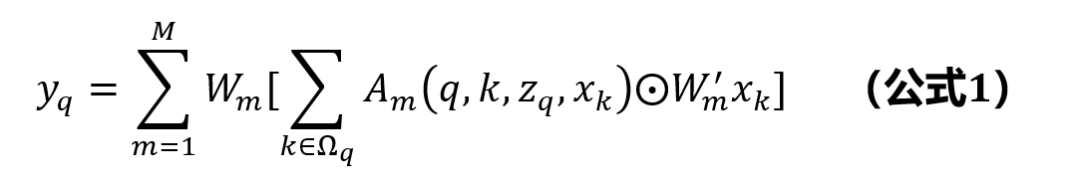点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
本文转载自:微软研究院AI头条
编者按:ICCV 2019 正于10月27-11月2日在韩国首尔举行。微软亚洲研究院有15篇论文入选本届 ICCV,内容涵盖空间注意力机制、图像深度估计、医学图像配准等多个前沿主题。本文将为大家介绍其中的5篇论文。
Recursive Cascaded Networks for Unsupervised Medical Image Registration
论文链接:https://arxiv.org/abs/1907.12353
GitHub链接:https://github.com/microsoft/Recursive-Cascaded-Networks
医学图像配准具有重要的临床意义,是医学图像处理任务中的关键步骤。待配准的图像可来自不同的模态、不同的时间点、不同的被试或者不同的成像视角。监督学习的配准方法需要大量准确成对的相关像素点标注;即便对医学专家来说,医学图像配准的成对相关像素点也非常难以标注。无监督算法克服了标注的困难,然而现有算法只能学习将运动图像一次性对齐到固定图像,对于变形大、变化复杂的配准效果较差。
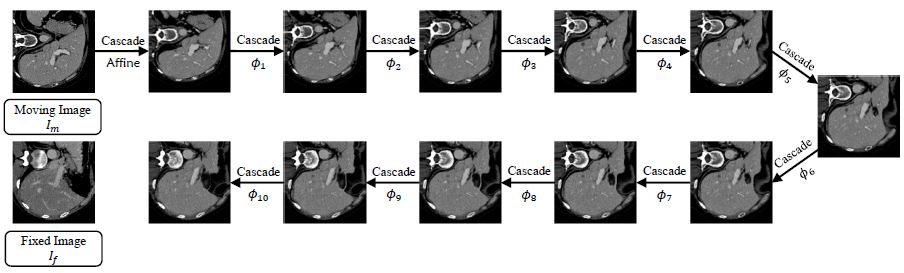
本文提出了一种深度递归级联的神经网络结构,可以显著提高无监督配准算法的准确率。图1是用于肝脏配准的递归级联网络效果图。运动图像通过一次一次微小的递归配准,最后与固定图像对齐。每个子网络的输入都是变形后的图像和固定图像,预测一个流场Φ。通过深度的递归迭代,最终的流场可以被分解为简单、轻微的渐进变化,大大降低了每个子网络的学习难度。
