【神经网络本质是多项式回归】Jeff Dean等论文发现逻辑回归和深度学习一样好


新智元报道
来源:Reddit;arXiv
作者:闻菲
【新智元导读】谷歌用深度学习分析电子病例的重磅论文给出了一个意外的实验结果,DNN与逻辑回归效果一样,引发了热烈讨论。不仅如此,最近Twitter讨论最多的论文,是UC戴维斯和斯坦福的一项合作研究,作者发现神经网络本质上就是多项式回归。下次遇到机器学习问题,你或许该想想,是不是真的有必要用深度学习。

近来,谷歌一篇关于使用深度学习进行电子病例分析的论文,再次引发热议。
起因是以色列理工学院工业工程与管理学院的助理教授 Uri Shalit 在 Twitter 上发文,指出这篇论文的补充材料里,有一处结果非常值得注意:标准化逻辑回归实质上与深度神经网络一样好。

Uri Shalit 的研究方向是将机器学习应用于医疗领域,尤其是在向医生提供基于大型健康数据的决策支持工具方面。其次,他也研究机器学习和因果推断的交集,重点是使用深度学习方法进行因果推断。在加入以色列理工学院以前,他先后在 David Sontag 教授在纽约大学和在 MIT 的临床机器学习实验室当博士后。 Uri Shalit 说的补充材料中的结果是指这个:
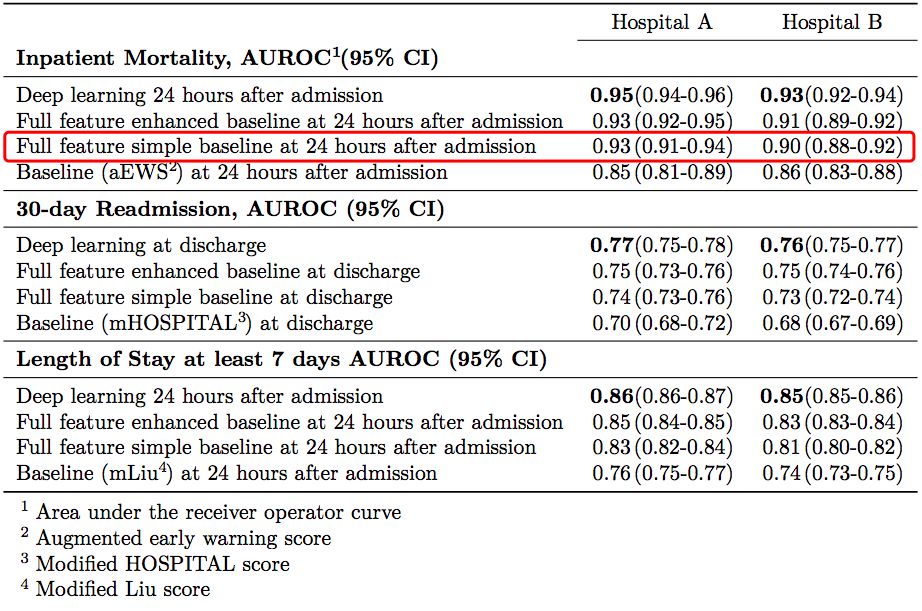
其中,基线 aEWS(augmented Early Warning Score)是一个有 28 个因子的逻辑回归模型,在论文作者对预测患者死亡率的传统方法 EWS 进行的扩展。而 Full feature simple baseline 则是 Uri Shalit 说的标准化逻辑回归。
注意到基线模型(红框标识)和深度模型在 AUCs 置信区间的重叠了吗?
Uri Shalit 表示,他由此得出的结论是,在电子病例分析这类任务中,应该选择使用逻辑回归,而不是深度学习,因为前者更加简单,更具可解释性,这些优点要远远胜过深度学习带来的微小的精度提升。
或者,Uri Shalit 补充说,这表明我们目前还没有找到正确的深度学习结构,能实现在图像、文本和语音建模领域中那样的性能提升。
谷歌的这篇论文“Scalable and Accurate Deep Learning for Electronic Health Records”,发表在自然出版集团(NPG)旗下开放获取期刊 npJ Digital Medicine 上,由 Jeff Dean 率队,联合 UCSF、斯坦福、芝加哥大学众多大牛,与全球顶级医学院联合完成,从题目到作者都吊足了大家的胃口。

