EMNLP 2018 | 从对话生成和文本风格转化看文本生成技术
| 本文授权转载自公众号:PaperWeekly
本文将介绍腾讯 AI Lab 发表于 EMNLP 2018 的两篇论文,论文关注的是文本到文本生成研究领域中的文本风格转化及对话生成任务。其中,在文本风格的论文中,作者提出了一个新的序列编辑模型旨在解决如何生成与给定数值相匹配的句子的研究问题。而关于对话生成的论文中,作者提出了一个新的对话模型用于抑制对话生成模型中通用回复的生成。
引言
随着近年来端到端的深度神经网络的流行,文本生成逐渐成为自然语言处理中一个热点研究领域。文本生成技术具有广阔的应用前景,包括用于智能对话系统,实现更为智能的人机交互;我们还可以通过自动生成新闻、财报及其它类型的文本,提高撰文者的工作效率。
根据不同的输入类型,文本生成可以大致划分为三大类:文本到文本的生成,数据到文本的生成以及图像到文本的生成。每一类的文本生成技术都极具挑战性,在近年来的自然语言处理及人工智能领域的顶级会议中均有相当多的研究工作。
本次将介绍腾讯 AI Lab 在文本到文本生成研究领域中关于文本风格转化及对话生成的两篇论文。其中,文本风格的论文中,我们提出了一个新的序列编辑模型旨在解决如何生成与给定数值相匹配的句子的研究问题。而关于对话生成的论文中,我们提出了一个新的对话模型用于抑制对话生成模型中通用回复的生成。以下我们将分别介绍两篇论文。
QuaSE: 量化指导下的序列编辑

在这篇由腾讯 AI Lab 主导,与香港中文大学(The Chinese University of Hong Kong)合作完成的论文中,作者提出一种新的量化指标引导下的序列编辑模型,可以编辑生成与给定的量化指标相匹配的句子,未来可以扩展到诸如 CTR 引导下的新闻标题和摘要生成、广告描述生成等业务场景中。
研究问题