被这种现象所启发,我们提出了一种递归级联的神经网络结构。递归级联网络可以构建于任何已有的基础网络之上,通过无监督、端到端的方式学习到深度递归的渐进配准。除此之外,我们还提出了一种 shared-weight 级联技术,可以在测试中直接增加递归深度并提高准确率。
我们在 CT 的肝脏图像和 MRI 的脑图像上都做了算法评测,使用了多样的评价指标(包括 Dice 和关键点)。我们的实验证明递归级联的结构对于两种基础网络(VTN 和 VoxelMorph)的作用都非常显著,并且在所有数据集上都超过了包括 ANTs 和 Elastix 在内的传统算法。
An Empirical Study of Spatial Attention Mechanisms in Deep Networks
论文链接:
https://arxiv.org/abs/1904.05873
空间注意力(Spatial Attention)机制,特别是基于 Transformer 的注意力机制在最近取得了广泛的成功与应用,但是对该机制本身的理解和分析仍然匮乏。本论文对空间注意力机制进行了详尽的经验性分析,取得了更深入的理解与一些全新的观点,这些分析表明空间注意力机制的设计存在很大的改进空间。
论文 Transformer-XL 中提出,注意力权重可以按使用的特征因子被拆解为四项:(E1)query 内容特征和 key 内容特征;(E2)query 内容特征和 query-key 相对位置;(E3)仅 key 的内容特征;(E4)仅 query-key 相对位置。如图2所示。
图2:不同的注意力项的描述。采样点上方的颜色条表示其内容特征。当图中存在内容特征或相对位置时,表明该项将它们用于注意力权重计算。
受此启发,我们使用广义注意力形式(公式1)来统一不同的注意力机制:
在此形式下,Transformer、可变形卷积(Deformable Convolution)和动态卷积(Dynamic Convolution)均可被视为空间注意力的不同实例,其区别仅在于如何计算注意力权重 A_m (q,k,z_q,x_k )。我们在此形式下对影响空间注意力机制的各种因素进行了详尽的分析与研究。
