【智能服务】阿里小蜜:智能服务技术实践及场景探索

分享嘉宾:张佶 阿里巴巴 高级算法专家
编辑整理:赵静宇
内容来源:2018年AI先行者大会
出品社区:DataFun
注:欢迎转载,转载请注明出处。
在2017年双十一期间,阿里小蜜所提供的智能服务机器人已经成为双十一服务主力。其中阿里小蜜的智能服务占比达到了95%,智能解决率为93.1%,为商家提供服务的店小蜜在1天内提供了1亿轮次的对话服务。在本次分享中我们将介绍阿里小蜜整体的产品业务、相关场景中的自然语言处理技术的运用以及阿里小蜜如何从智能客服逐渐升级为具备“泛服务”能力的咨询顾问。
阿里小蜜平台介绍
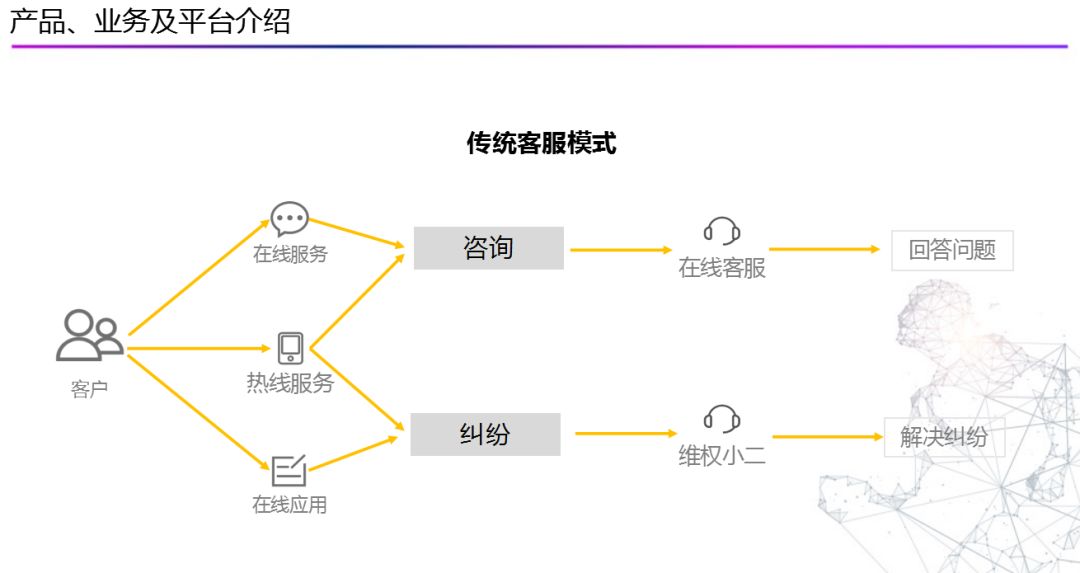
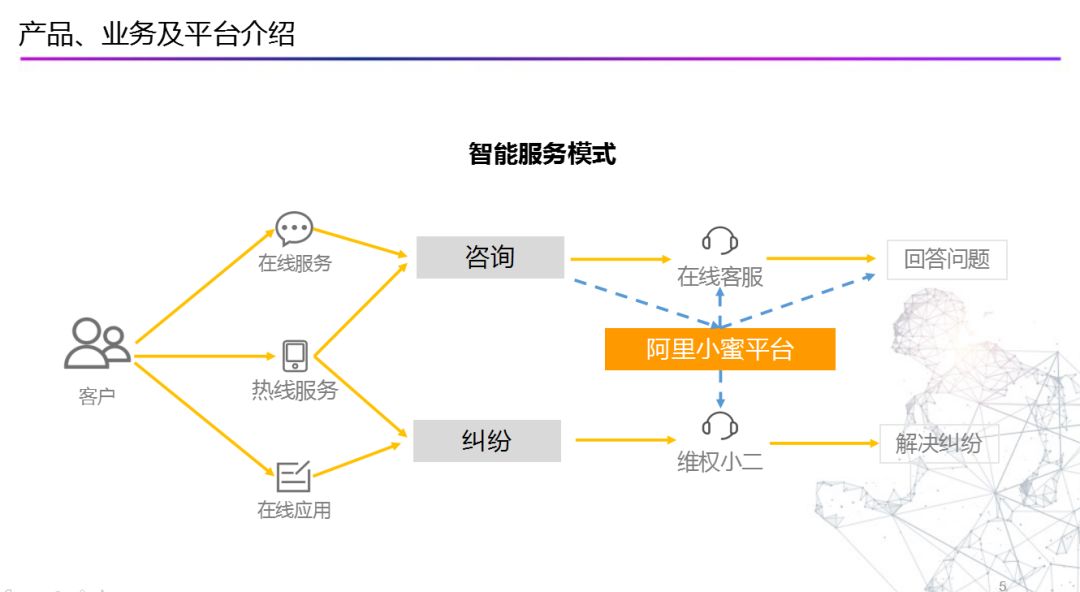
在人机交互行业生态领域发展的大背景下,面向智能服务领域,阿里小蜜在这两年时间同样在不断的升级与变迁,下面我们来对比传统客服与智能服务模式的区别:
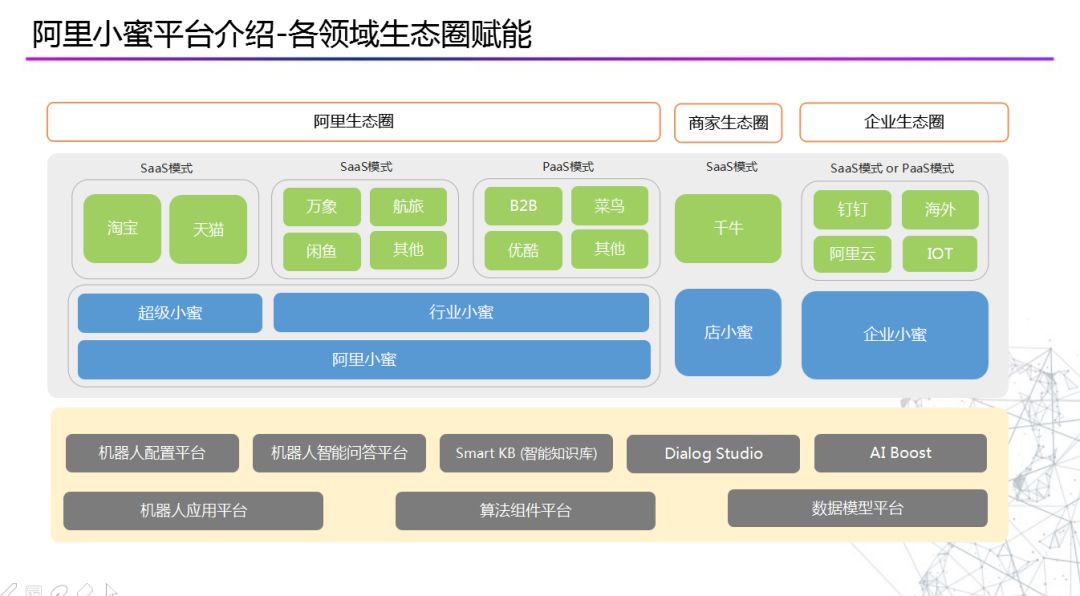
阿里小蜜赋能各领域生态圈:
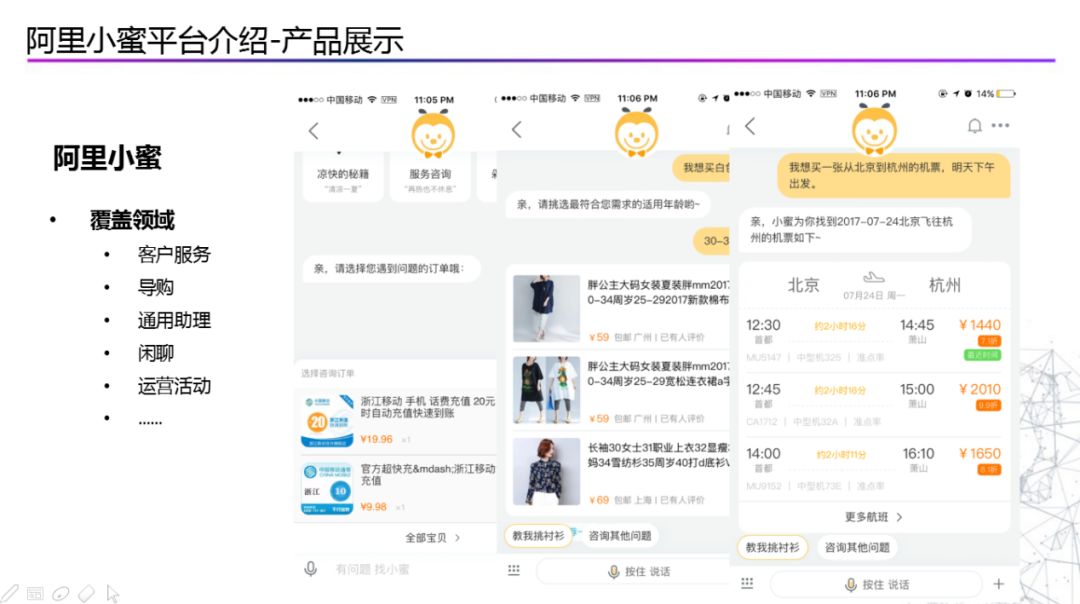
如图所示是阿里小蜜的产品功能,很多咨询业务都会通过小蜜来回答,作为一个人工智能助理,除了可以解决用户的业务咨询类问题,缓解人工压力之外,也兼备了其他助理业务,包括:查天气、买机票、充话费等。同时,还可以通过多轮会话完成一个导购助理的工作,通过主动推荐引导的方式推荐商品标签,搜集用户意图,最终为用户推荐出满足他们需求的商品,其功能覆盖如下:
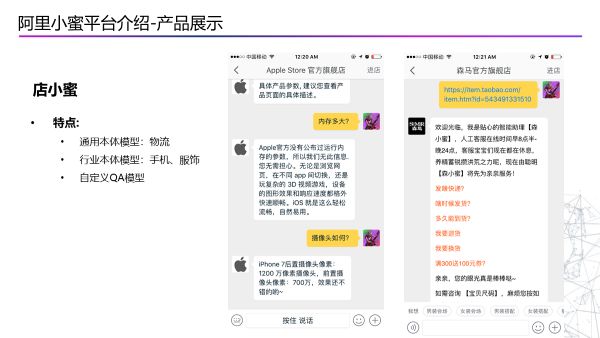
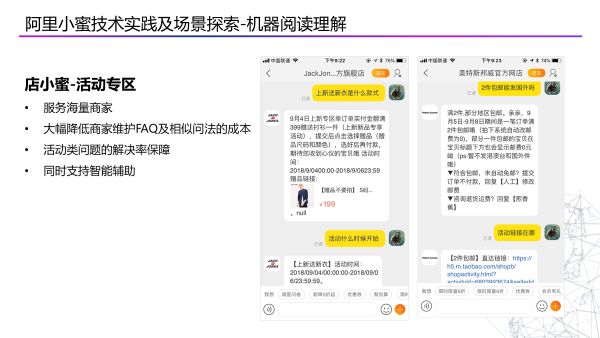
第二个是店小蜜的产品功能,店小蜜已经为海量的商家提供了智能服务能力,帮助商家更好的服务他们的用户。在店小蜜中,首先要解决的是每个商家都有的通用问题,如物流。其次,每个行业商品都有不同的特点,比如手机行业可能会有一些手机硬件和参数的问题,服饰行业可能会有他自己特有的问题。所以对不同的行业会制定一些相应的本体模型,然后针对自定义的QA模型做一些配置和输入。
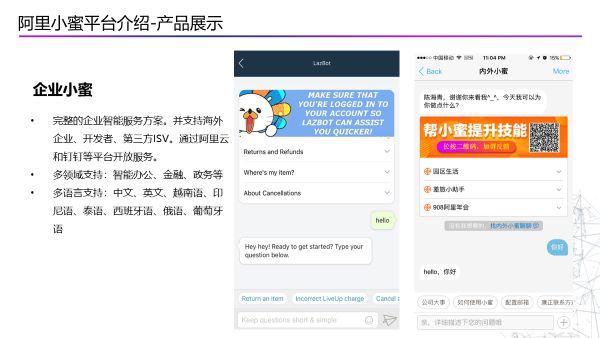
第三个是是通过企业小蜜支持整个企业的生态圈,现在国内和海外的企业,以及第三方ISV和开发者可以通过阿里云和钉钉等平台开放服务。所以在企业方面,我们不仅有电商小蜜,在政务、金融、办公等领域也有小蜜的支持,目前我们有了中文、英文、越南语、印尼语、泰语、西班牙语、俄语、葡萄牙语等多种语言的支持。第一个例子是东南亚最大的电商平台Lazada,第二个例子是为阿里巴巴内部为企业员工服务的内外小蜜,目前也有大量的钉钉企业用户采用了这种服务模式。
阿里小蜜技术实践与场景探索
技术方面从以下四个方面来介绍小蜜:
意图识别
机器阅读理解
多轮增强式导购
迁移学习
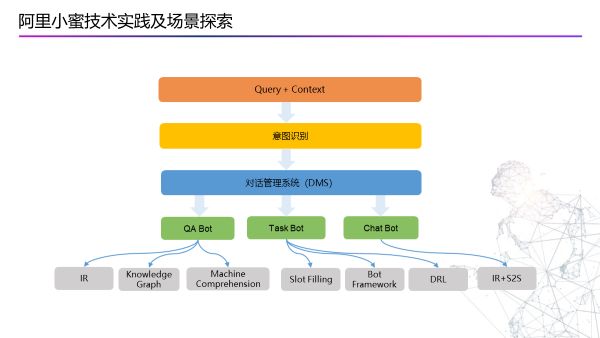
先看下小蜜整体的对话流程,当用户输入一个问题的时候,我们不仅会对这个query解析,也会结合上下文对用户query进行理解。意图识别就是为了挖掘用户真正的想要做的操作。然后在对话管理系统中进行多轮式控制,在理解用户后,会选择三大类(QA Bot,Chat Bot,Task Bot)中的一类来回答用户的问题。这三大类有不同的技术去支撑:
第一类是QA Bot:他使用IR建立自己的知识图谱,还有Machine Comprehension 从一篇文章中读取理解它等技术。
第二类是Task Bot:主要是做任务型工作,比如订一张机票。这些使用Slot Filling,Bot Framework和深度强化学习等技术来支持。
第三类是Chat Bot:纯粹的闲聊,比如“用户问你今年多大了?”等问题。使用IR+S2S(检索式和生成式的方法)技术支持。
意图识别
意图识别是机器人识别的第一个环节,阿里小蜜有三大场景。
意图场景识别:比如第一个用户说充值,其实是要给手机充话费。
多轮意图继承:比如用户第一句说上海天气怎么样,第二句说杭州呢?那第二句就是继承了第一句天气的意思。
动态障碍预测:当用户还没有输入问题的时候,阿里小蜜需要根据用户之前的询问历史来猜测推断出用户想要咨询的问题。
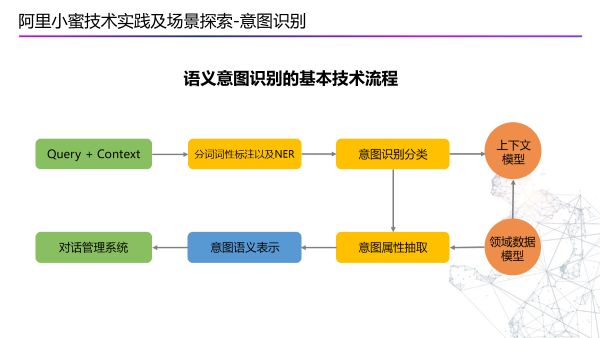
整体的技术流程
对用户的query首先进行NLP处理,分词词性标注以及NER处理。
然后输入到意图分类的模型,也需要根据上下文抽取一些意图的属性,结合领域的模型判断出属于哪一个领域的问题。
最后通过意图语义表示传回对话管理系统中。
分类
传统机器学习:
多分类模型(有监督的分类算法,依据具体场景进行选型 Bayes\SVM\最大熵\…):适用于相对简单场景且分类数稳定领域;
二分类模型(按照意图领域做成多个二分类模型):适用于领域分类相对独立,并且经常需要新增修改的场景,能做到相互独立。
深度学习:
深度学习多分类模型(CNN\DNN\LSTM\…):适用于较大数据量积累场景;
结合用户行为特征的深度学习意图预测模型:由于文本缺失、不明确或者不完整的情况下,增加用户行为特征进行意图分类预测。
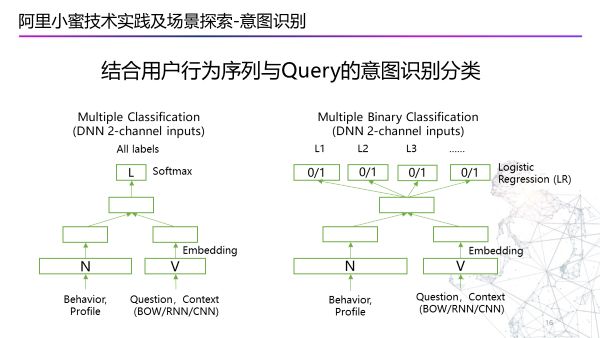
深度学习分类模型结构
神经网络中会有两大输入,左边N会输入结构化数据,比如个人属性以及浏览操作历史纪录,右边V会输入一些非结构化数据,比如前几轮问的问题和序列,对于这些非结构化的数据我们会有句子编码器解析这些数据,当需要考虑到句子的语序关系的时候会使用CNN或者RNN网络结构;上层的话,会结合用户的Embedding和句子的Embedding去输出。但是工业真正的场景中,用户问题的问题个数是不固定的,所以会把最后一层Softmax 更改为多个二分类模型。
机器阅读理解
机器阅读理解是目前一种新的QA方式,我们发现问答的答案线索往往已经存在于一些文章当中,如果能从现有的文章中简洁有效的抽取出有用的问题并且回答用户的问题,那效率会大大提高,省去了过去知识运营人员大量配置FAQ的工作。下面文章是阿里巴巴wiki的描述,这里面会有很多数字,地点,名称。如果传统的知识抽取FAQ的方法,这一小段能抽取二三十个问题,代价很大,而机器阅读目前能直接阅读回答这类问题。

机器阅读理解领域已经成为NLP研究的热点领域:
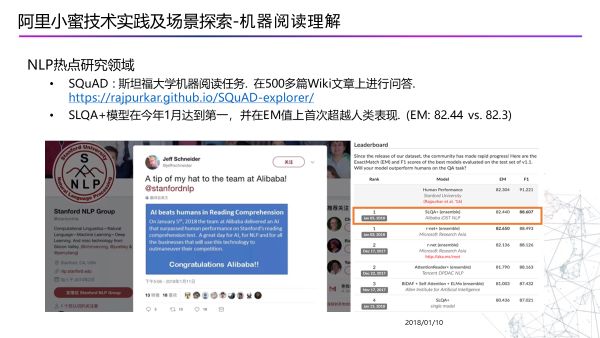
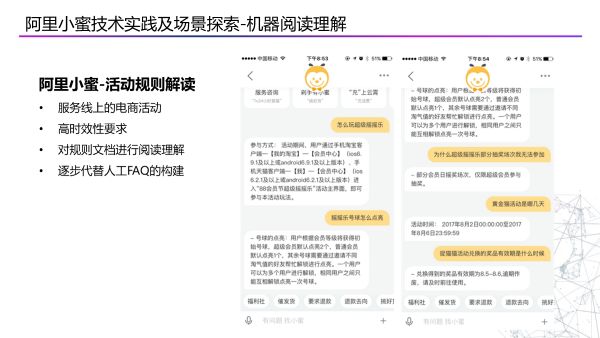
