程序员拯救乐坛?OpenAI 用“逆天”GPT2.0 搞了个 AI 音乐生成器


作者 | 琥珀
出品 | AI科技大本营(id:rgznai100)
以下为译文:
基于深度神经网络进行语音合成、音乐风格迁移,正成为不少致力于“让人人成为音乐家”的研究人员所追求的事情。像此前我们报道的微软小冰作词又作曲,AI帮清华博士写说唱歌词晋级,甚至不久前中央音乐学院招音乐AI方向博士生。不久前,为了纪念著名作曲家巴赫诞辰,Google 根据巴赫合唱和声训练而成的机器学习模式 Coconet 吸引了不少人前来围观。
最近,OpenAI 最新研发的 MuseNet 的深度神经网络,可以制作 4 分钟时长的音乐作品,其中涵盖 10 种不同的乐器(如钢琴、鼓、贝斯、吉他),甚至还能将诸如乡村风格、莫扎特风格、甲壳虫乐队风格的音乐融合起来。

首先需要说明的是,MuseNet 并没有根据人类输入的对音乐理解进行显式编程,而是通过学习预测成千上万个 MIDI 文件的下一个 token 来发现和弦、节奏和风格的模式。MuseNet 采用了无监督神经网络语言模型 GPT2.0(是的,就是此前被誉为可以 BERT 媲美的 NLP 模型 GPT2.0,普遍观点是,经过预训练可以预测上下文,无论是音频还是文本。)

据悉,5 月 12 日将正式开放 MuseNet 语言生成工具的试用版本。
传送门:
https://openai.com/blog/musenet/

过程原理
在简单模式(默认显示)中,用户会听到预设生成的随机未切割样本;然后选择某作曲家或风格下的著名作品片段,即可生成各种风格的音乐。
在高级模式下,用户可直接与模型交互。这个过程需要完成的时间会更长,但用户可以创建一个全新的作品。
注意:MuseNet 通过计算所有可能的音符和乐器的概率来生成每个音符,模型会倾向采用你选择的乐器,但也可能会选择逼得乐器;同样,MuseNet 也会搭配不同风格的乐器,如果用户自行选择最接近作家或乐队常用分风格或乐器,产生的音乐会更自然。
研究人员还创建了作曲家和乐器的 token,以便更好地控制 MuseNet 生成的样本类型。训练期间,这些作曲家和乐器 token 将预先添加到每个样本中,因此模型将学习利用该信息进行音符预测。生成音乐时,可以调整模型,如拉赫玛尼诺夫的钢琴曲为前提,以创建选定风格的音乐。
研究人员还将 MuseNet 中的嵌入进行可视化,以深入了解模型所学到的内容。他们采用了 t-SNE 创建各种风格嵌入的余弦相似性。(如下 2D 图像所示,可查看某个特定作曲家或风格之间的关系。)
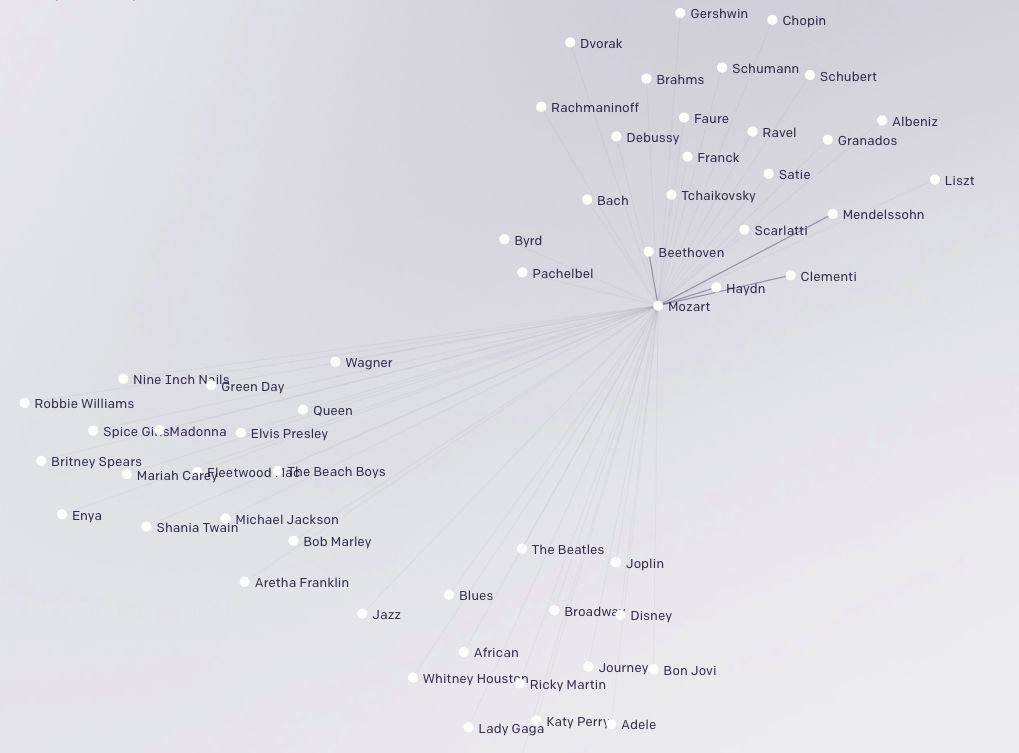