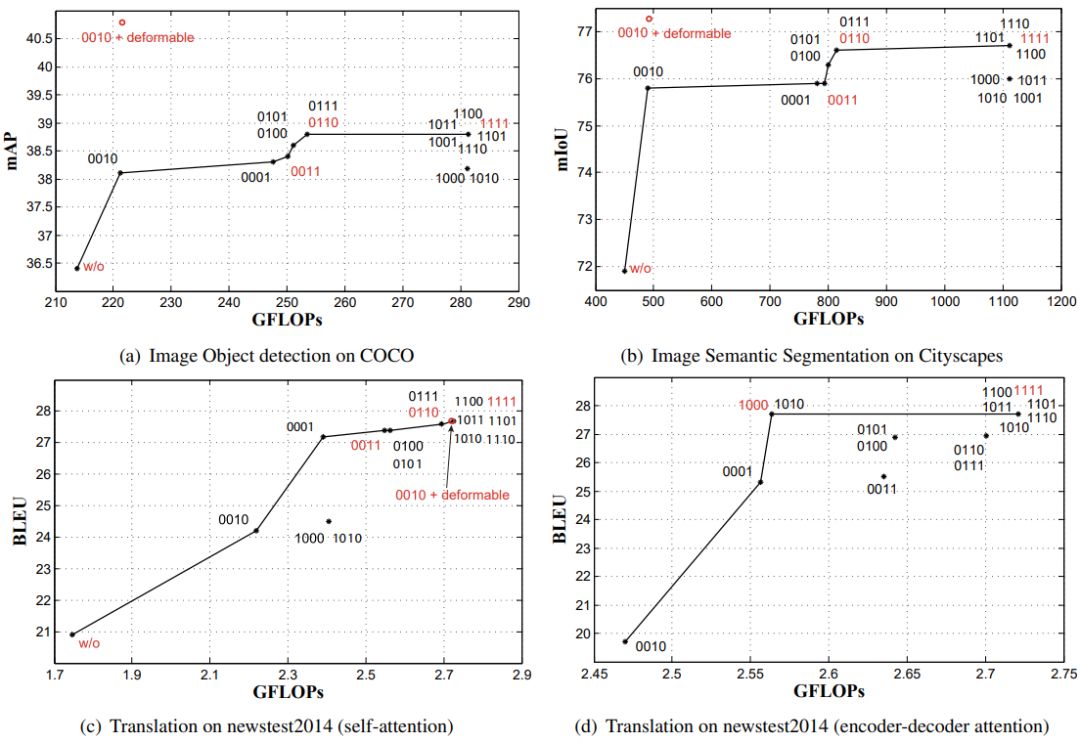
图3:不同特征因子对 Transformer 的性能影响
通过分析 Transformer 中不同特征因子对性能的影响(图3),我们发现:
1) 在 Self-Attention 中,query 无关项(E3)比 query 敏感项(E1、E2、E4)更重要,且 E2 与 E3 的组合是最重要的,而 E1 对精度的影响则可以忽略。
2) 在 Encoder-decoder Attention 中,建模 Query 与 Key 在内容上的关系(E1)至关重要。
该研究表明,建模 Query 和 Key 内容特征间的关系(E1)在 Self-Attention 中并不重要,甚至可以删除,这与人们的普遍认知相反。
此外,我们还探索了不同注意力机制间的关系(表1、2)。结果表明可变形卷积优于仅使用 E2 的 Transformer,且通过与仅使用 Key 内容项(E3)的 Transformer 进行组合,可以达到最佳的精度-效率权衡。而动态卷积在机器翻译任务中与仅使用 E2 的 Transformer 达到了相当的精度,但效率更低。在物体检测与语义分割任务中动态卷积则劣于 Transformer。
表1:可变形卷积与 Transformer 中 E2 项的比较
表2:动态卷积与 Transformer 中 E2 项的比较
这些结果表明 Transformer 仍具有巨大的改进空间。
Unsupervised High-Resolution Depth Learning from Videos With Dual Networks
论文链接:
https://arxiv.org/abs/1910.08897