实际上,早在今年初,新智元就介绍过这篇论文,当时它还只是挂在 arXiv 上,康奈尔大学威尔医学院助理教授王飞对当时的 arXiv 版本进行了解读。
这项工作是在 UCSF 和 UChicago 这两大医院系统的电子病历数据上,用深度学习模型预测四件事:1)住院期间的死亡风险;2)规划之外的再住院风险;3)长时间的住院天数;4)出院的疾病诊断。
文章仔细介绍了实验信息,例如如何构建病人队列、特征如何变换、算法如何评价等等。对于每一个预测任务,作者也都选取了临床上常用的算法作为基线来进行比较,例如评价死亡风险的 EWS 分数,以及评价再住院风险的 HOSPITAL 分数,并对这些模型做了微小的改进。最终结果,作者提出的深度学习模型在各项任务中都显著优于传统模型(AUC 普遍提高 0.1 左右)。
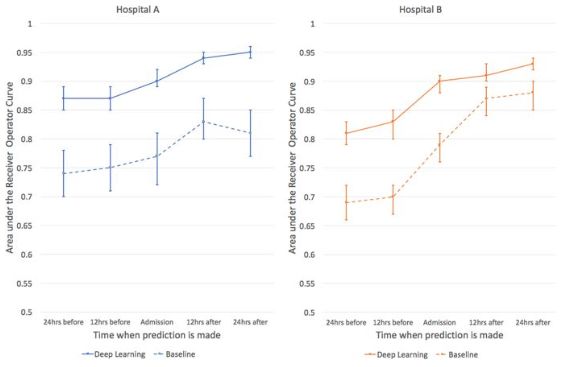
论文插图:使用深度学习预测病人住院期间死亡风险,深度学习(实线)在前后24小时时间范围内,都比基线水平(虚线)准确率更高。
如果说这次在同行评议期刊发表出的论文与之前的 arXiv 版本有什么不同,最大的就是给出了 15 页的补充资料,展示了深度学习方法与各种基线的具体数值。
谷歌这篇论文的初衷,是强调直接从 FHIR 数据中进行机器学习(“我们提出了一种对病人整个基于 FHIR 格式的原始 EHR 的表示”)。正如论文中所写的那样,其方法的原创性并不仅仅在于对模型性能的提升,而是“这种预测性能是在没有对专家认为重要的那些变量进行手动选择的情况下实现的……模型访问每位患者数以万计的预测因子,并从中确定哪些数据对于进行特定的预测非常重要”。
但是,从论文的一些表述,尤其是标题中,难免有宣传深度学习的嫌疑,也是这次争议重点所在。
现如今,深度神经网络已经成了很多分析师进行预测分析的首选。而在大众媒体里,“深度学习”也几乎可以算得上“人工智能”的同义词。
深度学习的热潮或许仍在持续,但很明显,越来越多的人开始冷静下来思考并且质疑。
在一篇最新公布的文章里,加州大学戴维斯分校和斯坦福的研究人员便指出,神经网络本质上是多项式回归模型。他们的文章取了一个谨慎的标题《多项式回归作为神经网络的代替方法》(Polynomial Regression As an Alternative to Neural Nets),对神经网络的众多性质进行了讨论。