论文的主要任务是给定一个句子以及其对应的分数,例如 Yelp 平台上的用户评价“The food is terrible”以及其评分 1,然后我们设置一个目标分数,让模型能够生成与目标分数相匹配的句子,并且原句的主要内容在新的句子中必须得以保持。例如,给定数值 3,生成“The food is OK”。给定数值 5,生成“The food is extremely delicious”。
任务的挑战和特点主要有以下几方面:
1. 给定的数值可以是连续的,例如 2.5, 3.7, 4.1 等,意味着很难像机器翻译一样能够有人工标注的成对出现的训练样本;
2. 模型需要具有甄别句子中与数值相关的语义单元的能力;
3. 根据数值进行句子编写时,必须保持原句的主要内容。
模型框架
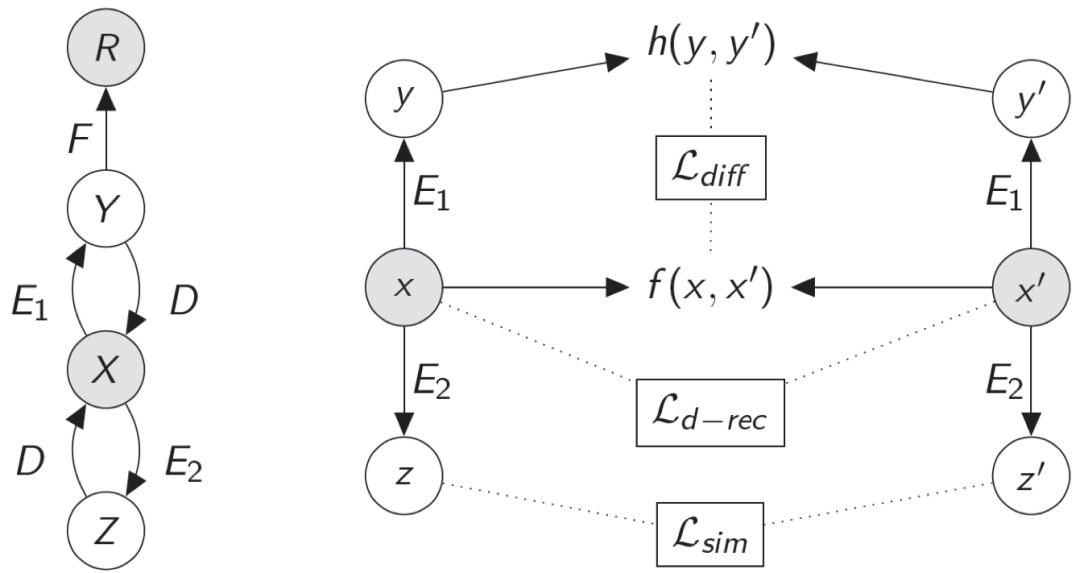
▲ 图1. QuaSE模型框架
图 1 为我们提出的模型 QuaSE 的框架,包含单句建模以及序列编辑两个部分的建模。左半部分为单句建模,其中 X 和 R 是观测值,分别表示句子(例如用户对餐厅的评价)以及其对应的数值(例如用户评分)。Z 和 Y 是隐变量,是对句子内容以及句子数值相关属性的建模表示。
受 Variational Auto-Encoders(VAE)模型的启发,对于隐变量 Z 和 Y 的建模是通过生成模型的方式实现。我们设计了两个 Encoder(E1 和 E2)和一个 Decoder (D),X 以 Z 和 Y 为条件进行生成。
模型的优化目标是使得生成的句子 X' 能够最大限度的重建输入句子 X。同时,由于优化目标积分计算困难等原因,我们采用变分的方法探寻优化目标的下界。单句建模的优化目标为:
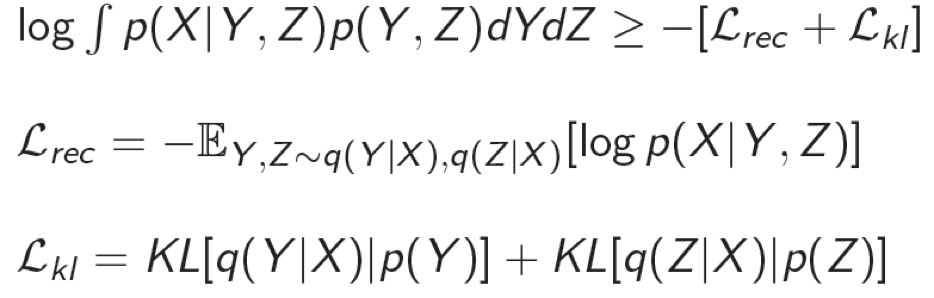
此外,我们还设计了一个回归函数 F 来学习隐变量 Y 和数值 R 的映射关系。
对于序列编辑过程的建模,我们首先构建了一个伪平行句对数据集。例如,对于句子 x=“I will never come back to the restaurant.” 我们找到其伪平行句子为 x'=“I will definitely come back to the restaurant, recommend!” 其中 x 和 x' 对应的数值分别是 1 和 5。