Moving Indoor: Unsupervised Video Depth Learning in Challenging Environments
论文链接:
https://arxiv.org/abs/1910.08898
三维视觉技术需要获取除了传统二维图像的以外的深度维度的信息,是计算机视觉的基础任务之一,在三维显示、增强现实、人机交互、无人驾驶和机器人等领域都有着非常重要且深远的应用前景。尽管可以通过深度相机或者双目/多目的方法采集场景深度信息,但是受到硬件设备和成本限制,以及广泛存在的海量图像数据,单目图像深度估计是实际应用中非常必需的计算机视觉技术。
针对单目图像深度估计问题,我们利用海量的视频数据,在无需直接深度信息监督的条件下,进行了如下两个方向的研究:
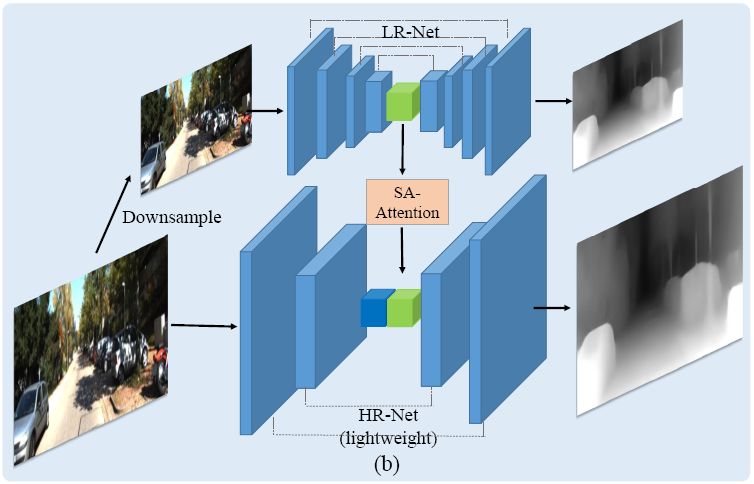
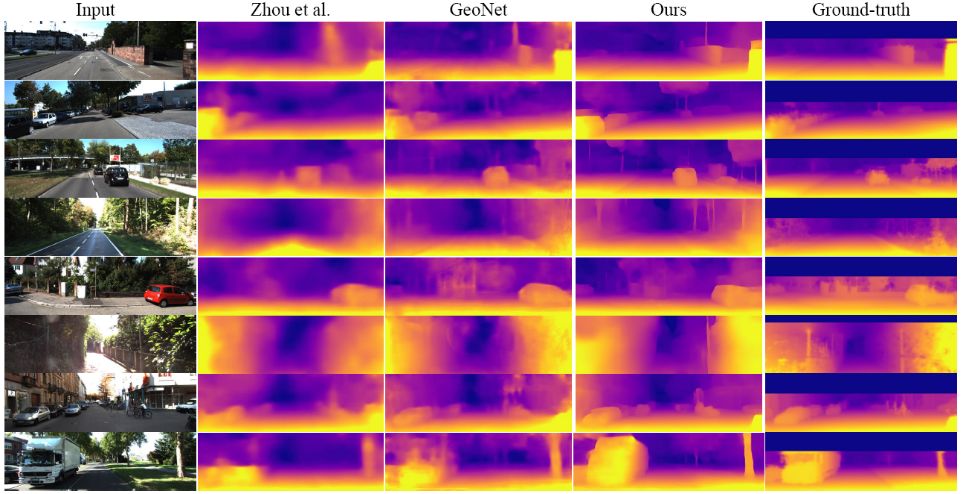
自监督深度学习以目标视角图像和视频中由临近帧合成的目标视角图像之间的图像表征差异作为监督信息。由于所有的监督信号均来源于图像本身,因此训练数据的图像分辨率对模型的性能具有非常重要的影响,高分辨率的图像含有更为细节的场景信息,可以提供更准确的监督信号。受到计算设备的内存和计算性能限制,目前用于深度估计训练的图像输入都经过了降采样处理,丢失了图像的细节信息。由此,本文提出一种基于双网络结构的高效的网络结构,使用全分辨率的图像作为深度网络训练的输入以保留监督信号的完整性。本文使用深度较深的网络处理低分辨率的图像输入,提取图像的全局特征,使用较浅的网络处理高分辨率的图像,提取局部的细节特征,同时使用一种基于自组织注意力机制的模块用来处理低纹理区域将上述的两部分特征进行结合预测深度值。本文在 KITTI 数据集上验证了该方法的有效性,取得了最优的效果,特别是在一些细节物体上效果提升明显,例如杆状物和物体边缘。
图5:深度估计结果示意图。我们的结果在精细区域(如杆状物,物体边缘)提升明显。