除了在学术领域取得一些成果之外,对于阿里小蜜来说更重要的是怎样通过机器阅读来真正解决真实场景中的问题。例如,在双十一等大促期间我们往往有大量的电商活动上线,而这些活动已经有一些规则文档,我们可以对这些文档进行阅读并回答用户关于双十一的活动问题,大大提升活动问答的上线效率。
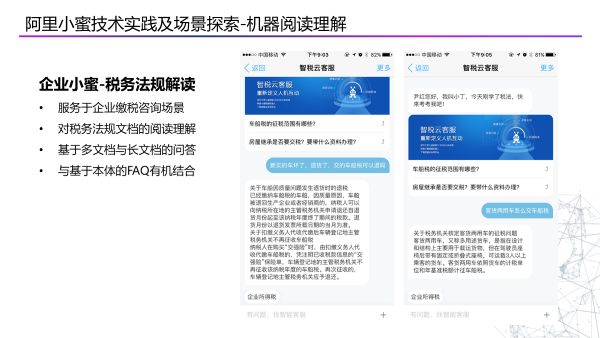
第二个场景是企业小蜜在支持外部的客户税务法规的解读。过去需要税务专业毕业的专业人员才能回答,现在我们可以通过机器阅读税务法规文档来回答问题。
第三个场景用在海外的企业,Lazada-政策条款解读,需要解决的是如何让机器阅读运用到更多的语言,例如像印尼语这样的小语种,但印尼语在Lazada中是市场非常大的。
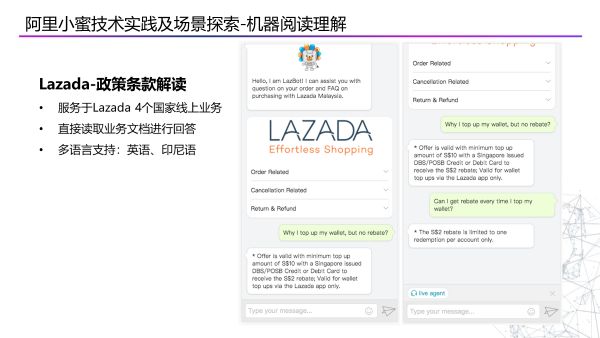
第四个场景是店小蜜中,我们推出了商家的活动专区功能,可以让商家直接以文本的方式来描述活动规则,机器自动阅读并回答用户问题。
机器阅读理解技术细节
一共分为四个步骤:
文章片段定位:针对用户问题,召回候选文档段落集合,借助文本分类、检索或者问题模板辅助;
输入预处理:格式归一,特征预计算问题,及相应段落向量表征,生成文档结构标签;
在线预测服务:GPU-Based模型加载及服务驱动,预测段落中词或符号得分;
后处理机制:基于动态规划选取最佳文本短语作为输出,拒识:判断是否拒绝回答。
机器阅读理解模型结构
Embedding Layer问题及篇章中词向量表示,RNN网络捕捉语序间依赖;
Attention Layer对齐问题和篇章,语义相似性计算,引进注意力机制,带着问题找答案;
Modeling Layer Question-Aware篇章建模,充分利用问题中信息;
Output Layer基于问题和篇章匹配预测答案位置。
