2019最全目标检测指南
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
计算机视觉是一门研究如何对数字图像或视频进行高层语义理解的交叉学科,它赋予机器“看”的智能,需要实现人的大脑中(主要是视觉皮层区)的视觉能力。
想象一下,如果我们想为盲人设计一款导盲产品,盲人过马路时系统摄像机拍到了如下的图像,那么需要完成那些视觉任务呢?

-
图像分类:为图片中出现的物体目标分类出其所属类别的标签,如画面中的人、楼房、街道、车辆数目等; -
目标检测:将图片或者视频中感兴趣的目标提取出来,对于导盲系统来说,各类的车辆、行人、交通标识、红绿灯都是需要关注的对象; -
图像语义分割:将视野中的车辆和道路勾勒出来是必要的,这需要图像语义分割技术做为支撑,勾勒出图像物体中的前景物体的轮廓; -
场景文字识别:道路名、绿灯倒计时秒数、商店名称等,这些文字对于导盲功能的实现也是至关重要的。
-
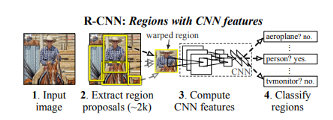
R-CNN -
Fast R-CNN -
Faster R-CNN -
Mask R-CNN -
SSD (Single Shot MultiBox Defender) -
YOLO (You Only Look Once)

-
训练是一个多阶段的任务,调整物体区域的卷积神经网络,使SVM(支持向量机)适应ConvNet(卷积网络)功能,最后学习边界框回归; -
训练在空间和时间上都很昂贵,因为VGG16是占用大量空间的深层网络; -
目标检测很慢,因为它为每个候选区域都要执行ConvNet前向传播。
https://arxiv.org/abs/1311.2524?source=post_page
http://host.robots.ox.ac.uk/pascal/VOC/voc2010/index.html?source=post_page
https://heartbeat.fritz.ai/a-beginners-guide-to-convolutional-neural-networks-cnn-cf26c5ee17ed?source=post_page
Fast R-CNN
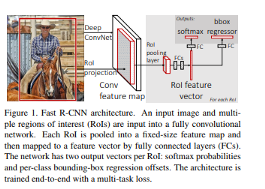
https://github.com/rbgirshick/fast-rcnn?source=post_page
Faster R-CNN
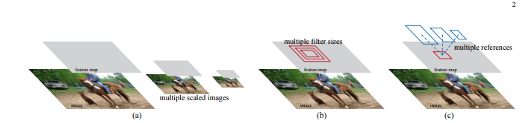
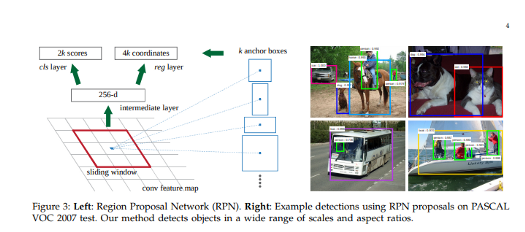
https://arxiv.org/abs/1506.01497?source=post_page
Mask R-CNN
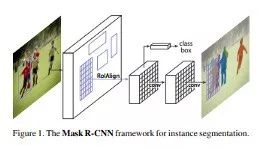
https://arxiv.org/abs/1703.06870?source=post_page
SSD: Single Shot MultiBox Detectorz
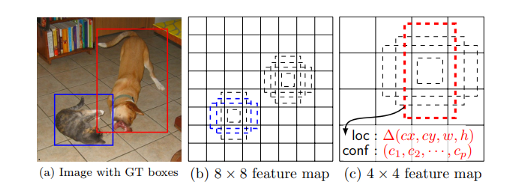
https://arxiv.org/abs/1512.02325?source=post_page

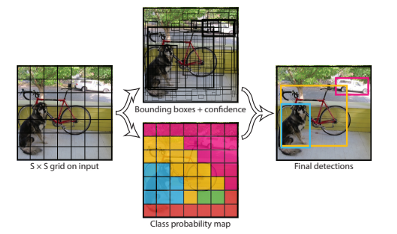

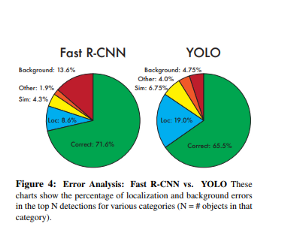
https://arxiv.org/abs/1506.02640?source=post_page

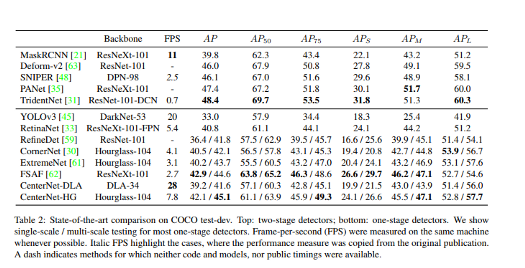
https://arxiv.org/abs/1904.07850v2?source=post_page

https://arxiv.org/abs/1906.11172v1?source=post_page
https://heartbeat.fritz.ai/a-2019-guide-to-object-detection-9509987954c3

高效对接AI领域项目合作、咨询服务、实习、求职、招聘等需求,背靠25W公众号粉丝,期待和你建立连接,找人找技术不再难!
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、算法竞赛、检测分割识别、GAN、三维视觉、医学影像、自动驾驶、计算摄影等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

推荐阅读
最新AI干货,我在看