作者在论文中列出了他们这项工作的主要贡献,包括:
NNAEPR 原理:证明了任何拟合的神经网络(NN)与拟合的普通参数多项式回归(PR)模型之间存在粗略的对应关系;NN 就是 PR 的一种形式。他们把这种松散的对应关系称为 NNAEPR——神经网络本质上是多项式模型(Neural Nets Are Essentially Polynomial Models)。
NN 具有多重共线性:用对 PR 的理解去理解 NN,从而对 NN 的一般特性提供了新的见解,还预测并且确认了神经网络具有多重共线性(multicollinearity),这是以前未曾在文献中报道过的。
很多时候 PR 都优于 NN:根据 NNAEPR 原理,许多应用都可以先简单地拟合多项式模型,绕过 NN,这样就能避免选择调整参数、非收敛等问题。作者还在不同数据集上做了实验,发现在所有情况下,PR 的结果都至少跟 NN 一样好,在一些情况下,甚至还超越了 NN。
其中,作者重点论证了他们的 NNAEPR 原理。此前已经有很多工作从理论和实践角度探讨了神经网络和多项式回归的共性。但是,UC戴维斯和斯坦福的这几名研究人员表示,他们的这项工作是首次证明了 NN 就是 PR 模型,他们从激活函数切入:
根据通用逼近定理,NN 可以无限逼近回归函数 r (t),
假设 p = 2,用 u 和 v 来表示特征,第一层隐藏层的输入,包括“1”的节点,将是
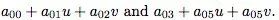
设激活函数为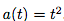
而对于更加实际的激活函数,其本身就常常被多项式逼近。因此,也适用于上述规则。
换句话说,NN 可以被松散地视为多项式回归的一种。
作者进行了很多实验来比较 PR 与 NN 的性能。在下面的各种结果中,PR 表示多项式回归,PCA 表示在生成多项式之前用 90%总方差主成分分析降维。KF 表示通过 Keras API 的神经网络,默认配置是两层,一层 256 个单元,一层 128 个单元(写作 “256,128”),dropout 比例是 0.4。DN 表示通过 R 语言包 deepnet 的神经网络。DN 会比 KF 快很多,因此在大一些的问题里会用 DN,但两者性能还是相似的。
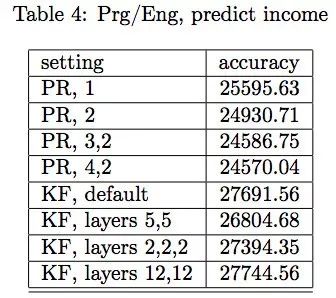
硅谷程序员收入预测的结果
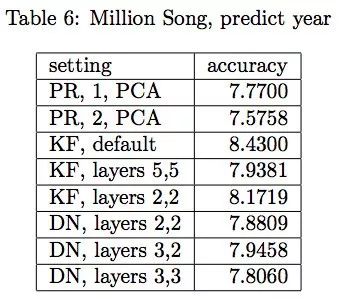
预测歌曲出版时间的结果
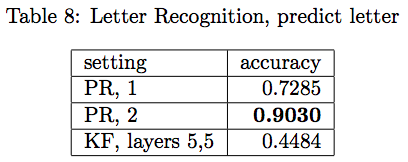
UCI 数据集字母预测的结果
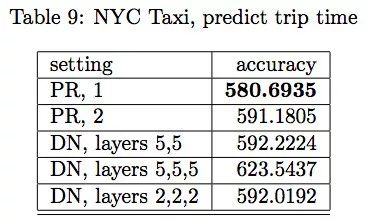
Kaggle 数据集出租车旅途时长预测结果
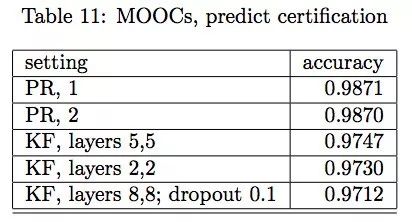
哈佛/MIT MOOC获得证书预测结果
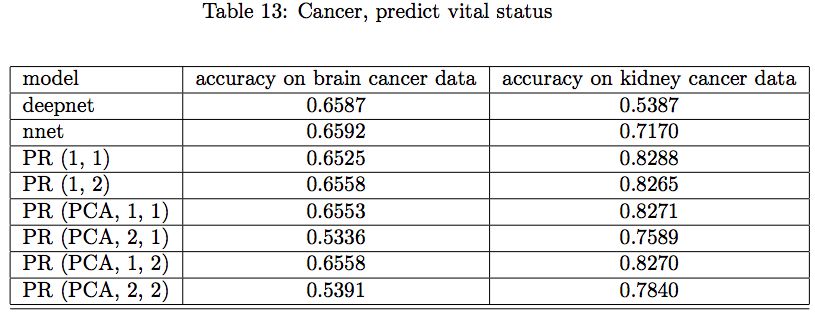
NCI 基因数据癌症预测结果
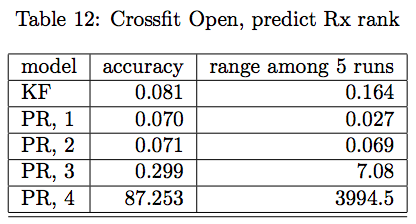
男女运动数据预测 Crossfit Open 排名
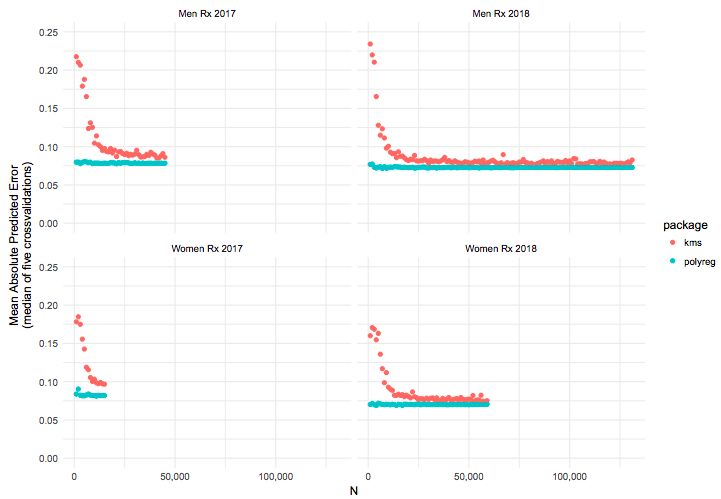
Crossfit Open 排名,数据集大小与预测精度的比较
总之,一系列实验结果表明,PR 至少不会比 NN 差,有些时候还超过了 NN。在实践中,许多分析师只是一开始就去拟合过大的模型,比如使用很多层,每层有数百个神经元。他们发现,使用 PR,很少需要超越 2 级,NNAEPR 原理表示,只用一层或者两层就够了,每一层有少量的神经元。
同时,作者也开始怀疑,拟合大的 NN 模型通常导致大多数的权重为0,或接近于0。他们已经开始调查这一点,初步结果与 NNAEPR 原理相结合表明,在 NN 初始化中 configur 大型网络可能是个糟糕的策略。
最后,他们开源了一个 R 语言的软件包 polyreg(Python 的正在制作中),里面有很大源代码可以实现很多功能。
相关论文
谷歌深度学习电子病例分析论文:https://www.nature.com/articles/s41746-018-0029-1
UC戴维斯+斯坦福:神经网络作为多项式回归的替代方法:https://arxiv.org/pdf/1806.06850v1.pdf
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号: aiera2015_3 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。