多轮增强式导购
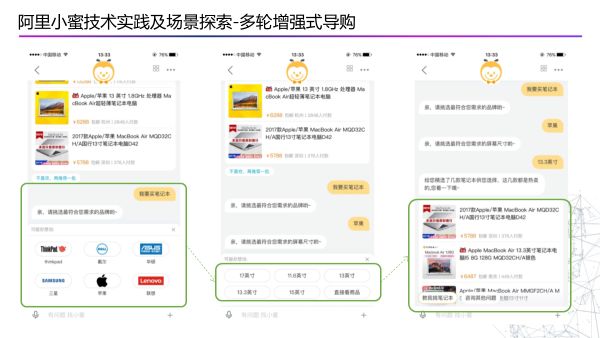
对于电商类机器人,主要功能是能否帮助客户快速的定位到自己想购买的产品,下面是几个例子,这里面会有一个问题, 在每一轮对话过程中,什么时候该出推荐商品,什么时候需要继续反问?因为反问的太多会导致用户离开。这个问题使用强化学习来解决的。
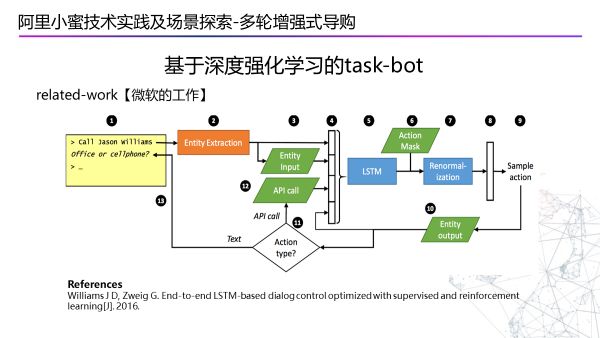
下面介绍一些微软在这方面的工作,他会先输入一些少量数据,做一个有监督的学习,再用Bot和用户做一个真实的交互,通过的方式做筛选,在这个基础上做一些调优。
第二个是剑桥在这方面的工作,它的network来生成一个策略,他的结果在推荐问题和给出结果之间选择。

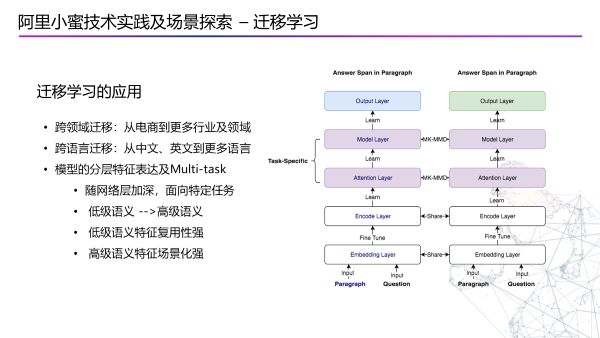
迁移学习
迁移学习对于企业小蜜有非常大的意义,因为需要从电商领域走向更多的行业,还有需要做跨语言的迁移学习。模型的迁移会做一个分层的表达,大部分的NLP模型都可以这样拆分,我们认为越是底层的层次越偏向于语言,他的复用性越高,越是上层,越偏向于具体的任务,复用性底。
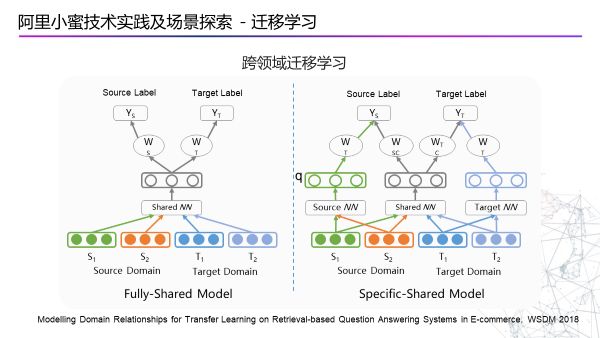
跨领域迁移学习
有两种方法,首先Fully-Shared Model是比较相似的两个领域,输入两个领域的知识,然后学习到两个领域公共的部分和表达。然后是Specific-Shared Model这种模型是采用摸着石头过河的方式,虽然两个领域相差比较远,但是也可以很好的过度过去,中间WSC和WTC会采用对抗的学习方式来训练。
