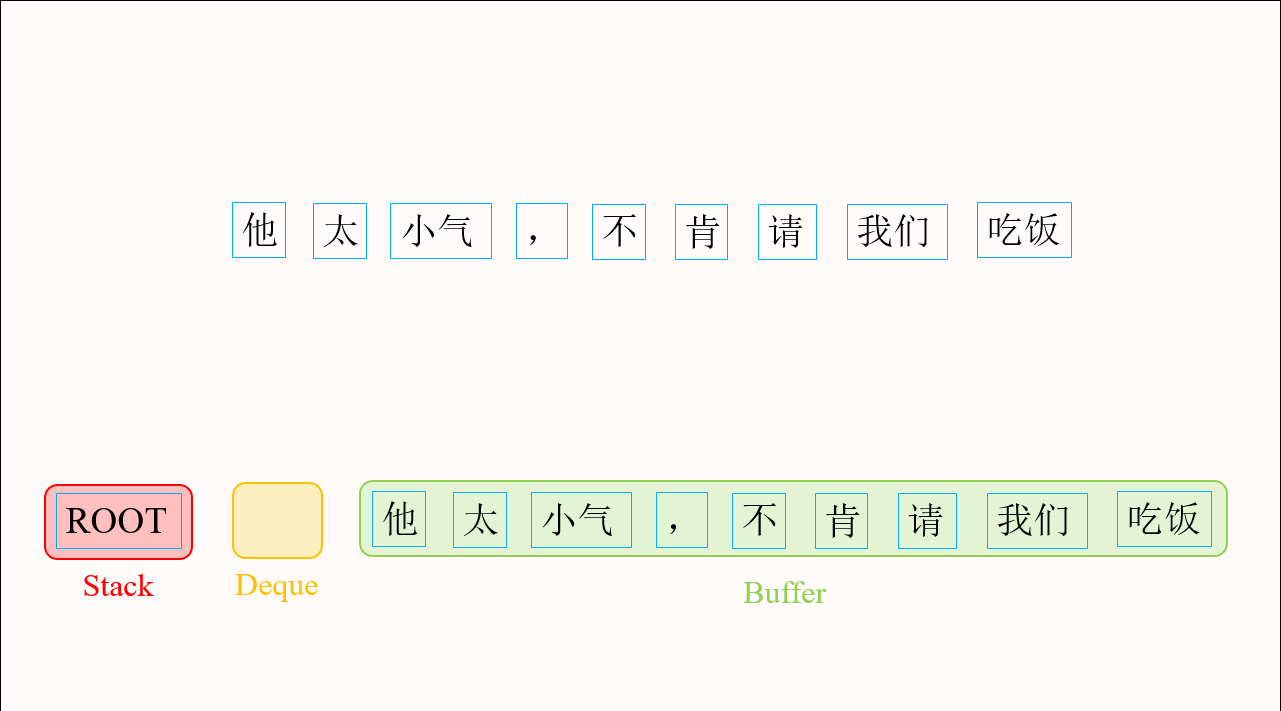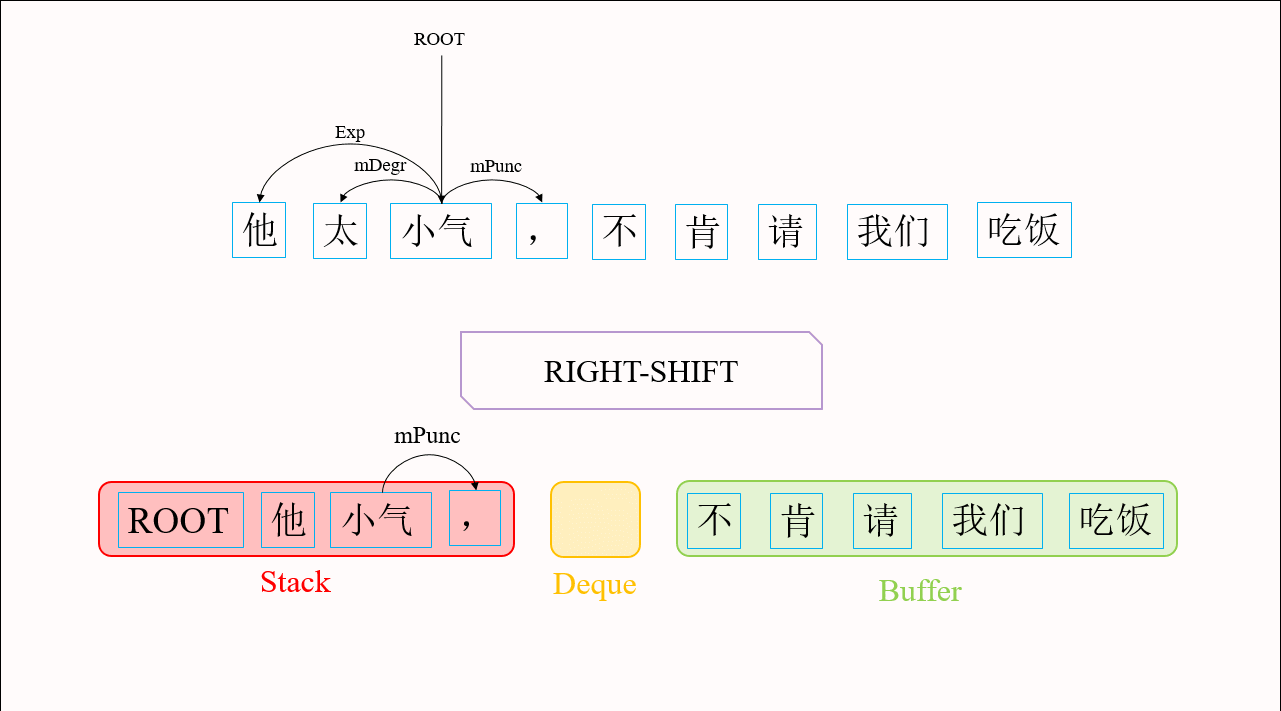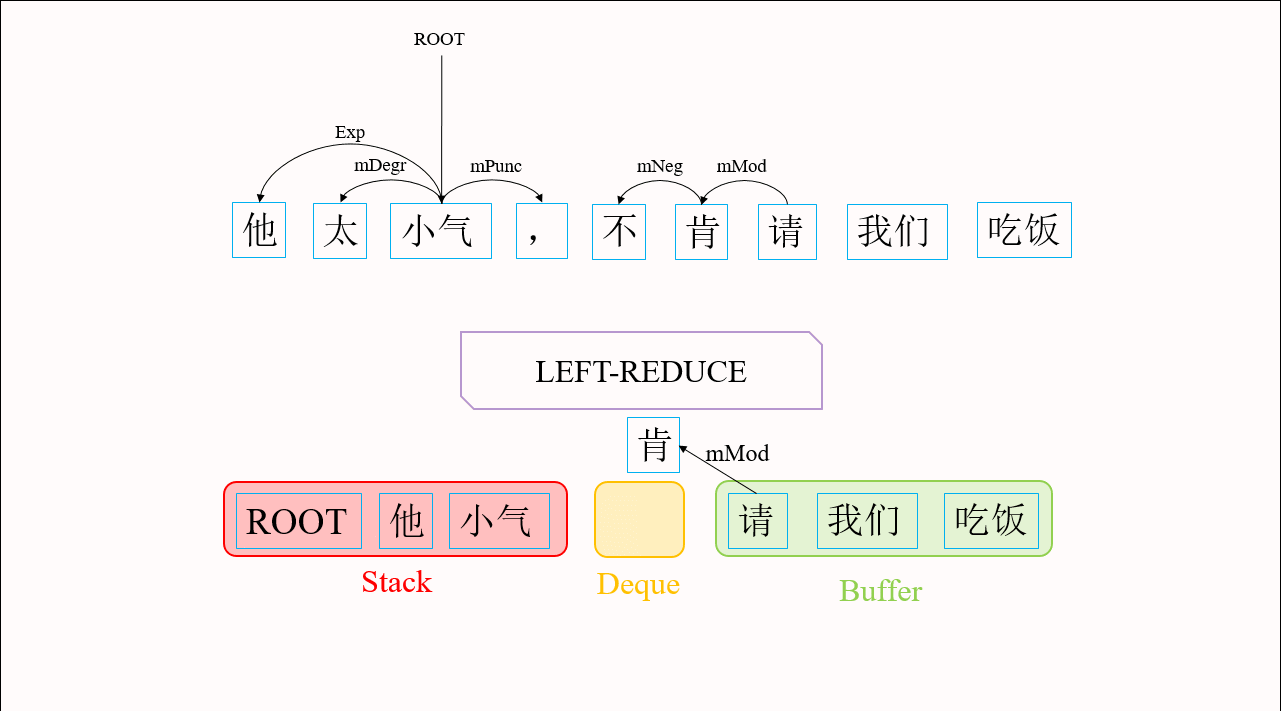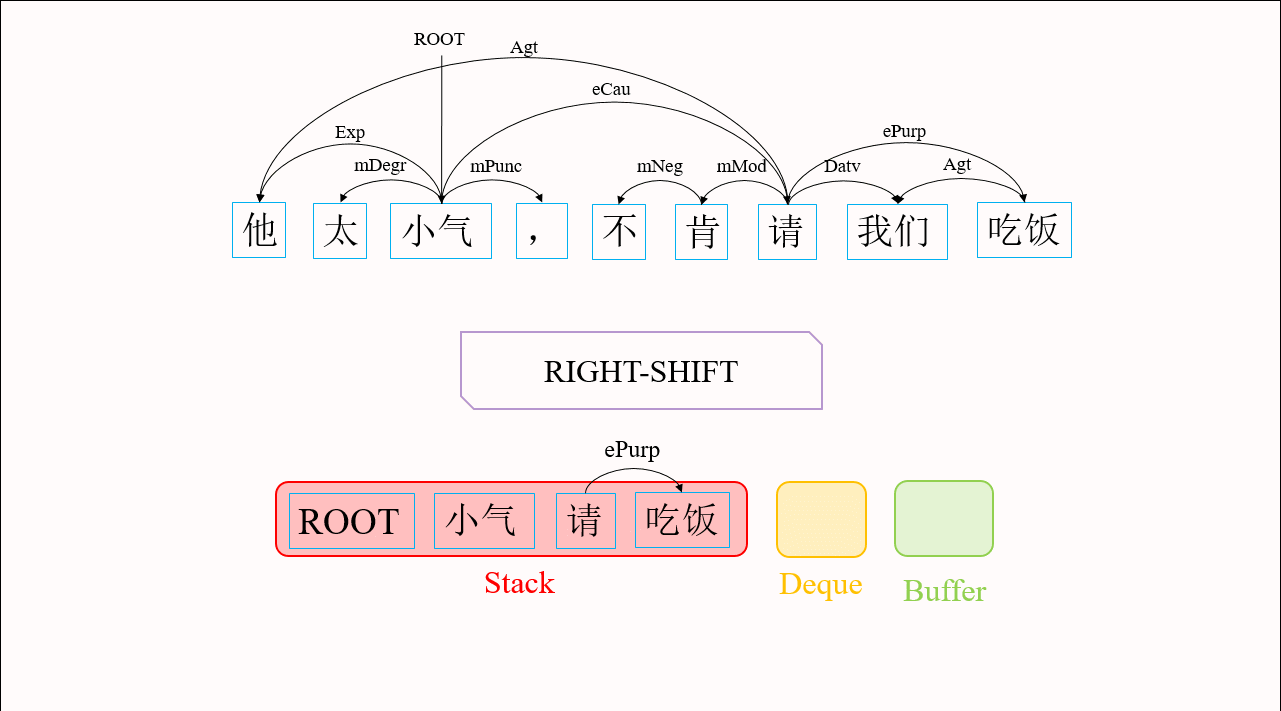
图3 修改后的List-based Arc-eager算法生成语义依存图的流程
2. 基于Stack LSTM的分类器
解决了转移系统的问题,接下来就需要选择一个合适的分类器在每个转移状态下预测出下一步要执行的转移动作。我们选择了Dyer等人在2015年提出的Stack-LSTM[2]作为基础网络结构来学习转移系统中的栈、双向队列、缓存和历史转移动作序列中的信息。(关于Stack LSTM的具体介绍可以参考http://mp.weixin.qq.com/s/QvHTUAicgf257wQwkRn3cQ)
为了更好地获得转移状态的表示,我们在上述结构的基础上提出了2个有效的神经网络模块——Bi-LSTM Subtraction和Incremental Tree-LSTM,分别对转移过程中的缓存和子图进行建模。图4给出了该模型的整体结构图。
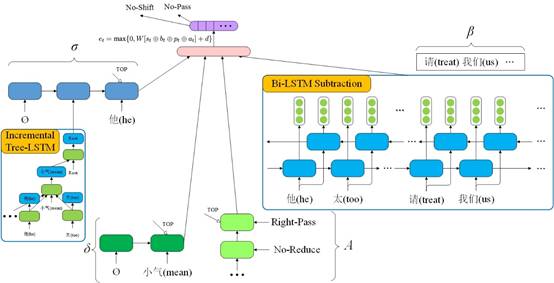
图4 依存图分析器模型整体结构图
2.1 Bi-LSTM Subtraction
Dyer等人的模型中简单地使用从右向左的单向LSTM的最后一个隐层状态向量表示缓存中的所有信息。这种方法不但无法获取缓存之外的词(已被移入栈中或规约)的信息,也损失了从左向右的上下文信息。而且,我们认为只用一个隐层状态向量是无法很好地表示整个缓存中的信息的。因此,我们将缓存看作一个段,并用段头和段尾的表示的差来表示整个段。此外,为了获得缓存之外词的信息,我们首先将整个句子输入双向LSTM中,用每个词对应的隐层状态向量作为其表示[3]。