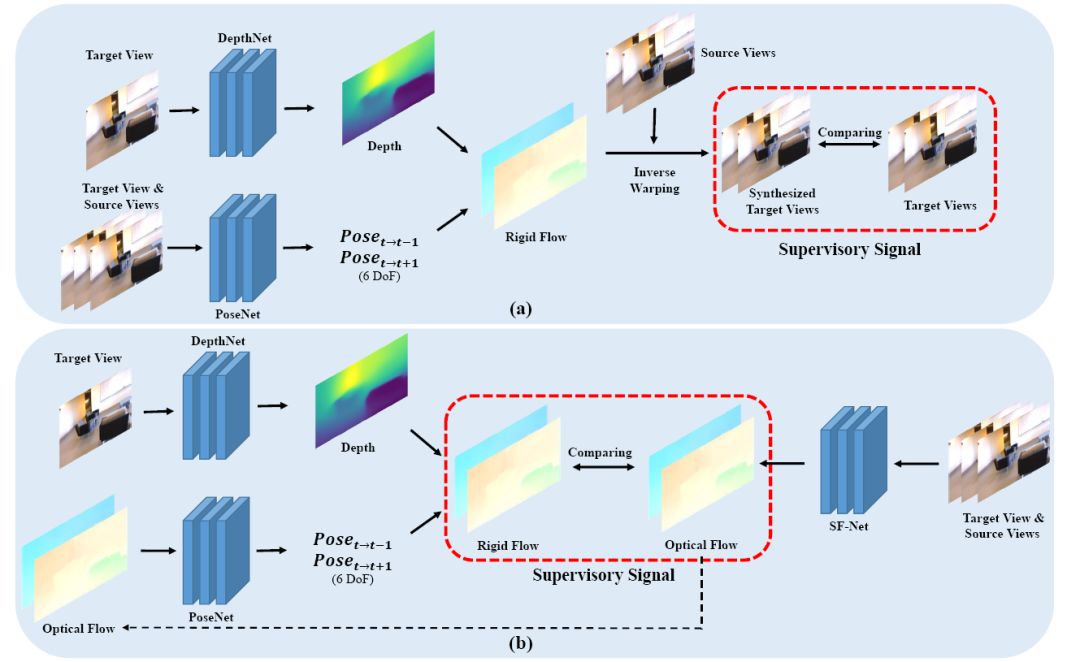
由于室内情景下,深度的分布比室外更复杂,包含大量的纹理缺失区域,并且拍摄视频的相机具有更为复杂的运动,因此传统的用于室外深度自学习的方法无法用于室内训练。我们提出在室内环境下使用更为鲁棒的光流作为监督信息,从稀疏点的光流传播得到密集光流再对深度网络进行监督,从而首次实现室内情景下稳定的深度估计。针对相机运动复杂的问题,我们使用光流这一比相机运动更为直接的信息作为预测相机位姿的输入,提升了相机运动的精度。
图6:网络结构与监督信号对比:(a)基于图像像素与(b)基于光流。
Learning Spatial Awareness to Improve Crowd Counting
论文链接:
https://arxiv.org/abs/1909.07057
人群计数的目的是利用人体头部的中心位置标注点信息来估计图像中的人数。随着深度卷积神经网络的发展,这一领域在近几年来取得了可喜的进展,现有的方法普遍采用均方误差损失函数 L2 Loss。然而,这一方法存在两个主要的缺点:
(1)这种损失函数在空间意识的学习上存在困难(空间认知障碍);(2)这种损失函数对人群计数中的各种噪声高度敏感,如零噪声、头部尺寸变化、遮挡等。Lempitsky 等人提出的 Maximum Excess over SubArrays (MESA) loss 通过从预测密度图中找到与 ground truth 差别最大的矩形子区域来解决了上述问题。然而,由于该方法不能使用梯度下降法求最优解,因此难以在深度学习框架中使用。
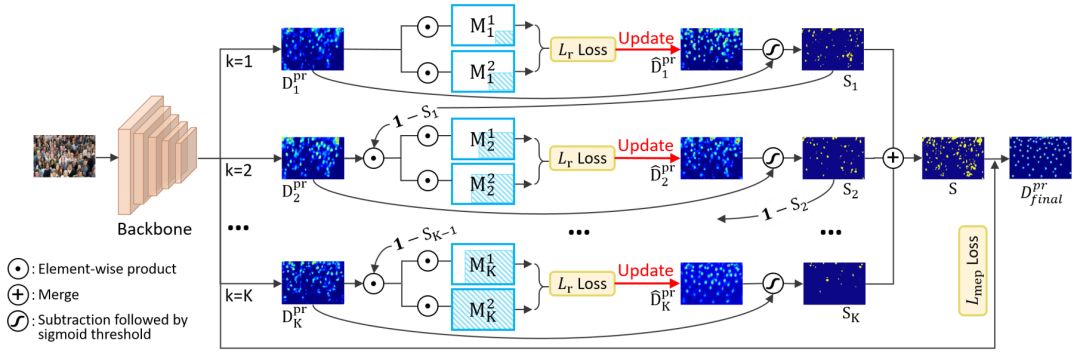