利用 Sparse Transformer 记住长期结构
MuseNet 使用 Sparse Transformer 的重算和优化内核来训练一个具有 24 个注意力头的 72 层网络,并将全部注意力放在 4096 个 token 的上下文中。这个长文本的目的是能够记住一个片段中的长期结构。或者,它还可以创建音乐旋律结构。
音乐生成是测试 Sparse Transformer 的一个有用域,因为它位于文本和图像的中间位置。它具有文本的 token 结构。在图形中,你可以查看 N 个 token,而在音乐中,查看之前的起点没有固定数。此外,还可以很容易听到该模型是否在按照成百上千个 token 顺序来获取长期结构。

数据集
研究人员收集了不同来源的 MuseNet 训练数据(ClassicalArchives、BitMidi、MAESTRO ),涵盖爵士乐、流行乐,以及非洲、印度和阿拉伯等不同风格的音乐。
首先,研究人员采用 transformer 在序列数据上进行训练:给定一组音符,要求它预测其他即将出现的音符。在尝试了几种不同方法后将 MIDI 文件编码为适用于此任务的 token。
在这种其中,他们采用和弦方法,将每次听到的音符组合视为单独的 “和弦”,并为每个和弦指定一个 token。然后,通过仅关注音符开头压缩音乐模式,并尝试使用字节对编码方案进行近一步压缩。
研究人员还尝试了标记时间推移的两种不同方法:一是根据音乐节奏进行缩放的 token,代表节拍或节拍的一小部分;二是以绝对时间为单位来标记 token。他们采用了一种结合了表现力和简洁性的编码方式:将音高、音量以及乐器信息组合称一个 token。
在训练中,
通过提高和降低音高来调换音符。(之后的训练中,减少了调换数量,使得每个乐器都有生成的音符。)
提高音量,调高或降低不同样本的整体音量。
增加时间,当使用以秒为单位的绝对时间编码时,可有效稍微减缓或加速片段。
在 token 嵌入空间中使用 mixup。
研究人员还创建了一个内部评测,在训练中,通过模型预测给定的样本是否来自数据集还是之前生成的样本,进行评判。

嵌入
为了给模型提供更加结构化的上下文,研究人员还添加几种不同类型的嵌入。
除了标准位置嵌入外,还有学习到的嵌入,可在给定的样本中追踪时间推移;然后,他们还在每个和弦中的音符添加了嵌入;最后,他们添加了两个结构化嵌入,该嵌入可表明模型既定的音乐样本在较大音乐片段中的位置。
【END】

作为码一代,想教码二代却无从下手:
听说少儿编程很火,可它有哪些好处呢?
孩子多大开始学习比较好呢?又该如何学习呢?
最新的编程教育政策又有哪些呢?
下面给大家介绍CSDN新成员:极客宝宝(ID:geek_baby)
戳他了解更多↓↓↓

热 文 推 荐
☞ 京东回应 5000 万用户数据泄露;百度向今日头条索赔 9000 万;腾讯全球专利申请量第二 | 极客头条
☞ 19 岁当老板,20 岁 ICO 失败,编程少年的创业辛酸史
☞ 打开阿兹海默之门:华裔张复伦利用RNN成功解码脑电波,合成语音 | Nature
☞ 澳洲生活7年, 前阿里程序员谈我们的区块链差距究竟在哪?
System.out.println("点个在看吧!");
console.log("点个在看吧!");
print("点个在看吧!");
printf("点个在看吧!\n");
cout << "点个在看吧!" << endl;
Console.WriteLine("点个在看吧!");
Response.Write("点个在看吧!");
alert("点个在看吧!")
echo "点个在看吧!"
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。