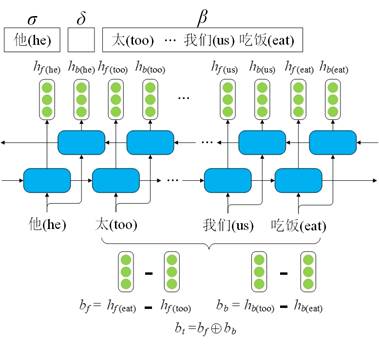
图5 Bi-LSTM Subtraction结构图
例如图5中计算缓存的表示时,先用“吃饭”的正向LSTM表示减去“太”的正向LSTM表示,获得该段正向的表示,再用“太”的反向LSTM表示减去“吃饭”的反向LSTM表示,获得该段反向的表示。二者拼接起来作为此时缓存的表示。
2.2 Incremental Tree-LSTM
Dyer等人的模型中使用基于依存的递归神经网络(RecNN)来计算转移过程中的子结构,在处理较深的子结构时,这种方法可能会遇到梯度消失问题。为了解决该问题,我们利用Tree-LSTM[4]对这些子结构进行建模。图6显示了我们提出的Incremental Tree-LSTM与基于依存的RecNN的区别。RecNN通过递归地组合一个个父节点-子节点对来构建子图,而Tree-LSTM则能同时合并一个节点及其所有子节点。
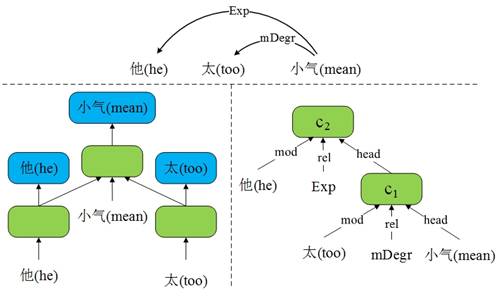
图6 Incremental Tree-LSTM与基于依存的递归神经网络对比
由于基于转移的依存图分析的特点,我们使用的Tree-LSTM与一般的Tree-LSTM有两点不同。首先,显然该任务中需要建模的子结构不一定是树。但好在我们处理的依存图不包括环,因此仍然能够使用LSTM。更重要的是,与一般的Tree-LSTM能够同时获得一个节点的所有子节点不同,在基于转移的依存分析中,一个节点的子节点是逐个被找到的,因此我们需要不断利用Tree-LSTM更新父节点信息。