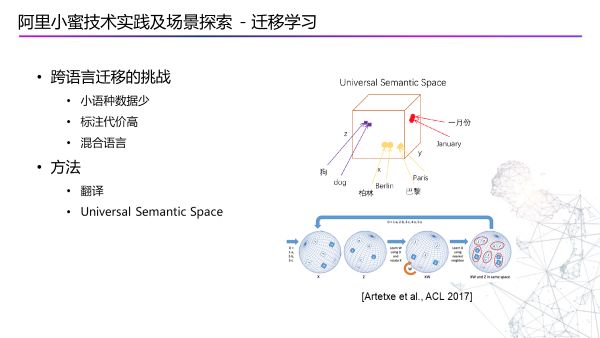
跨语言迁移学习
这部分最大的挑战是小语种的资料比较少,标签化的数据更少,所以面临比较大的挑战。我们现在有两种方法去解决:一是翻译,二是对用户的每次query进行Universal Semantic Space,右边的图是一个基础的思路。
挑战与思考
智能服务机器人将以多模态的方式,不仅提供自动服务模式,同时提供更好的人机协同模式,为用户和客服人员提供更复杂问题的解决能力和决策支持能力;
持续探索的技术方向:生成模型、强化学习、迁移学习、机器阅读理解、情感分析等。
作者介绍:

张佶(吉仁),阿里巴巴小蜜开放平台算法负责人,智能服务事业部高级算法专家,致力于智能人机交互领域的算法研究和业务场景落地,在机器学习和自然语言处理领域积累了多年的实战经验。目前在阿里小蜜团队担任云小蜜开放平台算法负责人,推动阿里小蜜在国内和海外企业领域的算法实践,带领团队实现了机器阅读理解等技术在工业界最早的成功应用。

先进制造业+工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进制造业OT(自动化+机器人+工艺+精益)和工业互联网IT(云计算+大数据+物联网+区块链+人工智能)产业智能化技术深度融合,在场景中构建“状态感知-实时分析-自主决策-精准执行-学习提升”的产业智能化平台;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。

版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。