受MESA Loss的启发,我们提出了一种新的框架 SPatial Awareness Network (SPANet),通过结合空间语义信息,保留密度图的 high-frequency spatial variations,提高人群计数精度。该方法与 MESA Loss 寻找差异矩形子区域不同,而是通过 MEP Loss 来优化与 ground truth 存在较大差异的像素级子区域。为了得到这个像素级子区域,我们采用了一个多分支架构,在每个分支中通过两个 mask(其中一个 mask 是另一个 mask 的子区域)利用弱监督排序信息来发现差异大的像素,然后通过模仿显著性区域检测利用整个图像进行差异检测,从而获得与 ground truth 具有较大差异的像素级子区域S。该框架可以集成到现有的深度人群计数方法中,并且 end-to-end training。
图7:SPatial Awareness Network(SPANet)框架图
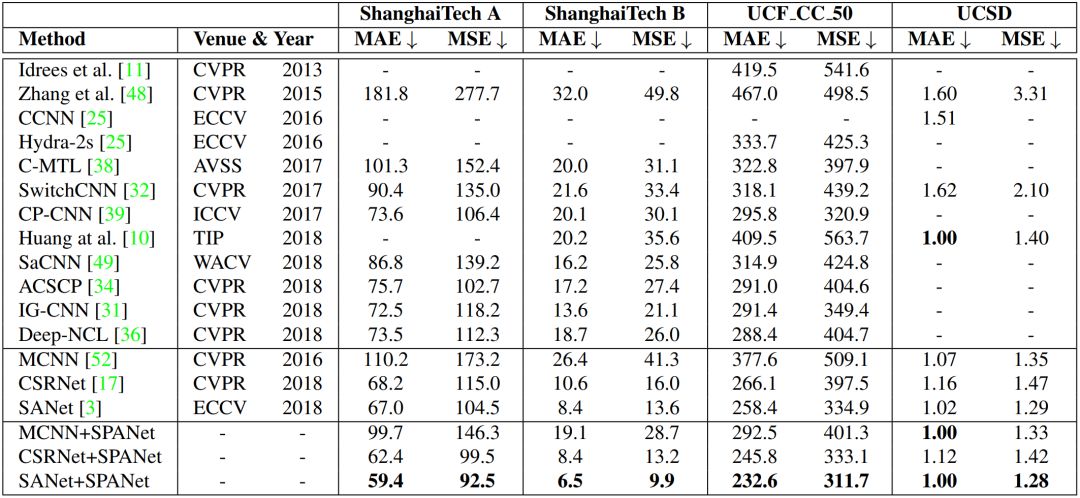
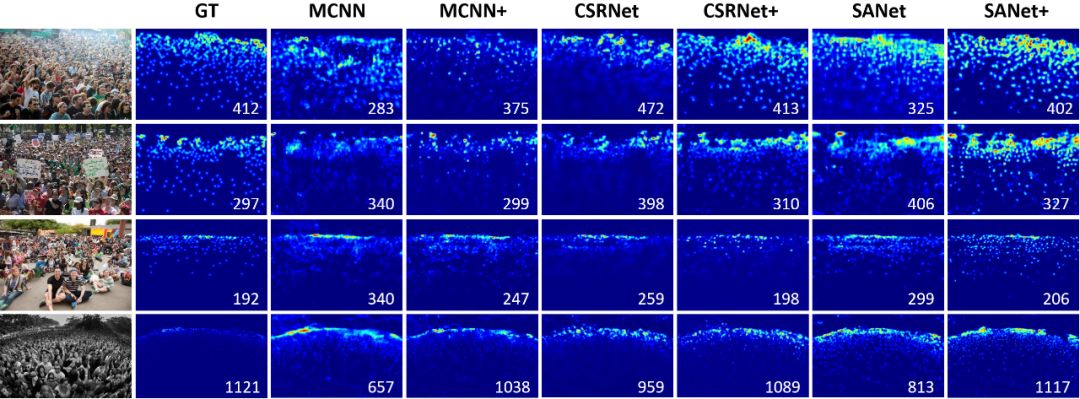
我们在 MCNN、CSRNet 和 SANet 三种深度卷积网络上融入了该方法,并借助 ShanghaiTech、UCF CC 50、WorldExpo'10和 UCSD 四个数据集进行了实验。实验结果表明,我们的方法显著地改进了所有基线,并且优于其他先进方法。这一结果充分说明了 SPANet 的有效性,不管是密集还是稀疏人群场景,都可以提供精确的密度估计。
表3:SPANet 在不同数据集上与 baseline 方法的实验对比
图8:SPANet 与 baseline 方法的预测密度图比较
重磅!CVer学术交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪&去雾&去雨等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)
![]()
▲长按加群
![]()
▲长按关注我们
麻烦给我一个在看!