具体来说,对于一个词,每当找到它的一个新子节点,就要将其所有已经找到的子节点和其本身的表示输入Tree-LSTM中计算它的新表示。例如图7中的子图构建流程如下:(1)用Tree-LSTM合并A和B的表示并将结果作为A的新表示;(2)合并B和C的表示并将结果作为B的新表示;(3)合并A、D的表示和B当前的表示(b+c)并将结果作为A的新表示。
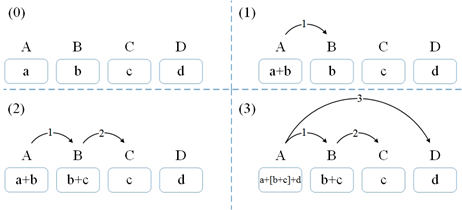
图7 Incremental Tree-LSTM中子图的递增式构建
2.3 模型融合
我们的系统能通过一个简单的模型融合方法进一步提高性能。具体来说,就是在训练时使用不同随机初始化种子训练多个模型。在预测时,用这些模型算出的分数之和来选择接下来的转移动作。
3. 实验结果
我们的系统在中英文数据集上都获得了很好的实验结果,表1是SemEval-2016 Task 9中文数据集上的实验结果。该数据集分为两部分,分别是新闻集(NEWS)和小学课本集(TEXTBOOKS),前者句子较长、较复杂,后者句子较短、较简单。该评测的评价指标中最重要的两个分别是弧标签的F值(LF)和有多父节点的词的弧标签的F值(NLF)。
表1 SemEval-2016 Task 9中文数据集上的实验结果
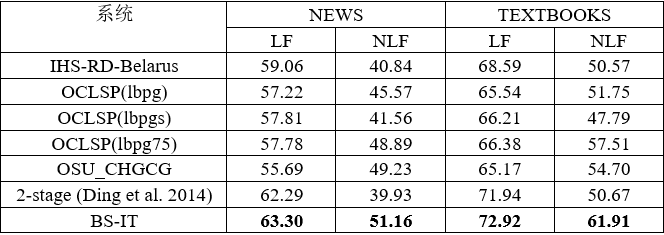
表中前5个是其他参赛系统,2-stage (Ding et al. 2014)是我们重新实现的Ding等人在2014年提出的一个两步方法[5],先用传统依存树分析器生成树结构,再用SVM分类器从规则产生的候选弧集合中选出一些弧加入其中从而得到依存图结构。BS-IT是我们的系统。实验结果表明我们的系统在两个数据集的各项评测指标中都明显超过其他系统。