对于句子编辑的建模主要包含三个部分:
1. 建立句子 x 到句子 x' 的内容变化与数值变化之间的关系。原句 x 到目标句 x' 的变化肯定是增加或者减少了某些词,从而使得在数值这个属性上产生变化,即 y 到 y' 的差别。对于这个变化映射我们设计了第一个目标函数 L_diff;
2. 我们提到 x 和 x' 必须在主要内容方面继续保持一致,例如必须都是在描述“restaurant”。所以我们引入第二个目标函数 L_sim 来使得 z 和 z' 尽量的相似;
3. 我们知道生成过程是给定 z 和 y 来生成 x (p(x|z,y)),那么改写的过程可以是给定 z 和 y' 来生成 x' (p(x'|z,y')),也可以同时是给定 z' 和 y 来生成 x (p(x|z',y)),这是个双向过程。所以对于这两个生成过程我们引入了第三个损失函数 L_d-rec。
最后,单句建模和编辑建模可以融合成一个统一的优化问题通过端到端的方法进行训练。
实验分析
我们使用 Yelp 上的用户评论和打分数据进行实验,实验分为两个部分。
第一个实验主要是为了验证给定任意数值的句子编辑能力。我们通过 MAE 和 Edit Distance 两个指标来衡量句子编辑的性能。实验结果如表 1 所示:

▲ 表1. Yelp数据集上的任意数值指导下的句子改写
从表 1 中可以看出我们的模型编辑的句子质量更高,编辑后的句子的预测数值与给定的目标数值更接近。而且能够保持原句的主要内容。
为了更加形象的说明句子编辑的效果,我们抽样了一些样本进行展示,如表 2:
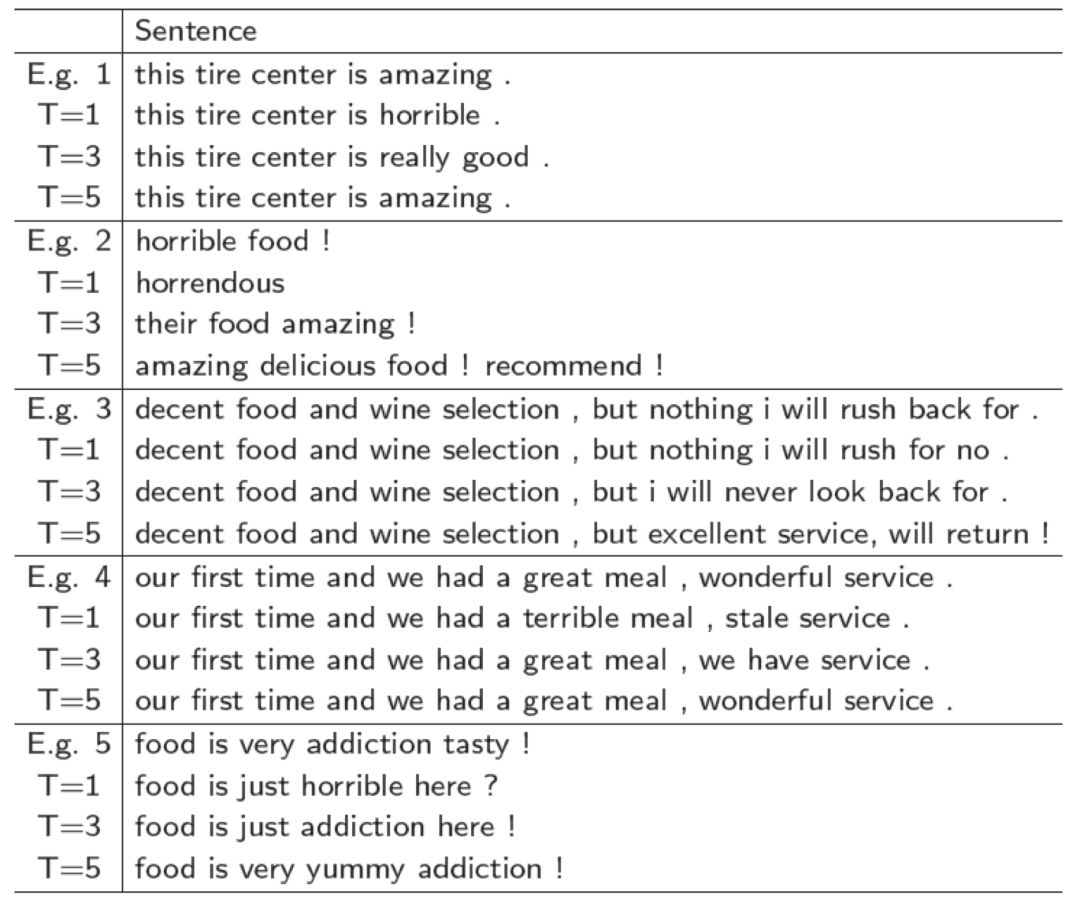
▲ 表2. 序列编辑的示例展示
另外,我们注意到有相关做文本风格转换的研究工作可以进行句子双向生成,即给定负向情感句子生成正向情感句子,或反之。
所以,为了与该类模型比较句子编辑的效果,我们设计了第二个实验与之对应,即从数值 1 的句子生成数值 5 的句子,或相反。我们用准确率来评价改写的好坏。实验结果如表 3 所示:

▲ 表3. 双向文本风格转换效果
实验结果说明我们的模型在双向文本风格转换实验中可以获得更高的准确率。
此外,生成的句子质量很难以进行客观评测,所以我们引入了人工评测的结果来衡量句子内容保持度以及句子质量的高低。人工评测结果如表 4 所示:
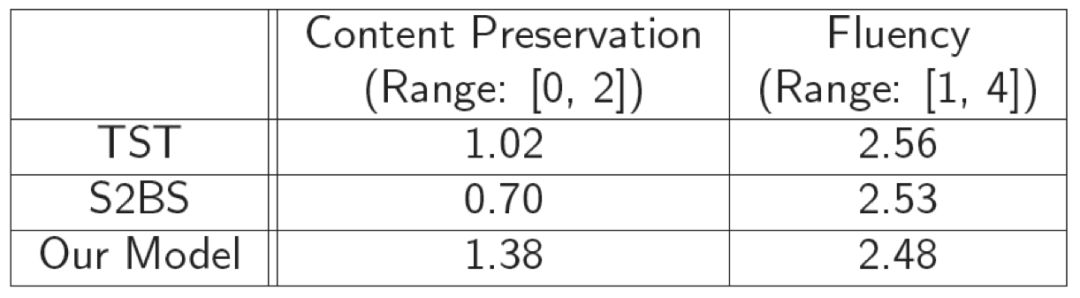
▲ 表4. 人工评测结果
可以看出我们的模型可以最大程度保持原句的内容,并且句子依然保持很好的流畅度。
基于统计重加权减少通用回复

在这篇由腾讯 AI Lab 主导,与武汉大学、苏州大学合作完成的论文中,作者提出一种适用于开放领域对话系统的新型神经对话模型(Neural Conversation Model),旨在解决生成模型中容易产生通用回复(如“我不知道”,“我也是”)的问题。
论文方法
神经生成模型在机器翻译中的成功应用,即神经机器翻译(Neural Machine Translation, NMT),激发了研究人员对于神经对话模型的热情。目前,最常用的神经对话模型为序列到序列(Sequence-to-sequence, Seq2Seq)模型:给定一个输入序列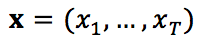
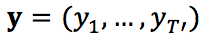
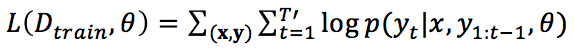
然而在开放领域的对话中,我们经常发现对于一个输入 x,如“你吃饭了吗?”,若干意思完全不一致的回复都是可以被接受的,如“刚吃完。”,“还没呢,还不饿。”,“不急。你呢?”等等,因此从 x 到 y 是一对多的映射关系。甚至,同一个回复经常可以适用于多个输入,因此是从 x 到 y 是多对多的映射关系(如图 1 所示)。
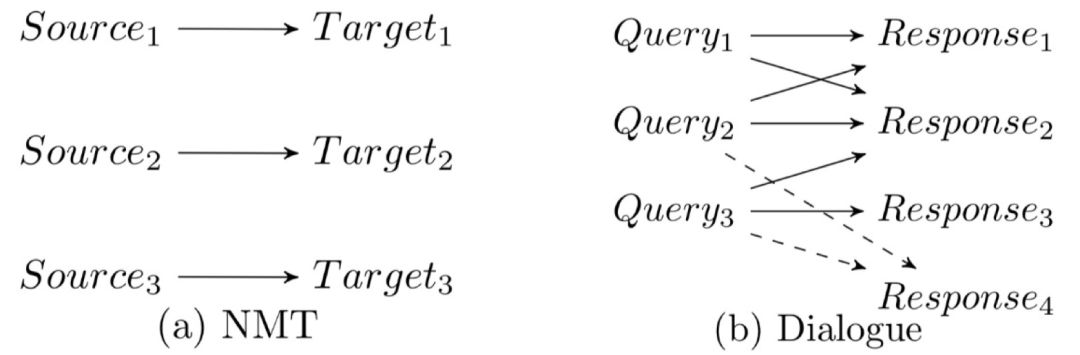
▲ 图1. 机器翻译及对话语料中从输入到输出的映射关系对比