表2 各模块效果实验结果
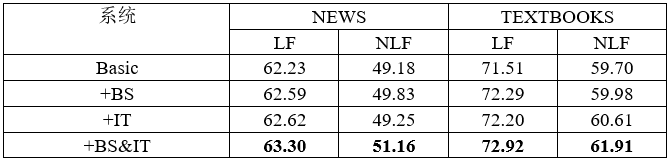
表2中列出了测试BS和IT模块效果的实验,结果表明二者都能为基础系统带来性能提升。而二者同时使用时对系统性能提升更明显。
4. 结语
本文提出了一个基于转移的语义依存图分析方法,利用List-based Arc-eager算法的变体实现了有向无环图的生成。此外,本文还提出了两种有效的神经网络模块用于学习转移系统中重要部分的表示。在中英数据集上的实验结果证明了该方法的有效性。
5. 参考文献
[1] Choi J D, McCallum A. Transition-based Dependency Parsingwith Selectional Branching[C]. Proceedings of the 51thAnnual Meeting of the Association for Computational Linguistics. 2013: 1052-1062.
[2] Dyer C, Ballesteros M, Ling W, et al. Transition-based Dependency Parsingwith Stack Long Short-Term Memory[C]. Proceedingsof Annual Meeting on Association forComputational Linguistics. 2015: 334–343.
[3] Kiperwasser E, Goldberg Y. Simple and Accurate DependencyParsing Using Bidirectional LSTM Feature Representations [J]. Transactions ofthe Association for Computational Linguistics. 2016: 313-327.
[4] Tai K S,Socher R, Manning C D. Improved Semantic Representations from Tree-StructuredLong Short-Term Memory Networks[C]. Proceedings of the 53rd Annual Meeting ofthe Association for Computational Linguistics and the 7th International JointConference on Natural Language Processing. 2015: 1556-1566.
[5] Ding Y,Shao Y, Che W, et al. Dependency graph based Chinese semantic parsing [M]. ChineseComputational Linguistics and Natural Language Processing Based on NaturallyAnnotated Big Data. Springer, Cham, 2014: 58-69.
本期责任编辑: 刘一佳
本期编辑: 赵怀鹏
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。