然而,Seq2Seq 模型的目标函数学习的是一个从 x 到 y 的一对一的映射关系,并且优化的目标函数由大量的预测高频词/短语的损失项所组成,导致最终收敛的模型易于生成高频词及他们的组合,生成通用回复。
因此,本文在损失函数项中引入权重,使得 Seq2Seq 模型能优化更为多样化的损失项。其中,我们发现若输出为(包含)高频序列,以及输出序列长度过短或过长,此输出序列的损失项优化都容易导致通用回复,因此我们设计了有效的方法对这些损失项乘以一个较小的权重。有兴趣的读者可以阅读我们的论文及具体的权重计算方式。
实验分析
我们从各大中文社交网站(如微博等)中爬取并筛选了 700 万高质量的对话句对进行实验。其中,我们保留了 500 个输入作为测试集,并且聘请了 3 个评测人员对各种对话生成模型的生成回复进行了包括句子通顺度(Fluency)、与输入句子的相关性等方面的评测。
同时,我们也对比了多种权重设计方式的有效性,包括只使用句子频次(Ours-RWE)、只使用句子长度(Ours-RWF)以及句子频次、长度均使用(Ours-RWEF)。结果如表 1 所示。从中,我们可以看到,我们的方法在保持较高的句子通顺度的时候,有效地提高了回复的相关性。
我们还另外保留了 10 万个输入作为另一个较大的测试集。在这个测试集上,我们统计了各种对比模型中产出几个常见的通用回复的频次。结果见表 2。由此表可见,我们提出的方法极大程度地减少了生成的通用回复。
最后,我们在表 3 中给出一些具体的生成回复。由此我们可以更为直观地感受到所提出的方法确实能够生成质量较高的回复。
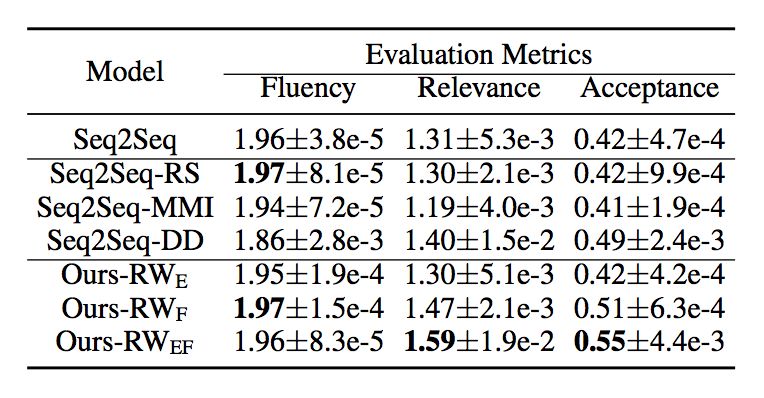
▲ 表1. 人工标注结果
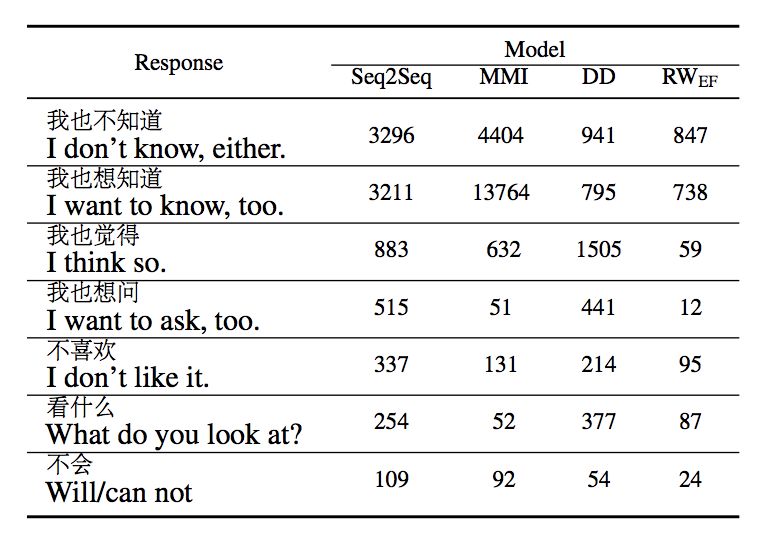
▲ 表2. 通用回复生成频次对比
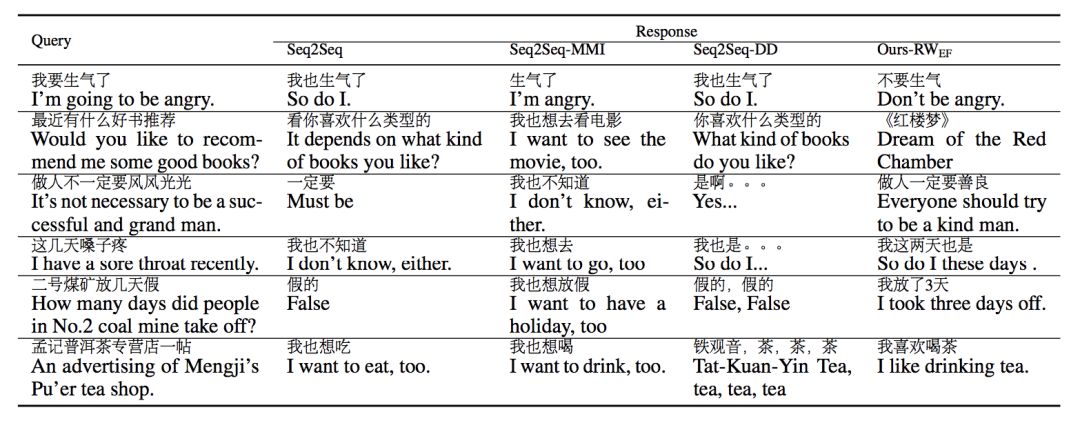
▲ 表3. 生成结果对比


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流




